一种基于小样本的语义标注方法及装置
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及文本处理领域,尤其涉及一种基于小样本的语义标注方法及装置。
背景技术
无论是资料搜集、学术研究还是写作需求等,生活和工作中,我们都免不了对自己学习或阅读到的文本资料或重要内容等信息进行标注,以便日后使用时,能快速检索到相关资料。
如何根据文本语义实现快速、高效且准确的标注,便于检索及提升工作效率成为了难题。为了解决这个问题,目前现有技术中采用传统的标签模型如人工标注,或者通过大量样本进行训练实现自动标注的方案。然而,现有技术中所采取的方案存在人工标注耗时高、效率低,大样本训练成本高、难度大、难以实现个性化和保证准确率的缺陷。
发明内容
本发明实施例提供了一种基于小样本的语义标注方法,旨在解决训练成本高、难以实现个性化和保证准确率的问题。
本发明实施例是这样实现的,提供了一种基于小样本的语义标注方法,包括:
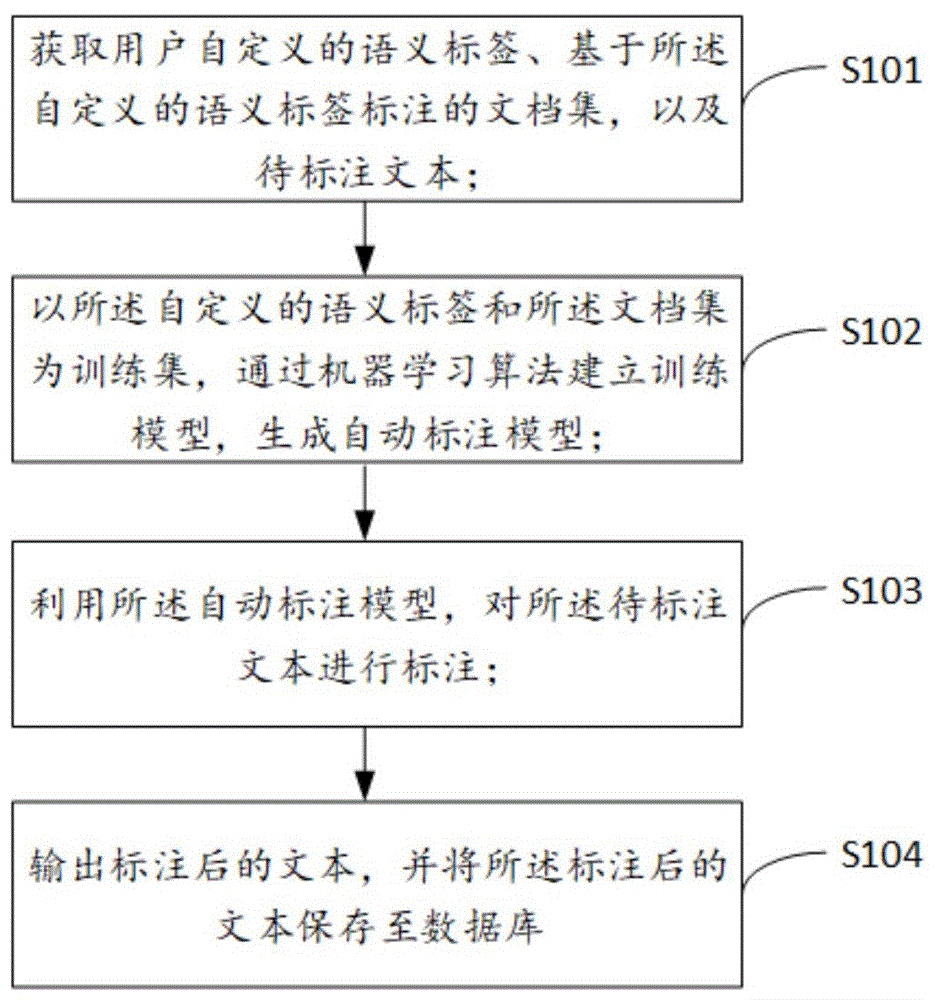
获取用户自定义的语义标签、基于所述自定义的语义标签标注的文档集,以及待标注文本;
以所述自定义的语义标签和所述文档集为训练集,通过机器学习算法建立训练模型,生成自动标注模型;
利用所述自动标注模型,对所述待标注文本进行标注;
输出标注后的文本,并将所述标注后的文本保存至数据库。
更进一步地,所述方法还包括如下步骤:
接收用户审阅后的文本;
对比所述审阅后的文本与所述标注后的文本,判断两个文本中标注的标签是否相同;
若所述两个文本中标注的标签不相同,则将所述审阅后的文本和修改后的标签加入训练集,并对所述自动标注模型进行迭代更新,同时将所述审阅后的文本保存至数据库替代原所述标注后的文本。
更进一步地,所述方法还包括如下步骤:
接收用户输入的语义搜索关键词;
根据所述语义搜索关键词与所述数据库中保存的文本进行标签匹配;
若所述数据库的文本中存在所述语义搜索关键词的标签,则显示标注有所述语义搜索关键词的标签的内容;
若所述数据库的文本中不存在所述语义搜索关键词的标签,则输出未检索到相关信息的提示。
更进一步地,所述标签的内容包括词语、句子、段落,或者文档中的其中之一或其任意组合。
更进一步地,所述文档集中包含多个基于所述自定义的语义标签标注的文档;
其中,每个自定义的语义标签对应3至5个所述文档。
本发明实施例还提供了一种基于小样本的语义标注装置,包括:
标注信息获取单元,用于获取用户自定义的语义标签、基于所述自定义的语义标签标注的文档集,以及待标注文本;
自动标注模型生成单元,用于以所述自定义的语义标签和所述文档集为训练集,通过机器学习算法建立训练模型,生成自动标注模型;
文本标注单元,用于利用所述自动标注模型,对所述待标注文本进行标注;
文本输出单元,用于输出标注后的文本,并将所述标注后的文本保存至数据库。
更进一步地,所述装置还包括:
第一接收单元,用于接收用户审阅后的文本;
标签判断单元,用于对比接收到的审阅后的文本与所述标注后的文本,判断两个文本中标注的标签是否相同;
数据更新单元,用于根据所述判断确定,若所述两个文本中标注的标签不相同,则将所述审阅后的文本和修改后的标签加入训练集,并对所述自动标注模型进行迭代更新,同时将所述审阅后的文本保存至数据库替代原所述标注后的文本。
更进一步地,所述装置还包括:
第二接收单元,用于接收用户输入的语义搜索关键词;
关键词搜索单元,用于根据用户输入的语义搜索关键词与所述数据库中保存的文本进行标签匹配;
第一显示单元,用于根据所述标签匹配的结果,确定若所述数据库的文本中存在所述语义搜索关键词的标签,则显示标注有所述语义搜索关键词的标签的内容;
第二显示单元,用于根据所述标签匹配的结果,确定若所述数据库的文本中不存在所述语义搜索关键词的标签,则输出未检索到相关信息的提示。
由于采用用户自定义的语义标签对文档进行标注,因此,不需要预先建立语义标签库,而是由用户自定义,满足用户个体需求即可。用户采用自定义的语义标签不仅增加了标签的丰富性,实现了标注个性化处理,还可以根据用户的理解来对语义进行标签定义,检索的便利性和灵活性更高。
另外,将这些自定义的语义标签和标注的文档作为训练集建立自动标注模型,实现基于小样本的训练即可,降低训练成本,同时,由于个性化的标签只需要少量训练集样本,相对于大型数据集的训练难以实现反复迭代而言,基于小样本的训练能够较快的完成训练,并能通过反复迭代提高准确率。
附图说明
图1是本发明提供的基于小样本的语义标注方法一个实施例的流程图;
图2是本发明提供的基于小样本的语义标注方法另一个实施例的流程图;
图3是本发明提供基于小样本的语义标注方法再一个实施例的流程图;
图4是本发明提供的基于小样本的语义标注装置一个实施例的结构示意图;
图5是本发明提供的基于小样本的语义标注装置另一个实施例的结构示意图;
图6是本发明提供的基于小样本的语义标注装置再一个实施例的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
现有技术中采用传统的标签模型如人工标注耗时高、效率低,通过大量大样本训练的方案成本高、反复迭代难度大,且均难以实现个性化和保证较高的准确率,因此,本发明实施例提出一种基于小样本的语义标注方法,根据用户自定义实现个性化标注,且基于小样本训练实现快速反复迭代提升准确率。
实施例一
参考图1所示,图1为本发明提供的基于小样本的语义标注方法一个实施例的流程图。
在步骤S101中,获取用户自定义的语义标签、基于自定义的语义标签标注的文档集,以及待标注文本;
可以理解的是,在本发明的实施例中,获取用户自定义的语义标签,其中,用户自定义的语义标签是指用户根据自己的理解或自己的偏好来对语义进行定义的标签,不同于某些领域内为满足群体需求所定义的通用或公共的标签,用户自定义的语义标签是为了满足个体需求而定义的。
可以理解的是,在本发明的实施例中,用户自定义的语义标签一般是用户根据所阅读到的句子、词语、段落或者某一篇或多篇文档,基于这些文字所要表达的核心语义来定义标签,即用这个标签来代表所标注的句子、词语或者段落的内容,与这个标签所代表的含义相关,或者根据标签表示用户所赋予该标签的含义,起到提示作用或着用户能够理解的其他自定义作用。
比如,在介绍某企业减少污染的措施但没有直接提及“环保措施”,用户可以定义标签“环保措施”来表示该段落与环保措施内容相关;
又如,用户以写作为目的浏览文档,就可以在用户认为在写作过程中需要再次参考/回顾的部分打上“重要”的标签。
可以理解的是,在本发明的实施例中,基于自定义的语义标签标注的文档集是指用于按照自己定义的标签已经完成标注的多个文档。
可以理解的是,在本发明的实施例中,待标注文本为未被标注的文档,即用户希望通过机器学习模型自动标注的文档,可以为一个,也可以为多个。
在步骤S102中,以自定义的语义标签和文档集为训练集,通过机器学习算法建立训练模型,生成自动标注模型;
可以理解的是,在本发明的实施例中,将用户自定义的语义标签和用户已经用自定义的语义标签完成标注的多个文档作为机器学习的训练集。
可以理解的是,在本发明的实施例中,机器学习的过程包含对训练集数据进行分割,比如分割为较大数据集用于训练,剩余较小子集用于测试,在训练的基础上建立预测模型,在测试中检验最佳模型,为了获得最佳模型,还可以进行超参数优化,超参数本质上是机器学习算法的参数,直接影响学习过程和预测性能。在另外一些实施例中,也可以将训练集数据分割为三部分,分别用于训练、验证和测试,此处不作任何限定。
可以理解的是,在本发明的实施例中,机器学习算法大致可以分为三种:监督学习类型、无监督学习类型、强化学习类型。机器学习算法可以是决策树算法、随机森林算法、支持向量机算法、深度学习算法、逻辑回归算法、聚类算法、贝叶斯分类器和神经网络算法中的任一项。以随机森林算法为例,在使用randomForest R包时,通常会对两个常见的超参数进行优化,其中包括mtry和ntree参数,mtry (maxfeatures)代表在每次分裂时作为候选变量随机采样的变量数量,而ntree (nestimators)代表要生长的树的数量。
可以理解的是,在本发明的实施例中,经过对样本集中提供的用户自定义的语义标签和基于所述自定义的语义标签标注的文档集的特征进行训练来建立模型,生成自动标注模型。
在步骤S103中,利用自动标注模型,对待标注文本进行标注;
可以理解的是,在本发明的实施例中,将对待标注文本输入到已经训练完成的自动标注模型中,通过模型计算对结果进行判断,根据提供的多组样本所提取的特征,来预测待标注文本中对应需要进行标注的词语、句子或段落。
在步骤S104中,输出标注后的文本,并将标注后的文本保存至数据库。
可以理解的是,在本发明的实施例中,通过模型完成自动标注之后,将标注后的文本输出模型,同时将标注后的文本保存至数据库中,以供后续搜索或调取时用。
通过用户采用自定义的语义标签不仅增加了标签的丰富性,实现了标注个性化处理,还可以根据用户的理解来对语义进行标签定义,检索的便利性和灵活性更高。
实施例二
参考图2所示,图2为本发明提供的基于小样本的语义标注方法另一个实施例的流程图。在本实施例中,本方案在实施例一方案的基础上作进一步优化,在实施例一步骤的基础上,本发明方法还包括如下步骤:
在步骤S201中,接收用户审阅后的文本;
可以理解的是,在本发明的实施例中,用户对实施例一步骤S104中输出的标注后的文本进行审阅,用户通过审阅判断,若有需要修改的标注,则对其修改;若不需要修改,则表示机器学习模型所作的标注准确度较高,能够正确的表达用户所要标注的内容。
可以理解的是,在本发明的实施例中,经过用户审阅之后,将审阅后的文本输入系统,系统接收用户审阅后的文本。
在步骤S202中,对比审阅后的文本与标注后的文本,判断两个文本中标注的标签是否相同;
可以理解的是,在本发明的实施例中,通过调取保存在数据库中的标注后的文本,将数据库中的标注后的文本与用户上传的审阅后的文本进行对比。
可以理解的是,在本发明的实施例中,判断两个文本中标注的标签是否相同,包括判断两个文本中所标注的标签位置是否一一对应,所用的标签是否完全一致,以及标签所代表的含义是否相同,即需要对比两个文件是否完全相同,若有一处不同,则认为两个文本中标注的标签不相同。
在步骤S203中,若两个文本中标注的标签不相同,则将审阅后的文本和修改后的标签加入训练集,并对自动标注模型进行迭代更新,同时将审阅后的文本保存至数据库替代原标注后的文本。
可以理解的是,在本发明的实施例中,若两个文本中标注的标签不相同,即两个文本中标注的标签存在区别,则将审阅后的文本和修改后的标签作为新的训练样本加入训练集,通过机器学习算法实现对自动标注模型进行迭代更新。
可以理解的是,在本发明的实施例中,同时将审阅后的文本保存至数据库替代原标注后的文本,以实现对数据库中保存的数据进行更新。
通过将这些自定义的语义标签和标注的文档作为训练集建立自动标注模型,实现基于小样本的训练即可,降低训练成本,同时,由于个性化的标签只需要少量训练集样本,相对于大型数据集的训练难以实现反复迭代而言,基于小样本的训练能够较快的完成训练,并能通过反复迭代提高准确率。
实施例三
参考图3所示,图3为本发明提供的基于小样本的语义标注方法再一个实施例的流程图。在本实施例中,本方案在实施例二方案的基础上作进一步优化,在实施例二步骤的基础上,本发明方法还包括如下步骤:
在步骤S301中,接收用户输入的语义搜索关键词;
可以理解的是,在本发明的实施例中,用户通过输入语义搜索关键词来检索数据库获取与关键词相关的词语、句子、段落或文本其中任一或其组合的标注。
可以理解的是,在本发明的实施例中,系统接收用户输入的语义搜索关键词之后,通过搜索关键词对数据库中保存的数据进行索引。
在步骤S302中,根据语义搜索关键词与数据库中保存的文本进行标签匹配;
可以理解的是,在本发明的实施例中,通过搜索关键词对数据库中保存的数据进行索引,包括与数据库中保存的所有文件中存在的标签进行一一比对来实现匹配,判断是否存在与搜索关键词相同的标签。
在步骤S303中,若数据库的文本中存在语义搜索关键词的标签,则显示标注有语义搜索关键词的标签的内容;
可以理解的是,在本发明的实施例中,若数据库的文本中存在与搜索关键词相同的标签,则显示标注有语义搜索关键词的标签的内容,内容可以是一个或多个词语、句子、段落或文档,也可以是其他指示内容。
在步骤S304中,若数据库的文本中不存在所述语义搜索关键词的标签,则输出未检索到相关信息的提示。
可以理解的是,在本发明的实施例中,若数据库的文本中存在与搜索关键词相同的标签,则系统提示未检索到相关信息。
通过语义搜索关键词的步骤,建立自定义标签与搜索关键词之间的联系,检测自定义标签的准确度,实现对自定义标签的校准,实现更加便捷的语义搜索。
实施例四
可以理解的是,在本发明的实施例中,标签的内容包括词语、句子、段落,或者文档中的其中之一或其任意组合。
实施例五
可以理解的是,在本发明的实施例中,文档集中包含多个基于自定义的语义标签标注的文档;其中,每个自定义的语义标签对应3至5个所述文档。
可以理解的是,在本发明的实施例中,用户添加个性化标签,只需要提供少量样本作为训练集,即每个自定义的语义标签在3至5个上传的训练集文档中存在,即可实现快速训练和反复迭代,大大的提升了效率,并能通过反复迭代提高准确率。
实施例六
参考图4所示,图4为本发明提供的基于小样本的语义标注装置一个实施例的结构示意图。作为对图1所示的一种基于小样本的语义标注方法的实现,本实施例提供一种基于小样本的语义标注装置,该装置实施例与图1所示的方法实施例相对应,该装置包括:
标注信息获取单元101,用于获取用户自定义的语义标签、基于自定义的语义标签标注的文档集,以及待标注文本;
自动标注模型生成单元102,用于以自定义的语义标签和文档集为训练集,通过机器学习算法建立训练模型,生成自动标注模型;
文本标注单元103,用于利用自动标注模型,对待标注文本进行标注;
文本输出单元104,用于输出标注后的文本,并将标注后的文本保存至数据库。
本发明实施例的有益效果为通过用户采用自定义的语义标签不仅增加了标签的丰富性,实现了标注个性化处理,还可以根据用户的理解来对语义进行标签定义,检索的便利性和灵活性更高。
实施例七
参考图5所示,图5为本发明提供的基于小样本的语义标注装置另一个实施例的流程图。作为在实施例六方案的基础上作进一步优化的装置,本实施例提供一种基于小样本的语义标注装置,该装置实施例与图2所示的方法实施例相对应,该装置还包括:
第一接收单元201,用于接收用户审阅后的文本;
标签判断单元202,用于对比接收到的审阅后的文本与标注后的文本,判断两个文本中标注的标签是否相同;
数据更新单元203,用于根据判断确定,若两个文本中标注的标签不相同,则将审阅后的文本和修改后的标签加入训练集,并对自动标注模型进行迭代更新,同时将审阅后的文本保存至数据库替代原标注后的文本。
本发明实施例的有益效果为通过将这些自定义的语义标签和标注的文档作为训练集建立自动标注模型,实现基于小样本的训练即可,降低训练成本,同时,由于个性化的标签只需要少量训练集样本,相对于大型数据集的训练难以实现反复迭代而言,基于小样本的训练能够较快的完成训练,并能通过反复迭代提高准确率。
实施例八
参考图6所示,图6为本发明提供的基于小样本的语义标注装置再一个实施例的流程图。作为在实施例七方案的基础上更进一步优化的装置,本实施例提供一种基于小样本的语义标注装置,该装置实施例与图3所示的方法实施例相对应,该装置还包括:
第二接收单元301,用于接收用户输入的语义搜索关键词;
关键词搜索单元302,用于根据用户输入的语义搜索关键词与数据库中保存的文本进行标签匹配;
第一显示单元303,用于根据标签匹配的结果,确定若数据库的文本中存在语义搜索关键词的标签,则显示标注有语义搜索关键词的标签的内容;
第二显示单元304,用于根据标签匹配的结果,确定若数据库的文本中不存在语义搜索关键词的标签,则输出未检索到相关信息的提示。
本发明实施例的有益效果为通过增加关键词搜索单元,建立自定义标签与搜索关键词之间的联系,检测自定义标签的准确度,实现对自定义标签的校准,实现更加便捷的语义搜索。
实施例九
本实施例提供基于小样本的语义标注系统,包括:存储器和处理器;
存储器,用于存储一个或多个程序,其中,当一个或多个程序被一个或多个处理器执行时,使得一个或多个处理器实现上述任一实施例的基于小样本的语义标注方法的步骤。
本发明实施例的基于小样本的语义标注系统的有益效果为不需要预先建立语义标签库,而是由用户自定义语义标签不仅增加了标签的丰富性,实现了标注个性化处理,还可以根据用户的理解来对语义进行标签定义,检索的便利性和灵活性更高,同时基于小样本的训练能够较快的完成训练,并能通过反复迭代提高准确率。
实施例十
本发明实施例还提供了一种计算机可读存储介质,计算机可读存储介质上存储有程序指令,程序指令被处理器执行时实现上述任一实施例的基于小样本的语义标注方法的步骤。
本发明的存储介质的有益效果为不需要预先建立语义标签库,而是由用户自定义语义标签不仅增加了标签的丰富性,实现了标注个性化处理,还可以根据用户的理解来对语义进行标签定义,检索的便利性和灵活性更高,同时基于小样本的训练能够较快的完成训练,并能通过反复迭代提高准确率。
本发明可用于众多通用或专用的计算机系统环境或配置中。
例如:个人计算机、服务器计算机、手持设备或便携式设备、平板型设备、多处理器系统、基于微处理器的系统、置顶盒、可编程的消费电子设备、网络PC、小型计算机、大型计算机、包括以上任何系统或设备的分布式计算环境等等。
综上所述,本发明实施例提供的一种基于小样本的语义标注方法及装置,可以实现获取用户自定义的语义标签、基于自定义的语义标签标注的文档集,以及待标注文本;以自定义的语义标签和文档集为训练集,通过机器学习算法建立训练模型,生成自动标注模型;利用自动标注模型,对待标注文本进行标注;输出标注后的文本,并将标注后的文本保存至数据库。从而解决了训练成本高、难以实现个性化和保证准确率的问题,带来了根据用户自定义实现个性化标注,且基于小样本训练实现快速反复迭代提升准确率的效果。
可以理解的是,本领域技术人员可以在以上实施例的教导下,可对以上各个实施例中各种实施方式进行组合,获得多种实施方式的技术方案。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种少标注样本下基于原型队列学习的全场景语义分割方法
- 一种基于超像素的图片语义分割标注方法及装置