一种基于智慧教育数据的高校学生学习画像生成系统及方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及用户画像及教育信息化技术领域,具体地涉及一种基于智慧教育数据的高校学生学习画像生成系统及方法。
背景技术
学生画像是基于一系列实际产生的数据所建立的用户模型,是由用户画像概念迁移而来,是用户画像在教育方面的使用场景。通过在海量的多源异构数据中,为学生标记学生标签,形成学生画像,更加全面、准确的去评价学生,运用学生画像采取个性化的教学方式等全方位了解学生、引导学生,从而提高教学质量,培养优秀人才,使学生获得个性化的学习支持服务,引领学生朝着期冀的方向改变。
当前学生画像的研究热点可分为画像构成要素、画像分析技术。画像构成要素随着学习对象、学习情境和学习内容的变化而变化,不同要素应能反映出学生个性化学习心理和外在表现特征;画像分析技术主要有多元分析法、聚类算法等,常与可视化分析技术相结合,立体呈现学生的学习过程。
学生画像领域当前仍存在一些不足:一是数据挖掘算法的应用较少且精确度较低,尚未构建统一且可行的学生标签体系,无法形成真实准确的学生画像;二是大量数据需要结合专业的数据处理知识才能被深入理解,无法被管理人员充分使用;三是当前的学生画像领域生搬用户画像领域的技术研究,忽略数据的限制强行去刻画丰富、全面的学生画像,无法做到针对性的画像描述,影响学生画像的准确性。
发明内容
针对现有技术的不足,本发明提出了一种基于智慧教育数据的高校学生学习画像生成系统及方法,构造聚焦于学习场景的学生画像标签体系,建立自动化学生画像生成,提升画像准确度,以解决当前的问题。
本发明的技术方案为:
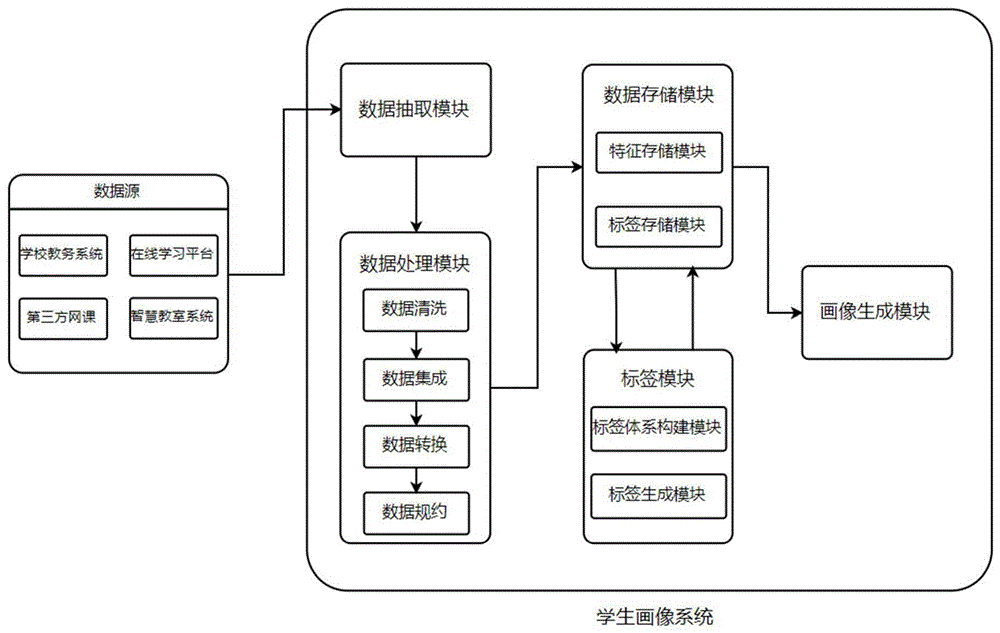
一种基于智慧教育数据的高校学生学习画像生成系统,包括数据抽取模块、数据处理模块、标签模块、数据存储模块、画像生成模块;
所述数据抽取模块、数据处理模块、数据存储模块、画像生成模块依次连接,所述数据存储模块连接所述标签模块;
所述数据抽取模块用于:抽取学习相关数据,包括:学生基本信息、课程信息、在线平台学习信息、课堂行为信息、学习成绩信息;将学习相关数据导入至数据处理模块中;
所述数据处理模块用于:接收数据抽取模块抽取的学习相关数据,对学习相关数据进行预处理,包括数据清洗、数据集成、数据转换、数据规约,形成学生特征数据集,存入数据存储模块;
所述标签模块用于:存储建立的标签体系和标签规则,并分析特征因素计算权重,生成学生画像标签;
所述数据存储模块用于:存储数据处理模块形成的学生特征数据集,将标签模块最终生成的学生画像标签数据进行数据库定向写入所述数据存储模块;
所述画像生成模块用于:整合标签生成不同维度的学生画像。
作为本发明进一步的方案,所述标签模块包括标签体系构建模块、标签生成模块;
所述标签体系构建模块用于:根据获取的学生特征数据类型及关联关系,构建表征学生学习情况的标签体系,通过聚类算法实现标签体系的自动更新;
所述标签生成模块用于:将学生划分为不同类型,生成相应的学生标签。
作为本发明进一步的方案,所述数据存储模块包括特征存储模块和标签存储模块;
所述特征存储模块用于:存储数据处理模块形成的学生特征数据集,根据学生特征数据集的特点,按照数据分布式存储、数据和索引分开存储原则进行数据库设计和数据集存储;
所述标签存储模块用于:存储经标签模块中的标签生成模块生成的学生标签,将标签数据进行数据库的定向写入。
一种基于智慧教育数据的高校学生学习画像生成方法,通过上述高校学生学习画像生成系统实现,包括:
步骤S1,通过数据抽取模块抽取学生的学习相关数据,包括学校教务系统中的学生基本信息、学生课程信息、学生成果信息、学生在课堂上的行为信息、学习数据信息;将学习相关数据导入至数据处理模块;
步骤S2,对数据处理模块中的学习相关数据进行数据处理,包括:数据清洗、数据集成、数据转换、数据规约;初构建学生特征数据集并存储至数据存储模块的特征存储模块;
步骤S3,在标签模块的标签体系构建模块中建立标签体系;
步骤S4,在标签模块的标签生成模块中进行标签生成;
作为本发明进一步的方案,在标签模块的标签体系构建模块中建立标签体系,包括:
(1)读取数据存储模块中的特征存储模块,根据学生特征数据集中的学生数据的共有特征,分类梳理为五个维度,建立一级标签;
(2)对一级标签进行细化,体现学生标签体系的管理及分析维度,建立二级标签;
(3)明确二级标签具体内容,采用预聚类模型对二级标签进行下属标签分类,分别将特征值传入PEA(Pre-clustering ensemble algorithm,预聚类集成算法)中,获取细化类别K值,求取公式如式(I)所示:
K=[AVG(K
式(I),[]为向下取整符号,代表调整到不超过它的最大整数,PEA算法的输入是学生特征数据集X,学生特征数据集X传入PEA算法内部的Canopy处理器,误差平方和SSE处理器,轮廓系数SC处理器,分别得到K
(4)将二级标签下属标签具体分K类,反映学生具体状态的个性化特征,建立三级标签。
作为本发明进一步的方案,在标签模块的标签生成模块中进行标签生成,包括:
a、采用基于MMD(Max-Min Distance,最大最小距离)的K-prototype算法进行标签生成,输入数据存储模块中特征存储模块的特征数据集X至MMD算法,输出聚类中心集C;
b、将步骤a生成的聚类中心集C传入K-prototype算法,通过聚类计算,输出该样本的类作为聚类结果,该聚类结果与标签模块的标签体系构建模块相结合进行标签生成,标签结果存储至数据存储模块的标签存储;
c、画像生成模块通过连接数据存储模块中的标签存储模块整合标签生成不同维度的学生画像。
作为本发明进一步的方案,聚类中心集C的求取过程如下:
采用基于MMD的K-prototype算法,输入学生特征数据集X={x
选择第m个聚类中心,对于j=1,2,...,m-1,分别计算数据集X中的样本到集合C={c
d
如果m等于K,则输出聚类中心集C;否则m增加1,重复上述步骤,输出初始聚类中心集合C={c
作为本发明进一步的方案,步骤b的具体实现过程包括:
将步骤a生成的聚类中心集C传入K-prototype算法,并传入学生特征数据集合X={X
对于数值型特征,距离表示公式如式(IV)所示:
对于类别型特征,使用汉明距离进行计算,如式(V)所示:
其中,当p=q时,δ(P,q)=0;当p≠q时,δ(p,q)=1;对于样本i,
计算混合特征类型的对象之间的相异性,把不同的特征组合到单个相异性矩阵中,K为聚类个数,设Qc={q
d(X
式(VI)中,d(X
则K-prototype的损失函数定义为式(VII):
代表类别c的样本中所有数值特征的总损失,/>
从数据集X中选择经MMD算法生成的聚类中心集C={c
对于数值特征采用式(IV)计算,对于类别特征采用式(V)计算;采用式(VI)和式(VII)计算损失函数;如果新的损失函数值小于所设定的阈值或迭代次数大于设定的T,则计算结束,输出聚类结果,否则重复上述步骤;该结果与标签模块的标签体系构建模块相结合进行标签生成,标签结果存储至数据存储模块的标签存储模块中。
一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现基于智慧教育数据的高校学生学习画像生成方法的步骤。
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现基于智慧教育数据的高校学生学习画像生成方法的步骤。
与现有技术相比,本发明的有益效果是:
1、本发明通过构造客观、真实准确的学生画像标签体系,降低大量数据给师生带来的认知负荷。
2、本发明对学生群体进行深度刻画,生成的画像准确度高,为学生教育管理者提供相应的决策支持,从而助力学生学业发展。
3、本发明减少人工打标签从而导致的重复性、繁琐性工作,定期更新标签体系,实现画像的自动化更新。
4、本发明以统一封装系统替代,不同数据输入即可得到具有差异化的画像系统。
附图说明
下面结合说明书附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述或其它方面的优点将会更加清楚。
图1为本发明基于智慧教育数据的高校学生学习画像生成系统的结构框图;
图2为本发明的学生学习画像生成方法流程示意图;
图3为本发明数据集X在算法中的流动示意图。
具体实施方式:
下面结合附图及实施例对本发明做进一步说明,但不限于此。
实施例1
一种基于智慧教育数据的高校学生学习画像生成系统,如图1所示,包括数据抽取模块、数据处理模块、标签模块、数据存储模块、画像生成模块;
数据抽取模块、数据处理模块、数据存储模块、画像生成模块依次连接,数据存储模块连接标签模块;
数据抽取模块用于:通过Kettle和Sqoop数据抽取工具从学校教务系统、在线学习平台、智慧教室系统中抽取学习相关数据,包括:学生基本信息、课程信息、在线平台学习信息、课堂行为信息、学习成绩信息;学生基本信息包括但不限于:学号stu_num、学生性别stu_age、注册年份enrol_year、学生年级stu_grade、学生专业stu_major,课程信息包括但不限于:课程代码course_code、课程名称course_name、课程年份course_year、课程成绩course_score,在线平台学习信息包括但不限于:登陆时间login_time、平台在线时长online_time、下载资源次数download_times、观看视频时长Viewing_duration、做题次数exercises_num,课堂行为信息包括但不限于:学生课堂行为stu_behavior,学习成绩信息包括但不限于:学生平均学分绩点stu_gpa、学生成果信息stu_achievement,将学习相关数据导入至数据处理模块中;
使用大数据组件Sqoop进行数据源抽取、HUE进行任务调度,每天定时执行Sqoop任务,以系统对接,数据录入,批量导入等方式,从各个业务系统中采集学生相关的各类学习数据,导入至数据处理平台,包括:对源数据的数据结构及其字段内容进行统计分析,形成空值数量、统计记录行数、字段规则等分析结果;基于时间戳、触发器以及日志实现增量数据捕获;进行数据抽取,将数据进行初步处理,对数据进行检验、清洗、解码与重命名,检验数据的有效性,检查数据是否存在逻辑错误,查找并纠正数据中可识别的错误,例如数据一致性检查、无效值和缺省值处理等;将收集来的学生学习数据传入数据处理模块。
数据处理模块用于:接收数据抽取模块抽取的学习相关数据,对学习相关数据进行预处理,包括数据清洗、数据集成、数据转换、数据规约,形成学生特征数据集,存入数据存储模块;包括:
以完整性、全面性、合法性、唯一性原则对原始数据集进行处理,对于缺失数据需要确定缺失值的范围,对每个字段都计算其缺失值的比例,按照缺失比例和字段的重要程度选择不同的清洗方法;对于重要性高,缺失率低的字段通过均值、中位数、自动填充空值0或近邻值补齐等方法进行填充;对于重要性高,缺失率高的字段使用其他字段通过计算获取;对于重要性低,缺失率低的字段进行简单填充或不做处理;对于重要性低,缺失率高的字段采用去除该字段的方法;例如针对教务系统中的成绩数据,一些学生因为休学、缺考等不确定性因素造成的数据缺失,为了保证数据的完整性,对这些数据进行了清洗。结合学生学籍信息剔除休学学生的数据,将缺考学生成绩记为0;
同名异义、异名同义、单位不统一、命名不一致的实体识别和属性冗余的问题进行数据集成,在遇到不匹配时在底层加以转换、提炼与集成;
对各类型数据进行归一化处理,消除数据量纲不同的影响,统一学习数据的格式,这里,即将学习数据变化为[0,1]之间的数值,这里采取最大最小值归一化线性变换方式:
其中X′
将处理完毕的学生特征数据集存入数据存储模块。
标签模块用于:存储建立的标签体系和标签规则,并分析特征因素计算权重,生成学生画像标签;
数据存储模块用于:存储数据处理模块形成的学生特征数据集,将标签模块最终生成的学生画像标签数据进行数据库定向写入所述数据存储模块;
画像生成模块用于:整合标签生成不同维度的学生画像。
实施例2
根据实施例1所述的一种基于智慧教育数据的高校学生学习画像生成系统,其区别在于:
标签模块包括标签体系构建模块、标签生成模块;
标签体系构建模块用于:根据获取的学生特征数据类型及关联关系,构建表征学生学习情况的标签体系,通过聚类算法实现标签体系的自动更新;包括:
综合利用各类学习数据,根据学生不同的特征,标签维度分为基础标签和扩展标签,基础标签描述学生的基本情况,扩展标签描述学生的学习特征,建立三个等级的学生标签,包括:
学生标签体系的一级标签,其为学生画像的基本刻画维度,学生的一级标签是学生的共有特征,数量固定,形式统一,可以梳理为基本信息、学业表现、实验实训、课堂表现、创新能力、综合评价六个一级标签,如下表1所示;
表1
学生标签体系的二级标签,是对一级标签进行细化,体现学生标签体系的管理及分析维度,数量及形式基本固定,涵盖基本信息、选课与成绩、课堂状态等多个方面,学生标签体系的二级标签如下表2所示;
表2
学生标签体系的三级标签,是对二级标签具体内容的明确,通过反映学生具体状态的个性化特征,性别、年级、专业主要用来描述学生的固有属性和基本特征,不需要过多计算和处理便可以从数据库中直接提取,属于直接获取的类型;选课偏好类型、绩点这类标签通过划定数值的规则范围,经过聚合函数count,max,min,between,大于,小于等数量统计和逻辑运算即可获得,属于统计计算的类型;其余的二级标签像平台活跃度、课程参与度、学习评价不能通过简单的计算获得,需要根据业务需求以及经过预聚类集成PEA算法(Pre-clustering ensemble algorithm)输出的K值确定二级标签的K类下属三级标签;学生标签体系的三级标签如下表3所示;
表3
具体标签具有不同的含义,例如在学习评价中的各三级标签包括:努力学霸型学生,天赋型学生,体验型学生,潜力型学生,具体含义包括:
努力学霸型学生,该类学生学习成绩优秀,并且在平台上的活跃度和参与度、学习投入程度很高,能够花费大量时间进行自学;
天赋型学生,该类学生学习投入程度和活跃度相比第一类学生有较大差距,但学习成绩相比努力学霸型的学生差距很小,推测是因其课程完成度较高,故学习成绩较好,此类学生若能在课程学习投入更多时间,学习效果更好;
体验型学生,该类学生学习成绩差,学习程度、教学活跃程度、课程完成度都是最低,一方面,该类学生仅以体验的心态在平台上进行课程实验的学习;另一方面,课程难度对于此类学生过大,以致产生厌学情绪,导致成绩较低;
潜力型学生,该类学生学习成绩一般,学习投入不多,活跃频次较少,课程完成度较低,此类学生需要激发其学习兴趣,否则容易造成成绩下降。
标签生成模块用于:通过数据存储模块中的特征存储模块和标签模块中的标签体系构建模块,将学生划分为不同类型,生成相应的学生标签,存储至数据存储模块。
实施例3
根据实施例1所述的一种基于智慧教育数据的高校学生学习画像生成系统,其区别在于:
数据存储模块的数据存储设计采用事件、学生用户和事件属性来记录学生行为事件,每一条事件数据对应学生用户的一次事件,一个用户可以产生多个事件,一个事件可以包含多个事件属性;一个完整的事件,包含:事件参与者(参与这个事件的具体学生用户,在系统的数据接口中,使用user_id来设置用户的唯一ID)、事件发生时间(这个事件发生的实际时间,在数据接口中,使用time字段来记录精确到毫秒的事件发生时间。如果不主动设置,则会自动获取当前时间作为time字段的取值)、事件发生地点、事件发生方式、事件具体内容;每个User实体都对应一个真实的用户,通过User_id进行唯一标识。User实体会通过User_id与这个用户的行为和事件进行关联;
数据存储模块包括特征存储模块和标签存储模块;
特征存储模块用于:存储数据处理模块形成的学生特征数据集,根据学生特征数据集的特点,按照数据分布式存储、数据和索引分开存储原则进行数据库设计和数据集存储;
标签存储模块用于:存储经标签模块中的标签生成模块生成的学生标签,将标签数据进行数据库的定向写入。
实施例4
一种基于智慧教育数据的高校学生学习画像生成方法,通过上述实施例1-3任一所述高校学生学习画像生成系统实现,如图2所示,包括:
步骤S1,通过数据抽取模块抽取学生的学习相关数据,包括学校教务系统中的学生基本信息、学生课程信息、学生成果信息、智慧教室系统中学生在课堂上的行为信息、在线学习平台中的学习数据信息;将学习相关数据导入至数据处理模块;
步骤S2,对数据处理模块中的学习相关数据进行数据处理,在充分保障学生数据隐私和确保学生数据的真实性和有效性的前提下进行数据预处理,包括:数据清洗、数据集成、数据转换、数据规约;初构建学生特征数据集并存储至数据存储模块的特征存储模块;
数据清洗、数据集成、数据转换、数据规约,包括:
步骤S2.1,数据集成:将学生的学号stu_num作为唯一标识符,使用Python的Pandas库执行数据连接操作,将从学校教务系统、在线学习平台、智慧教室系统中采集到各csv文件进行合并,创建一个包含来自各系统不同文件的所有相关数据的学生特征数据集。
步骤S2.2,数据清洗:对学生特征数据集进行数据清洗,包括:
步骤S2.2.1,识别缺失值:然后使用Pandas库的isna()函数进行标识缺失值,对于数值特征,使用均值、中位数进行填充;对于类别特征,使用众数进行填充;对于时间特征,使用前后时间值进行插值填充;对于缺失数据需要确定缺失值的范围,对每个特征都计算其缺失值的比例,按照缺失比例和字段的重要程度选择不同的清洗方法。
步骤S2.2.2,处理缺失值:对于重要性高,缺失率低的字段通过均值、中位数、自动填充空值0或近邻值补齐等方法进行填充。对于重要性高,缺失率高的字段使用其他字段通过计算获取。对于重要性低,缺失率低的字段进行简单填充或不做处理。对于重要性低,缺失率高的字段采用去除该字段的方法。例如针对学校教务系统中的成绩数据,一些学生因为休学、缺考等不确定性因素造成的数据缺失,为了保证数据的完整性,剔除休学学生的数据,将缺考学生成绩记为0。
步骤S2.2.3,处理重复值:使用Pandas的duplicated()函数检查是否存在重复的记录,如有重复值,使用drop_duplicates()函数删除重复记录。
步骤S2.3,数据转换
使用独热编码(One-Hot Encoding)将学生特征数据集X中只具有两种类别属性的类别特征转换为一个二进制向量,使用pandas库中的"get_dummies"方法将类别特征转换为数字形式,比如对于性别特征类别,用0和1分别表示男和女,这可以帮助模型理解和处理分类信息。
步骤S2.4,数据规约
对学生特征数据集X中的数字特征数据进行归一化处理,消除数据量纲不同的影响,统一学习数据的格式,将学习数据变化为[0,1]之间的数值,采取最大最小值归一化线性变换方式:
其中X′ij表示该属性归一化后的值,Xij表示未归一化的值,X max表示该属性所有样本最大值,Xmin表示该属性所有样本最小值;
步骤S2.5,经过以上预处理步骤之后形成学生特征数据集X,并存储至数据存储模块的特征存储模块。
步骤S3,在标签模块的标签体系构建模块中建立标签体系;包括:
(1)读取数据存储模块中的特征存储模块,根据学生特征数据集中的学生数据的共有特征,分类梳理为五个维度,建立一级标签;
(2)对一级标签进行细化,体现学生标签体系的管理及分析维度,建立二级标签;
(3)明确二级标签具体内容,采用预聚类模型对二级标签进行下属标签分类,分别将特征值传入PEA(Pre-clustering ensemble algorithm,预聚类集成算法)中,获取细化类别K值,求取公式如式(I)所示:
K=[AVG(K
式(I),[]为向下取整符号,代表调整到不超过它的最大整数,例如,[5.8]等于5。PEA算法的输入是学生特征数据集X,学生特征数据集X传入PEA算法内部的Canopy处理器,误差平方和SSE处理器,轮廓系数SC处理器,分别得到K
K
输出K
K
式中,c
输出K
K
a
设k取2到10,遍历不同k值的计算出不同的轮廓系数,选最大的轮廓系数所对应的k值,则为K
输出K
(4)将二级标签下属标签具体分K类,反映学生具体状态的个性化特征,建立三级标签。
步骤S4,在标签模块的标签生成模块中进行标签生成;包括:
a、采用基于MMD(Max-Min Distance,最大最小距离)的K-prototype算法进行标签生成,输入数据存储模块中特征存储模块的特征数据集X至MMD算法,输出聚类中心集C;
b、将步骤a生成的聚类中心集C传入K-prototype算法,通过聚类计算,输出该样本的类作为聚类结果,该聚类结果与标签模块的标签体系构建模块相结合进行标签生成,标签结果存储至数据存储模块的标签存储;
c、画像生成模块通过连接数据存储模块中的标签存储模块整合标签生成不同维度的学生画像。
作为本发明进一步的方案,聚类中心集C的求取过程如下:
采用基于MMD的K-prototype算法,输入学生特征数据集X={x
/>
选择第m个聚类中心,对于j=1,2,…,m-1,分别计算数据集X中的样本到集合C={c
d
如果m等于K,则输出聚类中心集C;否则m增加1,重复上述步骤,输出初始聚类中心集合C={c
步骤b的具体实现过程包括:
将步骤a生成的聚类中心集C传入K-prototype算法,并传入学生特征数据集合X={X
对于数值型特征,距离表示公式如式(IV)所示:
对于类别型特征,使用汉明距离进行计算,如式(V)所示:
其中,当p=q时,δ(P,q)=0;当p≠q时,δ(p,q)=1;对于样本i,
计算混合特征类型的对象之间的相异性,把不同的特征组合到单个相异性矩阵中,K为聚类个数,设Qc={q
d(X
式(VI)中,d(X
则K-prototype的损失函数定义为式(VII):
代表类别c的样本中所有数值特征的总损失,/>
从数据集X中选择经MMD算法生成的聚类中心集C={c
对于数值特征采用式(IV)计算,对于类别特征采用式(V)计算;采用式(VI)和式(VII)计算损失函数;如果新的损失函数值小于所设定的阈值或迭代次数大于设定的T,则计算结束,输出聚类结果,否则重复上述步骤;该结果与标签模块的标签体系构建模块相结合进行标签生成,标签结果存储至数据存储模块的标签存储模块中。数据集X在算法中的流动示意图如图3所示。
步骤S5,画像生成模块通过连接数据存储模块中的标签存储模块整合标签生成不同维度的学生画像。
实施例5
根据实施例4所述的一种基于智慧教育数据的高校学生学习画像生成方法,其区别在于:
以活跃度标签为例,对步骤S4进行进一步举例说明:
步骤1,学生数据经数据处理后处于HBase的tag_users表中,Hbase中的profile表用于存储各学生用户的具有哪些标签,在MySQL中包含标签规则表basic_tag、模型表model,标签表用来存储业务各级标签,包含标签id、标签名称、父标签、标签规则等字段,模型表存储具体Spark应用程序相关信息,用来驱动标签模型的运作,包含算法id、标签id、算法引擎、算法入口等字段;在标签表basic_tag中新建一级标签——实验实训,新建二级标签子标签——平台活跃度,同时在model表中插入相关字段数据;
步骤2,然后根据商业用户画像领域中的用户活跃度模型RFE引入RFT模型概念,RFE是根据最近一次访问时间R(Recency)、访问频率F(Frequency)和页面互动度E(Engagements)计算得出的RFE得分,学生活跃度模型RFT即为学生最近一次访问时间R,一个月内登陆频率F,均次在线时间T,利用RFT模型的三个属性对学生进行打分,R-F-T分别按照5、4、3、2、1进行赋值,分别给出R_Score、F_Score、T_Score值,给RFN值设置打分规则:
R:今天至上一次登陆间隔天数0-3天=5分,4-6天=4分,7-9天=3分,10-15天=2分,大于16天=1分;
F:一个月内登陆次数≥11=5分,7-10=4分,5-7=3分,2-4=2分,0-1=1分;
T:均次在线时间≥120min=5分,60-119min=4分,30-59min=3分,10-29min=2分,0-9min=1分;
步骤3,依照步骤2的规则计算RFT值,依据MySQL的basic_tag表中标签元数据解析标签规则,依据标签规则rule,获取业务数据inType判断业务数据的数据源,然后解析参数为Meta,加载业务数据解析出表名称、列簇及列名称,到指定的HBase数据库读取tag_users表的数据,获取业务数据,从学生实验实训数据表中获取相应字段值,转换为每个学生用户的RFN_Score值;根据Canopy粗聚类以及业务经验定义四个类别,新建三级标签高活跃、中度活跃、低活跃、不活跃,其规则值分别对应0,1,2,3,将R_Score、F_Score、T_Score组合为特征值features传入到K-prototype模型中,训练获取模型预测值prediction,预测值prediction为类簇cluster中心点的索引下标,类簇中心点索引数据与标签规则数据合并,依据获取的业务数据和三级属性标签数据中规则,进行关联匹配,构建每个用户的活跃度标签;最终将画像标签数据存储HBase中的profile表中。
本发明提供了一种基于智慧教育数据的高校学生学习画像生成方法及系统,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
实施例6
一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现实施例4或5所述基于智慧教育数据的高校学生学习画像生成方法的步骤。
实施例7
一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现实施例4或5所述基于智慧教育数据的高校学生学习画像生成方法的步骤。
- 一种基于学习成长数据的学习风格画像生成方法及系统
- 数据量充分性判定装置、数据量充分性判定方法、数据量充分性判定程序、学习模型生成系统、完成学习的学习模型生成方法及完成学习的学习模型生成程序