一种基于深度强化学习的网络自主智能管控方法
文献发布时间:2023-06-19 12:24:27
技术领域
本发明属于人工智能技术领域,具体的说是涉及一种基于深度强化学习的网络自主智能管控方法。
背景技术
近年来,随着网络规模的扩大、应用种类的增多,为业务制定智能化的路由策略,是实现业务服务质量保障和网络自主智能管控的重要一环。软件定义网络(SoftwareDefined Network,SDN)的出现为网络自主智能化路由部署带来了新的思路。区别于传统网络紧密耦合的垂直结构,SDN将数据平面和控制平面分离,数据平面由支持OpenFlow协议的SDN交换机实现,控制平面由软件实现,提供网络的可编程性。控制平面对整个网络具有完整的全局视图,能够根据网络状态动态配置业务流的转发路由,从而更高效地进行网络资源的调配。控制平面在向下层的数据平面下发控制策略的同时,向上层的应用平面提供开放应用程序可编程接口,使得运营商可以简单快速地完成动态、自动化的网络应用开发,而不被运维复杂的问题所困扰。整个SDN网络架构形成闭环,为部署业务智能路由方案提供了保障。
随着人工智能技术的发展,机器学习算法已经渗透到包括网络业务路由在内的各个领域。在基于强化学习的智能路由策略中,智能体能够在SDN网络环境中学习路由策略,以最大限度地提高奖励。但是,在SDN网络中使用传统的Q学习算法可能需要巨大的存储空间来维护Q表,同时Q表的查询也会带来额外的时间开销。深度Q网络(Deep Q Network,DQN)方法可以同时结合深度学习的感知能力与强化学习的决策能力来优化路由过程,然而它受限于离散的状态和动作空间,不适合动态的SDN网络系统。基于策略的强化学习方法,如确定性策略梯度(Deterministic Policy Gradient,DPG),可以用来处理连续动作空间,但它们使用线性函数作为策略函数,存在训练数据相关性引起的过拟合问题。而深度确定性策略梯度算法(DDPG,Deep Deterministic Policy Gradient)使用演员评论家(Actor-Critic,AC)框架结合DQN方法和DPG方法,利用神经网络生成策略函数和Q函数,可以形成高效稳定的连续动作控制模型。
发明内容
本发明的发明目的在于:通过深度强化学习技术,由智能体自主对网络中的历史数据完成感知和学习,寻找满足业务流传输需求的路由,提高网络资源的综合利用率,实现网络的自主智能管控。
本发明的基于深度强化学习的网络自主智能管控方法的技术方案为:
构建实时的网络全局视图,对承载业务的数据平面的网络状态进行感知,获取网络中节点对之间不同类型业务流的业务传输需求情况、网络中链路的实时流量负载和连接关系,以及业务流的端到端传输时延和丢包率。
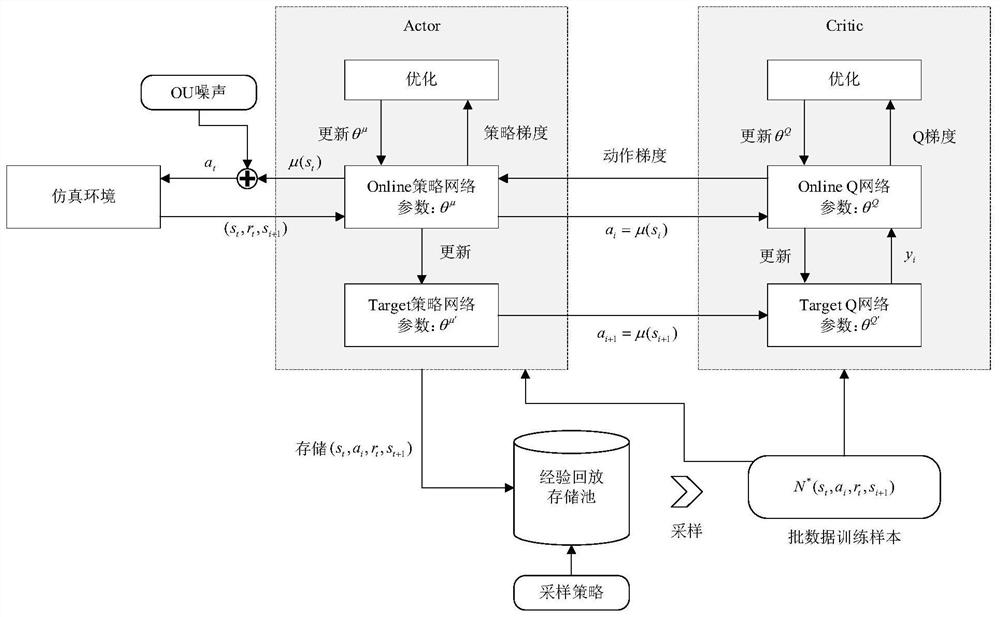
构建基于DDPG强化学习算法的路由决策模型。定义用于强化学习的网络状态、路由决策动作和业务奖励,并构建用于动作决策的Actor网络及其目标网络,以及用于评估动作质量的Critic网络及其目标网络。
使用基于深度强化学习算法的路由决策模型进行迭代训练。在每次迭代训练中,智能体将实时网络状态输入到Actor网络获得一组链路权重,并根据链路权重使用Dijkstra算法计算出总权重最小的路径作为业务的路由。根据路由计算结果,智能体下发流表,并根据新的路由结果,获取业务按照新的路由方案传输的端到端时延和丢包率,并根据其计算业务奖励值,反馈到智能体。每次迭代的过程信息,即网络状态、路由决策动作和业务奖励值都会被存储到经验回放存储池中。在进行一定轮数的迭代后,从经验回放存储池中,取出过程信息,对神经网络进行训练,使得Critic网络对状态-动作对Q值的判断更加准确,并使得Actor网络朝着有更高可能获取高奖励值的方向修改自身参数。通过这种方式,使得智能体能够通过不断迭代优化提高网络的奖励值,即优化业务的平均端到端时延和丢包率。
本发明通过上述方法,使得智能体对网络状态进行自主学习,并制定路由策略,提高了网络资源利用率,实现了网络的自主智能管控。
在构建基于DDPG强化学习算法的路由决策模型时,具体包含下列步骤:
S1、定义网络状态s=[T
S2、定义路由决策动作
S3、定义业务奖励值
S4、构建用于动作决策的Actor网络,其输入为网络状态s,输出为路由决策动作a。神经网络结构均依次包括输入层、CNN层、LSTM层、Dropout层、全连接层和输出端。初始化Actor网络的动作决策函数μ(s,θ
S5、构建Actor网络的目标网络,输入输出和神经网络结构设置与Actor网络相同。初始化Actor目标网络的动作决策函数μ′(s,θ
S6、构建用于评估动作质量的Critic网络,其输入为网络状态s和路由决策动作a,输出为状态-动作对的质量Q。神经网络结构均依次包括输入层、CNN层、LSTM层、Dropout层、全连接层和输出端。初始化Critic网络的动作评价函数Q(s,a|θ
S7、构建Critic网络的目标网络,输入输出和神经网络结构设置与Actor网络相同。初始化Critic目标网络的动作评价函数Q′(s,a|θ
S8、构建用于进行训练的经验回放存储池R。
在使用基于深度强化学习算法的路由决策模型进行迭代训练时,具体包含下列步骤:
S1、初始化当前迭代轮数episodes=0,总迭代轮数M,开始迭代训练,具体为:
S11、初始化当前时间步长t=0,总时间步长T,开始一轮迭代,具体为:
S111、初始化噪声O
S112、根据网络状态和Actor网络得到路由决策动作a
S113、从网络环境中获得业务奖励值r
S114、设置当前时间步长t=t+1,判断t≤T是否成立,若是,则转入S111。否则,则转入S12。
S12、将一轮迭代完整的过程样本(s
S121、从经验回放存储池R中采集N个完整的过程样本
S122、使用Actor和Critic目标网络计算每个样本的目标价值:
S123、使用反向传播方法更新Critic网络权重:
S124、使用反向传播方法更新Actor网络权重:
S125、使用软更新的方法更新Actor和Critic的目标网络:θ
S13、设置当前迭代轮数episodes=episodes+1,判断episodes≤M是否成立,若是,则转入S11。否则,则转入S2。
S2、神经网络训练结束,将神经网络权重以文件形式进行保存,即可直接进行线上使用。
本发明的有益效果是:
(1)智能体可以自主地从网络状态中学习知识,实现网络自主智能管控。
根据学习到的知识,可以指定智能化的路由策略,实现网络性能的自主优化
附图说明
图1为实施例的实验拓扑。
图2为实施例中,DDPG算法的执行流程。
图3为实施例中,DDPG算法的神经网络模型结构。
图4为实施例中,智能体的归一化奖励值的变化曲线。
图5为实施例中,业务不同路由算法的性能对比。
具体实施方式
下面结合附图和实施例对本发明进行补充描述。
实施例
本实施例使用ONOS作为网络控制器。通过Mininet(由一些虚拟的终端节点、交换机、路由器连接而成的一个网络仿真器)模拟SDN网络环境,使用Mininet的拓扑构建API生成了如图1所示的实验拓扑。
该拓扑由24个交换机节点和37条双向链路构成,每个交换机默认连接一个终端主机,编号与交换机相同。链路的带宽、时延、抖动和丢包率这四项性能参数通过Mininet的TCLink类进行配置。每条链路的额定带宽设置为10Mbps,链路时延范围为10~100ms,时延抖动范围为0~20ms,丢包率范围为0~2%。
本实施例中,DDPG智能体的运行流程如图2所示,具体包含下列步骤:
S1、初始化当前迭代轮数episodes=0,总迭代轮数M,开始迭代训练,具体为:
S11、初始化当前时间步长t=0,总时间步长T,开始一轮迭代,具体为:
S111、初始化噪声O
S112、根据网络状态和Actor网络得到路由决策动作a
S113、从网络环境中获得业务奖励值r
S114、设置当前时间步长t=t+1,判断t≤T是否成立,若是,则转入S111。否则,则转入S12。
S12、将一轮迭代完整的过程样本(s
S13、从经验回放存储池R中采集N个完整的过程样本
S122、使用Actor和Critic目标网络计算每个样本的目标价值:
S123、使用反向传播方法更新Critic网络权重:
S124、使用反向传播方法更新Actor网络权重:
S125、使用软更新的方法更新Actor和Critic的目标网络:θ
S13、设置当前迭代轮数episodes=episodes+1,判断episodes≤M是否成立,若是,则转入S11。否则,则转入S2。
本实施例中,DDPG智能体的神经网络结构设置如图2所示,参数设置如表1所示。
表1 DDPG智能体参数设置
本实施例设置6种不同的流量发送速率进行测试,分别是20Mbps、40Mbps、60Mbps、80Mbps、100Mbps和125Mbps。每种流量速率下,按照速率1:1的比例分配两种不同类型的业务,分别以时延和丢包率作为效用奖励。对于每种类型的业务,使用随机重力模型生成100组流量矩阵并在仿真环境中进行发送,并对结果取平均值。除了最小跳数算法以外,本文还实现了两种算法作为参照对象,分别是以时延作为路径权重进行最短路径计算的最短时延算法,和以最小化路径中的最大链路利用率为目标进行路由选择的负载均衡算法。对于每种类型的业务,分别使用最小跳数算法、最短时延算法、负载均衡算法和基于深度强化学习的智能路由算法进行业务的路由规划,并对四种算法的端到端时延和丢包率进行对比。
训练过程的归一化奖励值变化曲线如图4所示。整个训练过程中,奖励值稳定上升,在大约600轮训练后趋于稳定,算法表现出良好的收敛性。
不同路由算法下的平均端到端时延和业务丢包率的对比如图5所示。在流量发送速率较小的情况下,最小跳数和负载均衡算法不能较好地利用网络资源;随着流量发送速率的增加,最小跳数和最短时延算法易造成链路拥塞,带来性能的急剧恶化。而基于深度强化学习的智能路由算法通过不断迭代训练,自发性地持续进行优化,能够根据不同的网络状态,选择合适的路由策略,在不同的流量发送速率下均取得了较好的性能。
综上,本发明基于深度强化学习算法,使得智能体能够自主地从网络中学习知识并制定路由策略,从而提高网络资源利用率,优化网络综合性能。
- 一种基于深度强化学习的网络自主智能管控方法
- 一种基于深度强化学习的智能体自主导航方法