一种字体版权检测方法及装置
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及字体检测技术领域,尤其涉及一种字体版权检测方法及装置。
背景技术
随着计算机时代的到来,字体库已成为人们工作生活的一部分。字体均由人工设计,它们是由各个字体设计师在汉字或其它文字的基础上,对笔画、视觉、架构等元素进行的二次创作。字体是有版权的,是受著作权保护的,为了避免在未获授权使用字体时被认定为侵权的情况,需要对字体版权进行检测。
目前市场上的字体版权检测工具无法支持剔除企业已购买的字体,所以会误判断企业已购买的、且已使用的字体为侵权字体,从而导致字体版权检测精度不高。
发明内容
本发明实施例提供一种字体版权检测方法及装置,提高了对于字体版权的检测精度。
本申请实施例的第一方面提供了一种字体版权检测方法,包括:
根据预设配置文件,获取已购买字体列表和公共免费字体列表;
识别待检测文本信息中所使用的第一字体,根据已购买字体列表和公共免费字体列表对第一字体进行对比,生成对比结果;
根据对比结果,检测第一字体是否拥有版权。
在第一方面的一种可能的实现方式中,识别待检测文本信息中所使用的第一字体,具体为:
根据源代码文件的文件后缀,读取包含不同程序语言种类的第一文本信息,并将第一文本信息作为待检测文本信息;
根据程序语言种类,从待检测文本信息中分析语法特点和关键字用法,根据分析结果识别出待检测文本信息中所使用的字体,并作为第一字体。
在第一方面的一种可能的实现方式中,还包括:
将第一图片输入至字体分类模型中,以使字体分类模型获取第一图片中的待检测文本信息后,检测待检测文本信息中所使用的字体,并作为第一字体。
在第一方面的一种可能的实现方式中,根据对比结果,检测第一字体是否拥有版权,具体为:
当根据对比结果判定第一字体属于已购买字体列表或公共免费字体列表时,第一字体拥有版权;
当根据对比结果判定第一字体不属于已购买字体列表或公共免费字体列表时,第一字体不拥有版权。
在第一方面的一种可能的实现方式中,还包括:
当第一字体不拥有版权时,若第一字体源于源代码文件,则存储源代码文件的文件路径、文件名以及第一字体;若第一字体源于第一图片,则存储第一图片的图片路径以及图片名。
在第一方面的一种可能的实现方式中,还包括:
根据预设配置文件,获取可排除文件列表;
当某一文件属于可排除文件列表时,不对某一文件进行字体版权检测。
在第一方面的一种可能的实现方式中,字体分类模型的训练过程具体为:
将训练图片集输入至深度学习模型中,以使深度学习模型根据训练图片集进行训练,直至深度学习模型收敛,训练完毕并生成字体分类模型;其中,训练图片集包括:含有已购买字体和公共免费字体的图片。
本申请实施例的第二方面提供了一种字体版权检测装置,包括:获取模块、对比模块和检测模块;
其中,获取模块用于根据预设配置文件,获取已购买字体列表和公共免费字体列表;
对比模块用于识别待检测文本信息中所使用的第一字体,根据已购买字体列表和公共免费字体列表对第一字体进行对比,生成对比结果;
检测模块用于根据对比结果,检测第一字体是否拥有版权。
在第二方面的一种可能的实现方式中,识别待检测文本信息中所使用的第一字体,具体为:
根据源代码文件的文件后缀,读取包含不同程序语言种类的第一文本信息,并将第一文本信息作为待检测文本信息;
根据程序语言种类,从待检测文本信息中分析语法特点和关键字用法,根据分析结果识别出待检测文本信息中所使用的字体,并作为第一字体。
在第二方面的一种可能的实现方式中,还包括:
将第一图片输入至字体分类模型中,以使字体分类模型获取第一图片中的待检测文本信息后,检测待检测文本信息中所使用的字体,并作为第一字体。
相比于现有技术,本发明实施例提供的一种字体版权检测方法及装置,所述方法包括:根据预设配置文件,获取已购买字体列表和公共免费字体列表;识别待检测文本信息中所使用的第一字体,根据已购买字体列表和公共免费字体列表对第一字体进行对比,生成对比结果;根据对比结果,检测第一字体是否拥有版权。
其有益效果在于:本发明实施例在检测字体版权的过程中不仅根据公共免费字体进行对比,还根据已购买字体进行对比,能够在判定所使用的字体是否拥有版权的过程中把考虑每个企业已经购买的字体,从而避免现有技术中将企业已购买的、且已使用的字体为侵权字体而导致的误判断的问题,提高了对于字体版权的检测精度。
进一步地,本发明实施例能够对系统中所有源代码文件和所有含有字体的图片信息进行字体版权检测,实现了对于系统内字体版权的全面检测,克服了现有技术中由于只针对计算机上安装的字体库进行检查或者是识别图片以进行字体版权检测而导致的检测不全面的问题。
再者,本发明实施例实现了字体版权的自动化检测,能够避免现有技术因需人工截取图片、上传图片以及手工搜索关键字等操作而导致的效率低下问题,大大提高了字体版权的检测效率。
最后,本发明实施例能够从各个企业的实际需求出发,设定预设配置文件,能根据企业实际情况配置已购买字体列表,并且能根据系统实际情况配置无需检查文件,灵活方便。
附图说明
图1是本发明一实施例提供的一种字体版权检测方法的流程示意图;
图2是本发明一实施例提供的字体版权检测系统的结构示意图;
图3是本发明一实施例提供的一种字体版权检测装置的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
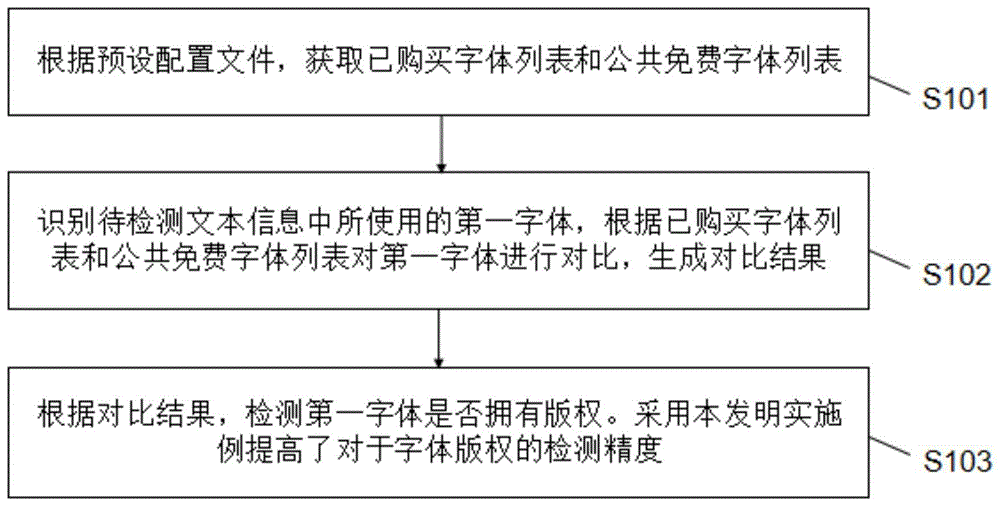
参照图1,是本发明一实施例提供的一种字体版权检测方法的流程示意图,包括S101-S103:
S101:根据预设配置文件,获取已购买字体列表和公共免费字体列表。
其中,所述预设配置文件能够根据不同的实际需求进行设置。
S102:识别待检测文本信息中所使用的第一字体,根据已购买字体列表和公共免费字体列表对第一字体进行对比,生成对比结果。
在本实施例中,所述识别待检测文本信息中所使用的第一字体,具体为:
根据源代码文件的文件后缀,读取包含不同程序语言种类的第一文本信息,并将所述第一文本信息作为待检测文本信息;
根据所述程序语言种类,从所述待检测文本信息中分析语法特点和关键字用法,根据分析结果识别出所述待检测文本信息中所使用的字体,并作为所述第一字体。
其中,所述源代码文件包括:Html、Css、JavaScript、Java、C和Python。
在一具体实施例中,还包括:
将第一图片输入至字体分类模型中,以使所述字体分类模型获取所述第一图片中的所述待检测文本信息后,检测所述待检测文本信息中所使用的字体,并作为所述第一字体。
在一具体实施例中,所述字体分类模型的训练过程具体为:
将训练图片集输入至深度学习模型中,以使所述深度学习模型根据所述训练图片集进行训练,直至所述深度学习模型收敛,训练完毕并生成所述字体分类模型;其中,所述训练图片集包括:存在已购买字体和公共免费字体的图片。
S103:根据对比结果,检测第一字体是否拥有版权。
在本实施例中,所述根据所述对比结果,检测所述第一字体是否拥有版权,具体为:
当根据所述对比结果判定所述第一字体属于所述已购买字体列表或所述公共免费字体列表时,所述第一字体拥有版权;
当根据所述对比结果判定所述第一字体不属于所述已购买字体列表或所述公共免费字体列表时,所述第一字体不拥有版权。
在一具体实施例中,还包括:
当所述第一字体不拥有版权时,若所述第一字体源于所述源代码文件,则存储所述源代码文件的文件路径、文件名以及所述第一字体;若所述第一字体源于所述第一图片,则存储所述第一图片的图片路径以及图片名。
在一具体实施例中,还包括:
根据所述预设配置文件,获取可排除文件列表;
当某一文件属于所述可排除文件列表时,不对所述某一文件进行字体版权检测。
进一步地,本发明一具体实施例提供了一种字体版权检测系统,请参照图2,图2是本发明一实施例提供的字体版权检测系统的结构示意图,包括:总控单元201,配置文件读取模块202,侵权字体检查模块203,结果写入模块204。
其中,总控单元201用于实现配置文件读取模块202、侵权字体检查模块203以及结果写入模块204的控制。通过控制配置文件读取模块202来读取自定义的配置信息,比如企业已购买版权字体的信息(即已购买字体列表)、公共免费字体信息(即公共免费字体列表)以及无需检查文件列表信息(即可排除文件列表)。然后通过控制侵权字体检查模块203检查指定系统涉及到使用侵权字体的情况,得到检查结果后,通过控制结果写入模块204,将工具检查的结果写入到结果文件中。
配置文件读取模块202用于读取预设配置文件,预设配置文件包括可安全使用的字体列表和无需检查文件列表(即可排除文件列表),其中,可安全使用字体列表文件包括:已购买字体列表和公共免费字体列表。可安全使用字体列表可用于字体版权检测、识别出侵权字体,无需检查文件列表可以让工具直接过滤部分文件,提升检查效率。
其中,无需检查文件列表主要包括系统的一些第三方依赖库文件,所以对这类文件无需进行检查。
进一步地,读取可安全使用配置文件,在内存中维护一个可安全使用字体列表;读取可排除文件配置文件,在内存中维护一个可排除文件列表。
侵权字体检查模块203的工作流程如下:
首先读取各种程序语言的源代码文件内容,比如Html、Css、JavaScript、Java、C、Python等程序语言,根据文件后缀获取到指定系统中各种程序语言的所有文件,并读取源代码文件的文本信息,并作为待检测文本信息。根据不同程序语言种类,分析出可能用于设置字体的语法和关键字,通过从待检测文本信息中分析语法特点和关键字用法来识别出源代码中所设置的字体,作为第一字体。将第一字体与已购买字体列表和公共免费字体列表进行对比,判断是否使用了未授权字体。如果使用了未授权字体,则将使用了未授权字体的源代码文件的文件路径、文件名和涉及到侵权的文件内容记录起来。
同时,系统基于深度学习的算法,通过学习含有已购买字体和公共免费字体的图片的特征,建立字体分类模型来识别各类图片资源所使用文字的字体,判断是否使用了未授权字体,如果使用了未授权字体,则将使用了未授权字体的图片的路径和名称记录起来。
结果写入模块204:获取侵权字体检查模块203所记录的涉及到使用侵权字体的文件信息和图片信息,并写入到结果文件中。
为了进一步说明字体版权检测装置,请参照图3,图3是本发明一实施例提供的一种字体版权检测装置的结构示意图,包括:获取模块301、对比模块302和检测模块303;
其中,所述获取模块301用于根据预设配置文件,获取已购买字体列表和公共免费字体列表;
所述对比模块302用于识别待检测文本信息中所使用的第一字体,根据所述已购买字体列表和所述公共免费字体列表对所述第一字体进行对比,生成对比结果;
所述检测模块303用于根据所述对比结果,检测所述第一字体是否拥有版权。
在本实施例中,所述识别待检测文本信息中所使用的第一字体,具体为:
根据源代码文件的文件后缀,读取包含不同程序语言种类的第一文本信息,并将所述第一文本信息作为待检测文本信息;
根据所述程序语言种类,从所述待检测文本信息中分析语法特点和关键字用法,根据分析结果识别出所述待检测文本信息中所使用的字体,并作为所述第一字体。
在一具体实施例中,还包括:
将第一图片输入至字体分类模型中,以使所述字体分类模型获取所述第一图片中的所述待检测文本信息后,检测所述待检测文本信息中所使用的字体,并作为所述第一字体。
在一具体实施例中,所述字体分类模型的训练过程具体为:
将训练图片集输入至深度学习模型中,以使所述深度学习模型根据所述训练图片集进行训练,直至所述深度学习模型收敛,训练完毕并生成所述字体分类模型;其中,所述训练图片集包括:含有已购买字体和公共免费字体的图片。
在一具体实施例中,所述根据所述对比结果,检测所述第一字体是否拥有版权,具体为:
当根据所述对比结果判定所述第一字体属于所述已购买字体列表或所述公共免费字体列表时,所述第一字体拥有版权;
当根据所述对比结果判定所述第一字体不属于所述已购买字体列表或所述公共免费字体列表时,所述第一字体不拥有版权。
在本实施例中,还包括:
当所述第一字体不拥有版权时,若所述第一字体源于所述源代码文件,则存储所述源代码文件的文件路径、文件名以及所述第一字体;若所述第一字体源于所述第一图片,则存储所述第一图片的图片路径以及图片名。
在本实施例中,还包括:
根据所述预设配置文件,获取可排除文件列表;
当某一文件属于所述可排除文件列表时,不对所述某一文件进行字体版权检测。
本发明实施例通过获取模块根据预设配置文件,获取已购买字体列表和公共免费字体列表;通过对比模块识别待检测文本信息中所使用的第一字体,根据已购买字体列表和公共免费字体列表对第一字体进行对比,生成对比结果;通过检测模块根据对比结果,检测第一字体是否拥有版权。
本发明实施例在检测字体版权的过程中不仅根据公共免费字体进行对比,还根据已购买字体进行对比,能够在判定所使用的字体是否拥有版权的过程中把考虑每个企业已经购买的字体,从而避免现有技术中将企业已购买的、且已使用的字体为侵权字体而导致的误判断的问题,提高了对于字体版权的检测精度。
进一步地,本发明实施例能够对系统中所有源代码文件和所有含有字体的图片信息进行字体版权检测,实现了对于系统内字体版权的全面检测,克服了现有技术中由于只针对计算机上安装的字体库进行检查或者是识别图片以进行字体版权检测而导致的检测不全面的问题。
再者,本发明实施例实现了字体版权的自动化检测,能够避免现有技术因需人工截取图片、上传图片以及手工搜索关键字等操作而导致的效率低下问题,大大提高了字体版权的检测效率。
最后,本发明实施例能够从各个企业的实际需求出发,设定预设配置文件,能根据企业实际情况配置已购买字体列表,并且能根据系统实际情况配置无需检查文件,灵活方便。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 一种字体转换的方法、装置、设备及计算机可读存储介质
- 一种欺诈检测模型训练方法和装置及欺诈检测方法和装置
- 一种用于焦距检测的双刀口差分检测装置、检测方法及数据处理方法
- 一种电梯轿厢意外移动保护装置安全性能检测装置及检测方法
- 一种数字声音的版权保护和获取方法、装置以及设备
- 一种检测字体版权信息的方法、装置、终端及存储介质
- 字体版权检测方法、介质、计算机设备及装置