基于局部-整体图推理网络的视频-段落检索方法及系统
文献发布时间:2023-06-19 12:05:39
技术领域
本发明涉及跨模态检索领域,尤其一种基于局部-整体图推理网络的视频-段落检索方法及系统。
背景技术
作为在视频和段落之间的跨模态检索任务,视频-段落检索任务是一项非常重要的任务,吸引了众多研究者的关注。
该任务设计到计算机视觉和自然语言处理两个领域,需要系统对视频和文本都进行编码,然后根据编码计算相似度,进而进行检索。目前视频-段落检索任务仍然是一个新颖的任务,目前在该任务上的研究还不够成熟。
目前已有的视频-段落检索任务不是对整个视频和整个段落直接进行编码,就是仅仅考虑视频和段落的多个分段而直接进行编码。然后这样的编码方式都很难得到很好的效果,一方面由于神经网络对长序列编码能力较差,直接使用其对长序列进行编码导致编码性能变差,另一方面只考虑整体和片段丢失了很多的细粒度信息,这进一步限制了检索系统的性能。
综上所述,对于长文本和长视频之间的检索,目前的技术没有很好的利用细粒度信息,性能较差,难以满足实际应用需求。
发明内容
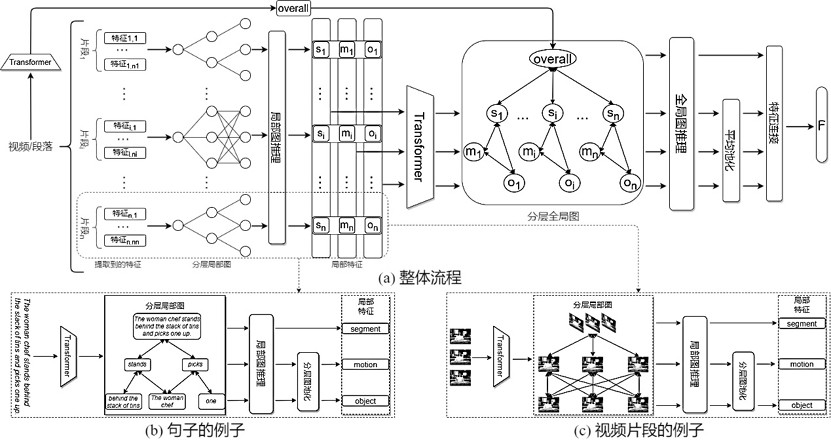
本发明的目的在于解决现有技术中的问题,为了克服长序列直接编码性能下降的问题同时学到更多细粒度的信息,本发明将视频和文本都分解为四个层次:总体级、片段层、动作层和物体层。同时在局部(视频片段/句子)和整体(视频/段落)构造成图使用图推理进行充分的语义交互。
为了实现上述目的,本发明所采用的具体技术方案是:
本发明的其中一个目的在于提供一种基于局部-整体图推理网络的视频-段落检索方法,包括以下步骤:
步骤1:将视频划分为片段,提取视频帧特征并编码得到视频整体层、视频片段层、视频动作层和视频物体层特征;将段落文本划分为句子,提取单词特征并编码得到段落整体层、段落句子层、段落动作层和段落物体层特征;编码过程采用第一编码器实现;
步骤2:对视频-段落分别构造视频分层局部图和段落分层局部图,确定图中各个节点的连接边;
步骤3:利用图卷积网络对视频分层局部图和段落分层局部图进行推理,计算局部图中各个连接边的边权重,更新局部图中的节点,得到更新后的分层局部图;
步骤4:对更新后的分层局部图进行分层池化,分别得到池化后的视频局部三层特征和段落局部三层特征;
步骤5:对视频-段落构造整体图:首先将经步骤4分层池化后的局部三层特征进行二次编码,利用二次编码后的片段层/句子层、动作层、物体层节点与初始编码后的整体层节点构造视频整体图和段落整体图,确定图中各个节点的连接边;所述的二次编码过程采用第二编码器实现;
步骤6:利用图卷积网络对视频整体图和段落整体图进行推理,利用步骤3中的方法更新整体中的节点,得到更新后的整体图;
步骤7:对更新后的整体图进行分层池化,分别得到池化后的视频全局四层特征和段落全局四层特征;分别对全局四层特征进行连接,得到视频和段落的最终特征表示;
步骤8:计算视频和段落间的余弦相似度,根据相似度度量结果对由第一编码器、第二编码器和图卷积网络构成的局部-整体图推理网络进行训练;
步骤9:利用训练好的局部-整体图推理网络实现视频-段落检索。
本发明的第二个目的在于提供一种基于局部-整体图推理网络的视频-段落检索系统,用于实现上述中的视频-段落检索方法,包括:
预处理模块,其用于将视频划分为片段,将段落文本划分为句子,并分别提取视频帧特征和文本单词特征;
局部图处理模块,其用于利用视频帧特征和文本单词特征构建视频分层局部图和段落分层局部图,得到视频局部三层特征和段落局部三层特征;
整体图处理模块,其用于利用局部三层特征与整体特征,构建视频整体图和段落整体图,得到视频全局四层特征和段落全局四层特征;
相似度计算模块,其用于连接全局四层特征,得到视频和段落的最终特征表示,并根据最终特征表示计算视频和段落间的余弦相似度,根据相似度度量值得到检索结果。
与现有技术相比,本发明的优势是:
(1)传统的对整个视频和段落直接编码的方式丢失了局部和细粒度的语义信息,且传统的对视频和段落的分段以及整体进行编码的方式则丢失了细粒度的语义信息,使得整体和局部难以进行充分的语义交互。本发明通过对视频和段落进行四个层次的分解,使用局部图推理可以更好的进行局部(句子和视频片段)内的语义交互,使用整体图推理可以进行整体(段落和视频)的语义交互,且四个层级的语义进行充分交互,获得的交互信息更加全面。
(2)传统的对视频和段落的分段以及整体进行编码的方式依然存在整体和局部的隔阂,使得整体与局部无法实现更优的互补。为了保证整体图推理和局部图推理可以更好地互补,本发明设计了基于图注意力的池化模块,并且在整体和局部之间利用Transformer模块进行编码,有效弥补了整体和局部之间的隔阂,取得了更优的技术效果。
附图说明
图1是本发明基于局部-整体图推理网络的视频-段落检索的示意图。
图2是本发明中的视频图推理和段落图推理的示意图。
图3是本发明实施例的从段落到视频的检索的实施效果图。
图4是本发明实施例的从视频到段落的检索的实施效果图。
具体实施方式
下面结合附图对本发明做进一步的说明。
本发明主要设计了四部分内容:首先对视频和文本(段落)进行预处理。其次,针对给定的视频和文本分别使用局部-整体图推理网络进行编码,得到最终的视频特征和文本特征。之后,使用余弦相似度计算视频特征和文本特征之间的相似度。最后,根据相似度度量结果进行检索。在局部-整体图推理网络中,本发明提出将视频和文本分别分解为四层语义结构,并且分别构造成局部图和整体图,进而使用图卷积网络进行图推理操作。
本发明的视频-段落检索流程的示意图参考图1所示,主要包括以下步骤:
步骤一:对视频-段落进行初始编码。
将视频划分为片段,提取视频帧特征并编码得到视频整体层、视频片段层、视频动作层和视频物体层特征;
将段落文本划分为句子,提取单词特征并编码得到段落整体层、段落句子层、段落动作层和段落物体层特征;
编码过程采用第一编码器实现;
步骤二:分层局部图推理。
首先,对视频-段落分别构造视频分层局部图和段落分层局部图,确定图中各个节点的连接边;
其次,利用图卷积网络对视频分层局部图和段落分层局部图进行推理,计算局部图中各个连接边的边权重,更新局部图中的节点,得到更新后的分层局部图;
之后,对更新后的分层局部图进行分层池化,分别得到池化后的视频局部三层特征和段落局部三层特征。
步骤三:整体图推理。
首先将经步骤4分层池化后的局部三层特征进行二次编码,利用二次编码后的片段层/句子层、动作层、物体层节点与初始编码后的整体层节点构造视频整体图和段落整体图,确定图中各个节点的连接边;所述的二次编码过程采用第二编码器实现;
其次,利用图卷积网络对视频整体图和段落整体图进行推理,计算整体图中各个连接边的边权重,更新整体图中的节点,得到更新后的整体图;
之后,对更新后的整体图进行分层池化,分别得到池化后的视频全局四层特征和段落全局四层特征;分别对全局四层特征进行连接,得到视频和段落的最终特征表示。
步骤四:利用相似度完整检索任务。
计算视频和段落间的余弦相似度,根据相似度度量值得到检索结果。在训练阶段,需要利用相似度度量结果对由第一编码器、第二编码器和图卷积网络构成的局部-整体图推理网络进行训练;训练好的局部-整体图推理网络可以直接用于进行检索任务。
下面对每一个步骤进行具体介绍。
本实施例中,步骤一为视频和段落的预处理步骤。
(1.1)将视频-段落划分成片段-句子。
针对一段由T帧构成的视频,将其划分为N个视频片段,其中第i个视频片段包含T
针对由L个单词构成的段落,将其划分为M个句子,第i个句子包含L
(1.2)提取初始特征。
将视频中每一帧的帧特征利用Transformer模型进行初始编码,得到编码后的每一个帧特征v
利用Transformer模型对每一个单词进行编码,得到编码后的每一个单词特征t
(1.3)初始特征聚合,得到视频-段落的整体层特征和片段/句子层特征。
对视频-段落相关特征向量基于自注意力机制进行聚合,聚合公式为:
其中,A为聚合结果,X为待聚合的特征向量,为激活函数,W
针对于视频,当X=Fv时,得到视频整体层特征A
针对于段落,当X=Ft时,得到段落整体层特征A
(1.4)确定视频-段落的动作层和物体层特征。
针对视频,根据视频片段特征向量Fc计算视频动作层特征和视频物体层特征,计算公式为:
其中,A
针对段落,标记每一个句子中的动词和名词短语,以及标记每一个名词短语所对应的动词,将每一个动词对应的单词特征t
经过步骤(1.1)至步骤(1.4),得到了编码后的视频整体层、视频片段层、视频动作层和视频物体层特征;以及编码后的段落整体层、段落句子层、段落动作层和段落物体层特征,将视频和段落划分成了初始的四层结构。
本实施例中,步骤二为分层局部图推理步骤。
(2.1)创建视频分层局部图和段落分层局部图中各节点的边。
针对视频,将每一个视频片段层特征作为一个段节点,将视频动作层特征中的每一帧特征作为一个动作节点,将视频物体层特征中的每一帧特征作为一个物体节点;将段节点与所属该视频片段的每一个动作节点相连,每一个动作节点与所属该视频片段的每一个物体节点相连;
针对段落,将每一个段落句子层特征作为一个段节点,将段落动作层特征中的每一个单词特征作为一个动作节点,将段落物体层特征中的每一个名词短语特征作为一个物体节点;将段节点与所属该句子的每一个动作节点相连,每一个动作节点与其相对应的物体节点相连。
(2.2)计算边权重,更新局部图中的节点。
边权重计算公式为:
节点更新公式为:
其中,x
(2.3)分层池化,获得视频局部三层特征和段落局部三层特征。
定义段节点特征、动作节点特征、物体节点特征分别对应与第一局部层特征、第二局部层特征、第三局部层特征。其中,将上一个步骤中得到的更新后的分层局部图中的段节点特征直接作为第一局部层特征,而动作节点特征、物体节点特征需要分别进行分层池化。
池化之前需要计算动作层注意力矩阵Am和物体层注意力矩阵Ao,为了既充分考虑图节点的特征,又充分考虑各节点之间的连接关系,因此在计算注意力权重矩阵时先再次使用步骤(2.2)中的图推理过程,也就是对更新后的分层局部图进行二次更新。这次图推理时图卷积的权重与第一次的不同,两者权重不共享,为了便于区分,我们将二次更新前的分层局部图节点表示为Xnode={node_s, node _m, node _o},二次更新后的分层局部图节点表示为Xatt={att_s, att_m, att_o};其中node_s和att_s分别为二次更新前后的段节点特征,node_m和att_m分别为二次更新前后的动作节点特征,node _o和att_o分别为二次更新前后的物体节点特征。
利用二次更新后的node _m和node _o分别计算动作层注意力矩阵A
其中,A
将二次更新前的段节点特征node_s直接作为第一局部层特征,表示为x_s,将池化后的动作节点特征和物体节点特征分别作为第二局部层特征x_m和第三局部级特征x_o,池化公式为:
其中,a
经过步骤二,获得了视频局部三层特征和段落局部三层特征,分别表示为第一局部层特征x_s=(s
本实施例中,步骤三为整体图推理步骤。
(3.1)创建视频整体图和段落整体图中各节点的边。
在创建整体图之前,需要将局部三层池化后的特征利用Transformer模型进行再次编码。
将视频和段落的整体层特征作为整体节点,与经再次编码后的段节点、动作节点、物体节点之间创建连接边;其中,对于每一个整体节点,其与对应的所有段节点连接,每一个段节点与其对应的动作节点和其对应的物体节点连接,而每一个动作节点与其对应的物体节点连接,节点的连接关系可参考图2所示。
(3.2)计算边权重,更新整体图中的节点。
该步骤与上述步骤(2.2)计算公式与过程相同,此处不再赘述。
(3.3)分层池化,获得视频全局四层特征和段落全局四层特征。
针对更新后的整体图,将整体节点直接作为全局第一层特征,将段节点、动作节点、物体节点的平均值分别作为全局第二层特征、全局第三层特征和全局第四层特征;
将视频的全局四层特征和段落的全局四层特征分别进行连接,得到视频最终特征表示v和段落最终特征表示p。
本实施例中,步骤四是利用相似度完整检索任务的步骤。
计算视频和段落间的余弦相似度,根据相似度度量值得到检索结果。在训练阶段,需要利用相似度度量结果对由第一编码器、第二编码器和图卷积网络构成的局部-整体图推理网络进行训练;训练好的局部-整体图推理网络可以直接用于进行检索任务。
局部-整体图推理网络采用三元组损失函数进行训练,损失函数为:
其中,
在训练过程中,整体推理和局部推理步骤分别使用的编码器、图卷积参数不共享,视频和段落使用的编码器、图卷积参数不共享,但是在整体推理过程中,单独针对视频执行的任务使用的编码器、图卷积参数共享,单独针对段落执行的任务使用的编码器、图卷积参数共享。在局部推理过程中,单独针对视频执行的任务使用的编码器、图卷积参数共享,单独针对段落执行的任务使用的编码器、图卷积参数共享。
与前述的基于局部-整体图推理网络的视频-段落检索方法的实施例相对应,本申请还提供了一种基于局部-整体图推理网络的视频-段落检索系统的实施例,其包括:
预处理模块,其用于将视频划分为片段,将段落文本划分为句子,并分别提取视频帧特征和文本单词特征;
局部图处理模块,其用于利用视频帧特征和文本单词特征构建视频分层局部图和段落分层局部图,得到视频局部三层特征和段落局部三层特征;
整体图处理模块,其用于利用局部三层特征与整体特征,构建视频整体图和段落整体图,得到视频全局四层特征和段落全局四层特征;
相似度计算模块,其用于连接全局四层特征,得到视频和段落的最终特征表示,并根据最终特征表示计算视频和段落间的余弦相似度,根据相似度度量值得到检索结果。
本实施例中,所述的局部图处理模块包括:
第一编码器,内置Transformer模型,其用于对视频-段落进行初始编码,针对视频,获得视频整体层、视频片段层、视频动作层和视频物体层特征;针对段落,获得段落整体层、段落句子层、段落动作层和段落物体层特征。
局部图创建模块,其用于确定片段层/句子层、动作层、物体层节点之间的连接边,获得初始视频分层局部图和段落分层局部图;
局部图卷积模块,内置局部图卷积网络模型,其用于计算分层局部图中连接边的权重值,并更新分层局部图;
局部分层池化模块,其用于对更新后的分层局部图进行分层池化,分别得到池化后的视频局部三层特征和段落局部三层特征;
本实施例中,所述的整体图处理模块包括:
第二编码器,内置Transformer模型,其用于对分层池化后的局部三层特征进行二次编码;
整体图创建模块,其用于利用二次编码后的片段层/句子层、动作层、物体层节点与初始编码后的整体层节点创建视频整体图和段落整体图;
整体图卷积模块,内置整体图卷积网络模型,其用于计算整体图中连接边的权重值,并更新整体图;
整体分层池化模块,对更新后的整体图进行分层池化,分别得到池化后的视频全局四层特征和段落全局四层特征。
关于上述实施例中的系统,其中各个单元或模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
对于系统实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的系统实施例仅仅是示意性的,其中所述作为局部图处理模块,可以是或者也可以不是物理上分开的。另外,在本发明中的各功能模块可以集成在一个处理单元中,也可以是各个模块单独物理存在,也可以两个或两个以上模块集成在一个单元中。上述集成的模块或单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现,以根据实际的需要选择其中的部分或者全部模块来实现本申请方案的目的。
为了验证本发明的效果,在多个图像翻译任务上进行了实验。实验如下:
本发明在ActivityNet-Captions数据集上进行了试验,本数据集是一个大规模多模态视频数据集,包括20k个来自YouTube的视频,有10,009个视频作为训练集4,917/4,885个视频构成两个验证集(两个验证集视频数据有大量重叠)。而每一个视频包含着多个片段(最多段数为26段),每一个片段对应着一个描述性的句子,每个视频对应的所有句子可以构成其对应的段落。
本实施例中,对于包含多个片段的视频,首先按照每个视频最多80帧提取视频整体级的帧,同时按照每个视频片段最多20帧提取视频片段级的帧。对于每一帧,使用TSN-Inception V3预训练模型提取出单帧的特征表达,得到维度为2048的特征。对每一个视频,得到视频特征向量和N个视频片段特征向量,T表示每个视频中提取到的帧的数目,T
对于包含多个句子的段落,使用“BERT-Base, Uncased”模型对其进行处理,使用 模型倒数第二层的特征表达,得到维度为1536的特征。对于每个段落,得到段落特征向量
本实施例使用PyTorch框架进行了实验,使用Adam优化器对模型进行了训练,将初始学习率设置为0.0001,在训练过程中学习率会逐渐降低;最大epoch设置为50,mini-batch大小设置为64。在损失函数中,设置边界值变量为0.2;上面提到的模型中使用的所有激活函数都是GELU函数。在对应的模态中,用于段级、运动级和对象级不同级别的局部池化特征所使用到的Transformer具有相同的权重。对于局部图推理,同一个模态的不同分段之间共享权值。在训练时,本实施例使用单卡的NVIDIA RTX2080Ti GPU,每个epoch大约花费2分钟。
模型训练结束后,在第一个验证集上测试了模型的性能。针对检索,本发明使用召回率Recall@K(R@K)作为评价指标,K值取1,5,50。在该指标中,召回率越大模型检索效果越好。本发明在ActivityNet-Captions数据集上进行实验,并且与现有技术HSE和COOT进行对比,模型效果如表1所示。
表1 本发明与技术一、二在ActivityNet-Captions数据集上的测试结果
正如表1所示,本发明在所有的度量指标上超越了之前的方法。在段落到视频一侧,本发明在R@1上超越之前的最佳结果(COOT)3.8%,在R@5上超越之前最佳结果3.1%,虽然在R@50上之前的结果已经达到了超过98%的性能,本发明依然超越了他们。同样,在视频到段落一侧,本发明在R@1上超越之前的最佳结果4.3%,在R@5上超越之前最佳结果2.9%,虽然在R@50上之前的结果已经达到了超过98%的性能,本发明也依然超越了他们。
本发明优秀的性能来源于对视频和段落层次的分解以及整体-局部图推理的应用。虽然HSE和COOT模型也采用了层次结构,COOT还进行了一定的全局和局部信息交互,但他们没有考虑到视频片段和句子本身具有层次结构,并且所有的结构都应该进行语义信息交互。
本发明还在ActivityNet-Captions数据集上给出了两个可视化的示例,其中图3和图4中的标记1表示本发明的模型,标记2为COOT模型,标记3为HSE模型。
如图3所示,从段落到视频的检索(根据给出的段落,检索出符合段落描述内容的视频片段)的排名分数来看,三个视频都是关于“南瓜”的场景,本发明的模型找到了最好的匹配段落,准确匹配视频。
如图4所示,从视频到段落的检索(根据给出的视频,检索出符合视频描述内容的句子)的排名分数来看,虽然三个句子都描述了关于“滑板”的场景,本发明的模型根据它们的细微差别检索出更为准确的结果,拉开了与其他两个模型的分数。
本发明不局限于上述具体实施方式,本领域的技术人员根据本发明公开的内容,可以采用多种其他实施方式,如将反馈解耦环节替换为前馈解耦环节、将两电平变流拓扑替换为三电平拓扑等。因而,权利要求书旨在涵盖本发明真正构思和范围内的所有变型。
- 基于局部-整体图推理网络的视频-段落检索方法及系统
- 基于局部-整体图推理网络的视频-段落检索方法及系统