借助于多代理强化学习在系统中配置部件的方法、计算机可读存储介质和系统
文献发布时间:2023-06-19 18:29:06
背景技术
由多个部件组成的软件系统通常需要配置部件,以便针对特定应用情况实现最佳实施该部件的任务。在较简单的情况下,这能够手动进行或借助调节回路完成。
这种配置的实例是将计算负载分配到多个处理器内核上、共享内存的大小或最大可能的通信数据包的数量。
如果影响因素(运行变量、干扰变量、调节变量……)变得越来越多并且关系越来越复杂,则找到最佳方案是非常困难的,并且必要时仅还借助于经验优化方案或借助于调整过的/经训练的人工智能(AI)模型借助机器学习才可行。
一般来说,机器学习分为无监督机器学习、监督机器学习和强化学习或“加强学习(
更困难的是,当相关的部件在运行时间期间经受变化并且对于这种情况训练数据不可用。动态添加具有新参数和影响的其他部件进一步增加了任务的复杂性。此外,还必须遵守跨部件的边界条件。边界条件也能够在部件的运行时间/生命周期期间变化。
对于在运行时间才出现的方面,例如部件内的变化、其他部件的添加或上级边界条件的变化,通常需要调整计算机系统的配置。如实,在基于AI的解决方案的情况下,在总系统的运行时间期间需要对AI模型进行后期训练。在此,必须确保在探索时不实施导致生产系统中出现不期望的行为的变化。
在此,调整例如用于以下目的:
-提高生产力,
-改进质量,
-增加数据流量,
-确保稳定性直至增加稳定性,
-增加最大容量利用率的储备,
-缓冲功率峰值,和
-及早识别不稳定性(存储器、网络、通信……)。
这种系统的一个实例是西门子HMI Operate的中央部件:控制访问点(CAP),以及参与部件(COS任务、NCK、...),其协作如今在运行时间经历静态配置/参数化,并且其因此仅不充分地或完全无法对不同的负载场景做出反应。尤其对于OPC-UA、大数据、智能数据、边缘、模块化运行概念或生产/机器特定的应用的领域中的未来应用,当今或多或少静态协作的部件的性能不再足够,因为尤其必须实现更高的数据流量,但同时必须保证潜在负载峰值的稳定性和储备。
如今,具有相应的协作的部件的复杂的工业控制系统(即例如CNC机器)通常彼此分开地配置或优化。当完全手动实施时,在变化的环境中(尤其是在运行时间)对经训练的系统进行调整。
例如,根据经验值,在重新启动操作程序之前手动(也可能是应用特定地)变化系统的一些运行变量(例如,线程数量取决于内核数量),以将人机接口(HMI)操作根据特定场景参数化。在系统的运行时间期间仅调整少量参数,以便确保更高的流量或更好的稳定性。
在此,如今的解决方案没有考虑在运行时间仅应在安全框架内进行调整,以防止在生产运行中造成不期望的行为。
在参考文献US 2019/0244099 A1中已经描述了强化学习系统,强化学习系统在系统的运行时间期间、例如也在工业环境中执行系统训练,以控制机器人完成具体任务。
发明内容
因此,本发明所基于的目的是:提出一种方法,该方法应该在运行时间能够对负载系统的参数化/配置进行调整。
目的通过根据权利要求1的特征的方法实现。此外,目的通过根据权利要求8的特征的计算机可读存储介质和根据权利要求15的系统的特征来实现。
该解决方案中采用机器学习概念。
根据本发明的方法用于利用影响部件的因素并且利用强化学习系统的构件来配置系统中的部件,其中,部件相互处于有效关联,并且其中,能够分别通过获取内部的测量变量来确定部件的状态,并且能够通过获取总系统的测量变量确定系统的状态。在此,基于至少一个代理和关于配属的环境的信息。在系统的运行时间期间,系统中的部件首先设置为训练模式,以便在第一状态中启动训练阶段。在此,该方法具有以下步骤:
a)调用配属的部件的至少一个代理,
b)在代理的第一训练动作之后,通过重新获取测量变量来评估部件和/或总系统的状态,以便然后根据获取的结果实施以下步骤之一:
cl)在测量变量一致或改进的情况下:执行下一个动作
c2)在测量变量恶化的情况下:将用于训练的Epsilon贪婪值设置为零,执行下一个动作,
c3)在测量变量严重恶化的情况下,尤其在实时行为中中断训练,并且系统转移到初始状态中,从步骤a继续,
d)在情况cl和c2中,重复步骤b)和c)直至强化学习事件结束,
e)更新代理的策略(策略“Policy”),
f)对下一个代理重复步骤a至e。
有利的实施例在从属权利要求中说明。
附图说明
下面,还通过附图对本发明进行说明。在此示出
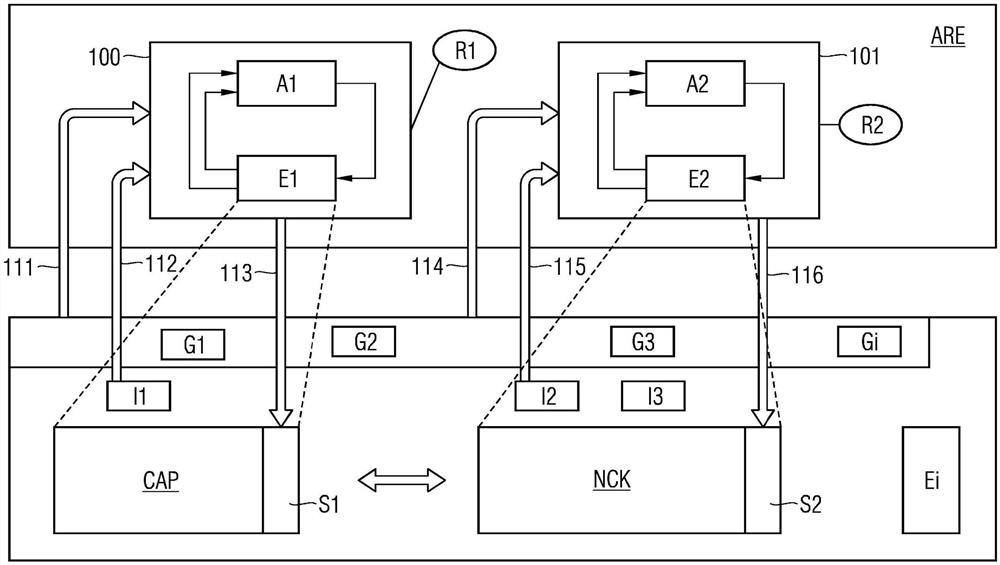
图1示出系统的架构概览,系统具有强化学习引擎,
图2示出强化学习代理,和
图3示出防御性在线训练的示意流程。
具体实施方式
例如由制造商提供的经预先训练的系统和模型也能够用作起点。如果构建在已经存在的系统上,则也会是这种情况。当然,如果模拟过于复杂或者会过于不精确,也能够从一开始就在实际应用中训练代理,除非这不可行。如果没有使用经预先训练的模型,则在此所谓的攻击性在线训练或者导致长的训练持续时间。为了随后使模型/代理匹配新的、变化的或自身变化的环境(甚至在生产期间),即重新训练(重训练)配置参数,使用所谓的防御性在线训练,其中,对于每个部件有利地都存在自身的代理(多代理系统)。
多代理系统还从以下公开文献中已知:
Lowe R.,Harb J.,Wu Y.,Abbeel P.,Tamar A.,Mordatch I.:Multi-AgentActor-Critic for Mixed Cooperative-Competitive Environments Actor-Critic,arXiv:1706.02275v3或者
Rashid T.,Samvelyan M.,Schroeder de Witt C.,Farquhar G.,Foerster J.,Whiteson S.,QMIX:Monotonie Value Function Factorisation for Deep Multi-AgentReinforcement Learning,arXiv:1803.11485v2,或者
KKIqing Zhang,Zhuoran Yang,Tarier Basar:Multi-Agent Rein forcementLearning:A Selective Overview of Theories and Algorithms,arXiv:1911.10635。
在此,在当前的现有技术中,存在多代理强化学习系统的两种常见的表现形式:
下面的描述也能够以图1为例来理解。每个代理A、A1、A2的状态在第一表现形式中包括关于自身部件的状态和总系统的状态,特别是表征总系统的要优化的特性的测量变量(例如CPU利用率或网络负载)。
或者,在替代的表现形式中,其仅包括要优化的系统的部分状态,但随后包括下游网络,下游网络接收其他(配属的)代理的动作作为输入,进而获得关于总体状态的间接信息。
代理A、A1、A2的可能的动作涉及变化单个部件的配置参数。所有代理都有利地组合在AI-RL引擎中,引擎能够位于部件外或与部件内的代理的实例连接。
在此,用于各个部件的代理的配置如图2中更详细地所示的那样运行:
-动作a、a
-状态s1、s2、s3、s
-环境E、E1、E2:对应于相应的部件、例如控制访问点CAP,数控内核NCK,...
-奖励r,r
在生产环境中的这种学习中重要的是:运行变量的持续变化(试错,“试错(trial&error)”)受控并谨慎进行,使得调整总是在安全的、预设的、可能多维度的参数空间中移动,并且作用不危害设施的生产(工件)和安全还有可能在其中移动的人员。因此,代理的动作空间强烈取决于参数空间描述。
为了在运行时间调整系统而区分两种模式,模式分别通过AI-RL引擎的相应的模式实现。
为了在较大变化后或针对新应用情况训练系统,在运行时间执行明确的训练阶段,在该训练阶段中用户启动典型遍历(在CNC机器中,例如制造典型产品),目的是关于新条件训练系统。练习阶段包括预先限定的时间段或多个部分,并且典型地由已经在生产环境中的最终用户执行。
在训练过程中,代理从其限定的动作空间中选择系统的配置参数。动作空间由离散参数组成,离散参数被限制,使得例如避免产品或机器的损坏以及设施的过大的性能下降。
在此,使用所谓的“贪婪”算法,其中,逐步选择下一个后续状态,该后续状态在选择的时间点承诺最大的获益或最好的结果。探索开发率(探索比开发(Erkundungvs.Verwertung))在此限定为,使得代理通常做出随机决定,以便尝试很多新事物(探索),从而能够实现快速匹配于变化的系统。然而,恶化受到高的负回报(奖励)惩罚,使得避免沿不利方向调整。
第二模式设置用于:在持续运行中、即在生产阶段中随较小的变化执行持续的调整。在此,由于通过代理进行的随机变化,总系统的要优化的目标值没有强烈恶化,使得例如要制造的工件的质量下降低于特定边界值。
在本发明的一个有利的表现形式中在正常生产运行期间使用第二模式,即目标变量允许在对于生产的所得出的特性(即流量、质量、磨损等)直接能够接受的范围内恶化。这在实践中能够例如实施为,使得在正常运行中(即没有优化的情况下)可观察到的波动加上一定的提升是能容忍的。
这通过以下方式实现:一方面使得配置参数的变化的离散步长小至使得借助于一个动作无法低于限定的边界值(例如性能值、负载、速度或温度)。此外,通过代理引起的用于探索的随机变化的份额相对小,例如Epsilon贪婪值设置为ε=10%。
图3示意性地示出如何实施防御性在线训练。在训练开始时,代理处于状态sl,并且选择随机动作al(参见图2)。真实系统采用通过动作a1选择的配置参数变化并且继续执行该过程。如果系统在变化后稳定,则测量到的数据限定随后的状态s2。如果状态s2表示目标变量与先前状态s1相比的恶化,则将Epsilon贪婪值ε直接设置为零,以便不再允许探索。代理应该利用其先前的知识将系统再次置于起始位置s1。在限定的事件长度(例如最多10个步长)之后,代理的策略(也称为Policy)被更新。该策略描述系统状态与动作之间的关联,代理根据该动作来执行动作。然后,代理能够通过调整总是更好地做出反应,经由此发生实际的学习过程。在实时关键系统中,在从一个状态恶化到下一个状态的情况下(例如,在预期错过时间上的预设的情况下)立即结束该事件,并且系统直接重置为状态s1的存储的配置参数。代理的策略(policy)的更新直接在事件中断之后实施。由此,避免通过随机依次选择的变化能够进行超出预设边界的恶化。
在此,原则上能够根据已知的方法实现各个代理的协作,例如在上面公开的文献中描述。
然而,在此也能够使用特别的方法,以限制调整的作用。代理以特定顺序实施,其中,首先调用具有高变化潜力的部件(即,本身并且对总系统作用最大),并且最后调用具有小作用的部件。因此,总系统不会由于相互增强的负面变化而处于不期望的状态,如果出现目标变量的恶化,则重复执行第一代理的步骤。这同样适用于后续的代理。
整体上,该方法因此包括具有以下步骤的流程:
1.根据训练模式配置系统。为此提供两种不同的替代方案:
a)模式1,即进攻性训练,用于快速学习新情况:
参数的值范围和步长限制到如下程度:使得借助一个动作仅能够实现不关键的变化。为此,明确地通过用户进行预设,或者类似地通过经预训练的模型进行预设。Epsilon贪婪值ε设置为更高的值,该值引起期望的(较大的)探索。
或者
b)使用模式2,防御性训练,其具有持续学习:
参数的值范围和步长以如下方式限制:即变化不显着恶化目标变量,Epsilon贪婪值ε设置为较小的值,例如10%。
2.具有(大概)最大影响的部件的代理A、A1、A2首先以初始状态s1被调用。如果没有关于部件影响的信息,则能够根据固定顺序再调用部件。然后例如根据经验值或还有较早的训练阶段或事件的结果来进行确定。对此的实例能够是使用更少的CPU内核,与减少主存储器相比,这对单核应用影响更小。
3.在代理A、A1、A2的第一动作a
在此,区分3种情况:
a)值的改进:执行下一个动作a
b)值的恶化:Epsilon贪婪值ε设置为零,然后执行下一个动作,直至事件结束在最终状态中sn,40。
c)严重恶化,通常在实时行为有负面影响的情况下:系统中断并转移到初始状态sl,利用步骤2继续,50
4.在前两种情况下(3a和3b),执行动作直至事件结束。然后更新第一代理的策略(Policy)。
5.然后对所有代理执行步骤2-4。
上面描述的特定方法有利地能够实现改进由多个(软件)部件的且例如控制(生产)过程组成的系统的行为,进而匹配变化的要求或应用,而不显著损害生产或完全不出现机器或工件的损坏。这通过对强化学习方法的特定的修改来实现。
强化学习代理的所提出的在线训练在(或多或少)防御模式中执行,以便在真实系统中可行。通过该防御性训练策略确保:相关的机器和/或产品不受到负面影响。
在此,能够考虑不确定的影响(例如温度波动),该影响在模拟中经常被忽略。此外,也不需要为系统的训练复杂地创建如下模拟,该模拟然后在训练过程中越来越偏离要模拟的系统。因此,也能够放弃使用训练数据,因为能够在训练单元中使用实际的系统数据。
训练阶段的发起和新策略(policy)的提供能够自动执行,不需要通过用户手动触发。能够自动切换至在线训练,例如通过调整Epsilon贪婪值。
该方法的另一优点是:能够在运行期间,将代理匹配变化的环境。到目前为止,这引起必须耗费地调整模拟并且或者必须重新开始训练。
所提出的方法有利地提供两种训练模式:即选择性的、具有频繁次优(但始终非关键)设置的快速学习,或具有罕有次优(但非关键)设置的缓慢学习。
使用机器学习方法(在此特别是强化学习)能够实现动态调整大量参数或更好的资源分配,以便为工业生产的数字化的未来需求做好准备。
特别地,根据特定机床、相应产品以及相应的生产阶段在现场进行特定的运行时间调整作为结果为客户实现提高生产率,更快地识别系统(通信、网络,...)中的问题,从而更好地定期检查整个制造进程。
- 项目生成方法及系统、计算机系统和计算机可读存储介质
- 显示方法及系统、计算机系统及计算机可读存储介质
- 排队通知方法及系统、计算机系统及计算机可读存储介质
- 用于增强存储设备的服务质量的存储系统、方法和非暂态计算机可读介质
- 目标检测系统、方法、空调系统和计算机可读存储介质
- 服务系统中的配置变更方法、系统及计算机可读存储介质
- 服务系统中的配置变更方法、系统及计算机可读存储介质