一种AI驱动的实时点云视频传输方法及系统
文献发布时间:2023-06-19 13:43:30
技术领域
本发明涉及点云视频流传输领域,具体来说,涉及一种AI驱动的实时点云视频传输方法及系统。
背景技术
点云是描述体积媒体和全息视频的一种典型且受欢迎的数据格式,它可以由带深度传感器的RGB-D相机捕获。它允许用户体验六个自由度的运动场景,并可以改变其中的位置和方向,像传统的虚拟现实(Vitual Reality,简称VR)视频中只有三个自由度。体积媒体提供了多个角度的3D场景,被广泛应用于各个领域,包括教育、医疗、和娱乐等。
目前,即使包括5G在内的现有网络环境中传输密集的点云流非常具有挑战性,原因包括:(1)传输大量的点云视频需要极高的带宽,即使经过传统的压缩,也可能达到吉比特每秒(Gbps)的水平,超过了当前5G网络的能力;(2)3D体积媒体的计算开销很大,因为只能使用软件编解码器,低效率的编解码器也会减慢传输速度;(3)传统的技术例如自适应比特率视频流(Adaptive Bitrate Streaming,简称ABR)的速率自适应和缓冲控制不适用于3D体积媒体,需要探索提供体积媒体的先进技术。
目前大多数现有的点云视频传输技术可以通过传统压缩(包括提供有损和无损压缩)来实现,减少需要传输的数据规模,但仍然存在诸多不足之处,如:一方面,点云视频的无损压缩技术仍然不足以实现高效传输和较好的用户体验。另一方面,在网络条件有限的情况下,有损压缩很难保证恢复的点云真实性与实际的原始视频相匹配。其他的点云视频传输技术,例如扩展当前VR视频流的技术,在数据块层次上进行传输,这些方法的移动能耗高,接收设备上的处理延迟往往也是不可接受的。另外,每个传输块都容易受到网络波动和重组过程中各种数据包丢失的影响。
综上所述,传统技术的传输能力远远不能满足实时点云视频流的带宽要求。因此,有必要探索一种先进的传输方案,以保证在现有网络下的提供良好的服务。
发明内容
针对相关技术中的问题,本发明提出一种AI驱动的实时点云视频传输方法及系统,可以显著降低点云视频流的传输量和能耗。该系统避免了传统传输方案中繁琐的多重处理,设计并训练了从原始数据采集到最终渲染和播放的端到端深度学习网络。
本发明的技术方案是这样实现的:
根据本发明的一个方面,提供了一种AI驱动的实时点云视频传输方法。
该AI驱动的实时点云视频传输方法,包括:
利用AI生成设备获取视频数据信息,并对该视频数据信息进行处理,得到点云视频数据;
对点云视频数据进行分层特征提取,确定点云视频帧中的关键点云特征,并传输该关键点云特征;
接收的关键点云特征,并对接收的关键点云特征进行扩展与重构,获得与原始输入点云相似的点云信息,形成视觉效果上的原始点云视频。
其中,利用AI生成设备获取视频数据信息,并对该视频数据信息进行处理,得到点云视频数据包括:利用多个不同角度的深度摄像机扫描需要传输的3D模型,并获取每个深度摄像机的点云流;并将从多视角摄像机汇集的多个点云拼接出一个完整的点云,得到点云视频数据;
此外,该AI驱动的实时点云视频传输方法还包括:
将预先搭建好的深度神经网络,在线下使用大量包含各种规模的3D模型组成的训练集进行训练,训练得到多个候选神经网络模型;
训练好的每个神经网络模型拆分成分层特征提取模块和基于生成对抗网络的点云恢复重建模块;并分别部署到靠近输入端的高性能边缘服务器和用户终端设备上;
在将分层特征提取模块和基于生成对抗网络的点云恢复重建模块部署到高性能边缘服务器和用户终端设备的同时,部署自适应匹配器,促使自适应匹配器根据实时监测到的网络带宽变化自适应地匹配满足当前网络的实时点云视频帧特征提取与重建恢复的神经网络模型。
进一步的,所述分层特征提取模块包含三个串联的集合抽象层次进行分层特征学习,来捕捉原始点云的局部结构;所述集合抽象层由三个基本层组成,包括采样层、 分组层和迷你PointNet层;
其中,采样层,从上一层的输出中使用最远点采样技术选择一个子集,子集中的每个点表示一个局部区域的中心;分组层,在局部区域中心的周围找到n个最近邻点,组合构造成局部区域集合;迷你PointNet层,采用3个二维卷积层和1个最大池化层将局部区域集合变换为特征向量;最后一个集合抽象层的迷你PointNet层输出的特征向量即为所要传输的数据。
进一步的,所述点云恢复重建模块包括点云特征扩展部分以及最终点集的生成部分,其中,点云特征扩展部分,用于在收到传输过来的关键点云特征,通过一个多层感知器来统一特征的维度;并通过一个向上-向下-向上的扩展单元,产生更多样化的点云数目和特征维度;最终点集生成部分,包含两个多层感知器层,并通过该两个多层感知器层将扩展后的点云特征重构为三维坐标形式。
另外,对点云视频数据进行分层特征提取,确定点云视频帧中的关键点云特征包括:通过部署到靠近输入端的高性能边缘服务器的分层特征提取模块,对点云视频数据进行分层特征提取,确定点云视频帧中的关键点云特征。
此外,对接收的关键点云特征进行扩展与重构,获得与原始输入点云相似的点云信息,形成视觉效果上的原始点云视频包括:通过部署到靠近输入端的用户终端设备上的基于生成对抗网络的点云恢复重建模块,对关键点云特征进行扩展与重构,获得与原始输入点云相似的点云信息,形成视觉效果上的原始点云视频。
根据本发明的另一个方面,提供了一种AI驱动的实时点云视频传输系统。
该AI驱动的实时点云视频传输系统包括:
点云视频数据获取模块,用于利用AI生成设备获取视频数据信息,并对该视频数据信息进行处理,得到点云视频数据;
关键点云特征提取模块,用于对点云视频数据进行分层特征提取,确定点云视频帧中的关键点云特征,并传输该关键点云特征;
点云恢复重建模块,用于接收的关键点云特征,并对接收的关键点云特征进行扩展与重构,获得与原始输入点云相似的点云信息,形成视觉效果上的原始点云视频。
其中,所述点云视频数据获取模块在利用AI生成设备获取视频数据信息,并对该视频数据信息进行处理,得到点云视频数据时,利用多个不同角度的深度摄像机扫描需要传输的3D模型,并获取每个深度摄像机的点云流;并将从多视角摄像机汇集的多个点云拼接出一个完整的点云,得到点云视频数据
此外,该AI驱动的实时点云视频传输系统还包括:
神经网络训练模块,用于将预先搭建好的深度神经网络,在线下使用大量包含各种规模的3D模型组成的训练集进行训练,训练得到多个候选神经网络模型;
神经网络部署模块,用于训练好的每个神经网络模型拆分成分层特征提取模块和基于生成对抗网络的点云恢复重建模块;并分别部署到靠近输入端的高性能边缘服务器和用户终端设备上;
神经网络匹配模块,用于在将分层特征提取模块和基于生成对抗网络的点云恢复重建模块部署到高性能边缘服务器和用户终端设备的同时,部署自适应匹配器,促使自适应匹配器根据实时监测到的网络带宽变化自适应地匹配满足当前网络的实时点云视频帧特征提取与重建恢复的神经网络模型。
进一步的,所述分层特征提取模块包含三个串联的集合抽象层次进行分层特征学习,来捕捉原始点云的局部结构;所述集合抽象层由三个基本层组成,包括采样层、 分组层和迷你PointNet层;
其中,采样层,从上一层的输出中使用最远点采样技术选择一个子集,子集中的每个点表示一个局部区域的中心;分组层,在局部区域中心的周围找到n个最近邻点,组合构造成局部区域集合;迷你PointNet层,采用3个二维卷积层和1个最大池化层将局部区域集合变换为特征向量;最后一个集合抽象层的迷你PointNet层输出的特征向量即为所要传输的数据。
进一步的,所述点云恢复重建模块包括点云特征扩展部分以及最终点集的生成部分,其中,点云特征扩展部分,用于在收到传输过来的关键点云特征,通过一个多层感知器来统一特征的维度;并通过一个向上-向下-向上的扩展单元,产生更多样化的点云数目和特征维度;最终点集生成部分,包含两个多层感知器层,用于通过该两个多层感知器层将扩展后的点云特征重构为三维坐标形式。
此外,所述关键点云特征提取模块在对点云视频数据进行分层特征提取,确定点云视频帧中的关键点云特征时,通过部署到靠近输入端的高性能边缘服务器的分层特征提取模块,对点云视频数据进行分层特征提取,确定点云视频帧中的关键点云特征。
另外,所述点云恢复重建模块在对接收的关键点云特征进行扩展与重构,获得与原始输入点云相似的点云信息,形成视觉效果上的原始点云视频时,通过部署到靠近输入端的用户终端设备上的基于生成对抗网络的点云恢复重建模块,对关键点云特征进行扩展与重构,获得与原始输入点云相似的点云信息,形成视觉效果上的原始点云视频。
有益效果:
本发明通过将原始需要传输的点云视频流进行特征提取,只传输部分关键点云特征,最后在接收端进行恢复重建,达到视觉上传输的是原始点云视频的效果,可以显著降低点云视频流的传输量和能耗。避免了传统传输方案中繁琐的多重处理,大大减少了数据传输量,使其更适合于现有的网络环境。本发明还考虑了网络环境的动态性和不稳定性,将其纳入到端到端网络设计和训练中,提供了自适应传输控制算法来平衡传输时延和重建准确率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是根据本发明实施例的一种AI驱动的实时点云视频传输的流程示意图;
图2是根据本发明实施例的一种AI驱动的实时点云视频传输系统的结构示意框图;
图3是根据本发明实施例的一种AI驱动的实时点云视频传输方法的原理示意图;
图4是根据本发明实施例的深度神经网络模型结构设计示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
根据本发明的实施例,提供了一种AI驱动的实时点云视频传输方法。
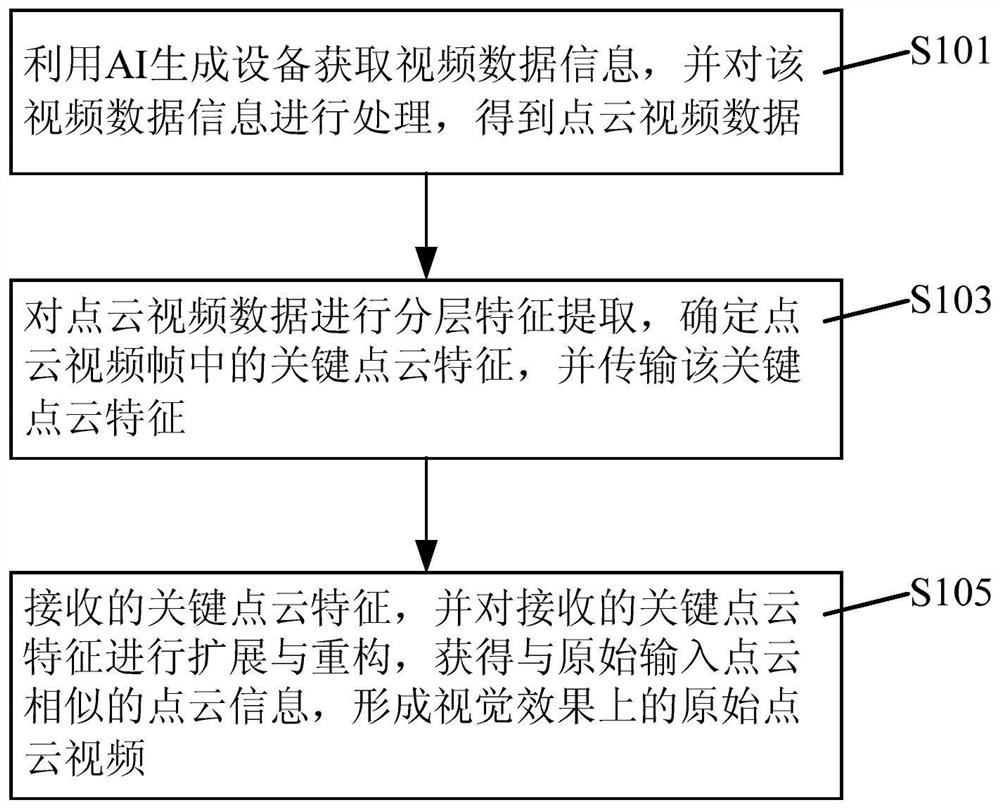
如图1所示,根据本发明实施例的AI驱动的实时点云视频传输方法包括:
步骤S101,利用AI生成设备获取视频数据信息,并对该视频数据信息进行处理,得到点云视频数据;
步骤S103,对点云视频数据进行分层特征提取,确定点云视频帧中的关键点云特征,并传输该关键点云特征;
步骤S105,接收的关键点云特征,并对接收的关键点云特征进行扩展与重构,获得与原始输入点云相似的点云信息,形成视觉效果上的原始点云视频。
其中,利用AI生成设备获取视频数据信息,并对该视频数据信息进行处理,得到点云视频数据包括:利用多个不同角度的深度摄像机扫描需要传输的3D模型,并获取每个深度摄像机的点云流;并将从多视角摄像机汇集的多个点云拼接出一个完整的点云,得到点云视频数据;
此外,该AI驱动的实时点云视频传输方法还包括:
将预先搭建好的深度神经网络,在线下使用大量包含各种规模的3D模型组成的训练集进行训练,训练得到多个候选神经网络模型;
训练好的每个神经网络模型拆分成分层特征提取模块和基于生成对抗网络的点云恢复重建模块;并分别部署到靠近输入端的高性能边缘服务器和用户终端设备上;
在将分层特征提取模块和基于生成对抗网络的点云恢复重建模块部署到高性能边缘服务器和用户终端设备的同时,部署自适应匹配器,促使自适应匹配器根据实时监测到的网络带宽变化自适应地匹配满足当前网络的实时点云视频帧特征提取与重建恢复的神经网络模型。
进一步的,所述分层特征提取模块包含三个串联的集合抽象层次进行分层特征学习,来捕捉原始点云的局部结构;所述集合抽象层由三个基本层组成,包括采样层、 分组层和迷你PointNet层;
其中,采样层,从上一层的输出中使用最远点采样技术选择一个子集,子集中的每个点表示一个局部区域的中心;分组层,在局部区域中心的周围找到n个最近邻点,组合构造成局部区域集合;迷你PointNet层,采用3个二维卷积层和1个最大池化层将局部区域集合变换为特征向量;最后一个集合抽象层的迷你PointNet层输出的特征向量即为所要传输的数据。
进一步的,所述点云恢复重建模块包括点云特征扩展部分以及最终点集的生成部分,其中,点云特征扩展部分,用于在收到传输过来的关键点云特征,通过一个多层感知器来统一特征的维度;并通过一个向上-向下-向上的扩展单元,产生更多样化的点云数目和特征维度;最终点集生成部分,包含两个多层感知器层,并通过该两个多层感知器层将扩展后的点云特征重构为三维坐标形式。
另外,对点云视频数据进行分层特征提取,确定点云视频帧中的关键点云特征包括:通过部署到靠近输入端的高性能边缘服务器的分层特征提取模块,对点云视频数据进行分层特征提取,确定点云视频帧中的关键点云特征。
此外,对接收的关键点云特征进行扩展与重构,获得与原始输入点云相似的点云信息,形成视觉效果上的原始点云视频包括:通过部署到靠近输入端的用户终端设备上的基于生成对抗网络的点云恢复重建模块,对关键点云特征进行扩展与重构,获得与原始输入点云相似的点云信息,形成视觉效果上的原始点云视频。
据本发明的实施例,提供了一种AI驱动的实时点云视频传输系统。
如图2所示,根据本发明实施例的AI驱动的实时点云视频传输系统包括:
点云视频数据获取模块201,用于利用AI生成设备获取视频数据信息,并对该视频数据信息进行处理,得到点云视频数据;
关键点云特征提取模块203,用于对点云视频数据进行分层特征提取,确定点云视频帧中的关键点云特征,并传输该关键点云特征;
点云恢复重建模块205,用于接收的关键点云特征,并对接收的关键点云特征进行扩展与重构,获得与原始输入点云相似的点云信息,形成视觉效果上的原始点云视频。
其中,所述点云视频数据获取模块201在利用AI生成设备获取视频数据信息,并对该视频数据信息进行处理,得到点云视频数据时,利用多个不同角度的深度摄像机扫描需要传输的3D模型,并获取每个深度摄像机的点云流;并将从多视角摄像机汇集的多个点云拼接出一个完整的点云,得到点云视频数据
此外,该AI驱动的实时点云视频传输系统还包括:神经网络训练模块(图中未示出),用于将预先搭建好的深度神经网络,在线下使用大量包含各种规模的3D模型组成的训练集进行训练,训练得到多个候选神经网络模型;神经网络部署模块(图中未示出),用于训练好的每个神经网络模型拆分成分层特征提取模块和基于生成对抗网络的点云恢复重建模块;并分别部署到靠近输入端的高性能边缘服务器和用户终端设备上;神经网络匹配模块(图中未示出),用于在将分层特征提取模块和基于生成对抗网络的点云恢复重建模块部署到高性能边缘服务器和用户终端设备的同时,部署自适应匹配器,促使自适应匹配器根据实时监测到的网络带宽变化自适应地匹配满足当前网络的实时点云视频帧特征提取与重建恢复的神经网络模型。
所述分层特征提取模块包含三个串联的集合抽象层次进行分层特征学习,来捕捉原始点云的局部结构;所述集合抽象层由三个基本层组成,包括采样层、 分组层和迷你PointNet层;
其中,采样层,从上一层的输出中使用最远点采样技术选择一个子集,子集中的每个点表示一个局部区域的中心;分组层,在局部区域中心的周围找到n个最近邻点,组合构造成局部区域集合;迷你PointNet层,采用3个二维卷积层和1个最大池化层将局部区域集合变换为特征向量;最后一个集合抽象层的迷你PointNet层输出的特征向量即为所要传输的数据。
所述点云恢复重建模块包括点云特征扩展部分以及最终点集的生成部分,其中,点云特征扩展部分,用于在收到传输过来的关键点云特征,通过一个多层感知器来统一特征的维度;并通过一个向上-向下-向上的扩展单元,产生更多样化的点云数目和特征维度;最终点集生成部分,包含两个多层感知器层,用于通过该两个多层感知器层将扩展后的点云特征重构为三维坐标形式。
此外,所述关键点云特征提取模块203在对点云视频数据进行分层特征提取,确定点云视频帧中的关键点云特征时,通过部署到靠近输入端的高性能边缘服务器的分层特征提取模块,对点云视频数据进行分层特征提取,确定点云视频帧中的关键点云特征。
另外,所述点云恢复重建模块205在对接收的关键点云特征进行扩展与重构,获得与原始输入点云相似的点云信息,形成视觉效果上的原始点云视频时,通过部署到靠近输入端的用户终端设备上的基于生成对抗网络的点云恢复重建模块,对关键点云特征进行扩展与重构,获得与原始输入点云相似的点云信息,形成视觉效果上的原始点云视频。
而为了方便更清楚的理解本发明的上述技术方案,以下从工作原理的角度对本发明的上述技术方案进行详细说明。
图3是本发明的原理示意图,从图3中可以看出,本发明的方法如下:
(1)多视角摄像机。系统使用多个放置在不同角度的深度摄像机来捕获原始点云,并使用USB线进行预处理,将每个摄像机的点云流同步到高性能边缘服务器进行拼接。
(2)点云特征提取和点云信息恢复重建。关键点云特征提取即本发明提供的分层特征提取模块,对拼接后的点云进行关键特征提取;基于生成对抗网络的点云信息恢复重建即本发明提供的点云重建恢复模块,将接收的点云特征恢复重建。
(3)自适应匹配器。用于感知所连接终端的网络状况,选择最优的传输推理模型,以保持通信的平稳运行,提高用户体验。
(4)基站。该系统可以在当前网络环境下提供实时点云传输,利用现有基站将关键点云特征通过无线传输到各种终端。
(5)用户终端。该系统可应用于多种终端,应用场景广泛。例如,智能手机上实现实时全息通信。更身临其境的体验例如使用AR眼镜或AR耳机渲染点云,用户可以身临其境地在点云视频中进行交互。
图4是深度神经网络模型结构设计示意图,从图4中可以看出,深度神经网络模型结构包括分层特征提取模块和点云恢复重建模块,具体包括:
(1)分层特征提取模块。用于对输入点云进行学习,提取部分关键点云的特征进行传输。具体地,该模块基于多个集合抽象层次进行分层特征学习,捕捉原始点云的局部结构。其中,每个集合抽象层由三个基本层组成,包括采样层,分组层和迷你PointNet层。
采样层用于从上一层的输出中选择一个子集,表示局部区域的中心;分组层用于在中心周围找到n个最近邻点来构造局部区域集合,迷你PointNet用于采用3个二维卷积层和1个最大池化层将局部区域集合变换为特征向量。
(2)点云恢复重建模块。用于对接收端接收的关键点云特征进行恢复重建。具体地,该模块使用对抗生成网络中的部分生成思想,相比于整个生成对抗网络具有更少的参数和计算量,便于在资源受限的终端上部署。包括一个点云特征扩展部分和最终点集生成部分。
点云特征扩展部分,首先收到传输过来的点云特征矩阵,通过一个多层感知器层来统一特征的维度。然后通过一个向上-向下-向上的扩展单元,产生更多样化的点云数目和特征维度。
最终点集生成部分,通过两个多层感知器层将扩展后的特征重构为三维坐标形式。
在实际运用时,通过深度神经网络中的分层特征提取模块对原始数据进行点云特征提取时,具体实施方案可如下所示:
(1)训练阶段
a、在训练集中的每个点云模型的表面随机选择200个点作为种子坐标,以每个种子坐标为中心,使用最远点采样技术,寻找其周围的256个点,使得这256个点构成的区域大约占据模型表面的5%,种子坐标和这256个点定义为一个碎片,并将碎片内的点集坐标归一化到一个单位球中。在本实施例中,输入到神经网络中的每个样本即为一个碎片,其包含256个点,每个点具有三维坐标,输入可表示为(256,3)。
b、将(256,3)的输入样本输入到采样层,具体步骤为,使用最远点采样技术,选择128个点,得到稀疏点集,表示为(128,3)。其中选择使用最远点采样技术的原因是其相比于随机采样,可以更好地覆盖整个点集,具体选择中心点的数量,由人为指定,在本实施例中指定为128。
c、将稀疏点集(128,3)的信息输入到分组层,具体步骤为,以128个点为中心,使用球查询方法生成128个局部区域,每个区域内包含32个点,球半径为0.2,得到分组特征,表示为(128,32,3)。其中每个区域中点的数量和球的半径,由人为指定,在本实施例中指定为32和0.2。此步骤也可通过K近邻方法实现,两者对于结果的影响不大。
d、将分组特征(128,32,3)的信息输入到迷你PointNet层,具体步骤为,分组特征(128,32,3)先后经过三个二维卷积层和一个最大池化层,输出分层特征信息(128,64)。其中,在本实施例中,三个二维卷积层的输出通道数目为64,64,64,卷积核大小为1×1,步长为1×1,无填充。
e、将分层特征信息(128,64)再输入到采样层,具体步骤为,使用最远点采样技术,选择64个点,输出稀疏点集特征(64,64)。其中具体选择中心点的数量,由人为指定,在本实施例中指定为64。
f、将稀疏点集特征(64,64)的信息再输入到分组层,具体步骤为,以64个点为中心,使用球查询方法生成64个局部区域,每个区域内包含64个点,球半径为0.3,得到分组特征,表示为(64,64,64)。其中每个区域中点的数量和球的半径,由人为指定,在本实施例中指定为64和0.3。此步骤也可通过K近邻方法实现。
g、将分组特征(64,64,64)的信息输入到迷你PointNet层,具体步骤为,分组特征(64,64,64)先后经过三个二维卷积层和一个最大池化层,输出分层特征信息(64,32)。其中,在本实施例中,三个二维卷积层的输出通道数目为64,64,32,卷积核大小为1×1,步长为1×1,无填充。
h、将分层特征信息(64,32)再输入到采样层,具体步骤为,使用最远点采样技术,选择N个点,得到稀疏点集特征(N,32)。其中具体选择中心点的数量N是一个变量。
i、将稀疏点集特征(N,32)的信息输入到分组层,具体步骤为,以N个点为中心,使用球查询方法生成N个局部区域,每个区域内包含64个点,半径为0.4,得到分组特征,表示为(N,64,32)。其中每个区域中点的数量和球的半径,由人为指定,在本实施例中指定为64和0.3。N是一个变量。此步骤也可通过K近邻方法实现。
j、将分组特征(N,64,32)的信息输入到迷你PointNet层,具体步骤为,分组特征(N,64,32)先后经过三个二维卷积层和一个最大池化层,得到分层点云特征信息(N,M)。其中,在本实施例中,三个二维卷积层的输出通道数目为32,32,M,卷积核大小为1×1,步长为1×1,无填充。
对于分层特征提取模块,采样层,分组层和迷你PointNet层为一个集合抽象层次,步骤b-d为集合抽象层次1,e-g为集合抽象层次2,h-j为集合抽象层次3。其中集合抽象层次的数量由人为指定,本实施例中指定为3,最后一个抽象层次的输出为点云特征(N,M)。将所有的训练样本输入到深度神经网络中,经过步骤b-j,前向传播和反向传播,计算损失函数,更新网络的权重,训练出神经网络模型。将N和M设置成不同的组合,即可训练出若干个候选模型。
(2)推理阶段
a、在要传输的视频帧中的目标物体中的表面随机选择若干个点作为种子坐标,以每个种子坐标为中心,使用最远点采样技术,寻找其周围的256个点,形成一个碎片,并将碎片内的点集坐标归一化到一个单位球中。其中种子数量由人为指定,在本发明中指定为目标点云数量除以256。
b、根据网络波动情况,选择最优推理模型。
c、以碎片为单位输入最优推理模型,进行前向推理,得到最终需要传输的点云特征。
在实际运用时,通过点云恢复重建模块对点云特征进行点云信息重建时,具体实施方案可如下所示:
(1)训练阶段
a、点云特征(N,M),经过一个二维卷积层,得到统一维度的点云特征(N,128)。该层的作用使得,即使通过不同的推理模型压缩的关键点云特征,经过此层也能输出相同维度的特征数目。其中,二维卷积层的输出通道数目为128,卷积核大小为1×1,步长为1×1,无填充。
b、统一维度的点云特征,表示为
将特征(N,128)复制r次后得到(rN,128),r为采样倍率,等于256/N。
采用2D网格机制,给每个特征生成一个唯一的二维向量,并将该向量附加到同一个特征中的对应的每个点的特征向量上,得到特征(rN,128+2)。
使用自注意单元和两个二维卷积层生成上采样后的点云特征
c、对点云特征
将点云特征
使用两个二维卷积层生成点云特征
d、将点云特征
e、对点云特征
f、将点云特征
g、将点云特征
对于点云恢复重建模块,步骤c-f为向上-向下-向上扩展单元,步骤g为最终点集生成部分。将所有的传输得到的点云特征样本输入到深度神经网络中,经过步骤a-g,前向传播和反向传播,计算损失函数,更新网络的权重,训练出神经网络模型。
(2)推理阶段
a、根据网络波动情况,选择最优推理模型。
b、将所有的传输得到的点云特征样本输入到深度神经网络中,经过步骤A-G,进行前向推理,得到恢复重建出的碎片点云信息。
c、将所有的碎片重建信息加在一起,使用最远点采样技术,选择出与原始输入点云数量相同的点,重建出最终的点云。
借助于本发明的上述技术方案,本发明通过将原始需要传输的点云视频流进行特征提取,只传输部分关键点云特征,最后在接收端进行恢复重建,达到视觉上传输的是原始点云视频的效果。
在运行时,本发明是完全使用AI作为驱动的,即使用深度神经网络来自动实现特征提取和重建目标,直接将原始点云坐标作为输入,不需要其他操作,包括信息预处理,人为地获取点云的几何分布情况,属性重要度信息,选择编解码方式等步骤,只需要对该深度神经网络进行训练后部署到实际应用便可,并且本发明中的深度神经网络分开便是特征提取和重建两个过程。
本发明的系统为端到端训练的神经网络,包括特征提取和重建,即只要有数据输入便可进行训练,更加智能化,无需关注内部具体操作,还可以根据网络状况,选择合适的推理模型,给用户更好的体验。
同时,本发明可以在精度损失可接受的情况下达到30.72倍的高倍压缩比,在现有的5G以下环境下,实现实时传输,大大减少了传输数据量。
综上所述,本发明可以显著降低点云视频流的传输量和能耗。避免了传统传输方案中繁琐的多重处理,大大减少了数据传输量,使其更适合于现有的网络环境,本发明还考虑了网络环境的动态性和不稳定性,将其纳入到端到端网络设计和训练中,提供了自适应传输控制算法来平衡传输时延和重建准确率
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种AI驱动的实时点云视频传输方法及系统
- 一种AI前端化的变电站巡检视频实时识别方法及系统