数据分布自适应的跨区域尾气排放预测方法及系统
文献发布时间:2023-06-19 12:07:15
技术领域
本发明涉及环境检测技术领域,具体涉及一种数据分布自适应的跨区域尾气排放预测方法及系统。
背景技术
研究表明,在某个特定的时空区域内机动车排放尾气的量与该段区域内交通流的密集程度、道路的路况信息、天气的好坏程度以及相关联区域的污染物排放量等等密切相关。现有的方法大多基于已有的尾气测量数据对将来某一时刻的尾气排放量进行相应预测,这种方法适用于布满尾气监测站点且能有效提供尾气浓度的区域。然而并不是所有的监测站点都可以有效测量尾气浓度,例如路况信息监测站点以及空气质量指数(AQI)监测站点,对于具有这些站点的区域,不易直接获得具体的尾气浓度。因此,期望利用易监测地区的交通流情况、空气质量指数等相关数据并与尾气浓度结合,对不易直接获得尾气浓度的区域进行尾气浓度预测分析。
发明内容
本发明提出的一种数据分布自适应的跨区域尾气排放预测方法及系统,可解决现有方法在目标区域无尾气浓度数据但具有AQI等其他相关数据的情况下,区域尾气预测的技术问题。
为实现上述目的,本发明采用了以下技术方案:
一种数据分布自适应的跨区域尾气排放预测方法,包括以下步骤,
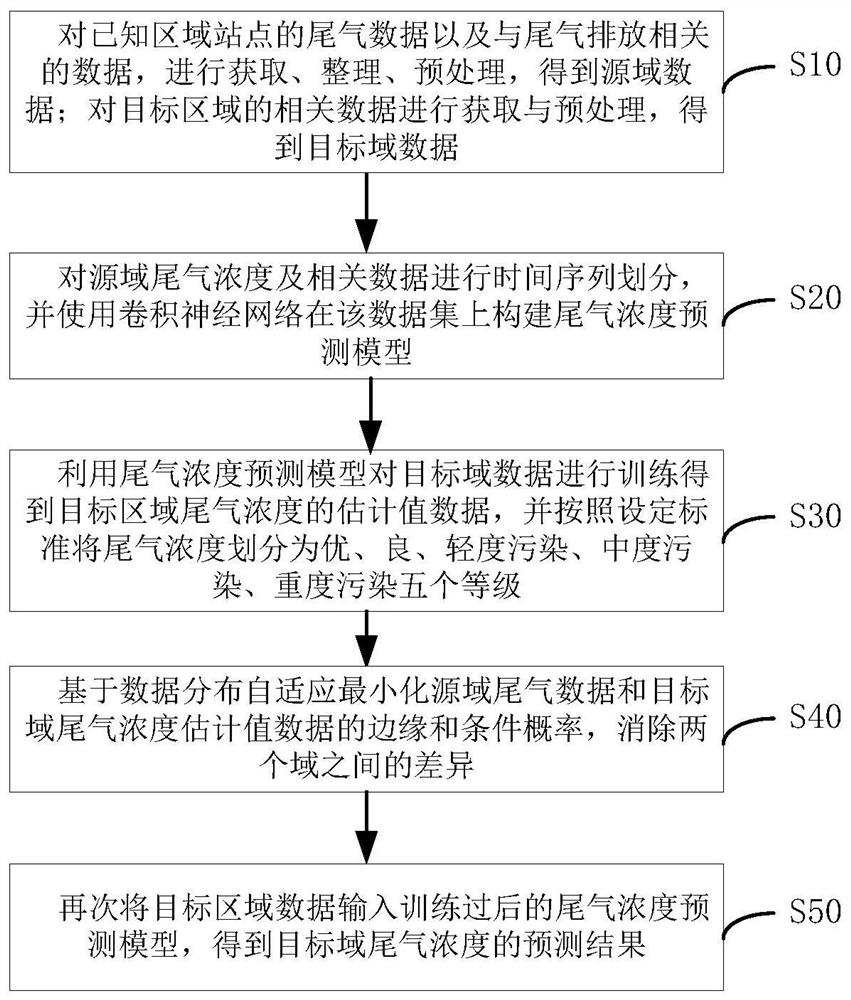
S10、对已知区域站点的尾气数据以及与尾气排放相关的数据,进行获取、整理、预处理,得到源域数据;对目标区域的相关数据进行获取与预处理,得到目标域数据;
S20、对源域尾气浓度及相关数据进行时间序列划分,并使用卷积神经网络在该数据集上构建尾气浓度预测模型;
S30、利用尾气浓度预测模型对目标域数据进行训练得到目标区域尾气浓度的估计值数据,并按照设定标准将尾气浓度划分为优、良、轻度污染、中度污染、重度污染五个等级;
S40、基于数据分布自适应最小化源域尾气数据和目标域尾气浓度估计值数据的边缘和条件概率,消除两个域之间的差异;
S50、再次将目标区域数据输入训练过后的尾气浓度预测模型,得到目标域尾气浓度的预测结果。
进一步的,所述S10对已知区域站点的尾气数据以及与尾气排放相关的数据,进行获取、整理、预处理,得到源域数据;对目标区域的相关数据进行获取与预处理,得到目标域数据,具体包括以下步骤:
S11:从指定官方网站分别获取源区域和目标区域的历史尾气数据以及与尾气浓度有关的外部因素数据,将同一时间段同一路段内各类污染物的最高浓度记为该路段特定时空下的尾气浓度;
S12:对源区域和目标区域的历史尾气数据进行插值,利用箱线图法对异常值进行识别并对其进行处理,零-均值规范化预处理操作,消除指标之间的量纲和取值范围差异的影响,将数据按照比例进行缩放,使之落入一个特定的区域。
进一步的,所述S20对源域尾气浓度及相关数据进行时间序列划分,并使用卷积神经网络在该数据集上构建尾气浓度预测模型,具体包括:
S21:将源域的尾气历史观测数据按照时间顺序以时间间隔Δt划分成观测数据序列;根据时间序列长度
S22:要使用卷积神经网络,需要提供二维的特征数据,将某段时间路段内尾气及其相关数据组织成二维数据,总共5行对应5个影响因子,10列对应尾气各主要成分浓度、总浓度,得到每天的上千组区域尾气分布图;
S23:随机选取数据集的80%作为训练集,使用卷积神经网络对训练集进行模型训练;神经网络使用Conv2D层和MaxPooling2D层的堆叠,使用均方损失函数MSE作为损失函数loss:
上式中,y
将数据集的剩余20%作为验证集,在训练的同时观察卷积神经网络在验证集上的表现,当验证集上的损失函数loss达到最小时,停止训练,得到适用于源域数据集的尾气预测模型。
进一步的,步骤S23中在训练过程中随机将部分神经元的权重置为0(dropout),即让一些神经元失效。
进一步的,所述S30利用尾气浓度预测模型对目标域数据进行训练得到目标区域尾气浓度的估计值数据,并按照设定标准将尾气浓度划分为优、良、轻度污染、中度污染、重度污染五个等级,具体包括:
S31:处理目标域中与尾气相关的数据,按照时间顺序以时间间隔Δt划分成观测数据序列;根据时间序列长度
S32:因尾气浓度定义为该时空条件下各类污染物浓度的最高值,将尾气按浓度与相对应的空气污染指数的关系进行划分,尾气浓度单位毫克/立方米,分为五个等级:(1)0-5记为“优”(Ⅰ级);(2)6-15记为“良好”(Ⅱ级);(3)16-60记为“轻度污染”(Ⅲ级);(4)61-100记为“中度污染”(Ⅳ级);(5)100以上记为“重度污染”(Ⅴ级),将源数据域上的尾气浓度数据与目标数据域的估计输出尾气浓度按照以上分类方法进行划分以便进行概率计算。
进一步的,所述S40基于数据分布自适应最小化源域尾气数据和目标域尾气浓度估计值数据的边缘和条件概率,消除两个域之间的差异,具体包括:
S41:对已经完成划分的源域尾气数据和目标域尾气数据估计值进行概率计算,记P(S)和P(T)是源域和目标域的边缘概率分布,设二维离散型随机变量(X,Y)的概率分布为P{X=x
记Q(S)和Q(T)是源数据域和目标数据域的条件分布概率:
S42:用最大均值差异MMD测量他们之间平均函数值之间的最大差值:
Distance(D
在条件概率下,公式表达为:
其中,n1,n2分别表示源域和目标域的样本个数;
应用于为估计值的目标数据域,则MMD表达为:
为了获得合理的f(·),引入核矩阵K:
以及一个MMD矩阵L,它的每个元素的计算公式为:
此时距离转变为tr(KL)-γtr(K),构造更低维度的矩阵W,使得:
TCA最后优化的目标变为:
s.t.W′KHKW=I
其中H是中心矩阵。
进一步的,所述步骤S11中源区域和目标区域的历史尾气数据以及与尾气浓度有关的外部因素数据包括天气因素、路况信息、交通流的密集程度。
另一方面,本发明还公开一种数据分布自适应的跨区域尾气排放预测系统,包括以下单元,
数据获取及处理单元,对已知区域站点的尾气数据以及与尾气排放相关的数据,进行获取、整理、预处理,得到源域数据;对目标区域的相关数据进行获取与预处理,得到目标域数据;
预测模型构建单元,用于对源域尾气浓度及相关数据进行时间序列划分,并使用卷积神经网络在该数据集上构建尾气浓度预测模型;
模型训练单元,用于利用尾气浓度预测模型对目标域数据进行训练得到目标区域尾气浓度的估计值数据,并按照设定标准将尾气浓度划分为优、良、轻度污染、中度污染、重度污染五个等级;
数据差异处理单元,用于基于数据分布自适应最小化源域尾气数据和目标域尾气浓度估计值数据的边缘和条件概率,消除两个域之间的差异;
预测单元,用于再次将目标区域数据输入训练过后的尾气浓度预测模型,得到目标域尾气浓度的预测结果。
第三方面,本发明还公开一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行如上述方法的步骤。
由上述技术方案可知,本发明的数据分布自适应的跨区域尾气排放预测方法、系统及存储介质,将基于域适应的跨域极限学习方法与传统方法相融合,该系统从已知区域内能获取尾气浓度以及AQI等数据的监测站点中提取数据,训练尾气预测模型,依据跨域极限学习机与域适应的方法,更好地将该模型迁移到只能获得AQI等相关数据而没有尾气数据的目标区域内,对目标区域的尾气浓度进行预测与分析。
本发明克服现有方法的不足,在已知区域站点监测数据上训练源域尾气预测模型,基于数据分布自适应尽可能地缩小源域和目标区域的差异,使训练模型能够更好地适用于不易直接获取尾气数据的目标区域,实现对目标区域的尾气浓度预测效果。
附图说明
图1是本发明的方法流程图;
图2是本发明的系统框图;
图3是本发明的尾气浓度预测热力图(a)源域(b)目标域。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
如图1所示,本实施例所述的数据分布自适应的跨区域尾气排放预测方法,包括以下步骤:
步骤1:对已知区域站点的尾气数据以及与尾气排放直接或间接有关的其他外部数据,进行获取、整理、预处理,得到源域数据。对目标区域(因环境、技术等问题无法直接获取尾气数据)的相关数据进行获取与预处理,得到目标域数据。
步骤2:对源域尾气浓度以及与尾气浓度有关的数据(如AQI等)进行时间序列划分,并使用卷积神经网络在该数据集上构建尾气浓度预测模型。
步骤3:利用尾气浓度预测模型对目标域数据进行训练得到目标区域尾气浓度的估计值数据,并按照国家环保局统一规定,将尾气浓度划分为优、良、轻度污染、中度污染、重度污染五个等级。
步骤4:基于数据分布自适应最小化源域尾气数据和目标域尾气浓度估计值数据的边缘和条件概率,有效地消除两个域之间的差异,使得学习的尾气浓度预测模型可以很好地在目标域数据上进行适应。
步骤5:再次将目标区域数据(AQI等)输入训练过后的尾气浓度预测模型,得到目标域尾气浓度的预测结果。
以下具体说明:
进一步地,上述步骤S1:对已知区域站点的尾气数据以及与尾气排放直接或间接有关的其他外部数据,进行获取、整理、预处理,得到源域数据。对目标区域(因环境、技术等问题无法直接获取尾气数据)的相关数据进行获取与预处理,得到目标域数据。具体包括如下细分步骤S11至S12:
S11:从政府官方网站分别获取源区域和目标区域的历史尾气数据以及与尾气浓度有关的外部因素数据,如天气因素、路况信息、交通流的密集程度等等,将同一时间段同一路段内各类污染物的最高浓度记为该路段特定时空下的尾气浓度。
S12:对源区域和目标区域的历史尾气数据进行插值,利用箱线图法对异常值进行识别并对其进行处理,零-均值规范化等预处理操作,消除指标之间的量纲和取值范围差异的影响,将数据按照比例进行缩放,使之落入一个特定的区域。
上述步骤S2:对源域尾气浓度以及与尾气浓度有关的数据(如AQI等)进行时间序列划分,并使用卷积神经网络在该数据集上构建尾气浓度预测模型。
具体包括如下细分步骤S21至S23:
S21:将源域的尾气历史观测数据按照时间顺序以时间间隔Δt划分成观测数据序列(其中Δt取1小时)。根据时间序列长度
S22:要使用卷积神经网络,需要提供二维的特征数据,将某段时间路段内尾气及其相关数据组织成类似于图片的二维数据,总共5行(对应5个影响因子如天气因素、路况信息、交通流的密集程度等等),10列(尾气各主要成分浓度、总浓度),得到每天的上千组区域尾气分布图。
S23:随机选取数据集的80%作为训练集,使用卷积神经网络对训练集进行模型训练。神经网络使用Conv2D层和MaxPooling2D层的堆叠,使用均方损失函数MSE作为损失函数loss:
上式中,y
上述步骤S3:利用尾气浓度预测模型对目标域数据进行训练得到目标区域尾气浓度的估计值数据,并按照国家环保局统一规定,将尾气浓度划分为优、良、轻度污染、中度污染、重度污染五个等级。具体包括如下细分步骤S31至S32:
S31:按同样的方法处理目标域中与尾气相关的数据(如AQI),按照时间顺序以时间间隔Δt划分成观测数据序列(其中Δt取1小时)。根据时间序列长度
S32:因尾气浓度定义为该时空条件下各类污染物浓度的最高值,因此可根据国家环保局统一规定,将尾气按浓度与相对应的空气污染指数(API)的关系进行划分,尾气浓度(毫克/立方米)分为五个等级:(1)0-5记为“优”(Ⅰ级);(2)6-15记为“良好”(Ⅱ级);(3)16-60记为“轻度污染”(Ⅲ级);(4)61-100记为“中度污染”(Ⅳ级);(5)100以上记为“重度污染”(Ⅴ级),将源数据域上的尾气浓度数据与目标数据域的估计输出尾气浓度按照以上分类方法进行划分以便进行概率计算。
上述步骤S4:基于数据分布自适应,最小化源域尾气数据和目标域尾气浓度估计值数据的边缘和条件概率,有效地消除两个域之间的差异,使得学习的尾气浓度预测模型可以很好地在目标域数据上进行适应。具体包括如下细分步骤S41至S42:
S41:对已经完成划分的源域尾气数据和目标域尾气数据估计值进行概率计算,记P(S)和P(T)是源域和目标域的边缘概率分布,设二维离散型随机变量(X,Y)的概率分布为P{X=x
记Q(S)和Q(T)是源数据域和目标数据域的条件分布概率:
S42:为完成数据分布自适应进行迁移学习,需要尽可能缩短源域数据和目标域数据的距离,来减少两个域之间的差异。用最大均值差异MMD测量他们之间平均函数值之间的最大差值:
Distance(D
在条件概率下,公式可表达为:
其中,n1,n2分别表示源域和目标域的样本个数,
应用于为估计值的目标数据域,则MMD可以表达为:
为了获得合理的f(·),引入核矩阵K:
以及一个MMD矩阵L,它的每个元素的计算公式为:
此时距离转变为tr(KL)-γtr(K),构造更低维度的矩阵W,使得:
综上可知,TCA最后优化的目标变为:
s.t.W′KHKW=I
其中H是中心矩阵。
上述步骤S5:再次将目标区域数据(AQI等)输入训练过后的尾气浓度预测模型,得到目标域尾气浓度的预测结果。具体包括如下步骤:通过最小化源域和目标域的距离,两域已足够接近,此时源域尾气数据集上训练的模型(AQI→尾气浓度)可以很好地适用于目标域数据集。将目标域上的数据(与尾气浓度相关的数据,如AQI等)输入步骤2中使用卷积神经网络构建的尾气浓度预测模型,得到目标区域的尾气浓度预测值;测试结果如图3所示。
综上所述,在已知区域站点监测数据上训练源域尾气预测模型,基于数据分布自适应尽可能地缩小源域和目标区域的差异,使训练模型能够更好地适用于不易直接获取尾气数据的目标区域,实现对目标区域的尾气浓度预测效果。
另一方面,本发明还公开一种数据分布自适应的跨区域尾气排放预测系统,包括以下单元,
数据获取及处理单元,对已知区域站点的尾气数据以及与尾气排放相关的数据,进行获取、整理、预处理,得到源域数据;对目标区域的相关数据进行获取与预处理,得到目标域数据;
预测模型构建单元,用于对源域尾气浓度及相关数据进行时间序列划分,并使用卷积神经网络在该数据集上构建尾气浓度预测模型;
模型训练单元,用于利用尾气浓度预测模型对目标域数据进行训练得到目标区域尾气浓度的估计值数据,并按照设定标准将尾气浓度划分为优、良、轻度污染、中度污染、重度污染五个等级;
数据差异处理单元,用于基于数据分布自适应最小化源域尾气数据和目标域尾气浓度估计值数据的边缘和条件概率,消除两个域之间的差异;
预测单元,用于再次将目标区域数据输入训练过后的尾气浓度预测模型,得到目标域尾气浓度的预测结果。
第三方面,本发明还公开一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行如上述方法的步骤。
可理解的是,本发明实施例提供的系统与本发明实施例提供的方法相对应,相关内容的解释、举例和有益效果可以参考上述方法中的相应部分。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 数据分布自适应的跨区域尾气排放预测方法及系统
- 基于子图分割的跨城市尾气迁移预测方法、系统及介质