一种交互式迭代建模方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及迭代建模技术领域,特别涉及一种交互式迭代建模方法。
背景技术
目前,行业中常见的模型迭代方案为:训练完一个模型后,若模型效果没有达到预期,此时需要进行模型迭代调优,可以沿用或者新启项目进行模型迭代。
但是,常见的模型训练平台在进行迭代调优时,通常仅有常见的超参优化与变量选择,特征衍生方式简单甚至没有特征衍生方式,自动化调优策略单一,粗糙且内置于算法内部,操作人员的可干预程度小。且在对模型进行深入的调整与调优时,通常需要通过写代码的方式完成,需要较高的代码能力。而且也会导致最终完成的模型的过程呈现出黑匣子的状态,模型的理解性差,影响模型的落地应用。
因此,现存的常见的模型训练平台存在以下问题:
人与机器交互性、可控性、交互性、可解释性差;
每次迭代模型更像是在独立完成一个新的模型,迭代延续性差,开发时间长,增加建模人员的时间成本,导致模型开发效率低:
建模人员进行人为干预时,往往需要熟练掌握模型开发代码的能力,对编程能力要求较高,上手难。
因此,本发明提出了一种交互式迭代建模方法。
发明内容
本发明提供一种交互式迭代建模方法,用以基于用户在迭代建模过程中输入的指令对迭代建模过程进行干预,提高迭代建模的效率,使得模型开发过程是可把控、可理解、可干预的,可以不断地基于现有模型进行快速优化迭代,使得每一次模型训练不再独立,而是变成一种迭代过程,从而提高了训练模型的效率,无需较高的编程能力即可实现在更短的时间内训练出更好的模型。
本发明提供一种交互式迭代建模方法,包括:
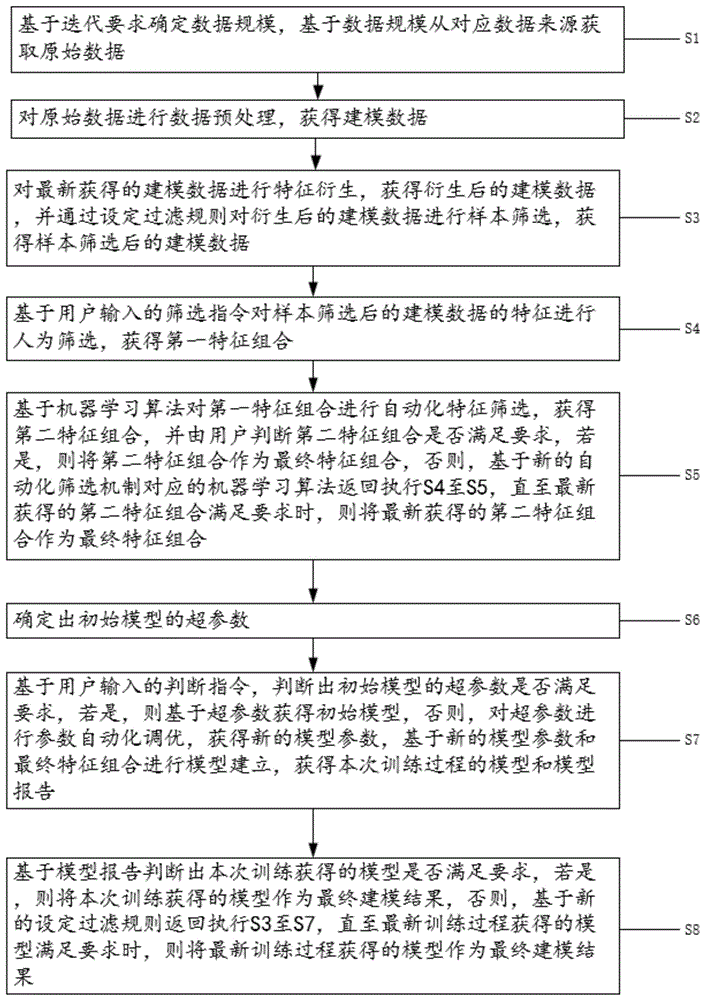
S1:基于迭代要求确定数据规模,基于数据规模从对应数据来源获取原始数据;
S2:对原始数据进行数据预处理,获得建模数据;
S3:对最新获得的建模数据进行特征衍生,获得衍生后的建模数据,并通过设定过滤规则对衍生后的建模数据进行样本筛选,获得样本筛选后的建模数据;
S4:基于用户输入的筛选指令对样本筛选后的建模数据的特征进行人为筛选,获得第一特征组合;
S5:基于机器学习算法对第一特征组合进行自动化特征筛选,获得第二特征组合,并由用户判断第二特征组合是否满足要求,若是,则将第二特征组合作为最终特征组合,否则,基于新的自动化筛选机制对应的机器学习算法返回执行S4至S5,直至最新获得的第二特征组合满足要求时,则将最新获得的第二特征组合作为最终特征组合;
S6:确定出初始模型的超参数;
S7:基于用户输入的判断指令,判断出初始模型的超参数是否满足要求,若是,则基于超参数获得初始模型,否则,对超参数进行参数自动化调优,获得新的模型参数,基于新的模型参数和最终特征组合进行模型建立,获得本次训练过程的模型和模型报告;
S8:基于模型报告判断出本次训练获得的模型是否满足要求,若是,则将本次训练获得的模型作为最终建模结果,否则,基于新的设定过滤规则返回执行S3至S7,直至最新训练过程获得的模型满足要求时,则将最新训练过程获得的模型作为最终建模结果。
优选的,所述的一种交互式迭代建模方法,S1:基于迭代要求确定数据规模,基于数据规模从对应数据来源获取原始数据,包括:
S101:基于迭代要求确定置信区间、可容忍误差和标准差值;
S102:基于置信区间、可容忍误差和标准差值,计算出数据规模;
S103:基于数据规模从对应数据来源获取原始数据。
优选的,所述的一种交互式迭代建模方法,S2:对原始数据进行数据预处理,获得建模数据,包括:
S201:对原始数据进行数据清理,获得第一处理数据;
S202:对第一处理数据进行数据变换,获得第二处理数据;
S203:对第二处理数据进行数据压缩,获得建模数据。
优选的,所述的一种交互式迭代建模方法,S201:对原始数据进行数据清理,获得第一处理数据,包括:
对原始数据进行缺失值补充,获得完整数据;
对完整数据进行光滑去噪,获得去噪数据;
将去噪数据中的离群点和重复数据删除,获得第一处理数据。
优选的,所述的一种交互式迭代建模方法,S202:对第一处理数据进行数据变换,获得第二处理数据,包括:
对第一处理数据进行数据平滑、数据聚集、数据概化和规范化,获得第二处理数据。
优选的,所述的一种交互式迭代建模方法,S203:对第二处理数据进行数据压缩,获得建模数据,包括:
确定出第二处理数据的目标存储变量类型;
基于目标变量存储类型,对第二处理数据进行压缩处理,获得建模数据。
优选的,所述的一种交互式迭代建模方法,S3:对最新获得的建模数据进行特征衍生,获得衍生后的建模数据,并通过设定过滤规则对衍生后的建模数据进行样本筛选,获得样本筛选后的建模数据,包括:
基于建模人员输入的选择指令确定出对应的特征衍生逻辑,基于特征衍生逻辑确定出第一特征衍生规则,基于第一特征衍生规则对建模数据进行特征衍生,获得第一衍生数据;
对建模数据进行分类,获得分类字段和每个分类字段的分类数据集,将所有分类字段汇总获得分类字段集群,将分类字段集群与预设分类字段集群库中的每个预设分类字段集群进行匹配,并确定出对应的匹配度,将最大匹配度对应的预设分类字段集群的字段维度衍生方式当作当前维度衍生方式,基于当前维度衍生方式对分类字段进行分类维度衍生,获得衍生特征维度;
基于衍生特征维度对应的当前维度衍生方式,确定出被衍生分类字段和维度衍生逻辑;
确定出每个分类数据集的自变量,基于预设区间数在自变量维度对分类数据集进行等区间离散化,获得预设区间数个区间数据,将每个分类数据集包含的所有区间数据汇总,获得对应分类字段的离散分类数据集;
基于维度衍生逻辑,对对应被衍生分类字段的离散分类数据集进行交叉衍生,获得第二衍生数据;
将第一衍生数据和第二衍生数据以及建模数据进行汇总,获得衍生后的建模数据;
并通过设定过滤规则对衍生后的建模数据进行样本筛选,获得样本筛选后的建模数据。
优选的,所述的一种交互式迭代建模方法,基于维度衍生逻辑,对对应被衍生分类字段的离散分类数据集进行交叉衍生,获得第二衍生数据,包括:
计算出离散分类数据集中每个区间数据的卡方值,将每个被衍生分类字段的离散分类数据集中包含的小于卡方值阈值的卡方值从小到大排序,获得卡方值序列,将所有被衍生分类字段的卡方值序列进行对齐,获得对齐序列;
基于对齐序列,确定出所有对齐的卡方值组合,判断出卡方值组合的总数是否超过预设衍生区间总数阈值,若是,则将卡方值组合中每个最新卡方值对应的最新区间数据作为待合并区间数据,获得待合并区间组合;
否则,基于预设区间数和区间数梯度变化值确定出最新区间数,基于最新区间数在自变量维度对分类数据集进行二次等区间离散化,获得最新区间数据,基于最新区间数据的最新卡方值确定出最新卡方值组合,直至最新卡方值组合的总数超过预设衍生区间总数阈值时,则将最新卡方值组合中每个卡方值对应的区间数据作为待合并区间数据,获得待合并区间组合;
基于维度衍生逻辑和所有待合并区间数据组合进行特征衍生,获得多个衍生区间数据,将所有衍生区间数据汇总,获得第二衍生数据。
优选的,所述的一种交互式迭代建模方法,S6:确定出初始模型的超参数,包括:
在建模数据中确定出初始模型的输入数据;
基于业务场景确定出建模算法,基于迭代要求确定出建模算法对应的模型配置参数;
将输入数据和模型配置参数作为初始模型的超参数。
优选的,所述的一种交互式迭代建模方法,基于新的模型参数和最终特征组合进行模型建立,获得本次训练过程的模型和模型报告,包括:
基于新的模型参数和样本筛选后的建模数据中最终特征组合对应的数据,搭建出本次训练过程的模型;
基于本次训练过程搭建出的模型确定出模型性能指标,基于模型性能指标生成本次训练过程的模型报告。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例中一种交互式迭代建模方法流程图;
图2为本发明实施例中又一种交互式迭代建模方法流程图;
图3为本发明实施例中再一种交互式迭代建模方法流程图;
图4为本发明实施例中再一种交互式迭代建模方法流程图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例1:
本发明提供了一种交互式迭代建模方法,参考图1和4,包括:
S1:基于迭代要求确定数据规模,基于数据规模从对应数据来源获取原始数据;
S2:对原始数据进行数据预处理,获得建模数据;
S3:对最新获得的建模数据进行特征衍生,获得衍生后的建模数据,并通过设定过滤规则对衍生后的建模数据进行样本筛选,获得样本筛选后的建模数据;
S4:基于用户输入的筛选指令对样本筛选后的建模数据的特征进行人为筛选,获得第一特征组合;
S5:基于机器学习算法对第一特征组合进行自动化特征筛选,获得第二特征组合,并由用户判断第二特征组合是否满足要求,若是,则将第二特征组合作为最终特征组合,否则,基于新的自动化筛选机制对应的机器学习算法返回执行S4至S5,直至最新获得的第二特征组合满足要求时,则将最新获得的第二特征组合作为最终特征组合;
S6:确定出初始模型的超参数;
S7:基于用户输入的判断指令,判断出初始模型的超参数是否满足要求,若是,则基于超参数获得初始模型,否则,对超参数进行参数自动化调优,获得新的模型参数,基于新的模型参数和最终特征组合进行模型建立,获得本次训练过程的模型和模型报告;
S8:基于模型报告判断出本次训练获得的模型是否满足要求,若是,则将本次训练获得的模型作为最终建模结果,否则,基于新的设定过滤规则返回执行S3至S7,直至最新训练过程获得的模型满足要求时,则将最新训练过程获得的模型作为最终建模结果。
该实施例中,迭代要求即为对初始模型的最终迭代结果要满足的条件,迭代要求包括:置信区间、可容忍误差和标准差值以及迭代终止条件。
该实施例中,数据规模即为原始数据的数据量。
该实施例中,数据来源包含但不限于以下来源:(1)文件,系统支持直接导入数据文件;(2)数据库,系统可以直接连接数据库获取数据库中的数据表作为建模数据;(3)分布式存储系统,系统也可以从hadoop(海杜普,是一个由Apache基金会所开发的分布式系统基础架构)、hive(是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制)等分布式存储系统中获取海量数据作为建模数据。
该实施例中,原始数据即为从数据来源直接导入的数据,原始数据后续经过预处理获得建模数据。
该实施例中,数据预处理包括:数据清理、数据变换、数据压缩。
该实施例中,最新的建模数据即为:在第一次迭代建模过程中,最新的建模数据即为对原始数据进行数据预处理后获得的可用于训练迭代初始模型的数据,在除第一次以外的迭代建模过程中,最新的建模数据即为上次训练迭代过程中基于用户输入的第三筛选指令对建模数据进行筛选后获得新的建模数据。
该实施例中,特征衍生即为利用现有的数据特征进行某种组合生成新的数据特征。
该实施例中,衍生后的建模数据即为对建模数据进行特征衍生后获得的数据。
该实施例中,机器学习算法即为用户设定的用于对样本筛选后的建模数据的特征进行自动化特征筛选的算法,例如:Filter过滤法或者卡方过滤法等。
该实施例中,第一特征组合即为基于用户输入的筛选指令对样本筛选后的建模数据的特征进行人为筛选后获得的特征组合,特征组合即为由样本筛选后的建模数据中的特征进行组合后的特征组合,例如:年龄和贷款年限的组合等,其中,年龄和贷款年限都是特征,其中,人为筛选即为基于用户输入的筛选指令对第一特征组合进行筛选。
该实施例中,第二特征组合即为基于机器学习算法对第一特征组合进行自动化特征筛选后获得的特征组合。
该实施例中,筛选指令即为包含用户对第一特征组合的筛选操作的指令。
该实施例中,由用户判断第二特征组合是否满足要求即为:由用户输入的另一判断指令判断出第二特征组合是否满足要求,该另一判断指令即为用户输入的包含用户判断出第二特征组合是否满足要求的判断结果的指令。
该实施例中,最终特征组合即为对样本筛选后的建模数据的特征进行自动化特征筛选和人为筛选操作之后,并且经过用户输入的第一判断指令判断其满足要求的特征组合。
该实施例中,设定过滤规则即为用户在迭代前设定的的对衍生后的建模数据进行样本筛选的规则,例如:可以是根据专家经验添加的过滤规则,也可以是根据模型发现的画像规则。
该实施例中,初始模型即为基于超参数搭建出的、且需要在本次迭代建模过程中对其进行训练迭代的模型。
该实施例中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据;通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果;超参数包括初始模型的输入数据(变量)和建模算法以及对应的模型配置参数;
其中,建模算法例如有GBDT的建模算法、逻辑回归、规则抽取等;
模型配置参数例如有学习率、子样本比率、正则化系数、损失函数、迭代轮数、树模型的每棵树最大节点数、惩罚机制、归因图等;
其中损失函数包括但不限于:
(1)对数损失函数(logarithmic loss function);
(2)平方损失函数(quadratic loss function);
(3)绝对值损失函数(absolute loss function);
(4)合页损失函数(Hinge loss);
(5)平方损失函数(Square loss);
(6)指数损失函数(exponential loss);
(7)感知损失(perceptron loss)函数;
(8)交叉熵损失函数(Cross-entropy loss function);
(9)平均绝对误差(Mean Absolute Error,MAE);
(10)平均绝对百分比误差(Mean Absolute Percentage Error,MAPE);
进一步的,上述的配置选项可以是手动输入的,也可以是在迭代建模过程中,用户交互后系统自动填写的。
该实施例中,判断指令即为用户输入的包含超参数是否满足要求的判断结果的指令。
该实施例中,基于用户输入的判断指令,判断出初始模型的超参数是否满足要求,即为:
基于判断指令中超参数是否满足要求的判断结果确定出判断出初始模型的超参数是否满足要求。
该实施例中,基于超参数获得初始模型,即为:基于超参数搭建出初始模型。
该实施例中,对超参数进行参数自动化调优,即为:
基于预设的调优方式对超参数进行参数自动化调优。
该实施例中,本实施例中的实时迭代建模方法的系统带有自动化配置给用户提供了多种针对不同应用场景的自动化模型训练功能,用户配置了自动化功能以后,系统会在后台根据自动化配置超参数,进而搭建出初始模型。
该实施例中,模型报告包含初始模型的各种衡量模型性能的指标,如ROC(Receiver Operating Characteristic,受试者工作特征曲线,是反映敏感性和特异性连续变量的综合指标)曲线,AUC(Area Under Curve,ROC曲线的曲线下面积)值,KS(Kolmogorov Smirnov,用于评估模型的分类能力)值、归因图(归因图展示预测变量的缺失情况、不同取值对目标的影响程度的归因关系。)等;如果用户有做自动化配置,自动化的结果也将在模型报告页面展示;同时参与建模的变量也将按照对模型的贡献程度从高到低展示出重要变量排名。用户可以在模型报告页面衡量模型是否符合预期效果,进而做出一些交互进行迭代建模;用户可以根据重要变量排名、画像规则、变量的业务含义等,综合考量,选择一些重要变量跳转的步骤三进行迭代建模;用户可以根据基于自动化配置的超参数生成的初始模型的迭代结果,选择符合预期的自动化模型配置参数继续进行迭代建模。
该实施例中,基于模型报告判断出本次训练获得的模型是否满足要求,即为:
将模型报告展示给用户,并接收用户的反馈指令,该反馈指令中包含了用户判断本次训练获得的模型是否满足要求的判断结果。
该实施例中,最终建模结果即为基于本实施例中的交互式迭代建模方法最终建模获得的模型。
该实施例中,新的设定过滤规则为用户根据上一次训练过程获得的模型报告对上一次训练过程中采用的设定过滤规则进行调整后后获得的新的设定过滤规则。
以上技术的有益效果为:基于用户在迭代建模过程中输入的指令对迭代建模过程进行干预,提高迭代建模的效率,使得模型开发过程是可把控、可理解、可干预的,可以不断地基于现有模型进行快速优化迭代,使得每一次模型训练不再独立,而是变成一种迭代过程,从而提高了训练模型的效率,无需较高的编程能力即可实现在更短的时间内训练出更好的模型。
实施例2:
在实施例1的基础上,所述的一种交互式迭代建模方法,S1:基于迭代要求确定数据规模,基于数据规模从对应数据来源获取原始数据,参考图2,包括:
S101:基于迭代要求确定置信区间、可容忍误差和标准差值;
S102:基于置信区间、可容忍误差和标准差值,计算出数据规模;
S103:基于数据规模从对应数据来源获取原始数据。
该实施例中,基于置信区间、可容忍误差和标准差值,计算出数据规模,包括:
基于置信区间对应的置信度下对应的常数、可容忍误差和标准差值,计算出数据规模:
式中,N为数据规模,c为置信区间对应的置信度下对应的常数,m为标准差值,α为可容忍误差;
例如,想要计算某产品的均价,在保证95%的置信度,30000的单品价格标准差值,价格误差在10000以内的条件下,统计多少个产品的价格最佳(即数据规模):
其中,1.96为标准正泰分布在95%的置信度下对应的常数,30000即为标准差值,10000为可容忍误差。
该实施例中,基于数据规模从对应数据来源获取原始数据,即为:从对应数据来源获取数据规模对应的数据量的数据作为原始数据。
以上技术的有益效果为:基于迭代要求中的置信区间、可容忍误差和标准差值计算出数据规模,确定了需要导入的数据量,保证了获取的原始数据量合理。
实施例3:
在实施例1的基础上,所述的一种交互式迭代建模方法,S2:对原始数据进行数据预处理,获得建模数据,参考图3,包括:
S201:对原始数据进行数据清理,获得第一处理数据;
S202:对第一处理数据进行数据变换,获得第二处理数据;
S203:对第二处理数据进行数据压缩,获得建模数据。
该实施例中,第一处理数据即为对原始数据进行数据清洗后获得的数据。
该实施例中,第二处理数据即为对第一处理数据进行数据变换后获得的数据。
该实施例中,建模数据即为对第二处理数据进行数据压缩后获得的数据。
以上技术的有益效果为:通过对原始数据进行户数清理、数据变换、数据压缩,实现对原始数据的预处理,获得可以训练初始模型的数据。
实施例4:
在实施例3的基础上,所述的一种交互式迭代建模方法,S201:对原始数据进行数据清理,获得第一处理数据,包括:
对原始数据进行缺失值补充,获得完整数据;
对完整数据进行光滑去噪,获得去噪数据;
将去噪数据中的离群点和重复数据删除,获得第一处理数据。
该实施例中,完整数据即为对原始数据进行缺失值补充后获得的数据。
该实施例中,去噪数据即为对完整数据进行光滑去噪后获得的数据。
该实施例中,第一处理数据即为将去噪数据中的离群点和重复数据删除后获得的数据。
该实施例中,缺失值补充通过填充默认值、均值、众数、KNN填充、以及把缺失值作为新的label通过模型来预测等方式来实现。
以上技术的有益效果为:通过对原始数据的缺失值补充、去噪、异常数据和重复数据的清除,实现了对原始数据的预处理。
实施例5:
在实施例3的基础上,所述的一种交互式迭代建模方法,S202:对第一处理数据进行数据变换,获得第二处理数据,包括:
对第一处理数据进行数据平滑、数据聚集、数据概化和规范化,获得第二处理数据。
该实施例中,数据平滑即为去除数据中的噪声,将连续的数据离散化,可采用分箱、聚类和回归的方式进行数据平滑。
该实施例中,数据聚集即为对数据进行汇总,在SQL中有一些聚集函数,如:Max()、Sum()。
该实施例中,数据概化即为用较高的概念替换较低的概念,如:上海、北京、深圳可以概化为中国。
该实施例中,数据规范化即为使属性数据按比例缩放,将原来的数据映射到一个新的特定区域中。
以上技术的有益效果为:基于对第一处理数据进行数据平滑、数据聚集、数据概化和规范化,实现了对第一处理数据的变换,使得获得的第二处理数据适合训练初始模型。
实施例6:
在实施例3的基础上,所述的一种交互式迭代建模方法,S203:对第二处理数据进行数据压缩,获得建模数据,包括:
确定出第二处理数据的目标存储变量类型;
基于目标变量存储类型,对第二处理数据进行压缩处理,获得建模数据。
该实施例中,目标存储变量类型即为第二处理数据被存储的目标基本数据类型,例如整数型、单精度浮点数型、双精度浮点型。
该实施例中,数据读入计算机内存时,通常都以系统默认类型存储如32位的整形或64位的浮点型,然后很多数据集中的具体特征取值范围通常都不需要如此大的变量类型来存储,因此如果把变量类型自适应压缩至合适的类型,能减少建模对系统资源的消耗;
进一步的,为了方便对同一数据进行多次迭代建模,系统会把预处理完的数据保存起来,以便于下次用同一份数据进行建模时,省略数据导入和数据预处理两个步骤,加快迭代模型的速度。
以上技术的有益效果为:把第二处理数据的变量存储类型自适应压缩至合适的类型,能减少建模对系统资源的消耗。
实施例7:
在实施例1的基础上,所述的一种交互式迭代建模方法,S3:对最新获得的建模数据进行特征衍生,获得衍生后的建模数据,并通过设定过滤规则对衍生后的建模数据进行样本筛选,获得样本筛选后的建模数据,包括:
基于建模人员输入的选择指令确定出对应的特征衍生逻辑,基于特征衍生逻辑确定出第一特征衍生规则,基于第一特征衍生规则对建模数据进行特征衍生,获得第一衍生数据;
对建模数据进行分类,获得分类字段和每个分类字段的分类数据集,将所有分类字段汇总获得分类字段集群,将分类字段集群与预设分类字段集群库中的每个预设分类字段集群进行匹配,并确定出对应的匹配度,将最大匹配度对应的预设分类字段集群的字段维度衍生方式当作当前维度衍生方式,基于当前维度衍生方式对分类字段进行分类维度衍生,获得衍生特征维度;
基于衍生特征维度对应的当前维度衍生方式,确定出被衍生分类字段和维度衍生逻辑;
确定出每个分类数据集的自变量,基于预设区间数在自变量维度对分类数据集进行等区间离散化,获得预设区间数个区间数据,将每个分类数据集包含的所有区间数据汇总,获得对应分类字段的离散分类数据集;
基于维度衍生逻辑,对对应被衍生分类字段的离散分类数据集进行交叉衍生,获得第二衍生数据;
将第一衍生数据和第二衍生数据以及建模数据进行汇总,获得衍生后的建模数据;
并通过设定过滤规则对衍生后的建模数据进行样本筛选,获得样本筛选后的建模数据。
该实施例中,基于建模人员输入的选择指令确定出对应的特征衍生逻辑,包括:
根据建模人员结合专家经验后输入的的选择指令(即为用于选择特征衍生逻辑的指令)确定出对应的特征衍生逻辑。
该实施例中,特征衍生逻辑即为对建模数据进行特征衍生的逻辑方式,例如:
交叉衍生,将两个及以上的变量混合衍生;
自动化的变量分箱衍生,把变量划分为多个分段后,计算每一分段里面的正样本比率、负样本比率,然后利用两个比率相除求得的值作为该箱的新值;可以降低异常值的影响,增加模型的稳定性;增加变量的可解释性;增加变量的非线性;增加模型的预测效果;支持衍生的特征类型包括但不限于,箱号-类别型、箱号-数值型、WOE、目标占比、卡方分箱等;
规则衍生,根据模型发现的画像规则进行自动化规则衍生;
独热编码衍生,将分类变量作为二进制向量的表示,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点,会让特征之间的距离计算更加合理;
等频衍生,区间的边界值要经过选择,使得每个区间包含大致相等的实例数量;
等宽衍生,从最小值到最大值之间,均分未N等份,这样,如果A,B未最小最大值,则每个区间的长度未W=(B-A)/N,则区间边界值为A+W,A+2W,…,A+(N-1)W;
多项式衍生,按照指定的阶数(最高次数),进行多项式操作从而衍生出新变量,这类的转换可以适当地提升模型的拟合能力,对于在线性回归模型上的应用较为广泛,如阶数为2,将进行二项式的衍生。
该实施例中,第一特征衍生规则即为基于特征衍生逻辑确定出的特征衍生规则,即为用于对建模数据进行特征衍生的方法。
该实施例中,分类字段即为将建模数据按照属性进行分类之后获得的表征对应属性含义的字段。
该实施例中,分类数据集即为将建模数据按照属性进行分类之后获得的每个属性对应的数据集合。
该实施例中,分类字段集群即为将所有分类字段汇总后获得的集合。
该实施例中,预设分类字段集群库即为存储预设分类字段集群的数据库。
该实施例中,预设分类字段集群即为预先准备的由多个分类字段构成的集群以及包含的分类字段之间的维度衍生方式。
该实施例中,将分类字段集群与预设分类字段集群库中的每个预设分类字段集群进行匹配,并确定出对应的匹配度,包括:
式中,ρ为分类字段集群与预设分类字段集群库中当前计算的预设分类字段集群之间的匹配度,exp即为以自然常数e为底的指数函数,e的取值为2.72,z为分类字段集群与预设分类字段集群库中当前计算的预设分类字段集群中包含的相同的分类字段,z
例如,z为5,z
该实施例中,当前维度衍生方式即为最大匹配度对应的预设分类字段集群的字段维度衍生方式。
该实施例中,基于当前维度衍生方式对分类字段进行分类维度衍生,获得衍生特征维度,例如:
当前维度衍生方式为将分类字段A的分类数据集和分类字段B的分类数据集组合衍生出分类字段C的衍生数据;
则将分类字段A的分类数据集和分类字段B的分类数据集组合衍生出分类字段C(即为新的衍生特征维度)的衍生数据。
该实施例中,被衍生分类字段即为基于衍生特征维度对应的当前维度衍生方式确定出的被衍生的分类字段,例如,当前维度衍生方式为将分类字段A的分类数据集和分类字段B的分类数据集交叉衍生出分类字段C的衍生数据,则类字段A和分类字段B为被衍生的分类字段。
该实施例中,维度衍生逻辑即为衍生特征维度被衍生时采用的特征衍生逻辑,和基于建模人员输入的选择指令确定出的特征衍生逻辑中可能的特征衍生方式种类范围一致。
该实施例中,自变量即为分类数据集变化的自变量。
该实施例中,预设区间数即为预先设置的、在自变量维度对分类数据集进行初次等区间离散化时,需要离散的区间数。
该实施例中,离散分类数据集即为将每个分类数据集包含的所有区间数据汇总后获得的对应分类字段的集合。
该实施例中,第二衍生数据即为基于维度衍生逻辑,对对应被衍生分类字段的离散分类数据集进行交叉衍生后获得的衍生数据
该实施例中,衍生数据即为将第一衍生数据和第二衍生数据进行汇总后获得的数据。
以上技术的有益效果为:基于建模人员输入的选择指令对建模数据进行特征衍生,通过对建模数据进行分类后获得的分类字段和分类数据集与预设份额里字段集群进行匹配,确定出维度衍生方式,对基于对分类数据集进行等区间离散化后获得的离散分类数据集进行特征衍生,实现了基于建模人员输入的选择指令和对建模数据进行自适应衍生两种方法对建模数据进行特征衍生,使得获得足够的、合理的衍生数据,提高了初始模型的迭代效率。
实施例8:
在实施例7的基础上,所述的一种交互式迭代建模方法,基于维度衍生逻辑,对对应被衍生分类字段的离散分类数据集进行交叉衍生,获得第二衍生数据,包括:
计算出离散分类数据集中每个区间数据的卡方值,将每个被衍生分类字段的离散分类数据集中包含的小于卡方值阈值的卡方值从小到大排序,获得卡方值序列,将所有被衍生分类字段的卡方值序列进行对齐,获得对齐序列;
基于对齐序列,确定出所有对齐的卡方值组合,判断出卡方值组合的总数是否超过预设衍生区间总数阈值,若是,则将卡方值组合中每个最新卡方值对应的最新区间数据作为待合并区间数据,获得待合并区间组合;
否则,基于预设区间数和区间数梯度变化值确定出最新区间数,基于最新区间数在自变量维度对分类数据集进行二次等区间离散化,获得最新区间数据,基于最新区间数据的最新卡方值确定出最新卡方值组合,直至最新卡方值组合的总数超过预设衍生区间总数阈值时,则将最新卡方值组合中每个卡方值对应的区间数据作为待合并区间数据,获得待合并区间组合;
基于维度衍生逻辑和所有待合并区间数据组合进行特征衍生,获得多个衍生区间数据,将所有衍生区间数据汇总,获得第二衍生数据。
该实施例中,计算出离散分类数据集中每个区间数据的卡方值,包括:
式中,A
该实施例中,卡方值阈值即为根据显著性水平和自由度得到的卡方值,自由度比离散分类数据集的类别数量小1,例如,离散分类数据集有3类,自由度为2,则90%置信度(10%显著性水平)下,卡方的值为4.6。
该实施例中,卡方值序列即为将每个被衍生分类字段的离散分类数据集中包含的小于卡方值阈值的卡方值从小到大排序后获得的序列。
该实施例中,对齐序列即为将所有被衍生分类字段的卡方值序列进行对齐后获得的对齐的序列。
该实施例中,卡方值组合即为对齐序列中对齐的卡方值构成的组合。
该实施例中,待合并区间数据即为卡方值组合总数超过预设衍生区间总数阈值时,卡方值组合中每个卡方值对应的区间数据。
该实施例中,待合并区间组合即为卡方值组合中每个卡方值对应的区间数据构成的组合。
该实施例中,区间数梯度变化值即为每次在自变量维度对分类数据集进行等区间离散化时相对于上一次等区间离散化过程中采用的区间数而言,增加的区间数。
该实施例中,最新区间数即为预设区间数和区间数梯度变化值的和。
该实施例中,最新区间数据即为基于最新区间数在自变量维度对分类数据集进行二次等区间离散化后获得的新的区间数据。
该实施例中,最新卡方值即为最新区间数据的卡方值。
该实施例中,最新卡方值组合即为基于最新区间数据的最新卡方值确定出的新的卡方值组合。
该实施例中,基于维度衍生逻辑和所有待合并区间数据组合进行特征衍生,获得多个衍生区间数据,即为:
当维度衍生逻辑对应的衍生方式为将待合并区间数据A和待合并区间数据B交叉衍生出待合并区间数据C,则待合并区间数据C为衍生区间数据。
该实施例中,衍生区间数据即为基于维度衍生逻辑和所有待合并区间数据组合进行特征衍生后获得的区间数据。
该实施例中,预设衍生区间总数阈值即为预先确定的需要衍生出获得的区间数据的最小区间总数。
该实施例中,第二衍生数据即为将所有衍生区间数据汇总后获得的数据。
以上技术的有益效果为:基于对离散分类数据集中的区间数据的卡方值进行排序、对齐、组合、组合总数判断,判断出当前等区间离散获得的衍生区间数据是否满足预设衍生区间总数阈值,进而部件实现了对分类数据集的等区间离散化,也保证了最后衍生获得的数据满足衍生要求。
实施例9:
在实施例1的基础上,所述的一种交互式迭代建模方法,S6:确定出初始模型的超参数,包括:
在建模数据中确定出初始模型的输入数据;
基于业务场景确定出建模算法,基于迭代要求确定出建模算法对应的模型配置参数;
将输入数据和模型配置参数作为初始模型的超参数。
该实施例中,输入数据即为在建模数据中确定出的用于输入至初始模型中进行模型训练的数据。
该实施例中,建模算法例如有GBDT的建模算法、逻辑回归、规则抽取等;
该实施例中,模型配置参数例如有学习率、子样本比率、正则化系数、损失函数、迭代轮数、树模型的每棵树最大节点数、惩罚机制、归因图等;
其中损失函数包括但不限于:
(1)对数损失函数(logarithmic loss function);
(2)平方损失函数(quadratic loss function);
(3)绝对值损失函数(absolute loss function);
(4)合页损失函数(Hinge loss);
(5)平方损失函数(Square loss);
(6)指数损失函数(exponential loss);
(7)感知损失(perceptron loss)函数;
(8)交叉熵损失函数(Cross-entropy loss function);
(9)平均绝对误差(Mean Absolute Error,MAE);
(10)平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)。
以上技术的有益效果为:为后续确定出初始模型并对其进行训练提供了数据基础。
实施例10:
在实施例1的基础上,所述的一种交互式迭代建模方法,基于新的模型参数和最终特征组合进行模型建立,获得本次训练过程的模型和模型报告,包括:
基于新的模型参数和样本筛选后的建模数据中最终特征组合对应的数据,搭建出本次训练过程的模型;
基于本次训练过程搭建出的模型确定出模型性能指标,基于模型性能指标生成本次训练过程的模型报告。
该实施例中,基于新的模型参数和样本筛选后的建模数据中最终特征组合对应的数据,搭建出本次训练过程的模型,即为:
将样本筛选后的建模数据中最终特征组合对应的数据划分为训练数据和检验数据;
基于新的模型参数和训练数据搭建出初始模型;
将检验数据输入至初始模型进行训练,获得本次训练过程的模型。
该实施例中,基于本次训练过程搭建出的模型确定出模型性能指标,即为:基于预设的性能指标评估方式对本次训练过程搭建出的模型进行评估,确定出表征模型性能的模型性能指标。
以上技术的有益效果为:实现将建模数据中第二筛选特征对应的子建模数据和筛选衍生数据输入至初始模型进行训练,获得训练后的模型和表征训练出的模型的性能的模型报告。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。