一种基于springbatch批量读取定长文件的方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及数据处理技术领域,特别涉及一种基于springbatch批量读取定长文件的方法。
背景技术
目前使用springBatch进行文件批处理时,主要步骤为ItemReader(从数据源读取数据)、ItemProcessor(对读取的数据进行处理)、ItemWriter(存储处理后的数据)。通常是逐条读取并按分隔符或者字节数进行文件内容的解析,但是在金融场景下,文件内容一般是字节定长,有英文、数字和汉字等各类字符,不同的字符类型有时单个字符的字节数不同。
现有技术中,批量读取文件是通过FlatFileItemReader类进行文件读取,该类通过设置分隔符或者固定字符长度读取行内容,但无法读取和处理固定字节长度的内容。
因此有必要提供一种基于springbatch批量读取定长文件的方法,以读取并处理固定字节长度的内容。
发明内容
本发明的目的在于提供一种基于springbatch批量读取定长文件的方法,以读取并处理固定字节长度的内容。
为了解决现有技术中存在的问题,本发明提供了一种基于springbatch批量读取定长文件的方法,包括以下步骤:
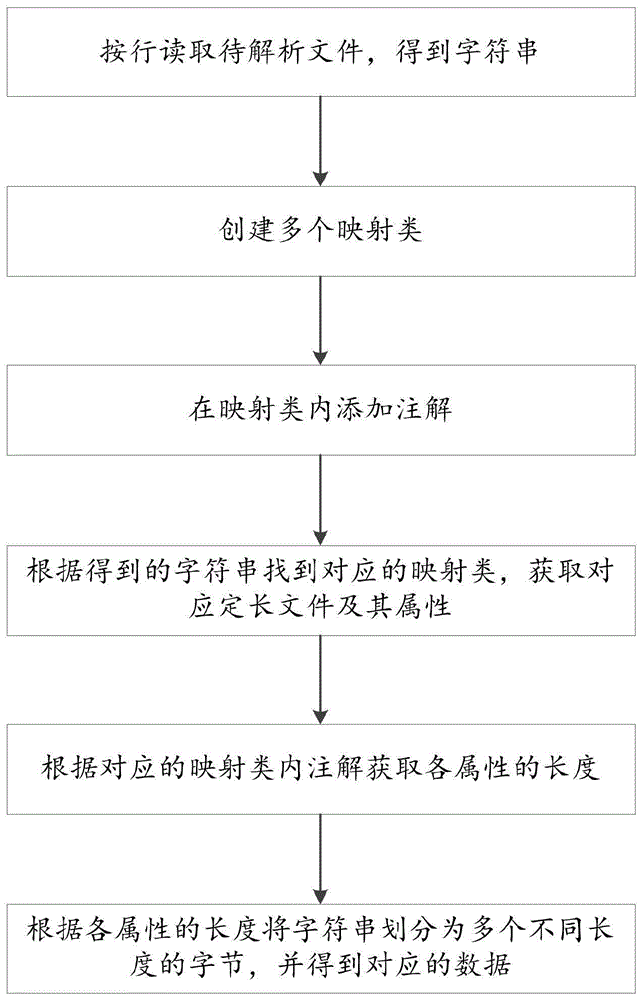
按行读取待解析文件,得到字符串;
创建多个映射类,各映射类包括定长文件及其不同属性;
在映射类内添加注解,所述注解包括所述属性及各所述属性的长度;
根据得到的字符串找到对应的映射类,获取对应定长文件及其属性;
根据对应的映射类内注解获取各属性的长度;
根据各属性的长度将字符串划分为多个不同长度的字节,并得到对应的数据。
可选的,在所述基于springbatch批量读取定长文件的方法中,按行读取待解析文件的实现方式为:在读取待解析文件的接口设置FiledSetMapper属性。
可选的,在所述基于springbatch批量读取定长文件的方法中,根据不同的定长文件创建不同的映射类。
可选的,在所述基于springbatch批量读取定长文件的方法中,所述注解还包括属性的序号和/或属性的类型。
可选的,在所述基于springbatch批量读取定长文件的方法中,还包括以下步骤:将得到的数据进行写操作。
可选的,在所述基于springbatch批量读取定长文件的方法中,写操作时,根据预设格式进行右补空格或左补0。
可选的,在所述基于springbatch批量读取定长文件的方法中,对完成写操作后的数据做持久化处理。
可选的,在所述基于springbatch批量读取定长文件的方法中,所述持久化处理包括保存至数据库。
在本发明所提供的基于springbatch批量读取定长文件的方法中,通过按行读取待解析文件,得到字符串,并通过获取映射类注解中的属性长度将字符串划分,从而可以读取并处理固定字节长度的内容,因此可以区分并处理英文、数字和汉字等各类字符。
附图说明
图1为本发明实施例提供的批量读取定长文件的方法的流程图。
具体实施方式
下面将结合示意图对本发明的具体实施方式进行更详细的描述。根据下列描述,本发明的优点和特征将更清楚。需说明的是,附图均采用非常简化的形式且均使用非精准的比例,仅用以方便、明晰地辅助说明本发明实施例的目的。
在下文中,如果本文所述的方法包括一系列步骤,本文所呈现的这些步骤的顺序并非必须是可执行这些步骤的唯一顺序,且一些所述的步骤可被省略和/或一些本文未描述的其他步骤可被添加到该方法。
现有技术中,批量读取文件是通过FlatFileItemReader类进行文件读取,该类通过设置分隔符或者固定字符长度读取行内容,但无法读取和处理固定字节长度的内容。
为了解决现有技术中存在的问题,本发明提供了一种基于springbatch批量读取定长文件的方法,如图1所示,包括以下步骤:
按行读取待解析文件,得到字符串;
创建多个映射类,各映射类包括定长文件及其不同属性;
在映射类内添加注解,所述注解包括所述属性及各所述属性的长度;
根据得到的字符串找到对应的映射类,获取对应定长文件及其属性;
根据对应的映射类内注解获取各属性的长度;
根据各属性的长度将字符串划分为多个不同长度的字节,并得到对应的数据。
进一步的,按行读取待解析文件的实现方式为:创建实现FiledSetMapper接口的类,该类用于配置FlatFileItemReader中lineMapper的FiledSetMapper属性,可实现对于文件整行的读取。读取时,设置ItemReader的文件路径属性,设置编码格式。
可选的,在所述基于springbatch批量读取定长文件的方法中,本发明中根据不同的定长文件创建不同的映射类,所述映射类包括定长文件及其不同属性。并且,所述注解包括所述属性及各所述属性的长度、序号和/或类型等。例如账户同步文件如果定长是30位,其中第1至10位是账号,第11位至30位是卡号,那么注解中的属性为账号时,其长度为10位,属性为卡号时,其长度为20位。
通常的,所述方法还包括以下步骤:将得到的数据进行写操作。写操作之前,得到的数据可能已经根据其他格式进行处理,例如数据为00010,则可能处理为10,那么在写操作时,根据预设格式进行右补空格或左补0,若预设格式是6位,则需要左补4个0,写为000010。
优选的,对完成写操作后的数据做持久化处理。所述持久化处理可以为保存至数据库。
综上,在本发明所提供的基于springbatch批量读取定长文件的方法中,通过按行读取待解析文件,得到字符串,并通过获取映射类注解中的属性长度将字符串划分,从而可以读取并处理固定字节长度的内容,因此可以区分并处理英文、数字和汉字等各类字符。
上述仅为本发明的优选实施例而已,并不对本发明起到任何限制作用。任何所属技术领域的技术人员,在不脱离本发明的技术方案的范围内,对本发明揭露的技术方案和技术内容做任何形式的等同替换或修改等变动,均属未脱离本发明的技术方案的内容,仍属于本发明的保护范围之内。