基于层次语义结构的跨模态哈希检索方法
文献发布时间:2023-06-19 13:45:04
技术领域
本发明涉及计算机技术领域,更进一步涉及信息检索技术领域的一种基于层次语义结构的跨模态哈希检索方法。本发明可应用于图像、文本两种模态数据的信息检索,实现具有层次标签数据的模态内部及模态间的快速检索。
背景技术
随着信息技术的快速发展,网络上出现了包括图像、文本、音频、视频等在内的各种多媒体数据,这些多媒体数据中包含着丰富的可利用信息。从海量多媒体数据中查找有用信息的方法之一就是进行跨模态信息检索。这些多媒体数据通常都具有数据量大,维数较高等特点,为了能够实现对多媒体数据进行快速准确的检索,需要采用哈希方法对数据进行降维、编码,使用二进制哈希码可以大大降低存储成本和查询时间成本,提高检索性能。当前的跨模态检索哈希检索的研究热点是细粒度跨模态检索。细粒度跨模态检索的对象更加细致,类间差异更加细微,往往只能借助于微小的局部差异才能区分出不同的类别。据此实现细粒度跨模态检索的方法之一就是利用标签的层次结构。在实际应用中,数据的多个标签往往存在着由粗粒度到细粒度的层次结构。比如在电商中,一件衣服可以被标记为:衣服—上衣—衬衫。现有的方法处理多标签数据时,判断两个数据是否相似简单地根据其是否共享至少一个标签,这样显然忽略了标签的层次结构,从而导致检索精度不足。因此,如何有效的利用标签的层次结构,将标签的细粒度和粗粒度互补来提高检索精度是层次化跨模态检索的研究关键。
Changchang Sun等人在其发表的论文“Supervised Hierarchical Cross-ModalHashing”(Proceedings ofthe 42nd International ACM SIGIR Conference onResearch andDevelopment in Information Retrieval,2019,pp.725–734.)中提出了一种监督的层次化跨模态哈希检索方法。该方法通过分层判别学习和正则化的跨模态哈希来为多媒体数据的每一层语义信息学习一组哈希码;最后利用不同层次的哈希码来计算汉明距离,选择距离最近的若干个哈希码对应的多媒体数据,作为检索结果输出。该方法存在的不足之处是,在学习哈希码的过程中保留了数据的同层内的语义相似性信息,忽略了不同层之间的语义关联,使得学习到的哈希码缺乏标签的层次信息,导致图像文本检索精度不高。
山东大学在其申请的专利文献“利用标签层次信息的多媒体数据跨模态检索方法及系统”(申请号:202010771701.0,申请公布号:CN 111930972A)中提出了利用标签层次信息的多媒体数据跨模态检索哈希方法。该方法首先获取待检索的第一模态多媒体数据,对待检索的第一模态多媒体数据进行特征提取。其中,图像数据利用预先训练好的卷积神经网络CNN进行特征提取,文本数据利用预先训练好的多层感知器MLP模型进行特征提取;然后利用标签和类哈希码将类别信息先整合到提取的特征中,然后将特征直接映射到二进制哈希码中;最后将第一模态哈希码与预存储的第二模态的所有多媒体数据对应的已知哈希码进行距离计算;选择距离最近的若干个哈希码对应的第二模态的多媒体数据,作为检索结果输出。该方法存在的不足之处是,将标签信息先融合到图像特征和文本特征中,再将图像特征和文本特征中高精度的值直接映射到值为{-1,1}的二进制哈希码,造成部分语义信息损失的问题。
发明内容
本发明的目的在于针对上述现有技术的不足,提出一种基于层次语义结构的跨模态哈希检索方法。用于解决目前提出的跨模态哈希检索方法在处理具有层次标签数据的时候,没有充分保持层间的关联信息以及将标签的语义信息融合到了特征中而导致损失了部分语义信息的问题。
实现本发明的技术思路是,通过将所有图像文本对标签中每层的所有类别的类哈希码用标签扩展为对应层次的层次语义结构,再将各层的层次语义结构融合到哈希码中,使得图像文本对的哈希码保持了标签的同层与层间的关联信息,解决现有跨模态哈希检索方法忽略数据标签层间的语义关联导致标签信息不全面的问题。本发明将图像文本对的层次语义结构和标签语义信息直接映射到了图像文本对的哈希码中,将层次语义结构和标签的语义信息很大程度地保留到了哈希码中,使得学习到的哈希码具有更丰富的语义信息,解决了当前技术中直接将标签信息融合到图像特征和文本特征中导致哈希码损失了部分语义信息的问题。
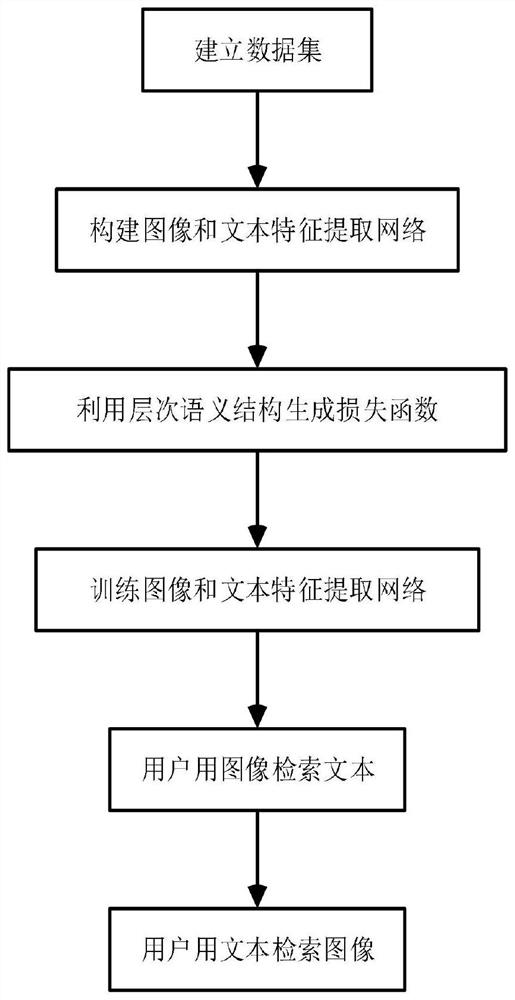
实现本发明的具体步骤包括如下:
步骤1,建立训练集:
(1a)选取至少500个自然图像数据样本与其对应的文本数据样本组成图像文本对样本集,对每个图像文本对中的图像和文本样本分别从粗粒度到细粒度进行人工分层标注;
(1b)将标注后的每个图像文本对中的图像样本裁剪成224×224像素值的图像;
(1c)利用词袋模型,将标注后的每个图像文本对中的文本样本转化成同样长度的0-1词袋向量;
(1d)将裁剪后的所有图像样本与其对应的文本的词袋向量,组成图像文本对训练集;
步骤2,构建图像和文本特征提取网络:
(2a)构建一个12层的图像特征提取网络,其结构依次为:输入层,第一卷积层,第一最大池化层,第二卷积层,第二最大池化层,第三卷积层,第四卷积层,第五卷积层,第三最大池化层,第一全连接层,第二全连接层,第三全连接层,第四全连接层,输出层;设置图像特征提取网络的各层参数如下:将第一至第五卷积层的卷积核大小分别设置为:11×11×3×64、5×5×64×256、3×3×256×256、3×3×256×256、3×3×256×256,步长分别设置为:4、1、1、1、1;将第一至第四全连接层的神经元数目分别设置为:4096、2048、1024、r,其中r表示图像文本对的哈希码长度,其数值由用户根据其检索的模糊程度从8bits,16bits,32bits,64bits,128bits的编码长度中选取一个长度;第一至第三最大池化层的窗口大小均设置为3×3;
(2b)构建一个由两个卷积层串联的文本特征提取模块;将第一至第二卷积层的卷积核大小分别设置为:1×m×1×8192、1×1×8192×r,步长均设置为1,其中,m表示词袋向量的维度;
(2c)将图像特征提取网络和文本特征提取网络并联成一个图像和文本特征提取网络;
步骤3,利用层次语义结构生成损失函数:
(3a)将所有图像文本对标签中每层所有类别的类哈希码按列从左往右组成一个类哈希码矩阵;
(3b)按照下式,计算训练集中每个图像文本对中每层的层次语义结构:
其中,
(3c)按照下式,计算将每个图像文本对每层的层次语义结构映射到图像文本对哈希码中的损失值:
其中,
(3d)生成损失函数如下:
其中,J表示损失函数,n表示训练集中图像文本对的总数,t表示图像文本对标签的总层数,α
步骤4,训练图像和文本特征提取网络:
(4a)将训练集中的图像文本对分批次输入到图像和文本特征提取网络中,利用Adam优化算法,用梯度下降法更新当前图像和文本特征提取网络中的参数,其中每个批次包含128个图像文本对;
(4b)利用最小二乘法,对更新网络参数后损失函数中的
(4c)利用当前更新后
(4d)判断更新后的损失函数是否收敛,若是,则得到训练好的图像和文本特征提取网络、
步骤5,用户用图像检索文本:
(5a)采用与步骤(1b)和(1c)相同的方法,对每个待检索的图像样本和被检索的文本样本进行处理后输入到训练好的图像和文本特征提取网络中,分别得到该图像样本的图像特征向量和文本样本的文本特征向量;
(5b)用输出的每个图像样本特征向量与损失函数收敛时的
(5c)将待检索的每个图像哈希码和被检索的每个文本哈希码进行异或操作,得到两个哈希码的汉明距离,将所有的汉明距离升幂排序后提取前k个文本样本,作为图像检索文本的检索结果;其中,k的取值为小于被检索的文本样本的总数;
步骤6,用户用文本检索图像:
采用与步骤5相同的方法,用待检索的文本样本和被检索的图像样本得到文本检索图像的检索结果。
本发明与现有技术相比有以下优点:
第一,本发明将所有图像文本对的标签中每层的所有类别的类哈希码按列从左往右组成一个类哈希码矩阵,计算训练集中每个图像文本对中每层的层次语义结构,克服了现有技术中忽略数据标签不同层之间的语义关联导致标签信息不全面的问题,使得本发明学习到的哈希码保持了数据标签的同层与层间的关联信息,从而提高了图像文本检索的精度。
第二,本发明计算将每个图像文本对每层的层次语义结构映射到图像文本对哈希码中的损失值,克服了当前技术中直接将标签信息融合到图像特征和文本特征中导致部分语义信息损失的问题,使得层次语义结构和标签的语义信息很大程度地保留到了哈希码中,从而提高了哈希码中语义信息的丰富性。
附图说明
图1为本发明的流程图;
图2是本发明的图像和文本特征提取网络的结构示意图。
具体实施方式
下面结合附图和实施例对本发明做进一步描述。
参照图1,对本发明的实现步骤做进一步的描述。
步骤1,建立训练集。
第一步,选取至少500个自然图像数据样本与其对应的文本数据样本组成图像文本对样本集,对每个图像文本对中的图像和文本样本分别从粗粒度到细粒度进行人工分层标注。
第二步,将标注后的每个图像文本对中的图像样本裁剪成224×224像素值的图像。
第三步,利用词袋模型,将标注后的每个图像文本对中的文本样本转化成同样长度的0-1词袋向量。
第四步,将裁剪后的所有图像样本与其对应的文本的词袋向量,组成图像文本对训练集。
步骤2,构建图像和文本特征提取网络。
构建一个12层的图像特征提取网络,其结构依次为:输入层,第一卷积层,第一最大池化层,第二卷积层,第二最大池化层,第三卷积层,第四卷积层,第五卷积层,第三最大池化层,第一全连接层,第二全连接层,第三全连接层,第四全连接层,输出层;设置图像特征提取网络的各层参数如下:将第一至第五卷积层的卷积核大小分别设置为:11×11×3×64、5×5×64×256、3×3×256×256、3×3×256×256、3×3×256×256,步长分别设置为:4、1、1、1、1;将第一至第四全连接层的神经元数目分别设置为:4096、2048、1024、r,其中r表示图像文本对的哈希码长度,其数值由用户根据其检索的模糊程度从8bits,16bits,32bits,64bits,128bits的编码长度中选取一个长度;第一至第三最大池化层的窗口大小均设置为3×3。
构建一个由两个卷积层串联的文本特征提取模块;将第一至第二卷积层的卷积核大小分别设置为:1×m×1×8192、1×1×8192×r,步长均设置为1,其中,m表示词袋向量的维度。
将图像特征提取网络和文本特征提取网络并联成一个图像和文本特征提取网络。
下面结合图2,对本发明构建的图像和文本特征提取网络做进一步的描述。
图2是本发明构建的图像和文本特征提取网络的结构示意图,图像和文本特征提取网络由图像特征提取网络和文本特征提取网络组成。其中,图像特征提取网络包括5层卷积层、4层全连接层和3层最大池化层,文本特征提取网络包括两个卷积层,矩形块上方的参数表示卷积层的卷积核的大小、全连接层的神经元数目和图像特征的维度。图像输入为224×224像素值大小的图像,输出为维度大小为r的图像特征。文本特征输入为词袋向量,输出为维度大小为r的文本特征。
步骤3,利用层次语义结构生成损失函数。
将所有图像文本对标签中每层所有类别的类哈希码按列从左往右组成一个类哈希码矩阵。
按照下式,计算训练集中每个图像文本对中每层的层次语义结构:
其中,
按照下式,计算将每个图像文本对每层的层次语义结构映射到图像文本对哈希码中的损失值:
其中,
生成损失函数如下:
其中,J表示损失函数,n表示训练集中图像文本对的总数,t表示图像文本对标签的总层数,α
所述的第i个图像文本对第k层的标签对该图像文本对对应层的层次语义结构分类的损失值
其中,
所述的第i个图像文本对的最底层的标签对该图像文本对对应的哈希码分类的损失值
其中,Q
所述的第i个图像文本对中图像特征映射到该图像文本对哈希码中的损失值
其中,
所述的第i个图像文本对中文本特征映射到该图像文本对哈希码中的损失值
其中,
步骤4,训练图像和文本特征提取网络。
第一步,将训练集中的图像文本对分批次输入到图像和文本特征提取网络中,利用Adam优化算法,用梯度下降法更新当前图像和文本特征提取网络中的参数,其中每个批次包含128个图像文本对。
第二步,利用最小二乘法,对更新网络参数后损失函数中的
第三步,利用当前更新后
所述的利用当前更新后
其中,
步骤5,用户用图像检索文本。
第一步,采用与步骤1中第一步和第二步相同的方法,对每个待检索的图像样本和被检索的文本样本进行处理后输入到训练好的图像和文本特征提取网络中,分别得到该图像样本的图像特征向量和文本样本的文本特征向量。
第二步,用输出的每个图像样本特征向量与损失函数收敛时的
第三步,将待检索的每个图像哈希码和被检索的每个文本哈希码进行异或操作,得到两个哈希码的汉明距离,将所有的汉明距离升幂排序后提取前k个文本样本,作为图像检索文本的检索结果;其中,k的取值为小于被检索的文本样本的总数。
步骤6,用户利用文本检索图像。
采用与步骤5相同的方法,用待检索的文本样本和被检索的图像样本得到文本检索图像的检索结果。
本发明的效果可以通过以下仿真实验进一步说明:
下面结合仿真实验,对本发明的效果做进一步说明。
1.仿真实验条件:
本发明的仿真实验的硬件平台为:处理器为Intel Core Xeon 4210 CPU,主频为2.2GHz,内存16GB,显卡为Nvidia GeForce RTX 3090。
本发明的仿真实验的软件平台为:Linux4.15操作系统和python 3.6。
本发明仿真实验所采用的数据为:FashionVC数据集,包含19862个图像文本对,图像样本为已裁剪成224×224像素值的图像,文本样本为bag-of-words向量。每一个图像文本对由层次标签所标注,层次标签的层数为两层,第一层标签类别为8类,第二层标签类别为27类。从FashionVC数据集中随机选取3000个图像文本对组成测试集,剩余的16862个图像文本对组成训练集。根据检索模糊程度分别将哈希码的长度设置为8bits,16bits,32bits,64bits,128bits五种长度。
2.仿真内容及其结果分析:
本发明的仿真实验是采用本发明方法和五个现有技术(DLFH、SSAH、DADH、HiCHNet和SHDCH)分别构建的六个跨模态信息检索网络,利用相同的训练集数据分别训练六个网络,得到训练好的六个跨模态哈希检索网络,将训练好的跨模态哈希检索网络中输出的训练集在五种哈希码长度下的哈希码作为被检索的哈希码检索集。利用相同的测试集分别对六个训练好的跨模态哈希检索网络在五种哈希码长度下输出图像检索文本和文本检索图像的检索集结果。
在仿真实验中,采用的五个现有技术是指:
现有技术DLFH是指,Wang等人在其发表的论文“Discrete latent factor modelfor cross-modal hashing”(IEEE Transactions on Image Processing,vol.28,no.7,pp.3490–3501,2019)中提出的跨模态哈希检索算法,简称DLFH。
现有技术SSAH是指,Li等人在其发表的论文“Self-supervised adversarialhashing networks for cross-modal retrieval”(Proceedings of the 31st IEEEConference on Computer Vision and Pattern Recognition,2018,pp.4242–4251)中提出的跨模态哈希检索方法,简称SSAH。
现有技术DADH是指,Bai等人在其发表的论文“Deepadversarialdiscretehashing for cross-modal retrieval”(Proceedings of the2020on International Conference on MultimediaRetrieval,2020,pp.525–531)中提出的跨模态信息检索方法,简称DADH。
现有技术HiCHNet是指,Sun等人在其发表的论文“Supervised hierarchicalcross-modalhashing”(Proceedingsofthe42ndInternationalACM SIGIRConferenceon ResearchandDevelopmentinInformationRetrieval,2019,pp.725–734)中提出的跨模态哈希检索方法,简称HiCHNet。
现有技术SHDCH是指,Zhan等人在其发表的论文“Supervisedhierarchical deephashingforcross-modalretrieval”(Proceedingsofthe28thACMInternationalConference onMultimedia,2020,pp.3386–3394)中提出的跨模态哈希检索方法,简称SHDCH。
为了评价本发明实验的仿真效果,利用每种哈希码长度下的平均精度均值mAP
利用下面公式,分别计算本发明跨模态哈希检索方法与五个现有技术跨模态哈希检索方法中每种方法在图像检索文本的每种哈希码长度下的平均精度均值mAP
所述的每种方法在每种哈希码长度的平均精度均值是由下式计算得到的:
其中,
所述采用第z个跨模态哈希检索方法在哈希码长度为y的测试集中第e个图像文本对中图像的平均精度是由下式计算得到的:
其中,X表示哈希码检索集中根据标签是否相同得到的与第e个图像相关的样本总数,U
采用与图像检索文本相同的方式计算本发明跨模态哈希检索方法与五个现有技术跨模态哈希检索方法中每种方法在文本检索图像的每种哈希码长度下的平均精度均值mAP
表1:本发明仿真实验图像检索文本的平均检索精度比较表
表2:本发明仿真实验文本检索图像的平均检索精度比较表
结合表1和表2可以看出,本发明方法在计算的图像检索文本和文本检索图像的平均检索精度均高于五种现有技术方法,较于五种现有技术中平均检索精度最好的跨模态哈希检索方法SHDCH,本发明方法的图像检索文本精度在五个哈希码长度上分别提高了1.4%、3%、1.5%、0.4%、1%,本发明方法的文本检索图像精度在五个哈希码长度上分别提高了2.2%、1.6%、0.5%、0.3%、0.7%;证明本方法可以得到更高的跨模态哈希检索精度。
以上仿真实验表明:本发明通过将所有图像文本对标签中每层的类哈希码用标签扩展为对应层次的层次语义结构,再将各层的层次语义结构融合到哈希码中,使得图像文本对的哈希码保持了标签的同层与层间的关联信息,哈希码很大程度地保留了标签信息,解决现有技术跨模态哈希检索方法忽略数据标签不同层之间的语义关联导致图像文本检索精度不高问题和直接将标签信息融合到图像和文本的特征中造成部分语义信息损失的问题,提高了跨模态哈希检索的精度。