一种基于双脑异向网络的多模态医学图像的融合模型和方法
文献发布时间:2024-01-17 01:27:33
技术领域
本发明属于医学图像的技术领域,具体涉及一种基于双脑异向网络的多模态医学图像的融合模型和方法。
背景技术
多模态医学图像融合技术旨在突破单一成像机制下传递信息不足的问题,结合源图像的显著信息来生成一幅信息丰富的融合图像,进而推动其后续应用。在诊断过程中,由于疾病类型繁杂,临床医生往往需要多次、重复性读取不同模态下相同部位的图像,这给临床工作带来了繁重的工作压力。因此,我们重点关注将单光子发射计算机断层扫描(SPECT)和磁共振成像(MRI)各自所涵盖的特异性信息有机结合,进而推动临床诊断、治疗规划和术前导航等应用进程。
经过数十年的发展,多模态医学图像融合问题已经得到了深入研究。可以将其归纳为两大类:传统的融合方法和基于深度学习的融合方法。其中传统的融合方法是针对不同的需求,在数学变换的基础上,手动分析变换域或空间域中涵盖的信息含量,设计并优化分解策略和融合规则,来达到期望的融合结果。为了避免传统融合方法下的局限性,基于DL的医学图像融合方法广泛发展,但现阶段仍存在以下不足:(1)现有的DL的方法多以非交互方式来同时捕获不同模态下的局部特征与全局特征,但无法避免特征相似问题。然而,基于人类视觉感知领域的研究表明,图像全局特征对局部特征的学习具有指导作用。(2)现有的DL方法通常将图像直接馈送到特征提取网络中,仅在高层次采用相加或拼接方式来融合特征,而尚未考虑不同等级下模态特征的异质性,这可能会导致丢失一些关键信息。(3)现有基于DL的方法所采用的损失函数对噪声和边缘细节的关注程度仍有待提升。在某种程度上,损失函数设计的好坏会直接影响模型的最终融合效果。
有鉴于此,本发明提出一种新的一种基于双脑异向网络的多模态医学图像的融合模型和方法,有效克服了单一模态图像下表达信息的不足。
发明内容
本发明的目的在于提供一种基于双脑异向网络的多模态医学图像的融合模型和方法,综合考虑了不同等级下功能图像和解剖图像的特异性信息,采用全局特征动态引导局部特征的方式,以此达到长期动态指导性关系建模,使得该网络能够充分实现跨东西半球集成互补特征信息的功能,解决多模态医学图像融合中的问题。
为了实现上述目的,所采用的技术方案为:
一种基于双脑异向网络的多模态医学图像的融合模型,包括:双脑异向网络模块和损失函数模块;
所述的双脑异向网络模块包括:Left hemisphere1、Lefthemispher2和Righthemisphere;
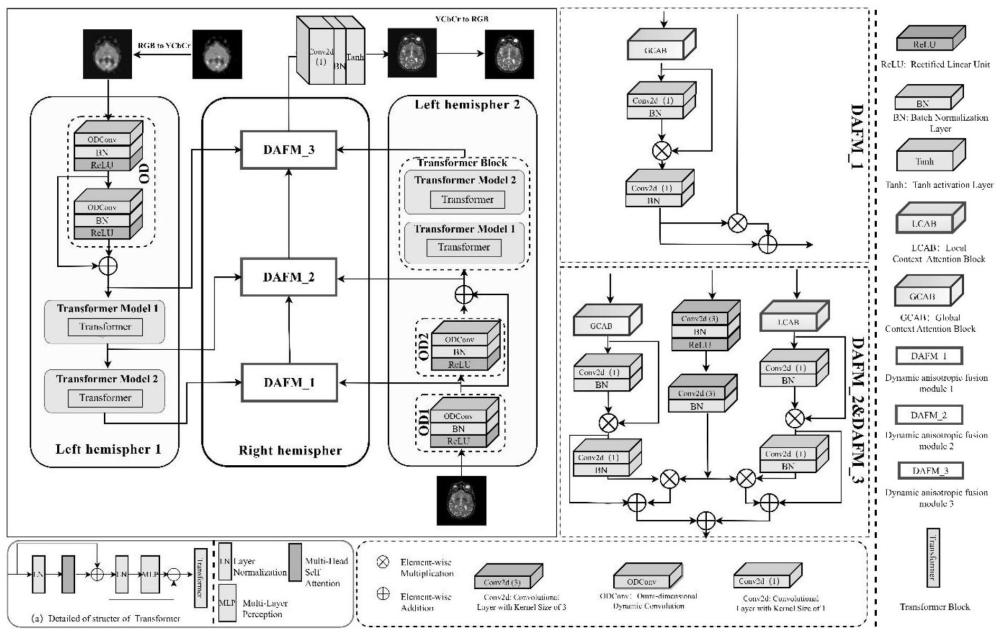
其中,所述的Lefthemisphere1、Lefthemispher2作为主干网络来分别提取全局特征;所述的Lefthemisphere1包括:OD模块、Transformermodel1模块和Transformermodel 2模块;所述的Lefthemisphere2包括:OD1模块、OD2模块和Transformerblock模块;
所述的Righthemisphere是一个动态引导网络,用于提取局部特征,包括:DAFM_1模块、DAFM_2模块和DAFM_3模块;
所述的损失函数模块来训练双脑异向网络,驱动网络关注边缘细节和结构信息。
进一步的,所述的损失函数模块采用以下公式:
L
其中,L
再进一步的,所述的结构级损失采用以下公式:
所述的区域级损失采用以下公式:
RMI定义如下公式所示:
式中,ε∈[0,1]是权重参数,
所述的纹理损失采用以下公式:
本发明的另一个目的在于提供一种基于双脑异向网络的多模态医学图像的融合方法,有效克服了单一模态图像下表达信息的不足。
为了实现上述目的,所采用的技术方案为:
一种基于双脑异向网络的多模态医学图像的融合方法,采用上述的融合模型,包括以下步骤:
(1)采用RGB-YCbCr颜色转换,使得SPECT图像I
(2)将
(3)通过
进一步的,所述的步骤(2)中,Lefthemisphere1生成特征图采用以下公式:
所述的Left hemisphere2生成特征图采用以下公式:
所述的
式中,
进一步的,所述的Transformer model 1模块、Transformer model 2模块和Transformerblock模块为滤波器模块,采用以下公式:
式中,
进一步的,所述的步骤(2)中,将Lefthemisphere1和Left hemispher2的多个阶段性特征图作为的Righthemisphere的网络输入,来提取局部特征。
再进一步的,所述的DAFM_1模块每次只接受不同模态下两个相邻的特征映射,融合高层次功能图像的语义信息和低层次解剖图像的细节信息;
所述的DAFM_2模块和DAFM_3模块接受三个相邻的特征映射;
所述的DAFM_2模块采用GCAB模块和LCAB模块进行深度提取,提升图像的表征能力。
再进一步的,所述的DAFM_1模块、DAFM_2模块和DAFM_3模块的各个阶段产生图采用以下公式:
式中,τ1是DAFM_1模块、τ2是DAFM_2模块,τ3是DAFM_3模块,
进一步的,所述的融合方法可以用于SPECT和MRI、PET和MRI、CT和MRI图像的融合。
与现有技术相比,本发明的有益效果在于:
本发明的多模态医学图像融合技术有效克服了单一模态图像下表达信息的不足,帮助医生提升诊断效率,促进术前精准导航。以往的融合研究多采用非交互方式同时关注不同模态的局部特征与全局特征,并且仅在高层次采用相加或拼接方式来融合特征,极易丢失模态差异化信息。基于此,本发明提出了一种用于多模态医学图像融合的双脑异向网络TBHNet。具体来说,本发明设计了一种双脑机制分别提取全局特征,尝试构建动态交互模块实现双模态下的全局特征自主引导局部特征。其次,本发明设计的异向输入机制可以同时捕获功能图像的高层次语义特征和解剖图像的低层次细节特征,避免结构细节信息丢失。此外,由SSIM损失、区域损失和纹理损失组成的损失函数可以更好地驱动网络关注边缘细节和结构信息。实验结果表明,在多模态医学图像融合场景下,综合主观与客观评估结果,TBHNet均优于现有的代表性技术方法。重要的是,本发明还将其无需微调直接应用于PET和MRI、CT和MRI融合问题上,令人满意的融合结果表明TBHNet具有良好的泛化性。具体的:
1、本发明所述的一种基于双脑异向网络的多模态医学图像的融合模型和方法,从人类视觉感知角度出发,提出了一种双脑异向网络以交互方式同时关注到不同模态下局部特征与全局特征的异质性,提升图像融合性能。
2、本发明所述的一种基于双脑异向网络的多模态医学图像的融合模型和方法,与现有的融合方法不同,TBHNet中的异向机制重点关注高层次下功能图像的语义信息和低层次下解剖图像的细节信息间的互补性。
3、本发明所述的一种基于双脑异向网络的多模态医学图像的融合模型和方法,定义了一个统一的损失函数,从结构细节保留、区域互信息损失和纹理损失三方面来保持显著信息和边缘信息。
4、本发明所述的一种基于双脑异向网络的多模态医学图像的融合模型和方法,在主流数据集上开展了大量实验,证明本发明提出的方法可以在一定程度上解决SPECT和MRI存在的模态局限性,获取同时包含显著信息的单一复合型图像。本发明将其无需微调扩展到PET和MRI、CT和MRI图像融合任务中。试验结果表明,它在定性、定量评估上优于其他具有代表性和最先进的方法,具有良好的泛化能力。
附图说明
图1为SPECT和MRI图像融合结果展示;
图2为模型的总体架构;
图3为LCAB和GCAB的模型结构图;
图4为SPECT和MRI结果展示;其中,a图为MRI,b图为SPECT,c图为MSMG_PCNN_EA,d图为CSMCA,e图为TL_ST,f图为MLEPF,g图为DATFuse,h图为YDTR,i图为Swinfusion,j图为Crossfusion,k图为MATR,l图为Ours;
图5为SPECT和MRI定量指标展示;
图6为PET和MRI结果展示;其中,a图为MRI,b图为SPECT,c图为MSMG_PCNN_EA,d图为CSMCA,e图为TL_ST,f图为MLEPF,g图为DATFuse,h图为YDTR,i图为Swinfusion,j图为Crossfusion,k图为MATR,l图为Ours;
图7为CT和MRI结果展示;
图8为PET和MRI定量指标展示;
图9为CT和MRI定量指标展示;
图10为模型结构消融图;其中,a栏为MRI,b栏为SPECT,c栏为TBHNet(此时损失函数系数为α=1.5、β=1、γ=1、δδ=1和ε=1),d栏为修改后的TBHNet模型结构图呈现同向时(修改后的网络结构图见图11),e栏为无DFAM_1、DFAM_2和DFAM_3时的TBHNet模型结构图(修改后的网络结构图见图12),f栏为无DFAM_1时的TBHNet模型结构图(修改后的网络结构图见图13),g栏为将Left hemispher1和Left hemispher2的输入图像调换后的TBHNet模型结构图(修改后的网络结构图见图15),h栏为无动态机制的TBHNet模型结构图(修改后的网络结构图见图14),i栏为损失函数L
图11为修改后的TBHNet模型结构图呈现同向结构时;
图12为无DFAM_1、DFAM_2和DFAM_3后的TBHNet模型结构图;
图13为无DFAM_1的TBHNet模型结构图;
图14为无动态机制的TBHNet模型结构图;
图15为调换输入图像后的TBHNet模型结构图。
具体实施方式
为了进一步阐述本发明一种基于双脑异向网络的多模态医学图像的融合模型和方法,达到预期发明目的,以下结合较佳实施例,对依据本发明提出的一种基于双脑异向网络的多模态医学图像的融合模型和方法,其具体实施方式、结构、特征及其功效,详细说明如后。在下述说明中,不同的“一实施例”或“实施例”指的不一定是同一实施例。此外,一或多个实施例中的特定特征、结构或特点可由任何合适形式组合。
在详细阐述本发明一种基于双脑异向网络的多模态医学图像的融合模型和方法之前,有必要对本发明中提及的相关背景做进一步说明,以达到更好的效果。
1、图像融合
早期实现图像融合的方法我们统称为传统方法。传统融合方法例如空域算法中滤波器的发展最为经典,最初是由Tomasi提出的双边滤波器(Bilateral Filter,BF),Jian提出的联合使用双边滤波和滚动引导滤波。上述基于空域的算法虽然计算效率高,实现方式简单,但其在保留源图像对比度信息和亮度信息方面能力较差。因此,为弥补空域算法的缺陷,基于变换域的方法随之产生,例如Pajares提出的离散小波变换(Discrete WaveletTransform,DWT),Wang等人基于小波变换(Wavelet Transform,WT)的研究,双树复小波变换(Dual Tree-Complex Wavelet Transform,DT-CWT)、轮廓波变换(ContourletTransform,CT)以及剪切波变换(Shearlet Transform,ST),非下采样轮廓波变换(Non-Subsampled Contourlet Transform,NSCT)和非下采样剪切波变换(Non-SubsampledShearlet Transform,NSST),以及近几年发表的基于NSST和参数自适应脉冲耦合神经网络的医学图像融合,Zhu等人提出的用于MRI和CT融合的混合图像分解模型,一种基于像素强度偏度(SPI)和一种新的基于自适应共现滤波器(ACOF)的图像分解优化模型,一种基于潜在低秩表示(LatLRR)的多级图像分解方法MDLatLRR用于红外与可见光图像融合,一种基于结构贴片分解(structural patch decomposition,SPD)的多模态医学图像融合方法,一种基于Haar滤波的小波变换(Wavelet transform)实现了多焦点图像融合算法。上述方法大部分遵循“分解-融合-重建”的步骤,存在以下两点不足之处,一方面,为了保证后续特征融合的稳步进行,传统方法一般对于不同的源图像输入采用相同的变换,分解过程中忽视不同模态之间特征的互补性,另一方面,人工方式下设计的融合策略具有较大的局限性,使得图像融合性能有限。
现阶段,深度学习凭借着其强大的特征表示能力,在计算机视觉领域发挥着越来越重要的作用,并且众多基于深度学习的多模态医学图像融合方法相应产生。
虽然现有的基于DL的医学图像融合方法广泛发展,但现阶段仍存在以下不足:忽视全局特征对局部特征的指导作用,多采用非交互方式来同时捕获不同模态下的局部特征与全局特征,易出现特征相似问题进而影响融合图像质量。大多数研究中未针对不同等级下模态特征的异质性以及互补性展开探讨性研究。
2、Vision Transformers用于多任务图像融合
随着Transformer架构从自然语言处理(NLP)领域扩展到CV领域,越来越多的研究者关注到Transformer在提取全局语义信息方面的独特优势而被广泛使用。Fu等人提出了一种Patch Pyramid Transformer(PPT)架构可以更好的关注相邻像素的局部相关信息。具体来说,首先通过Patch Transformer将图像转化为一组patch序列,其次在金字塔变换器的帮助下提取图像的非局部信息,最后构建了有效的图像重建网络,模型的融合性能优越。Ma等人关注到了同一域内和跨域的长距离依赖关系的互补性,通过构建注意力引导的跨域模块和设计了高效的损失函数使得融合模型效果突出。Tang等人抛弃了传统卷积,引入了效果显著的自适应卷积,并且采用自适应变换器来增强全局语义提取能力,以不同尺度的角度来充分提取源图像信息。Tang等人从全局特征和局部特征的角度出发,设计了一种Y型动态变换器(YDTR)用于红外和可见光图像融合。Li等人同时关注到融合全局特征和局部特征的必要性,因此该研究设计了convolution feature extraction module(CFEM)和transformer feature extraction module(TFEM)分别用于提取局部特征和全局特征,并且采用交替使用CFEM和变换器模块的方式试图捕捉局部特征和长距离依赖的内在关系。Qu等人设计了一种基于编码器-解码器的图像融合框架,使用CNN和Transformer分别提取局部特征和全局特征,并对两者进行融合,该框架在多个任务上都达到了令人满意的效果。Tang等人设计了局部特征提取分支(local feature extraction branch,LFEB)和全局特征提取分支(global feature extraction branch,GFEB)来分别提取局部信息与全局信息,并设计了一个交叉相关损失(cross correlation loss)来训练模型用于红外和可见光图像融合。Chen等人提出了一种基于变换器和混合特征提取器融合框架(transformer andhybrid feature extractor),首先采用双分支CNN模块来提取局部特征,然后利用视觉变换器模块来捕获全局特征,通过图像重建模块最终得到融合的结果。
Transformer因其具有良好的捕捉长距离的远程依赖关系的能力而被众多研究者喜爱,但是目前研究中仅通过简单的融合操作将多模态条件下的全局特征和局部特征进行融合,尚未探讨过交互方式下全局特征对局部特征的引导在提升融合图像质量上的作用。
因此,本发明在人类视觉感知的基础上,精心设计出了一种端到端的可用于多模态医学图像融合的双脑异向网络TBHNet,在引用OCDConv模块的基础上,使用了具有移位窗口机制的自适应变压器来进行长期关系构建,充分提取SPECT图像与MRI图像中的特异性特征,提升融合图像质量。除此之外,本发明重点关注两种模态下全局特征与局部特征的动态交互,试图增加模态间特征的差异化表示。其次,本发明提出了一种异向机制来关注不同等级下功能图像和解剖图像所涵盖的互补性特征。此外,由SSIM损失、区域损失和纹理损失组成的复杂损失函数使融合图像呈现最佳的表观强度。
在了解了本发明中提及的相关背景之后,下面将结合具体的实施例,对本发明一种基于双脑异向网络的多模态医学图像的融合模型和方法做进一步的详细介绍:
本发明所述的一种基于双脑异向网络的多模态医学图像的融合模型和方法,提出了一种双脑机制来分别提取两种模态下的全局特征,通过自主引导模块来推进全局特征与局部特征的动态交互,以此来增加特征表示之间的差异。其次,提出了一种异向机制来关注高层次下功能图像的语义信息和低层次下解剖图像的细节信息。此外,本发明设计的损失函数是由SSIM损失、区域损失和纹理损失组成,可以更好地驱动网络关注纹理细节和结构信息。
为了证明本发明融合方法的有效性,图1展示了一对SPECT和MRI图像的示例,以及基于先进融合方法和本发明所提出方法的融合结果。使用矩形框圈出局部纹理,放大在对应图像的下方,以更好地比较融合图像的细节信息。可以观察到,其他融合算法都不可避免地忽略了源图像的特异信息。更具体地说,如图1的红色框中可以观察到,在某些SPECT图像中不包含功能信息的区域,由于缺乏全局信息对局部信息的动态引导,其他对比算法通常会破坏MRI图像中的结构信息,甚至出现黑色伪影。然而TBHNet更关注MRI图像的结构细节及边缘纹理信息,融合效果更好。
实施例1.
具体操作步骤如下:
将分以下三部分进行阐述。本发明实施例首先描述了总体框架TBHNet(A)。其次,本发明实施例介绍了双脑异向网络结构(B),最后本发明实施例阐述了建议构建的最佳目标函数(C)和实验结果分析(D)。
A总体框架:
据研究可知,大脑的左/右半球更倾向于捕捉全局/局部特征。因此,本发明实施例在综合考虑了功能图像的语义信息和解剖图像的细节信息的基础上,采用一种双脑机制分别提取全局特征,尝试构建交互模块实现双模态下的全局特征分别引导局部特征,以此达到长期动态指导性关系建模,并且本发明实施例设计的异向输入机制可以关注SPECT图像的高级语义特征和MRI图像的低级细节特征,以解决多模态医学图像融合中的问题。
TBHNet的网络结构如图2实线矩形框所示,Left hemisphere1和Left hemispher2分别使用ODConv模块和两个自适应变压器模块作为主干网络来分别提取
B TBHNet的详细内容:
1)Left hemisphere1和Left hemispher2
①Left hemisphere结构:
如图2所示,Left hemisphere1和Left hemispher2分别是两个特征提取网络
其中,
具体来说,能否从多模态的源图像中充分保留重要的互补信息已成为影响融合图像性能的重要因素。常规卷积层在提取图像局部特征方面具有明显优势,但单一静态卷积核并且与输入样本无关的特性,使得仅采用常规卷积层进行融合任务时,对于解剖图像含有的复杂纹理信息易丢失。因此,考虑到丰富上下文语义信息的重要性,尝试引入了全维动态卷积来从四个维度上自适应调整卷积核的权重,从而大幅度提升卷积核的特征表示能力。除此之外,可以对更多的互补信息进行内容自适应维护,从而获得更多信息的融合结果,本发明采用的Transformer Model结构如图2中实线圆角矩阵所示,该滤波器块可以由两个加法操作完成,分别对应公式5和公式6。
其中,
如何有效的提取功能性代谢信息和结构性软组织细节信息成为提升融合图像质量的关键因素。与现有技术比较,本发明提出的是一种更适用于提取结构细节丰富的医学图像全局特征的方式。具体来说,由于传统的卷积运算在保存全局上下文信息方面能力有限,因此本发明引入ODCOnv代替传统卷积来提取特征,ODConv模块的引入使得可以从四个维度上自适应调整卷积核的权重。除此之外,本发明采用双Transformer Model对上下文全局信息进行深层次提取,有利于生成信息量更大的融合结果。
②Right hemisphere结构:
如图2所示,Right hemisphere Block是一个动态引导网络τ用于提取局部特征,由三个DAFM模块组成。本发明将Left hemisphere1和Left hemispher2的多个阶段性特征图作为的τ的网络输入,DAFM模块的各个阶段产生图见公式(7)-(9)。
其中,τ1是DAFM_1模块、τ2是DAFM_2模块和τ3是DAFM_3模块并且
本发明设计了一种更适合于多模态医学图像融合工作的方法。如图2中的虚线矩形框所示,DAFM_1接受来自功能图像的高级别特征和解剖图像的低级别特征,并应用乘性引导因子将解剖图像的纹理、边缘等信息应用到功能图像的语义特征,实现细节信息动态引导语义信息,并在加法引导因子的作用下,最后得到融合后的特征图
与现有技术比较,本发明提出的是一种采用模态间特征差异化表示学习的方式。首先,在异向输入的基础上,DAFM_1模块融合了高层次功能图像的语义信息和低层次解剖图像的细节信息。其次,DAFM_2模块针对功能图像和解剖图像的不同模态特征,本发明分别设计了GCAB模块和LCAB模块针对有效的进行深度提取,尝试提升图像的表征能力。本发明重视模块的差异化特征输入构建了三个DAFM子模块,可以逐步缩小高、低等级间的差异化的语义特征,来获得更好的融合结果。其次,本发明通过乘性因子和加性因子使得网络获得自动聚焦于不同模态中的关键区域的能力,并指导局部特征进行补充学习。
C损失函数构建
在无监督方式下,损失函数的构建对于多模态医学图像融合的融合结果具有指导性作用。本发明提出了一个新的损失函数来训练TBHNet网络,损失函数公式如式10所示:
L
其中,L
结构级损失:结构相似度(structural similarity,SSIM)指标可以从三方面来有效反映图像失真,因此为了进一步保持SPECT和MRI图像的有用特征,本发明采用了基于结构相似性指数度量(SSIM)定义的结构损失,其定义如公式11所示:
其中,ssim(·)表示结构相似度操作。
区域级损失:本发明引入了区域互信息(RMI)概念,可以准确的保存多模态条件下的图像信息。L
其中γ和δ用于平衡的超参数,RMI定义如公式13所示:
其中ε∈[0,1]是一个权重参数。
纹理损失:保留更多的纹理细节是提升图像融合结果的重要因素之一。本发明试图在prewittee边缘检测算子的帮助下提升融合结果的纹理细节。本发明将纹理损失L
其中,
D实验结果分析:
本发明实施例介绍了使用的数据集和训练细节。其次,本发明展示了TBHNet方法与其他先进方法在SPECT-MRI融合任务上的定性和定量比较以及相应的分析。再次,本发明实施例扩展模型适用范围到PET-MRI和CT-MRI图像融合任务。最后,本发明实施例依次对模型结构、损失函数中权衡参数的设定和目标函数组成进行了大量的消融实验,验证TBHNet模块特定设计的有效性。
(1)数据集的准备及训练细节
哈佛大学数据集是一个广泛使用的医学图像融合数据集,可用于公平比较。本研究从哈佛大学公布的主流医学图像数据库(http://www.med.harvard.edu/AANLIB/home.html)中下载了607对医学图像,其中SPECT和MRI图像数据集下载390对,PET和MRI图像97对,CT和MRI图120对。由于图像配准是图像融合的先决条件,因此假设本研究所采用的图像对均可以精准对齐。本发明实施例将390个图像对进行了如下五次实验,首先,本实施例将其自动划分为350个图像对作为训练集,将20个SPECT和MRI图像对作为验证样本,剩余20个图像对作为测试集,其中验证集用于确定模型结构、损失函数和损失函数中的超参数设置,本实施例最终损失函数中超参数设置为α=1.5、β=1、γ=1、δ=1和ε=1。其次,本实施例在剩余四次实验中手动剔除20对验证集样本,将剩余370对样本自动划分为350个图像对作为训练集,20个图像对作为测试集。本实施例为了获得足够的医学图像训练样本,本实施例采用了广泛使用的随机裁剪策略进行增强训练图像数据,五次实验中均收集到大小为120×120的17500对训练集。由于采用裁剪策略进行数据增强,因此裁剪工作不用于验证集和测试集。其次,本实施例采用自动抽样的方式依次从97对PET和MRI图像,120对CT和MRI图像中分别抽取20对图像用作测试样本。本实施例部署在NVIDIA GeForce GTX 3090GPU上,采用PyTorch框架实现,使用学习率指定为0.001的Adam优化器,批量大小设置为32,epoch设置为10。
(2)对比算法与评价指标
对比方法:对比了九种具有代表性和先进性的方法:CSMCA,MSMG-PCNN-EA,TL-ST、MLEPF、SwinFusion、MATR、YDTR、DATFuse、CrossFuse与本发明的方法进行比较。采用的所有比较方法都是使用作者公开的代码进行的。
评价指标:本研究采用了八种评价指标从多个角度来评估融合图像的性能:normalized mutual information(Q
(3)SPECT和MRI融合结果和讨论
图4展示了不同对比方法作用于四组样本对的融合图像。图中图中下方两个放大局部区域均显示了不同的程度的信息,为了进行更详细的对比,进行放大展示。具体来说,以上方法虽获得令人相对满意的融合性能,但是与本发明提出的方法相比,仍不可避免地削弱了源图像的基本信息。如图4展示,其他竞争对手方法中对于保留边缘细节方面能力有限,并易伴随伪影情况的存在,影响主观视觉感受。如图4样本3中的放大区域图展示,CSMCA、YDTR、Crossfusion和MATR方法下出现了不必要的黑色伪影,MSMG_PCNN_EA和MLEPF融合的图像中存在阴影和噪声。TL_ST、DATFuse和Swinfusion融合的图像在细节上缺乏清晰度。值得注意的是,由于全局信息对于局部信息的动态引导和适当的强度控制,TBHNet模型可以在充分表征PET图像中的功能信息基础上,最大程度的保留MRI图像中丰富的纹理细节。
图5为SPECT和MRI定量指标展示。其中:定量比较所提出的TBHNet在SPECT和MRI图像融合与9个代表性和最先进的方法在8个客观评价指标。图例中说明了不同方法在五折交叉验证下100对样本的平均分±标准差。值得注意的是,MATR方法图例中&后代表的是原论文中展示的20对测试样本的平均值。
图5显示了每次实验中自动选取的20对SPECT和MRI图像测试集分别在八个广泛使用的评估指标下的定量比较。对于每个指标,取100个测试样本的平均值和标准差标记于图例中,将样本的指标评估分数用折线图呈现。据指标图可知,QMI、QNCIE,Qp、QG、VIF和FMI_w在所有100张图像上获得的平均值得分最高。对于MS_SSIM和FMI_dct该方法得分相对较低,但与其他方法差异较小。
综上所述,本发明提出的TBHNet在保留源图像的互补信息方面具有更佳的融合特性。
(4)PET和MRI结果展示
为了探讨本发明提出的TBHNet方法的泛化性能,我们将TBHNet无需微调直接应用到正电子发射断层扫描(PET)-MRI和CT-MRI图像融合任务,总计在100组测试样本中采用典型的对比方法和评价指标来综合测试模型性能。
图6分别详细展示了五组典型PET和MRI图像对的融合图像。从样本1中的放大区域框图和样本3中的放大区域框图可知,由于其他方法缺乏对于全局信息和强度的关注,会不可避免的忽略PET图像中不包含功能信息的对应区域,进而融合图像中对于MRI图像的软组织信息保留程度不高。在其他方案的结果中,MRI图像中的纹理细节都有不同程度的减弱或忽视。
图7分别详细展示了五组典型CT和MRI图像对的融合图像。从样本3全部细节图和样本5放大区域框图RI图像中的边缘细节信息被DATFuse、YDTR、Swinfusion和MATR减小。此外,其他方案对于源图像信息都有不同程度的减弱。相反,从样本1、2和4可知,我们的TBHNet存在丢失了较少的CT图像中的功能代谢信息,保留了MRI图像中的纹理等信息,综合比较而言,可以为医生制定恰当的治疗方案提升全面的辅助信息。
图8为PET和MRI定量指标展示。注:定量比较所提出的TBHNet在PET和MRI图像融合与9个代表性和最先进的方法在8个客观评价指标。图例中说明了不同方法在五折交叉验证下100对样本的平均分±标准差。值得注意的是,MATR方法图例中&后代表的是原论文中展示的20对测试样本的平均值。
图9为CT和MRI定量指标展示。注:定量比较所提出的TBHNet在CT和MRI图像融合与9个代表性和最先进的方法在8个客观评价指标。图例中说明了不同方法在五折交叉验证下100对样本的平均分±标准差。值得注意的是,MATR方法图例中&后代表的是原论文中展示的20对测试样本的平均值。
从图8中PET和MRI客观评价指标可知,QMI、QNCIE,Qp、QG、VIF和FMI_w在所有100对测试样本上得分最高,并且平均值都达到了最佳分数。然而对于MS_SSIM平均值较低。从图9中CT和MRI客观评价指标可知,QMI、QNCIE和Qp测试样本上平均值都达到了最佳分数。基于主观质量和客观评价的比较,所提出的方法在一定程度上优于其他对比方法,这说明本发明的TBHNet具有良好的泛化能力。
(5)消融研究
本发明的TBHNet的融合性能依赖于精心设计的网络架构和损失函数。一方面,本发明提出的双脑机制实现了两种模态下全局特征与局部特征的动态交互,很好的增加特征表示之间的差异。另一方面,异向机制的提出可以有效地关注来自不同等级下功能图像和解剖图像所涵盖的互补性特征。此外,由SSIM损失、区域损失和纹理损失组成的复杂损失函数更好地驱动网络关注纹理细节和结构信息。本发明进行了一系列的消融研究,以验证特定模块设计的有效性和必要性。多模态图像融合消融实验的视觉结果如图10所示。
异向机制分析:深度学习模型低层次更易捕捉到图像的边缘等细节特征,高层次更倾向于保留丰富的语义特征。SPECT图像和MRI图像两者传递的特异性信息具有互补性,因此,构建恰当的异向机制分别提取两幅图像中的显著信息。如图10(d)所示,将Lefthemispher2的输入方向改为与Left hemispher1同向时(具体修改后的TBHNet模型见图11),融合结果并没有呈现出合适的视觉提升。具体而言,异向机制的存在使得融合过程中更易感知两种模态源图像中的互补信息。
DAFM模块分析:动态渐进模块的存在使得特征从高层次流向低层次,有效缓解了高层次和低层次特征间的语义差距。如图10(e)所示,我们将DAFM_1、DAFM_2和DAFM_3分别替换为简单的元素相加操作(具体修改后的TBHNet模型见图12),融合模型不能有效控制融合图像的纹理结构细节,更甚者出现伪影现象。如图10(f)所示,我们将Left hemispher1与Left hemispher2进行结构缩减,分别丢弃
双脑机制下交换分析:最初的Left hemispher1和Left hemispher2分别重点关注SPECT图像的语义特征和MRI图像的纹理细节,为探究不同层次下提取多模态特征的异质性,我们交换Left hemispher1和Left hemispher2的输入图像,使得两者分别重点关注MRI图像和SPECT图像。图10(g)可以看出,交换输入特征图后得融合模型,不能有效保留源图像MRI中的结构细节信息(具体修改后的TBHNet模型见图15)。
损失函数组成因子分析:如图10(i)所示,L
L
L
L
消融研究的定量结果如表1所示。从结果中我们可以看出,任何组件都有其存在的必要性,去除任何一个均会不同程度的降低TBHNet的融合性能。
表1模型结构消融客观指标
注:表中(c)TBHNet(此时损失函数系数为α=1.5、β=1、γ=1、δ=1和ε=1),(d)同向网络,(e)没有DFAM_1、DFAM_2和DFAM_3,(f)没有DFAM_1,(g)将Left hemispher1和Left hemispher2输入图像调换,(h)没有动态机制,(i)L
损失函数权衡参数分析:定量结果如表2所示,其中均为验证集中所有样本的平均得分。显而易见,当α=1.5、β=1、γ=1、δ=1和ε=1时,验证集的融合性能最佳。因此,我们将α、β、γ、δ和ε的默认值分别设置为1.5、1、1、1和1。
表2损失函数系数对比
在本发明中,提出了一种端到端的双脑异向网络TBHNet用于多模态医学图像融合。在本发明的方法中,引入ODCOnv和自适应变压器作为双左半球分支来异向提取全局互补上下文信息。为了使得全局特征可以动态引导局部特征来实现准确融合的目标,我们设计了由三个DAFM模块组成的右半球分支,有效的融合了功能图像下的高级语义特征和解剖图像下的低级结构特征。此外,从结构损失、区域损失和边缘损失的角度出发设计了一个损失函数,用于训练TBHNet。大量实验表明,我们的方法在客观评价和主观视觉方面优于其他具有代表性和最先进的方法。我们并将该方法无需微调推广到PET和MRI、CT和MRI图像融合问题,结果表明该方法具有较好的泛化能力。
以上所述,仅是本发明实施例的较佳实施例而已,并非对本发明实施例作任何形式上的限制,依据本发明实施例的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明实施例技术方案的范围内。
- 一种基于双残差超密集网络的多模态医学图像融合方法
- 一种基于双重张量低秩模型的多模态三维医学图像融合方法