一种基于提示学习和上下文感知的关系类别推断系统及方法
文献发布时间:2023-06-19 18:35:48
技术领域
本发明属于计算机技术领域,尤其涉及计算机信息抽取技术,主要涉及了一种基于提示学习和上下文感知的关系类别推断系统及方法。
背景技术
随着信息技术的发展,互联网上的文本信息不断增加,纯文本的信息难以被计算机高效利用,而知识图谱等结构化的数据展示存储方法在使用时具有更大的优越性,能更好地为计算机所处理,因此结构化的数据使用价值更高。从复杂、多源、异构的数据中挖掘出高质量、结构化的有价值的信息,是当前学术界的一个重要课题。从非结构化文本中提取结构化的信息并储存在一个有结构的数据库或知识图谱中,称为信息抽取。信息抽取分为实体抽取、关系抽取和事件抽取三大方向。其中,关系抽取技术作为信息抽取技术中的一个关键环节,可以识别或分类文本中给定实体间的关系类型。例如:从文本“乔布斯创立了苹果公司”中确定“乔布斯”和“苹果公司”之间的关系类型为“创始人”或者“公司管理者”。
但是传统关系抽取只关注在预定义好关系类型的静态数据集下模型的学习效果,而现实情况更加复杂,很难通过专家系统对目标领域内的无标注文本数据充分预先定义好其中的关系类型。并且随着时间的推移,无标注的数据也会不断增加,数据中的包含的关系类型也会随之扩大。模型如何在动态增加的数据中学习成为关系抽取新的挑战,由此引出对增量关系抽取任务的研究,即,模型需要抽取的关系集合会随着数据的积累而扩大,而如何从新增的文本数据中识别新的关系类型成为增量关系抽取的挑战。
在关系类别推断中,主要是从给定的无标注文本中推断文本中蕴含的关系类别信息。如:从文本“乔布斯创立了苹果公司”中,人类很容易识别出句子中表达的关系类型是“创始”、“创立”关系,而完全采用人工进行标注关系成本较高。采用规则进行关系识别的方法中,确定句子中的动词作为候选关系词,筛选包含依存关系nsubj和dobj的关系词作为有意义的关系词,然后对关系词频排序,推断出无标注文本的关系类别信息。这些方法受到规则设计的限制,难以适应增量关系抽取场景下不断新增的无标注文本。而直接从无标注文本中推断出关系类别会受到文本中的噪声数据的影响,所以需要先从文本中提取必要的信息,如:实体关系三元组信息,然后利用无监督聚类等方法挖掘提取出信息中表达的关系类型。
随着深度学习的快速发展,预训练模型在预训练阶段使用了海量的数据使模型充分接触到了现实中文本的各种表达方式和语义信息,在下游任务微调过程中迁移预训练中学到的知识,可以有效提升下游任务表现。提示学习不需要在预训练模型之后添加任何网络结构,而是在测试数据后拼接提示,通过微调提示得到预测结果,提升了模型的使用效率并且减少了存储空间。提示学习在文本推理、问答、关系分类等领域的零样本和少样本的场景上取得了不错的效果,但是在信息抽取领域的研究还比较缓慢,这启发了本专利用提示学习的方法先对无标注的文本进行抽取实体关系三元组作为特征信息,然后利用无监督聚类对无标注文本中的关系类型信息进行推断,以解决增量关系抽取场景中无标注文本的关系类型标注问题。
发明内容
本发明正是针对现有技术中的问题,提供一种基于提示学习和上下文感知的关系类别推断系统及方法,首先执行文本预处理获取规范的文本内容;根据文本与关系词的联系设计提示学习模板,所述模板由文本、提示文本和掩码组成,提示文本由提示词和三个掩码组成,掩码对应文本中的实体关系三元组信息,将文本代入提示学习的模板,引入标签词掩码并拼接提示短语;之后经过知识增强的词映射器,获取掩码位置的标签词进行监督学习,标注关系词三元组时则将标签词通过词映射器还原成关系词和实体词;然后按关系词位置将文本划分为上文和下文,然后对上下文分别进行无监督聚类,推断上下文均在相同类别的不同关系词为同一类别,突破了关系类别仅依赖关系词本身而不考虑语境信息的限制,解决了增量关系抽取场景中无标注文本的关系类型标注问题。
为了实现上述目的,本发明采取的技术方案是:一种基于提示学习和上下文感知的关系类别推断方法,具体包括如下步骤:
S1,数据初始化:收集实体关系三元组及包含三元组的文本形成标注数据集、同时收集目标领域的无标注文本构建无标注的样本集,对收集的文本数据进行预处理,规范实体和关系的长度,删除跨句三元组,去除句子中的特殊符号;
S2,构建提示学习模板:根据文本与关系词的联系设计提示学习模板,所述模板由文本、提示文本和掩码组成,提示文本由提示词和三个掩码组成,掩码对应文本中的实体关系三元组信息,所述模板的英文形式为:
Inthissentence,therelationbetweenentity[MASK]
entity[MASK]
其中,[MASK]
S3,基于知识增强的词映射器:经过知识增强的词映射器,获取掩码位置的标签词进行监督学习,将标签词通过词映射器还原成关系词和实体词;
S4,构建关系三元组标注模型:将掩码位置隐藏层的特征向量与候选标签词的特征向量计算欧氏距离得分,得分最高的候选标签词为模型对掩码位置的预测结果,其目标函数为:
p(y|d)=p([MASK]=V
其中,V
S5,基于上下文感知的无监督聚类:将文本按关系词的位置划分为上文和下文,并进行分词,分别得到上文和下文的特征向量,对上文和下文的特征向量分别执行无监督聚类,通过拐点法获取最佳聚类中心个数,对满足上文在同一聚类类别中且下文在同一聚类类别中的关系词,归为同一种关系类型,然后在关系词集合选择出现频率最高的词作为关系类别词。
为了实现上述目的,本发明还采取的技术方案是:一种基于提示学习和上下文感知的关系类别推断系统,包括关系词三元组标注模块和关系聚类模块,
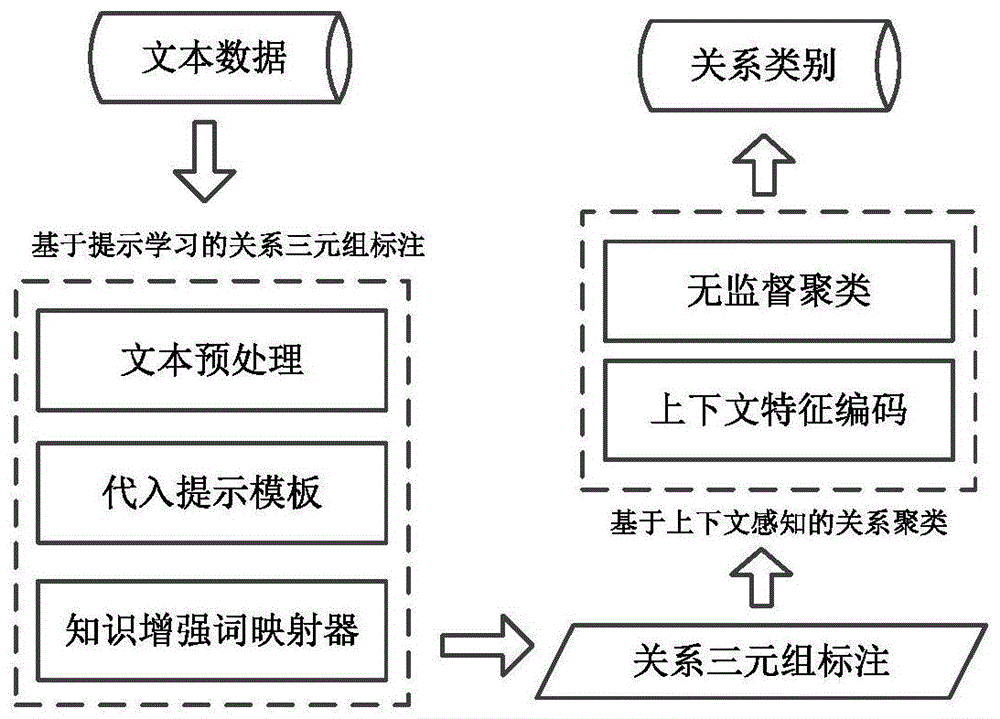
所述关系词三元组标注模块中,执行文本预处理获取规范的文本内容,将文本代入提示学习的模板,引入标签词掩码并拼接提示短语,之后经过知识增强的词映射器,获取掩码位置的标签词进行监督学习,标注关系词三元组时则将标签词通过词映射器还原成关系词和实体词;
所述关系聚类模块中,按关系词位置将文本划分为上文和下文,然后对上下文分别进行无监督聚类,推断上下文均在相同类别的不同关系词为同一类别。
与现有技术相比,本发明具有的有益效果:
(1)本专利设计并提出了一个针对关系类别推断所需文本特征的提示学模板,可以从无标注的文本中提取出实体关系三元组信息。
(2)本专利采用子词切分和近义词词库对提示学习中的词映射器进行数据增强,扩大了词映射器中标签词的在覆盖范围。
(3)本专利提出使用上下文感知的方法对标注的关系词上下文进行聚类,考虑了关系词的上下文信息对关系类别的影响,突破了关系类别仅依赖关系词本身而不考虑语境信息的限制。
附图说明
图1为本发明基于提示学习和上下文感知的关系类别推断系统的工作流程图;
图2为本发明实施例2中步骤S5的流程图。
具体实施方式
下面结合附图和具体实施方式,进一步阐明本发明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
实施例1
一种基于提示学习和上下文感知的关系类别推断系统,包括关系词三元组标注模块和关系聚类模块,其工作流程如图1所示,所述关系词三元组标注模块中,执行文本预处理获取规范的文本内容,将文本代入提示学习的模板,引入标签词掩码并拼接提示短语,之后经过知识增强的词映射器,获取掩码位置的标签词进行监督学习,标注关系词三元组时则将标签词通过词映射器还原成关系词和实体词;
在执行文本预处理的过程中,其关系类别推断任务的初始化步骤具体为:收集实体关系三元组及包含三元组的文本形成标注数据集L,然后收集目标领域的无标注文本构建无标注的样本集U;随后进行文本预处理,规范实体和关系的长度,删除跨句三元组,去除句子中的特殊符号。
在构建提示学习模板的过程中,提示模板对从预训练模型中获取文本所需要的标注信息进行提示,具体为:根据文本与关系词的联系人工设计提示模板,模板由文本、提示文本和掩码组成,提示文本由提示词和三个掩码组成,掩码对应文本中的实体关系三元组信息。再将从文本中标记实体关系三元组的任务构建为完型填空任务,使用关系词三元组标注模型对代入提示模板的文本中掩码位置的词进行预测。
基于知识增强的词映射器具体包括:对实体词和关系词进行切分,将生成的子词作为标签词,模型对掩码位置进行预测,预测时将预测标签词,然后通过词映射器还原到实体词和关系词。利用近义词词库搜索相近意义的词对实体词和关系词扩充标签词,获取中冲突的标签词自动化分配给标签词较少的实体词或关系词
所述关系聚类模块中,按关系词位置将文本划分为上文和下文,然后对上下文分别进行无监督聚类,通过拐点法获取最佳聚类中心个数,对满足上文在同一聚类类别中且下文在同一聚类类别中的关系词,归为同一种关系类型,然后在关系词集合选择出现频率最高的词作为关系类别词。
本系统突破了关系类别仅依赖关系词本身而不考虑语境信息的限制,解决了增量关系抽取场景中无标注文本的关系类型标注问题,可以从无标注的文本中提取出实体关系三元组信息,是一种低人工成本的关系类别推断系统。
实施例2
一种基于提示学习和上下文感知的关系类别推断方法,包括以下几个步骤:
步骤S1,关系类别推断任务的初始化,具体如下:
收集实体关系三元组及包含三元组的文本形成标注数据集L,然后收集目标领域的无标注文本构建无标注的样本集U。规范实体和关系的长度,将实体长度规范为一个词,将关系长度规范为三个词,同时对数据集中的空实体、空关系进行删除。对收集的文本数据中,三元组不在同一个文本句子中的文本进行删除。去除句子中的特殊符号。
规范关系过程中,如果关系短语长度多于三个词,则使用词性标注工具保留其中的动词部分,其余部分采取截断的方式;如果关系长度少于三个词,则通过添加介词或者助动词对关系进行扩充。
步骤S2,构建提示学习模板,提示模板对从预训练模型中获取文本所需要的标注信息进行提示,具体为:
根据文本与关系词的联系人工设计提示模板,模板由文本、提示文本和掩码组成,提示文本由提示词和三个掩码组成。为了引导BERT预训练模型输出关系三元组标注任务相关的信息,添加上下文提示词,显式的关系提示词和显式的实体提示词。掩码对应文本中的实体关系三元组信息。设计的提示模板T的英文形式和s分别为:
Inthissentence,therelationbetweenentity[MASK]
entity[MASK]
在这句话中,实体[MASK]
其中,[MASK]
对于每条输入文本d∈L,将文本输入到模板中T(d):
dInthissentence,therelationbetweenentity[MASK]
entity[MASK]
将从文本中标记实体关系三元组的任务构建为完型填空任务,然后使用关系词三元组标注模型对代入提示模板的文本中掩码位置的词进行预测。
步骤S3,基于知识增强的词映射器;
对实体词和关系词进行切分,将生成的子词作为标签词,模型对掩码位置进行预测,预测时将预测标签词,然后通过词映射器还原到实体词和关系词。利用近义词词库搜索相近意义的词对实体词和关系词扩充标签词,获取冲突的标签词自动化分配给标签词较少的实体词或关系词。步骤S2中将从文本中标注关系三元组的任务转化成完型填空任务,即对掩码位置的实体和关系词进行预测。如果只对目标范围内的实体和关系词预测,由于其分布比较集中因此本专利采用子词法和词库法对其扩充。训练阶段,由预测实体词关系词通过词映射器转化为预测标签词。测试阶段,则将关系三元组标注模型的实体关系预测结果还原为标签词。
步骤S4,构建关系三元组标注模型;
将代入提示模板的文本通过BERT标记解析器解析成token序列,采用预训练的语言模型BERT对token序列进行编码,将词转化成vocab词表中的id,同时为句子添加句子类别符号和句子分割符号;通过加载预训练的参数获取token的词向量,获得token序列的词向量矩阵;然后经过BERT模型进行特征编码,获取每个词的隐特征向量;同时将关系三元组的候选标签词也使用相同的方式获取BERT模型的隐特征向量;然后将掩码位置隐藏层的特征向量与候选标签词的特征向量计算欧氏距离得分,得分最高的候选标签词为模型对掩码位置的预测结果,其目标函数为:
p(y|d)=p([MASK]=V
其中V
步骤S5,基于上下文感知的无监督聚类,具体如图2所示:
初始化Word2Vec编码器。将文本按关系词的位置划分为上文和下文,分别使用d
其中,w
然后对上文文本和下文文本分别使用无监督聚类方法进行聚类挖掘文本之间的相似性,聚类采用欧式距离作为两条文本的上文或下文的相似性的度量标准。
其中
对文本d
其中r
测试例
本测试例使用了如下指标进行评估:在关系类别推断数据集上,针对关系类别推断结果,使用precision、recall和F1来评测预测效果。precision为查准率,计算预测为正的样本中,预测正确的样本数;recall为查全率,表示真实为正的样本中,预测正确的样本数;F1表示precision和recall的调和平均数,用来平衡查准率和查全率,使用
针对本方法中的基于提示学习的信息抽取模块在公开数据集OIE2016、WEB和NYT具体测试后,具体如下表:
上表中可以看出,本发明的方法均优于对比方法,本方法可以从无标注的文本中提取出实体关系三元组信息,扩大了词映射器中标签词的在覆盖范围,解决了增量关系抽取场景中无标注文本的关系类型标注问题。
需要说明的是,以上内容仅仅说明了本发明的技术思想,不能以此限定本发明的保护范围,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰均落入本发明权利要求书的保护范围之内。