一种金属表面缺陷语义分割网络及相应策略
文献发布时间:2023-06-19 19:27:02
技术领域
本发明涉及图像语义分割领域,尤其涉及一种针对金属表面缺陷检测的图像语义分割方法与策略。
背景技术
图像语义分割是计算机视觉的重要研究方向之一,其目的是将输入图像按照语义信息进行像素级别的类别划分。工业生产中,金属表面缺陷尺度信息对于产品合格率至关重要,而金属表面进行像素级别语义分割是实现尺度测量的前提。
不同于自然图像数据,金属表面缺陷检测,因为工业上的生产实际,缺陷样本往往十分稀少,同时缺陷尺度微小、对比度低、边界轮廓不清晰。因为上诉问题的存在,所以训练过程中往往会造成假阳性或假阴性分类,造成对金属表面图像中像素的错误分类。
在目前,因为上述技术难题,包含SegNet、Unet、FCN、DeepLabv3+等网络都不能较好的实现对金属表面缺陷的语义分割。
发明内容
为了解决上述技术难题,本发明提供了一种金属表面缺陷语义分割网络与相应策略,可以显著提高金属表面缺陷语义分割的精度。
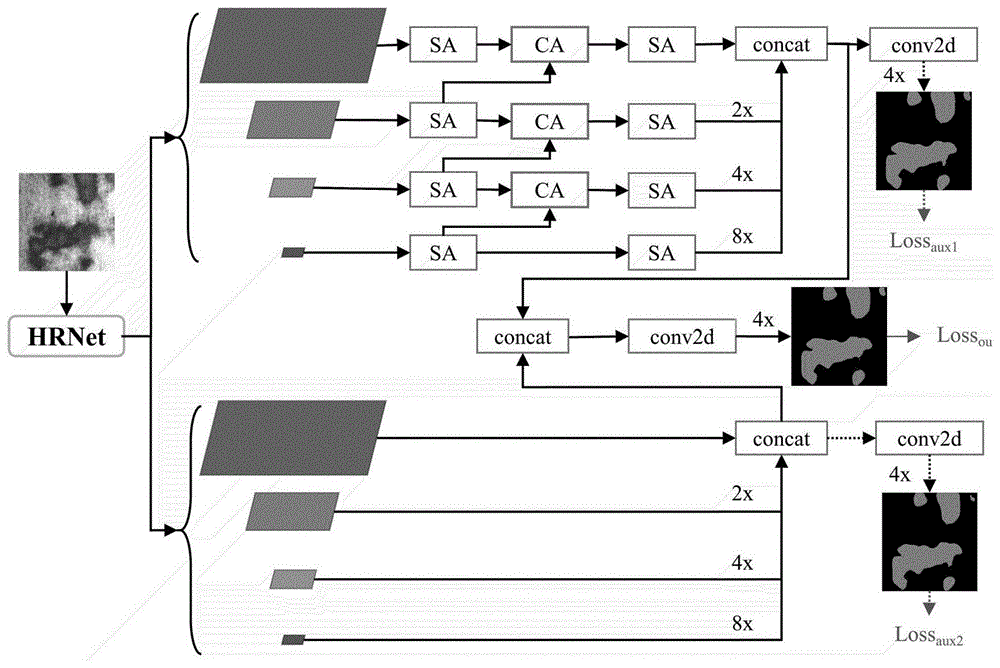
在公开的技术方法中,金属表面缺陷语义分割网络包含有HRNet特征提取器。原图像经过双线性插值操作后,通过HRNet特征提取器生成多尺度特征信息图,相对于原输入图像,尺度分别变成1/4、1/8、1/16、1/32。随后,四个不同尺度的特征图分为2个支路。
第一个支路中,多尺度特征图各自经过一个独立的空间注意力模块,接下来,相邻的2个多尺度信息再通过独立的通道注意力进行融合,并再次经过一个独立的空间注意力模块,获得含有丰富语义与纹理信息的多尺度特征图,最后将多尺度特征图经过插值,插值到原图像1/4尺度层面并拼接。
第二个支路中,多尺度特征图直接通过上采样,线性插值到原图像1/4尺度并拼接。
对以上两个分支获得的特征信息拼接,获得第三个分支。
对以上三个特征分支各自经过一个卷积块,将通道压缩到类别数量。再经过上采样,到原图像尺度,并与标签真值进行损失计算。
在公开相应策略中,包含归一化均方频率类别权重策略、偏权重训练采样策略、类别与边界并行的损失计算策略。
归一化均方频率类别权重策略,首先对所有数据样本进行分析,确定各个类别像素占比,以及含有各个类别的图像数量,结合上述信息计算各个类别的权重系数因子。
偏权重训练采样策略,首先记录数据集中图像含有的缺陷类别,将包含各个类别缺陷的图像地址形成列表,训练过程中,按照类别的不同,在类别列表中随机取样。
类别与边界并行的损失计算策略,训练过程中,系统得到一个样本的原始图像与标签信息。对标签信息进行边界轮廓提取,获得边界信息,将边界信息经过滤波后得到边界权重,损失计算中,结合类别损失与边界损失调整网络参数。
与现有方案相比,本方案具有以下技术优点:
金属表面缺陷语义分割网络,通过融合双重注意力机制与多尺度融合方式,显著扩大了感受野,增大了网络对于输入信息的理解能力。同时相应策略的引入,只发生在训练阶段,在测试阶段参与计算,因此在不增加计算量与参数量的条件下,显著提升了网络的分割能力,让网络对于假阳性与假阴性分类的比例大大降低。综合来看,本方法显著提升了对于金属表面缺陷的检测性能。
附图说明
图1为金属表面缺陷分割网络框架整体结构示意图;
图2为金属表面缺陷分割网络的空间注意力模块示意图,对应于图1中的SA部分;
图3为金属表面缺陷分割网络的通道注意力模块示意图,对应于图1中的CA部分;
图4为偏权重训练采样策略流程图;
图5为本发明方法在SD900数据集上对比实验效果图;
图6为本发明方法在Crack数据集上对比实验效果图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明公开的技术方法中,输入图像为RGB图像。特征提取器为HRNet网络,并采用其在人体关键点检测数据集上的预训练权重作为初始参数进行训练。在原RGB图像经过特征提取器后,将网络stage4部分的输出作为原输入图像的多尺度特征信息。
空间注意力模块如图2所示,由1×1大小的卷积,批量归一化算子,与Sigmoid算子组成,卷积模块将输入信息压缩到通道为1的特征图,并与原输入图像做空间的位置点乘运算,最后采用残差的方式连接,引入初始结构信息,保证网络性质不下降。
通道注意力模块如图3所示,由平均池化算子,1×1大小的卷积,批量归一化算子,与Sigmoid算子组成,接受2个相邻尺度的特征图信息输入。低分辨率特征图经过平均池化算子后,压缩到长宽各自为1的特征图,保留通道信息,经过1×1大小的卷积后,通道与高分辨率特征图保持一致,通过批量归一化算子与Sigmoid算子后,与高分辨率特征图做空间的位置点乘运算。最后通过残差连接,引入高分辨率图像的原始信息,最后输出高分辨率特征图。
多监督训练中,2个旁路分支与主路预测分支,损失权重系数设定为0.25:0.25:0.5,从而保证网络训练过程中能够优先侧重预测分支的预测。
归一化均方频率类别权重策略中,假设数据集中有N个类别(包含背景),则定义第i个类别出现的频率信息如下所示:
f
其中i∈[1,2,..,N],Γ
其中计算第i个像素类别权重系数W
因为多类别像素并存,不同类别的权重系数间互相影响,因此采用归一化的类别权重w
至此,得到了经归一化后的网络各类别权重。
偏权重训练采样策略如图4所示。在获得训练样本与类别数量N后,首先对训练集进行分析,对每张图像依次判断,确认图像中是否具有不同类别的缺陷。当存在有对应类别的缺陷时,将该图像地址记录在相应的缺陷类别集合中(从计算机内存的因素考虑),在不存在任何缺陷类别时,则这张图像不含有任何缺陷,于是将其地址记录在无缺陷的图像地址集合中。在实现上述处理过程后,会依次得到不同缺陷类别下的图像地址集合与无缺陷图像地址集合。在训练过程中,在不同类别的集合中以均等概率取样,在类别内部,随机选取图像进行训练。
类别与边界并行的损失计算策略中,训练过程中,首先对标签图像利用Sobel算子进行边界轮廓提取,得到图像的边界轮廓信息。然后用高斯滤波器边界轮廓图像进行滤波,从而在边界轮廓区域具有较高的权重信息。边界权重系数如下所示:
其中ψ
损失计算中采用交叉熵计算损失,整体损失函数Ψ可以表示为:
其中,x为网络预测的特征图信息,y为标签信息,C为类别数量,w为类别权重信息,Ω为图像中所有像素组成的集合,λ为比例因子,实验中设为1.0。
本发明方法在2个数据集上与多个方法对比(mIou)如表一,实验证明,本方法可以显著提升金属表面缺陷语义分割的精度。
表一
此外,本发明效果图如图5、图6所示,可以看出,本发明方法相比于其他方法,与标签真值最为接近,能够提升金属表面缺陷语义分割的精度。
- 基于编解码器结构实现钓鱼行为检测处理的方法及相应的语义分割网络系统
- 一种事件语义分割方法及事件语义分割网络