基于标签加密发送的企业间联邦学习算法模型训练方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及人工智能技术领域,特别涉及一种基于标签加密发送的企业间联邦学习算法模型训练方法。
背景技术
随着隐私的重要性与数据安全的问题受到越来越多的关注,数据隐私和安全问题已成为时下的热点问题,受到了来自各大企业的重点关注。与此同时,人工智能技术与大数据的在公司业务中的应用效果颇具成效,引发了人工智能的时代浪潮。在这两个前提下,联邦学习应运而生。
在联邦学习中,各方参与者之间可以共享训练数据但对数据内容不可见,可以实现协同训练的效果。在该机制下,由可信协调者控制流程,并负责管理密钥的生成、发放与解密,各个参与方将所持有的数据经过加密后发送至协调者与其他参与方,实现联合训练一个联邦模型,再将这个模型给各个参与方使用。但与此同时,在这个过程中,每个参与方都需要发送自己的数据,若密钥泄露,这个过程中数据泄露的风险需要所有参与方共同承担。此外,如何在保证数据安全的前提下提升各个环节的交互效率,对于提升联邦学习的效率有重要的意义。
鉴于企业间的数据特征空间重叠度小,但可能共享一个巨大的用户群体,因此采用一种基于用户对齐,扩展特征空间的联邦学习。但在传统的联邦学习体系下,各参与方都需要承担将数据发送至其他参与方中可能会导致数据泄露带来的风险。这种风险一定程度上降低了联邦学习的可操作性,阻碍了企业间建立良好的数据共享环境。
在目前传统联邦学习中,交互过程中需要每一轮都发送中间结果,并利用中间结果计算所需数据,完成本轮自身参数的更新。在计算过程中会主要遇到两种延误计算效率的情况,其一是交换的中间数据为密文,密文的计算往往比明文计算慢1-2个数量级;其二是当双方的计算中间数据完成的时间不一致,将会出现先完成的一方等待另一方的情况,导致总时间成本增加。
发明内容
为解决上述问题,本发明提供了一种基于标签加密发送的企业间联邦学习算法模型训练方法,通过同态加密算法,持有目标预测标签的参与方将加密后的标签发送至无标签的参与方,之后各个参与方独自完成训练,得到各自的模型,并利用各参与方的预测结果计算最终预测值,更符合企业间“需求方承担有限的数据传送风险,协作方不承担数据传送风险”的业务协作基本特性,让联邦学习更具有可操作性。同时,该联邦学习算法保证传统联邦学习质量的条件下,提高近50%的计算效率。
本发明提供了一种基于标签加密发送的企业间联邦学习算法模型训练方法,具体技术方案如下:
S1:协调者进行初始化,获取各项训练参数,感知参与方数量,并开始让参与方进行标签ID对齐操作;
S2:完成标签对齐后,协调者发起模型训练,各参与方将利用共有的实体数据训练机器学习模型;
S3:各参与方对ID对应的标签结果进行预测,协调方根据各参与方的预测结果计算最终预测值。
进一步的,所述训练参数包括训练目标以、训练轮数以及正则化参数。
进一步的,步骤S1中,样本ID对齐方式采用RSA密钥与哈希函数进行的加密样本对齐。
进一步的,步骤S2中,各参与方在训练过程中均采用同一种机器学习模型算法进行模型训练。
进一步的,(引用3)步骤S1,具体过程如下:
S101:协调者获取各项训练参数,感知参与方数量,并发送标签对齐消息至各参与方;
S102:持有标签方生成RSA密钥对,包括公钥(e,n)与私钥(d,n),并利用私钥计算自身样本ID的最终签名;
S103:发送公钥(e,n)至无标签参与方,并将私钥存储在本地;
S104:对每一个样本生成一个与n互质且不为1的随机数,利用公钥对ID进行加密,并乘以随机数进行加盲扰动,加密后的数据作为第一数据;
S105:无标签参与方发送第一数据至持有标签发送方;
S106:利用私钥进行对第一数据进行签名的初步计算,将该数据与自身的最终签名作为第二数据;
S107:持有标签方将第二数据发送至无标签参与方;
S108:对第二数据进行去盲计算,并计算得到最终签名,将双方的最终签名进行取交集运算,得到对齐ID集合;
S109:无标签方将对齐ID集合发送给持有标签方,持有标签方保存对齐ID集合,并发送样本对齐完成信号至协调者;
S110:协调者接收到样本对齐完成信号后,发送模型训练开始的信号。
进一步的,步骤S2,具体过程如下:
S201:协调者生成同态加密公钥和私钥,将私钥保存在本地,将公钥发送至各参与方;
S202:持有标签方将标签y利用公钥进行同态加密,并将该数据作为第一加密数据,同时开始进行自身模型训练。
S203:持有标签方发送第一加密数据至无标签参与方;
S204:无标签参与方利用第一加密数据作为标签与自身所持数据结合进行模型训练,得到所需的模型参数加密中间结果,并添加随机掩码加盲,将加盲结果作为第二加密数据;
S205:无标签参与方将第二加密数据发送至协调者进行解密;
S206:协调者对第二加密数据使用私钥进行解密,并将解密结果作为第三数据。
S207:协调者将解密后的第三数据发送至第二加密数据的发送方;
S208:无标签参与方将第三数据上所附加的掩码去除得到模型参数中间结果,并使用该中间结果更新各项模型参数;
S209:各参与方检查是否达成训练目标,若未完成则返回至步骤S204重新执行,直至各参与方均完成模型训练。
进一步的,步骤S3,具体过程如下:
S301:协调者获取预测目标ID,并将ID发送至各参与方;
S302:各参与方利用ID、自身所持数据与模型对该ID对应的标签结果进行预测;
S303:各参与方发送预测结果至协调者,协调者利用各方预测结果计算最终预测值。
进一步的,各参与方ID、自身所持数据与模型均保存在各方分布式服务器本地,除计算结果外其余数据均不会发送。
进一步的,(引用7),协调者采用如下公式计算最终预测结果:
其中,pred
本发明的有益效果如下:
1、本发明通过发起者发送加密标签的方式,实现需求方承担有限的数据传送风险,协作方不承担数据传送风险,解决传统联邦学习算法在不同业态企业间的条件下的通讯过程中责任所有制的问题,让联邦学习更具有可操作性,且利用了其他方数据的同时,可以让除标签以外绝大部分的数据不出本地,维持了联邦学习中隐私保护的特点。
2、该算法不需要每一轮迭代时都进行各个参与方之间两两交换中间结果,减少了中间通信,同时也避免了在训练过程中因训练数据量不同导致的步调不一致的时间等待问题,保证在达到传统联邦学习质量的条件下,提高了效率。
附图说明
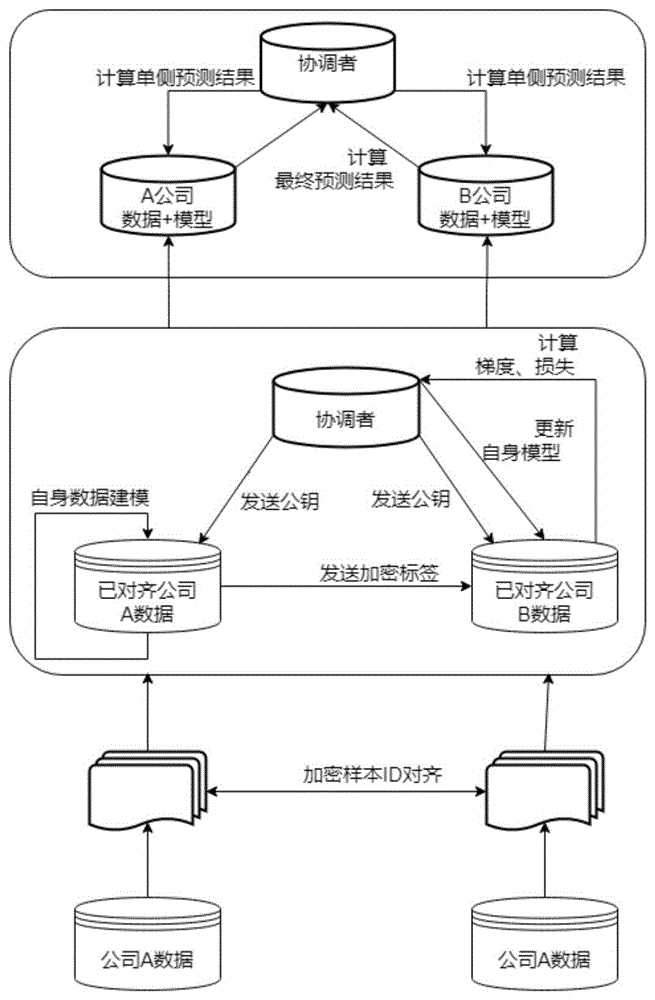
图1是整体结构及流程示意图;
图2是标签ID对齐流程示意图;
图3是模型训练流程示意图;
图4是标签预测流程示意图。
具体实施方式
在下面的描述中对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明实施例的描述中,需要说明的是,指示方位或位置关系为基于附图所示的方位或位置关系,或者是该发明产品使用时惯常摆放的方位或位置关系,或者是本领域技术人员惯常理解的方位或位置关系,或者是该发明产品使用时惯常摆放的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”仅用于区分描述,而不能理解为指示或暗示相对重要性。
在本发明实施例的描述中,还需要说明的是,除非另有明确的规定和限定,术语“设置”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是直接连接,也可以通过中间媒介间接连接。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
实施例1
本发明的实施例1公开了一种基于标签加密发送的企业间联邦学习算法模型训练方法,如图1所示,本实施例中,选取两个客户端参与训练进行说明,持有标签方对应集团企业下的信贷业务,未持有标签方对应集团企业下的电商业务,中央服务器(协调者)部署在集团中央服务器上;
所述训练出的模型用于预测信贷企业用户贷款金额;所述本地训练数据集和所述本地验证集均包含多个客户数据,每个所述客户数据包含多个客户特征以及用户期望贷款金额标签。
具体如下:
S1:协调者进行初始化,获取各项训练参数,感知参与方数量,并开始让参与方进行标签ID对齐操作;
本实施例中,所述训练参数包括训练目标、训练轮数以及正则化参数等;
协调者初始化完成后,将训练参数分发至各参与方,并命令参与方开始执行样本对齐工作,本实施例中,为提高计算效率,使用gmpy2库对下述步骤的全程计算进行加速;
采用RSA加密算法进行加密样本ID对齐,具体的,持有目标训练标签y的参与方作为Server,只持有特征不持有标签的参与方作为Client;
Server侧的样本ID集合{s
Server侧利用私钥计算自身样本ID的最终签名,计算方式如下:
其中,hs
Client侧对每一个样本ID生成一个随机数R
完成计算后将该加密数据作为第一数据发送至Server侧;
Server侧接收Client侧发送的第一数据,并对该数据使用私钥进行d次幂运算,加上第二把锁:
Server侧将加上第二把锁的数据与自身样本ID的最终签名作为第二数据传输给Client侧继续完成去盲的操作:
其中,K
Client侧将两边加密后的哈希值进行取交操作,得到双方的样本对齐ID:
其中,{a
基于上述步骤,参与方双方在不泄露样本ID的前提下获取到了双方ID集合的交集,实现了样本ID对齐。
S2:完成样本ID对齐后,协调者发起模型训练,各参与方将利用共有的实体数据训练机器学习模型;
具体如下:
协调者生成同态加密密钥对,将私钥存储在本地,并将公钥发送至各参与方;
持有标签的参与方利用公钥将自身所持有的标签y加密:
y
其中,[[y]]表示y的同态加密,记为第一加密数据,R
开始建模迭代,持有标签方利用自身的数据完成训练;
无标签参与方利用自身的特征数据训练用于预测持有标签参与方y的结果,具体标签的内容可在数据预处理时工程师可使用映射对y进行自身加密,用于避免无标签训练方利用模型结果计算出加密标签的原始值造成的隐私泄露;
其他参与方利用加密的标签进行计算建模,得到如下中间结果:
[[IntermediateResult
其中,α()表示建模中需要进行的运算,X表示参与方所拥有的无标签数据,X+[[y]]表示使用无标签数据与加密标签数据联合训练,i表示迭代轮数;
所述中间结果均为双方所选择的模型训练方法所需的参数,包括但不限于梯度,损失等;
完成计算后,参与方将加密后的中间结果添加随机掩码进行混淆,加盲结果作为第二加密数据,加盲后发送至协调者:
[[Data
R
协调者收到第二加密数据后,使用私钥对中间结果进行解密:
[[Data
解密结果作为第三数据,将解密后的结果回送至第二加密数据发送方,即无标签参与方;
参与方接收到来自协调者的解密结果,即第三数据,去除随机掩码后使用中间结果更新自身各项模型参数:
Data
λ
其中,λ
每一轮训练完成后检查损失是否达到规定目标,或训练轮数是否已经达到上限,若未完成,则继续进行迭代,直至完成设定的模型训练目标,各参与方获得各自的模型{θ
S3:各参与方对ID对应的标签结果进行预测,协调方根据各参与方的预测结果计算最终预测值;
本实施例中,持有标签方向协调者发起预测任务,协调者获取到预测任务ID后开始执行预测任务。
具体如下:
使用模型对目标样本进行预测,协调者向各个参与方发送目标样本ID j,各个参与方使用模型对该ID进行预测:
其中,f()表示按模型类型计算预测值,X
各参与方将预测结果发送给协调者,本实施例中,各参与方ID、自身所持数据与模型均保存在各方分布式服务器本地,除计算结果外其余数据均不会发送;
协调者计算预测算术平均作为最终预测结果:
其中,预测平均值pred
本发明的模型训练方法对不同业态企业间任意有较多共同样本的企业数据都可以进行建模预测,可以应用于多种场景,对多种数据进行预测。
本实施例所述的模型训练方法相较于传统联邦学习可以在保持和传统联邦学习近乎一致的学习效果的前提下,节省约50%的时间开销。
本发明并不局限于前述的具体实施方式。本发明扩展到任何在本说明书中披露的新特征或任何新的组合,以及披露的任一新的方法或过程的步骤或任何新的组合。