一种针对视觉跟踪模型的人在回路训练方法及相关装置
文献发布时间:2023-06-19 12:02:28
技术领域
本发明属于计算机视觉领域,具体涉及一种针对视觉跟踪模型的人在回路训练方法及相关装置。
背景技术
视觉目标跟踪是计算机视觉和人工智能领域内的一个重要且基础的问题。该问题主要研究内容为在一段视频序列中,给定初始帧中的目标位置和大小,视觉目标跟踪算法如何自动的跟踪目标并给出之后帧中的目标位置和大小。视觉目标跟踪可应用于自动驾驶、智能安防、智慧城市、国防军工等众多领域,是当前人工智能领域的热点问题。近些年,由于深度学习模型相比于传统模型拥有较高的准确性,基于深度学习的视觉目标跟踪算法取得了较快的发展。
然而,基于深度学习视觉跟踪模型的跟踪效果会受到训练数据的数量和质量的影响。基于深度学习的模型网络结构复杂,参数众多,所以需要大量的,有标签的训练数据来训练深度模型以防止过拟合。通过实验发现,大幅度提高训练数据的数量,可以有效的提升模型的跟踪性能。同时,不同质量的训练数据也会影响跟踪模型的表现。采用质量更好的训练数据集,例如数据集中包含更全面的物体类别,更多的目标姿态等等,也可以有效的提高跟踪模型的准确性。但是,获得大量且高质量的有标签训练数据是非常耗费人力和时间的,现有的用于视觉跟踪的深度模型,大多都依赖万级甚至百万级千万级的图片数量,对如此庞大数量的样本进行人工标注是非常耗费时间和人力的。此外,用于训练跟踪模型的数据集大都是视频序列。视频的连续帧中,物体的位置,尺度和姿态变化都非常小,目标物和背景都极为相似,这也就意味着训练数据中的视频序列存在着大量的冗余信息,对这些冗余信息不加筛选的全部标注,则是非常低效和不经济的。
基于以上两个方面,势必需要一种高效的视觉跟踪模型训练方法。
发明内容
为解决现有技术中存在的问题,本发明的目的在于提供一种针对视觉跟踪模型的人在回路训练方法及相关装置,本发明能够解决现有基于深度模型的视觉目标跟踪算法训练数据量大、数据中冗余信息较多以及由此造成的数据标注费时费力的问题。
本发明采用的技术方案如下:
一种针对视觉跟踪模型的人在回路训练方法,包括如下过程:
S1,从已构建的初始训练样本待标注集中随机选择一部分样本进行人工标注,将人工标注的样本构成初始训练集;其中,初始训练样本待标注集通过视频序列进行构建;
S2,利用初始训练集训练视觉跟踪模型,得到初步训练的跟踪模型;
S3,利用所述初步训练的跟踪模型对初始训练样本待标注集中未标注的样本进行处理,并根据所述初步训练的跟踪模型输出的响应图生成伪标签图片;
S4,根据所述伪标签图片和初步训练的跟踪模型输出的响应图,利用交叉熵损失函数,生成伪损失;
S5,依据所述伪损失,对初始训练样本待标注集中未标注的样本进行排序,选择损失较大的若干样本;
S6,以人在回路的方式对所选择的损失较大的若干样本进行人工标注,并将人工标注后的样本加入初始训练集,得到新的训练集;
S7,使用新的训练集重新训练所述视觉跟踪模型,训练完成后得到训练好的视觉跟踪模型。
优选的,S1中,所述视频序列中的样本应包含多种物体类别、尺度、姿态、光照以及遮挡情况;
S1和S6中,对样本进行人工标注时,标示出样本中目标物的位置和尺度。
优选的,S3中,据所述初步训练的跟踪模型输出的响应图生成伪标签图片的过程包括:
令响应图中与最大值距离不大于t的所有像素点的像素值为1,令响应图中其它部分像素点的像素值为0,得到伪标签图片;
其中,t=(0.1-0.3)h,h为响应图的边长。
优选的,S4中,伪损失通过下式计算:
loss=-∑(p*log(r)+(1-p)log(1-r))
上式中,loss为整个响应图的伪损失,r为响应图中的像素值,p为生成的伪标签图片中的标签值,∑()表示对响应图上所有点的损失进行求和,求和结果为整个响应图的伪损失。
优选的,S1中,从初始训练样本待标注集中随机选择一部分样本进行人工标注时,选择的样本数量为初始训练样本待标注集中样本数量的1%-5%;S6中,选择损失较大的若干样本时,选择的样本数量为初始训练样本待标注集中未标注的样本数量的1%-5%。
优选的,利用初始训练集训练视觉跟踪模型时,直到视觉跟踪模型收敛到局部最优解,得到初步训练的跟踪模型;
使用新的训练集重新训练所述视觉跟踪模型时,直到视觉跟踪模型收敛到局部最优解,得到训练好的视觉跟踪模型。
本发明针对视觉跟踪模型的人在回路训练方法还包括如下步骤:
S8,对S7得到的训练好的视觉跟踪模型按照S3-S7重复训练若干次,直到标注的样本数量达到预设的数量或者视觉跟踪模型的精度达到预设要求,则停止训练,得到最终的视觉跟踪模型。
本发明还提供了一种视觉跟踪模型训练装置,其特征在于,包括:
未标注的初始训练样本待标注集构建模块:用于利用视频序列构建未标注的初始训练样本待标注集;
第一训练集构建模块:用于从初始训练样本待标注集中随机选择一部分样本进行人工标注,将人工标注的样本构成初始训练集;
模型初步训练模块:用于利用初始训练集训练视觉跟踪模型,得到初步训练的跟踪模型;
伪标签生成模块:用于利用初步训练的跟踪模型对初始训练样本待标注集中未标注的样本进行处理,并根据初步训练的跟踪模型输出的响应图生成伪标签图片;
伪损失生成模块:用于根据伪标签图片和初步训练的跟踪模型输出的响应图,利用交叉熵损失函数,生成伪损失;
样本选择模块:用于依据伪损失,对初始训练样本待标注集中未标注的样本进行排序,选择损失较大的若干样本;
第二训练集构建模块:用于以人在回路的方式对所选择的损失较大的若干样本进行人工标注,并将人工标注后的样本加入初始训练集,得到新的训练集;
模型最终训练模块:用于使用新的训练集重新训练视觉跟踪模型,训练完成后得到训练好的视觉跟踪模型。
本发明还提供了一种电子设备,包括:
一个或多个处理器;
存储装置,其上存储有一个或多个程序;
当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现本发明如上所述的针对视觉跟踪模型的人在回路训练方法。
本发明还提供了一种存储介质,其上存储有计算机程序,其中,所述计算机程序被处理器执行时实现本发明如上所述的针对视觉跟踪模型的人在回路训练方法。
本发明具有如下有效果:
本发明通过人在回路标注方式,用少量的样本标注实现优秀的跟踪模型训练效果。在训练过程中,对未标注的样本生成伪标签,进而生成伪损失,根据伪损失的大小对无标签样本进行排序,从中选择损失较大的样本进行人在回路标注后,再送入视觉跟踪模型中进一步训练模型。通过此种筛选方法,可以从大量样本中选择少量有效的,富含较多信息的样本进行标注,节省了标注全部样本所耗费的时间和人力,同时也可以有效的去除样本中的冗余信息。
附图说明
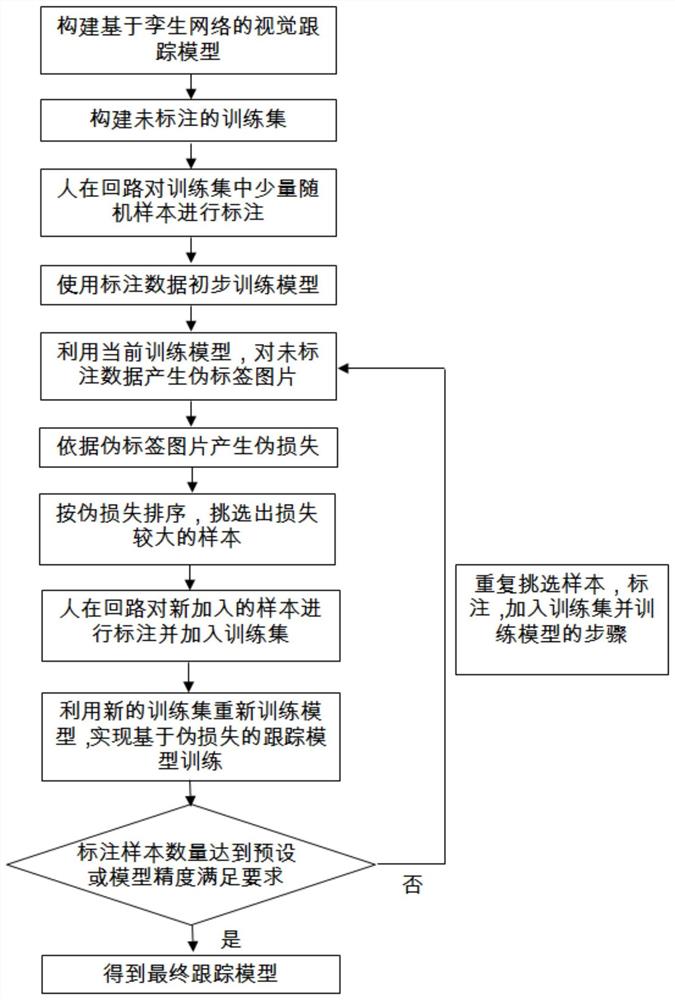
图1是本发明实施例针对视觉跟踪模型的人在回路训练方法流程图;
图2是本发明实施例中采用的基于残差网络结构的孪生网络跟踪模型结构图;
图3是本发明实施例中利用伪标签得到样本伪损失的流程图。
具体实施方式
下面结合附图和实例对本发明的具体实施方式作进一步详细描述。以下实施用于解释本发明,但不用来限制本发明的范围。
为解决现有基于深度模型的视觉目标跟踪算法训练数据量大,数据中冗余信息较多,以及由此造成的数据标注费时费力的问题,本发明在视觉跟踪模型的训练过程中,将大量的数据样本进行筛选,将少量有效的,富含信息较多的样本选出并进行人工标注,然后送入视觉跟踪模型中进行训练。其他的样本则无需标注,也不参与训练。由于删除的样本大都是无效的,其信息含量较低的或者信息冗余。所以经过筛选后的样本训练而得到的视觉跟踪模型,可以取得接近在完整数据集上训练的视觉跟踪模型的准确性。从而大大节省用于标注样本的时间和人力成本。
参照图1,本发明针对视觉跟踪模型的人在回路训练方法,包括以下步骤:
步骤1:构建基于深度孪生网络结构、ResNet结构和bottleneck结构的视觉跟踪模型;
步骤2:利用若干视频序列构建未标注的初始训练样本待标注集,该初始样本全都未经标注;
步骤3:针对步骤2中的初始训练样本待标注集,随机选择少量样本进行人工标注,并构成初始训练集,人在回路等待新的需要标注的样本;
步骤4:针对步骤3中标注后的初始训练集,使其用于训练步骤1的视觉跟踪模型,得到一个经过初步训练的跟踪模型;
步骤5:针对步骤3初始训练样本待标注集中剩余的未标注样本,将这些未标注的样本送入步骤4得到的经过初步训练的跟踪模型,根据视觉跟踪模型输出的响应图生成伪标签;
步骤6:根据伪标签和原始响应图(即步骤5中视觉跟踪模型输出的响应图),依据交叉熵损失函数,生成伪损失。
步骤7:将初始训练样本待标注集未标注的样本,依据步骤6生成的伪损失进行排序,选择损失较大的若干样本,以人在回路的方式对新选择的若干样本进行人工标注,加入上述初始训练集,对初始训练集进行更新,然后使用更新后的训练集重新训练视觉跟踪模型,得到最终的视觉跟踪模型。
所述步骤1中采用孪生网络结构实现视觉目标跟踪。所述孪生网络中有2条通路,1条用于提取模板特征,另1条用于提取搜索区域特征,两条通路共享一个网络参数。本发明中的视觉跟踪模型为了提取更加鲁棒的特征,特征网络中使用ResNet构架,包含了残差连接和bottleneck结构。
所述步骤2中,使用若干视频序列构建训练样本待标注集,这些视频序列中的样本应包含多种物体类别、尺度、姿态、光照、以及遮挡情况。同时,此阶段获得的数据还未经过人工标注,所以还无法直接用于深度跟踪模型的训练。
所述步骤3中,首先从步骤2所得的样本中随机的选择少量样本,然后对这些样本进行人工标注,标示出目标物的位置和尺度。这些已获得标注的样本构成初始训练集。
所述步骤4中,使用步骤3所得到的初始训练集,多次随机采样得到同一视频序列中的2个样本,使用这2个样本,对步骤1中的视觉跟踪模型进行初步的训练。2个样本1个送入孪生网络的模板通路,另1个送入搜索通路。通过多次随机采样和训练,从而得到一个经过初步训练的视觉跟踪模型。该视觉跟踪模型仅采用少量标注样本进行训练,具有初步的跟踪判别能力,但相比于采用全部标注数据训练得到的模型,跟踪效果较差。
所述步骤5中,需要将未标注的样本送入经过初始训练的网络中。孪生跟踪网络中存在2条通路,模板通路中送入的是步骤3中得到的已经标注的样本。将样本依据标注信息裁剪出目标,然后缩放成指定大小,送入孪生网络中的模板通路。同时,未标注的图像送入搜索通路。依据有标签的模板图像中物体的位置和尺度,将其扩大成搜索区域,依据搜索区域进行裁剪,然后缩放成指定大小,送入孪生网络中的搜索通路。两个图片应是来自于训练集中的同一视频中。孪生网络中的2个通路都用来提取特征,且两个通路共享权值。经过特征提取后的模板图片和搜索图片进行卷积,从而得到响应图。响应图中数值的大小对应目标在搜索图片中当前位置出现的概率。所以,响应图中的最大值,标示着目标最可能出现的位置。依据该最大值的位置,建立伪标签。响应图中最大值附近的值(与最大值的距离小于t,t=(0.1-0.3)h,h为响应图的边长),预示着目标的出现的概率较高,标签值为1,响应图中的其他部分,目标出现的概率很低,所以标签值为0。
所述步骤6中,利用步骤5中产生的响应图和伪标签,通过交叉熵计算损失。具有伪标签的样本的交叉熵的计算公式为:
loss=-∑(p·log(r)+(1-p)log(1-r))
上式中,loss为伪损失,r为响应图中的像素值,p为生成的伪标签图片中的标签值,∑()表示对响应图上所有点的损失进行求和,从而得到整个响应图的伪损失。通过此种伪标签计算得到的当前图片的损失称为伪损失。该损失标示了无标签数据中所含的信息量以及信息的混乱程度。如果未标注的图片中待跟踪的物体,利用步骤4获得的初始模型能够很好的实现跟踪,则步骤5中所获得的响应图中,在目标位置附近应该有较高的响应,同时在远离目标的位置有较低的响应,且响应图的变化应尽量平缓,波动较小。此类未标注样本的伪损失也较小,同时对模型的改善作用也很小。相反的,如果步骤4获得的模型无法良好的跟踪此未标注样本中的目标,那么步骤5获得的响应图应该表现的较为混乱,不满足目标附近响应大或远离目标响应小的特点,或者响应图变化剧烈,波动大。此类未标注的数据的伪损失也较大,同时对模型的改善作用也更大。
通过以上分析可得,伪损失较小的样本,产生的响应图足够准确、平缓、稳定和鲁棒,此类样本已经能够被模型准确的分类并判断,所以对模型性能的改善没有太大的影响。相反的,伪损失较大的样本,意味着孪生网络产生的响应图不够准确和稳定,或者变化幅度较为剧烈。此种响应图则说明步骤4所得的初步训练模型不能够很好的对当前样本进行跟踪和判别。所以,此样本包含了改善模型性能的关键和有效信息。本步骤中,将所有未标注样本都送入步骤4中的经过初步训练的跟踪模型中,并产生对应的伪损失。
步骤7中,将所有未标注的样本,按照步骤6中所得的伪损失进行排序。这些样本经过模型的筛选,包含更多的有效信息,对模型的改善也有着更好的效果。所以,将这些选出的少量样本推给等待在回路中的人,对其进行人工标注后,加入到步骤3所得的训练样本集中,构成新的、更加全面和丰富的训练样本。
以某一个视频的筛选过程为例,将该视频中所有未标注样本依据伪损失从大到小排序,从中挑选出1个伪损失最大的样本;考虑到视频序列中连续帧之间的样本存在着高度的相似性和冗余性,当该帧的伪损失最大时,当前帧的相邻帧内也会产生较大伪损失,且这些图片中包含的信息存在着高度的相似性和较大冗余。如果单纯的采用最大值策略选择多帧图片进行训练,则选择出的图片相似度很高,所含有的信息相似,且冗余较大,对模型的训练无法起到很好的改善效果,且有可能造成模型在该类数据上的过拟合问题。所以,最大伪损失样本被选出后,该帧的前后10帧图像将不参与以后的筛选,以防止选出相似和冗余的图片。经过此种处理,再从剩余的帧中选择伪损失最大的图片,并重复此过程,直到挑选出了特定数量的样本。
该训练集中标注样本的数量相比与整体样本的量依然非常少,但是已经包含了整体样本中大部分的有效信息,也舍弃了连续视频序列中的冗余信息,从而减少标注所耗费的时间和人力。通过使用此训练集再次训练步骤4所得的模型,由于包含更多信息的样本的引入,使得模型准确性得到了进一步的提高。同时,采用此种训练方法得到的模型,可以在少量标注样本的条件下,得到和全部标注样本训练的模型非常接近的跟踪效果。从而大大节省标注样本所用的时间和人力。
本发明首次提出在基于深度学习的视觉跟踪模型训练过程中,采用伪标签并生成伪损失对未标注样本进行排序的样本筛选方法,通过人在回路样本标注方法减少样本标注量。且筛选过程中,对于已经选出的具有较大伪损失的样本,将其前后的相近帧删除,再进行之后的筛选过程,在保证选择高质量,多信息样本的同时,避免了筛选出相似的,冗余的样本,从而以少量有效的样本,获得最好的跟踪效果。经过本发明中的基于伪损失的样本筛选方法,可以在总量仅为3%的标注样本情况下,达到99%的模型准确度,从而大大节省了标注训练样本所耗费的时间和人力。
实施例
如图1所示,本实施例的针对视觉跟踪模型的人在回路训练方法,包括以下步骤:
步骤1:采用孪生网络结构构建跟踪模型。该网络结构和运行流程如图2所示。网络中有两条通路,上方1条通路用于提取模板特征,下方1条用于提取搜索区域特征,两条通路采用同一种特征提取网络,共享同一套网络参数。经过特征提取后,将2条通路所得的特征进行卷积运算,从而得到最终的响应图。响应图中每个位置的数值,标示着搜索区域内目标物在此处的概率。为了提取更加鲁棒的特征,特征提取网络采用ResNet(ResidualNetwork)结构,包含残差连接(residual connection)和bottleneck结构,此网络中共有22个卷积层(convolution layer),一个最大池化层(max pooling layer),以及跨越不同层之间的残差连接。
步骤2:使用若干视频序列构建初始训练样本。该视频序列中的样本应包含多种物体类别、尺度、姿态、光照,以及遮挡情况。同时,此阶段获得的数据还未经过人工标注,即未明确标示出每张图片中目标物体的位置和大小,所以目前还不能直接用于有监督的深度跟踪模型的训练。
步骤3:从步骤2所得的样本中随机的选择少量样本(为总样本数量的1%),然后对这些少量样本进行人工标注,标示出目标物的位置和尺度。这些获得标注的样本构成初始训练集。标注工作尚未完成,人在回路等待新的需标注样本。
步骤4:使用步骤3所得到的初始训练集中的样本,采用随机采样的方式对步骤1所得的视觉跟踪模型进行训练。每次随机采样得到同一视频序列中的2个样本。其中1个样本按照标注信息进行裁剪,从而获得只包含模板物体的图片区域,然后将该图片缩放到127×127大小,并送入孪生网络的模板通路;另1个样本依据标注信息,将标注的目标框适当扩大后再进行裁剪,使得裁剪后的图片区域中心位置处为目标,目标周围有少量背景元素,然后将其缩放到255×255大小并送入搜索通路。之后,模板图片和搜索图片都经过特征提取阶段,模板经过特征提取得到一个5×5×512维度的特征,搜索图片经过特征提取得到一个21×21×512维度的特征。然后,以模板图像得到的特征作为卷积核与搜索图像得到的特征进行卷积,从而得到一个17×17大小的响应图。响应图每个位置的值预示着搜索图片中目标物在该位置的概率。
从初始训练集中多次随机选择样本,不断的训练模型,直到模型收敛到局部最优解。采用此种训练方法,可以得到一个初步的训练模型。该模型采用少量标注样本进行训练,具有初步的跟踪判别能力,但相比于采用全部标注数据训练得到的模型,跟踪效果还有一定差距。
步骤5:将未标注的样本送入经过初步训练的网络中。本步骤中,孪生网路的模板通路送入的是步骤3中得到的标注样本。同样的,将样本依据标注信息裁剪出目标,然后缩放成127×127,送入孪生网络中的模板通路。同时,未标注的样本送入搜索通路。依据有标注信息的模板图像中物体的位置和尺度,将其扩大成搜索区域,依据搜索区域进行裁剪图片,然后缩放成255×255,送入孪生网络中的搜索通路。获得响应图的过程和步骤4相同。送入孪生网络2条通路中的图片应来自训练集中的同一个视频。响应图中数值的大小对应目标在搜索图片中当前位置出现的概率。所以,响应图中的最大值,标示着目标最可能出现的位置。依据该最大值的位置,建立伪标签。响应图中最大值附近的值(与最大值的距离小于t,t=0.1h,h为响应图的边长),预示着目标出现的概率较高,标签值为1,响应图中的其他部分,目标出现的概率很低,所以标签值为0。响应图的获取和伪标签的产生如图3所示。
步骤6:利用步骤5中产生的响应图和伪标签,通过交叉熵计算响应图和伪标签的损失。交叉熵的计算公式为:
loss=-∑(p*log(r)+(1-p)log(1-r))
上式中,r为响应图中的像素值,p为生成的伪标签图片中的值。通过此种伪标签计算得到的当前图片的损失称为伪损失。该损失标示了当前无标签数据中所含的信息量以及信息的混乱程度。如果未标注的图片中待跟踪的物体,利用步骤4获得的初始模型能够很好的实现跟踪,则步骤5中所获得的响应图中,在目标附近应该有较高的响应,同时在远离目标的位置有较小的响应,且响应图的变化应尽量平缓,波动较小。此类未标注样本的伪损失也较小,同时对模型的改善作用也很小。相反的,如果步骤4获得的模型无法良好的跟踪此未标注样本,那么步骤5获得的响应图应该表现的较为混乱,不满足目标附近响应大或远离目标响应小的特点,也可能响应图变化剧烈,波动大。此类未标注的数据的伪损失也较大,同时对模型的改善作用也更大。
通过以上分析,可以发现伪损失较小的样本,产生的响应图足够准确,平缓,稳定和鲁棒,此类样本已经能够被模型准确的分类和判别,所以对模型性能的改善没有太大的影响。相反的,伪损失较大的样本,通过孪生网络产生的响应图不够准确和稳定,或者变化幅度较为剧烈。此种响应图意味着步骤4所得的初步模型不能够很好的对当前样本进行分类和判别。所以,此样本包含了改善模型性能的关键信息。本步骤中将所有未标注样本都送入步骤4中的初始模型中,并产生对应的伪损失。
步骤7:将所有未标注的样本,按照步骤6中所得的伪损失进行排序,并挑选出损失较大的少量样本(约为总样本量的2%),经过人在回路人工标注后,再加入训练集继续训练模型。这些样本经过模型的筛选,包含更多的有效信息,对模型的改善也有着更好的效果。
以某一个视频的筛选过程为例,将该视频中所有未标注样本依据伪损失从大到小排序,从中挑选出1个伪损失最大的样本;考虑到视频序列中连续帧之间的样本存在着高度的相似性和冗余性,当该帧的伪损失最大时,也就意味着当前帧前后附近的帧内也会产生较大伪损失,且这些图片中包含的信息存在着高度的相似性和较大冗余。如果单纯的采用最大值策略选择多帧图片进行训练,则选择出的图片相似度很高,所含有的信息相似,且冗余较大,对模型的训练无法起到很好的改善效果,且有可能造成模型在该类数据上的过拟合问题。所以,最大伪损失被选出后,该帧的前后10帧图像将不参与以后的筛选,以防止选出相似和冗余的图片。经过此种处理过程后,再从剩余的帧中选择伪损失最大的图片,并重复此过程,直到挑选出了特定数量的样本。
此后,将这些挑选出的少量样本进行人工标注,加入到步骤3所得的训练样本中,构成新的,更加全面和丰富的训练样本集。该训练集中标注样本的数量相比与整体的样本量依然非常少(不足总量的10%),但是已经包含了整体训练样本中大部分的有效信息,也舍弃了连续视频序列中的冗余信息。使用此训练集再次训练步骤4所得的模型,由于引入了包含更多信息的样本,使得的模型准确性得到了进一步的提高。同时,采用此种训练方法得到的模型,可以在少量标注样本的条件下,得到和全部样本训练的模型非常接近的跟踪效果(仅采用3%的数据,即可达到采用全部训练样本的99%的准确率),从而大大节省标注样本所用的时间和人力。
- 一种针对视觉跟踪模型的人在回路训练方法及相关装置
- 人脸识别模型训练方法及相关装置、人脸识别方法及相关装置