面向群智感知的海量未知工人选择与激励机制设计方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于群智感知领域,具体涉及一种面向群智感知的海量未知工人选择与激励机制设计方法。
背景技术
群智感知是一种新兴的众包感知模式,通过这种模式,平台通过雇佣一系列的工作人员来协同执行感知任务。目前相关的研究开展了较多,其中主要分为两个研究方向:在未知工人选择的群智感知问题以及群智感知中激励机制的研究。
在未知感知工人选择的群智感知问题中,工人的感知质量是未知的,雇佣工人执行感知任务的花费是已知的。平台需要在有限的预算下通过协调探索和利用的平衡来实现最终感知质量的最大化,已有的研究采用多臂老虎机(Multi-Armed Bandit,MAB),组合多臂老虎机(Combinatorial Multi-Armed Bandit,CMAB)的框架进行实现并进行和最优算法之间差距的理论分析。
在群智感知中激励机制的研究中,工人的感知质量是已知的,但工人执行感知任务的花费是私人信息,工人可以进行有策略地提交从而最大化自身收益。平台需要设计一种支付机制鼓励工人提交执行任务真实的花费,同时满足个体理性,真实性,预算平衡等一些经济属性(economic properties)。已有的研究采用第二报价(second-price),VCG机制进行支付机制的设计。
由于各种传感器以及智能设备的普及,很难对工人的感知能力进行很好的刻画。虽然传统的多臂老虎机框架可以很好的解决在学习工人感知质量时探索和利用的平衡,但由于工人的数量是海量的,所以平台无法保证足够的资金来对未知工人进行探索;同时,又因为工人执行感知任务会产生一定的费用需要平台进行支付,而这部分花费对于工人来说是私人信息,其可以进行有策略地提交从而最大化自身地收益,所以需要提出一个支付机制激励工人提交其执行感知任务真实的花费,这进一步限制了我们解决该问题以及相关的理论分析。在现实中,工人会被收集一些特征信息作为用户画像,而其中某些特征会与工人执行任务的质量存在某种关系。
发明内容
针对上述提出的技术问题,本发明提供了一种面向群智感知的海量未知工人选择与激励机制设计方法。通过该方法,可以实现在考虑预算约束和鼓励工人提交真实花费的情况下,最大化预期累计感知收益;同时与最优的累计期望质量的差值可以得到一个次线性增长的曲线。
为达上述目的,本发明的技术方案如下:
一种面向群智感知的海量未知工人选择与激励机制设计方法,包括如下步骤:
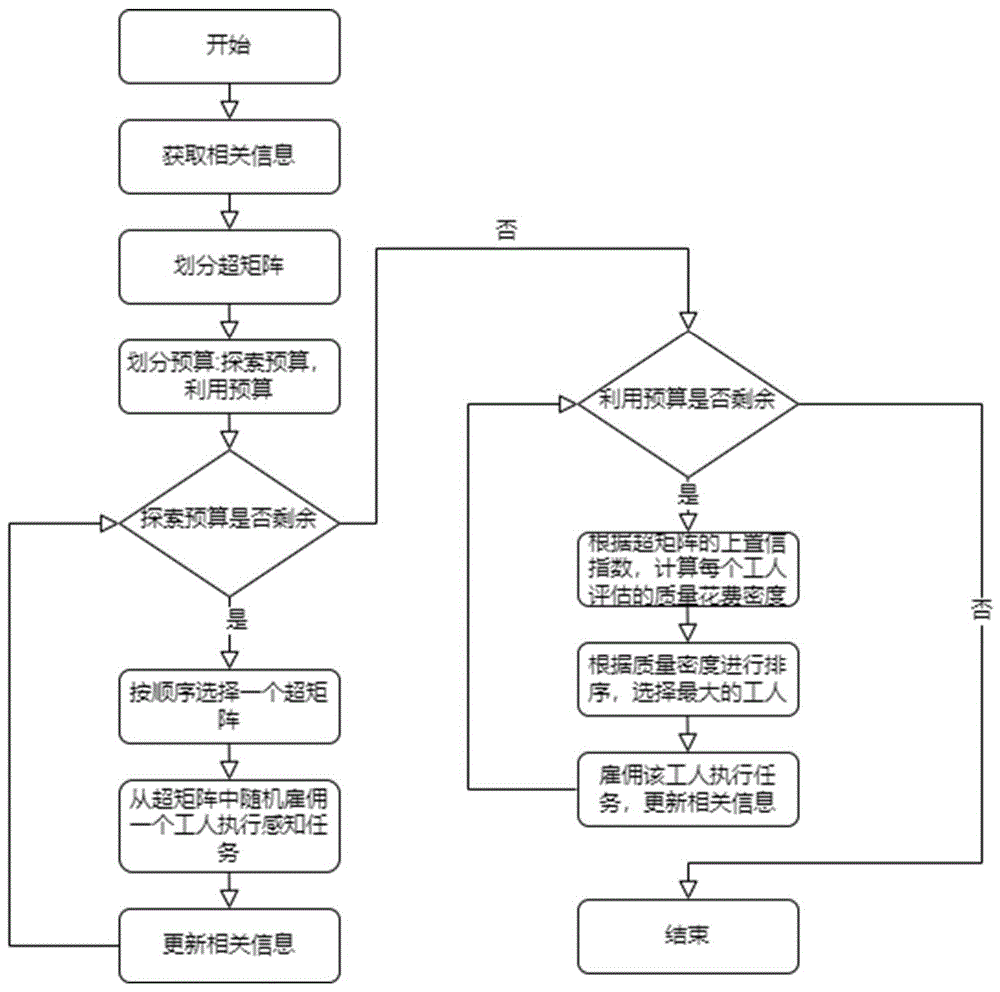
步骤一,初始化群智感知任务模型,将时间离散化为时刻t=1,2,…,获取雇佣工人执行感知任务的总预算B、工人信息、工人执行任务所需的花费投标、上下文信息特征空间和每个感知任务所需的执行时间τ;
步骤二,对上下文信息特征空间进行超矩阵划分;
步骤三,将预算分为探索预算B′和利用预算两部分。;
步骤四,按照特定顺序选择一个超矩阵,并从中随机选择一个可用的工人执行感知任务,更新相关变量,在执行时间τ之后观察其返回的任务收益,并根据收益更新其对应超矩阵的上置信指数,在下一轮重复该步骤,直到探索预算花完且没有工人正在执行感知任务为止;
步骤五,对于每一名工人,根据其所在超矩阵的上置信指数评估其执行任务的质量,并根据工人提交的执行任务所需的花费投标计算其评估质量花费密度,根据评估的质量花费密度进行工人的雇佣以及支付,选择一名工人执行感知任务,并更新相关变量,在下一轮重复该步骤直到利用预算花完为止。
优选的,步骤一中,执行感知任务雇佣工人所支付的总预算不得超过B;
设工人集合
下文信息特征空间
感知任务在分配给工人i执行后,需要执行时间τ,在此期间,工人i属于被占用的状态,无法再次被分配,直到当前感知任务执行结束。
优选的,步骤二中,将上下文信息空间划分为一个个超矩阵,将在同一个超矩阵中的工人视为一类,并且假设在同一个超矩阵中的工人具有类似的执行任务的质量,对其之间的差距进行界定。
优选的,步骤二具体方法如下:
(1)假设工人i执行任务的质量μ
|μ
(2)将上下文信息空间的每一维平均划分成
优选的,步骤三中,执行感知任务的总预算为B,其中探索预算为
优选的,步骤四具体方法如下:
(1)模型初始化:
(2)在t时刻,选择第
(3)在t时刻,雇佣选择出的工人执行感知任务,并支付报酬b
(4)当t>τ时,观察t-τ时刻雇佣的工人执行感知任务所得到的质量,更新其对应超矩阵Q的相关变量:
(5)探索预算不足以进行下一次探索,进入利用阶段。
优选的,步骤五具体方法如下:
(1)利用阶段初始化:对于工人集合
(2)计算每个工人的评估质量花费密度:
(3)对于
(4)计算利用预算:B
(5)在时刻t,当
(6)选择
(7)重复步骤(5)(6),直到预算不足以选择一个工人。
有益效果
1.提出了基于上下文信息的组合多臂老虎机和第二报价结合的方法,解决海量未知工人选择以及激励机制设计的问题,在考虑预算约束的情况下,最大化预期累计感知收益,进行严格的理论分析和大量的实验验证算法的有效性。
2.通过该方法,可以实现在考虑预算约束和鼓励工人提交真实花费的情况下,最大化预期累计感知收益;同时与最优的累计期望质量的差值可以得到一个次线性增长的曲线。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。
图1为本发明实施例所公开的一种面向群智感知的海量未知工人选择与激励机制设计方法流程图;
图2为本发明的群智分配模型图;
图3为本发明所提出发明的效果图,其中CACI为本发明所提出的方法,ε-first是基于ε-greedy的算法,CMAB-based是处理场景和本发明类似的对比方法。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
本发明提供了一种面向群智感知的海量未知工人选择与激励机制设计方法,如图1所示,包括如下步骤:
步骤一,初始化群智感知任务分配模型,群智感知系统主要有两个组成部分:任务平台服务中心及若干可执行感知任务的工人。在每个时刻,平台会雇佣一名工人执行感知任务,并支付工人一定的报酬,工人执行完任务后将结果上传至平台。由于不同工人的能力不同,处理完成的任务质量是未知的,所以平台需要根据之前工人上传的任务结果进行分析,从而选择出能力更好的工人。同时,因为工人执行任务所产生的花费不同且未知,平台需要支付一定量的报酬,激励工人参加感知任务并提交其真实的花费。
具体为,执行感知任务的总预算B,即执行感知任务雇佣工人所支付的总报酬不得超过B;
设工人集合
下文信息特征空间
感知任务是时间关键类型的任务,在分配给工人i执行后,需要τ时间的执行,在此期间,工人i属于被占用的状态,无法再次被分配,直到当前感知任务执行结束。
步骤二,对下文信息特征空间进行超矩阵划分;
具体为,将下文信息特征空间划分为一个个超矩阵,将在同一个超矩阵中的工人视为一类,并且假设在同一个超矩阵中的工人具有类似的执行任务的质量,其之间的差距可以使用数学公式进行界定。
划分超矩阵的具体方法如下:
(1)假设工人i处理任务的质量μ
|μ
(2)将上下文信息空间的每一维平均划分成
步骤三,将预算分为探索预算和利用预算两部分;
具体计算公式:总预算为B,其中探索预算为
步骤四,按照特定顺序选择一个超矩阵,并从中随机选择一个可用的工人执行感知任务,更新相关变量,在时间τ之后观察其返回的任务收益,并根据收益更新其对应超矩阵的上置信指数(UCB算法)。在下一轮重复该步骤,直到探索预算花完且没有工人正在执行感知任务为止;
具体方法如下:
(1)模型初始化:
(2)在t时刻,选择第
时/>
(3)在t时刻,Q表示当前工人所在超矩阵。若B
(4)在t时刻,雇佣选择出的工人执行感知任务,并支付报酬b
(5)当t>τ时,观察t-τ时刻雇佣的工人执行感知任务所得到的质量,更新其对应超矩阵Q的相关变量:
(6)计算利用阶段的预算:B
步骤五,对于每一名工人,根据其所在超矩阵的上置信指数评估其执行任务的质量,并根据工人提交的执行任务所需的花费投标计算其质量花费密度,根据评估的质量进行工人雇佣以及支付。选择一名工人执行感知任务,并更新相关变量,在下一轮重复该步骤直到利用预算花完为止。
具体方法如下:
(1)利用阶段初始化:对于工人集合
(2)计算每个工人的评估质量花费密度:
(3)对于
(4)计算利用阶段可用的总预算:B
(5)在时刻t,当
(6)选择
(7)重复步骤(5)(6),直到预算不足以选择一个工人。
为了评估本发明所提出的方法的性能,对本发明所提出的方法进行了模拟实验。对于工人i其特征信息s
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 一种面向群智感知的基于上下文信息的在线工人选择方法
- 一种面向群智感知的基于上下文信息的在线工人选择方法