一种基于BERT神经网络与多方面语义学习的关系抽取方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及自然语言识别处理领域中的情感分析,具体是一种基于BERT(Bidirectional Encoder Representations from Transformers)神经网络与多方面语义学习的关系抽取方法,可广泛应用于各个领域的知识图谱自动生成任务中。
背景技术
关系抽取是信息抽取的关键技术之一,旨在识别出给定句子的实体对之间的语义关系,提取的语义关系可应用在知识库自动补全、问答系统等下游任务中。传统的神经网络的关系抽取方法需要大量精准标注的训练数据,然而要获取这些数据需要耗费大量的时间和精力。为了克服上述的问题,目前出现使用大规模预训练模型,如使用谷歌提出的BERT(Bidirectional Encoder Representations from Transformers)来减少下游关系抽取的训练规模。然而,如何在BERT模型之上沿袭传统神经网络关系抽取方法中的一些技术,如广泛采用的分段卷积神经网络技术,成为新的挑战。本专利在BERT模型之上采用多方面语义学习来移植传统的分段卷积神经网络技术,实现即可减少下游关系抽取的训练规模,又可沿袭传统神经网络关系抽取方法中的分段卷积神经网络技术。
发明内容
本发明公开了一种基于BERT神经网络与多方面语义学习的关系抽取方法,在BERT模型之上采用多方面语义学习来改进传统的分段卷积神经网络技术,实现即可减少下游关系抽取的训练规模,又可沿袭传统神经网络关系抽取方法中的分段卷积神经网络技术,以更有效的方法解决方面级情感分析问题。
为实现上述目的,本发明的技术方案为:
一种基于BERT神经网络与多方面语义学习的关系抽取方法,其特征在于包括以下步骤:
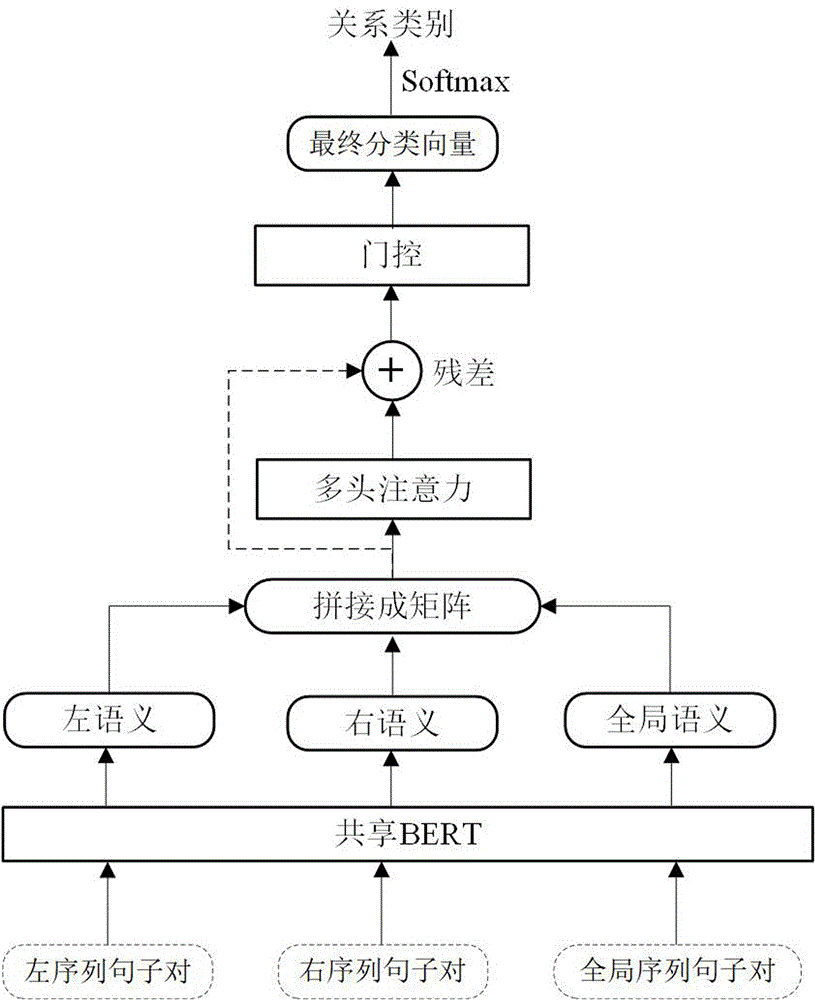
S1.将关系抽取的样本分为左序列、右序列、全局序列,然后将左序列、右序列和全局序列分别与待抽取关系的实体对拼接起来,形成实体感知的左序列、右序列和全局序列句子对;
S2.将实体感知的左序列、右序列和全局序列句子对,分别输入到一个参数共享的BERT神经网络模型中进行处理,得到相应的左语义、右语义和全局语义的隐藏表示;并在左语义、右语义和全局语义的隐藏表示中,分别将BERT分类符所对应的隐藏状态提取出来,形成左语义、右语义和全局语义的分类向量;
S3.将左语义、右语义和全局语义的分类向量按行拼接成一个三行矩阵,并送入到一个多头注意力机制进行融合及残差操作,得到样本的残差分类矩阵;
S4.将样本的残差分类矩阵进行平均池化,得到样本的残差分类向量,并对其进行门控操作,得到样本的最终分类向量;
S5.将样本的最终分类向量送入一个执行softmax操作的全连接层,计算样本在所有关系类别上的置信分数和概率,根据概率的最高值确定样本中指定实体对的关系类别;
所述BERT神经网络是指Google AI Language提出的Bidirectional EncoderRepresentations from Transformers(BERT)语言模型;
所述步骤S1具体包括:
以样本中待抽取关系的实体对为分界,将样本分为左序列、右序列、全局序列,并以BERT的分类符[CLS]作为开始符号、以BERT的分离符[SEP]作为分隔符和结束符,形成实体感知的句子对;
其中,实体感知的全局序列句子对s
所述步骤S2具体包括:
S2.1将左序列句子对s
H
H
H
其中,sharedBERT(·)表示一个参数共享的BERT模型;
S2.2分别在左语义、右语义和全局语义的隐藏表示H
所述步骤S3具体包括:
S3.1将左语义、右语义和全局语义的分类向量按行拼接成一个三行的语义矩阵H
H
其中,[:]表示将向量按行拼接成矩阵;
S3.2将H
其中,MHA(·)表示多头注意力机制,且有Q=K=V=H
MHA(Q,K,V)=tanh([head
head
其中,Q∈R
S3.3将融合矩阵
其中,LayerNorm(·)表示神经网络中的层归一化,所述层归一化是文献“Ba J L,Kiros J R,Hinton G E.Layer normalization.in:arXiv:1607.06450,2016.”所提出的层归一化算法,将参数将它们处理为-1和1之间的不饱和值,“+”表示矩阵的逐元素相加;
所述步骤S4具体包括:
S4.1将样本的残差分类矩阵H
h
其中,avePooling(H
S4.2对残差分类向量h
g=Sigmoid(W
Z=h
其中,g为门控中的门向量,b
所述步骤S5具体包括:
S5.1通过样本的最终分类向量Z,计算样本在所有关系类别上的置信分数,计算过程如下:
其中,
S5.2通过样本在所有关系类别上的置信分数的向量o,计算样本在指定关系类别上的预测概率,计算过程如下
其中,y是一个指定的关系类别,p(y|Z,θ)表示样本的最终分类向量Z在指定的关系类别y上的预测概率,θ是所有可学习的参数集合,exp(·)表示以e为底的指数函数;S5.3根据概率的最高值确定样本中指定实体对的关系类别,计算过程如下:
其中,Ω为关系类别的集合,y
进一步的,所述BERT神经网络的损失函数采用如下的交叉熵损失误差:
其中,T是关系抽取任务的训练样本的集合,|T|表示集合T的大小,y
训练目标是按公式(16)最小化T中所有训练样本的交叉熵损失误差。
更进一步的,所述BERT神经网络在微调的回溯过程中,固定BERT的词嵌入层和位置嵌入层,设置方法为:
bert.enbeddings,word_embeddings,word_embeddings.weight.requires_grad=False(17)
bert.embeddings.position_embeddings.weight.requires_grad=False(18)
公式(17)和公式(18)为两个设置BERT模型参数的公式,其中公式(17)表示在回溯过程中不更新BERT词嵌入层的权重,公式(18)表示在回溯过程中不更新BERT位置嵌入层的权重。
本发明具有以下优点:
(1)充分利用BERT模型广泛的预训,为模型获取知识丰富的初始化参数,使模型只需小规模的微调即可快速适应关系抽取任务;
(2)提出了一个基于BERT的关系抽取多方面语义学习框架,包括左语义学习、右语义学习和全局语义学,为移植传统的分段卷积神经网络技术创造了条件;
(3)提出了一种基于残差、门控和多头注意力机制的多方面语义融合方法,生成了语义丰富的分类向量;
(4)模型遵循BERT中的Transformer结构,使用轻量级的多头自注意力和线性变换层进行编码,使模型更容易训练和成型。
附图说明
图1是本发明的方法流程示意图。
具体实施方式
以下结合具体实施例对本发明作进一步说明,但本发明的保护范围不限于以下实施例。
对于包含两个待抽取关系的实体的样本,按照图1所示的本发明方法流程图,通过以下步骤分析样本指定实体对之间的关系类别:
S1.将关系抽取的样本分为左序列、右序列、全局序列,然后将左序列、右序列和全局序列分别与待抽取关系的实体对拼接起来,形成实体感知的左序列、右序列和全局序列句子对;
S2.将实体感知的左序列、右序列和全局序列句子对,分别输入到一个参数共享的BERT神经网络模型中进行处理,得到相应的左语义、右语义和全局语义的隐藏表示;并在左语义、右语义和全局语义的隐藏表示中,分别将BERT分类符所对应的隐藏状态提取出来,形成左语义、右语义和全局语义的分类向量;
S3.将左语义、右语义和全局语义的分类向量按行拼接成一个三行矩阵,并送入到一个多头注意力机制进行融合及残差操作,得到样本的残差分类矩阵;
S4.将样本的残差分类矩阵进行平均池化,得到样本的残差分类向量,并对其进行门控操作,得到样本的最终分类向量;
S5.将样本的最终分类向量送入一个执行softmax操作的全连接层,计算样本在所有关系类别上的置信分数和概率,根据概率的最高值确定样本中指定实体对的关系类别;
所述BERT神经网络是指Google AI Language提出的Bidirectional EncoderRepresentations from Transformers(BERT)语言模型;
所述步骤S1具体包括:
以样本中待抽取关系的实体对为分界,将样本分为左序列、右序列、全局序列,并以BERT的分类符[CLS]作为开始符号、以BERT的分离符[SEP]作为分隔符和结束符,形成实体感知的句子对;
其中,实体感知的全局序列句子对s
所述步骤S2具体包括:
S2.1将左序列句子对s
H
H
H
其中,sharedBERT(·)表示一个参数共享的BERT模型;
S2.2分别在左语义、右语义和全局语义的隐藏表示H
所述步骤S3具体包括:
S3.1将左语义、右语义和全局语义的分类向量按行拼接成一个三行的语义矩阵H
H
其中,[:]表示将向量按行拼接成矩阵;
S3.2将H
其中,MHA(·)表示多头注意力机制,且有Q=K=V=H
MHA(Q,K,V)=tanh([head
head
其中,Q∈R
S3.3将融合矩阵
其中,LayerNorm(·)表示神经网络中的层归一化,所述层归一化是文献“Ba J L,Kiros J R,Hinton G E.Layer normalization.in:arXiv:1607.06450,2016.”所提出的层归一化算法,将参数将它们处理为-1和1之间的不饱和值,“+”表示矩阵的逐元素相加;
所述步骤S4具体包括:
S4.1将样本的残差分类矩阵H
h
其中,avePooling(H
S4.2对残差分类向量H
g=Sigmoid(W
Z=h
其中,g为门控中的门向量,b
所述步骤S5具体包括:
S5.1通过样本的最终分类向量Z,计算样本在所有关系类别上的置信分数,计算过程如下:
其中,
S5.2通过样本在所有关系类别上的置信分数的向量o,计算样本在指定关系类别上的预测概率,计算过程如下
其中,y是一个指定的关系类别,p(y|Z,θ)表示样本的最终分类向量Z在指定的关系类别y上的预测概率,θ是所有可学习的参数集合,exp(·)表示以e为底的指数函数;S5.3根据概率的最高值确定样本中指定实体对的关系类别,计算过程如下:
其中,Ω为关系类别的集合,y
进一步的,所述BERT神经网络的损失函数采用如下的交叉熵损失误差:
其中,T是关系抽取任务的训练样本的集合,|T|表示集合T的大小,y
训练目标是按公式(16)最小化T中所有训练样本的交叉熵损失误差。
更进一步的,所述BERT神经网络在微调的回溯过程中,固定BERT的词嵌入层和位置嵌入层,设置方法为:
bert.embeddings.word_embeddings.weight.requires_grad=False (17)
bert.embeddinggs.position_embeddings.weight.requires_grad=False (18)
公式(17)和公式(18)为两个设置BERT模型参数的公式,其中公式(17)表示在回溯过程中不更新BERT词嵌入层的权重,公式(18)表示在回溯过程中不更新BERT位置嵌入层的权重。
应用实例
1数据集介绍
SemEval-2010 Task 8(http://www.kozareva.com/downloads.html)数据集是关系抽取领域的经典数据集,本实例使用它来进行实验。该数据集中包含9中关系类型和1中other类型,other类型表明实体间的关系类型不属于上述9种关系类型中的任何一种。这9种关系类型分别是:Casuse-Effect,Component-Whole,Content-Container,Entity-Destination,Entity-Origin,Instrument-Agency,Member-Collection,Message-Topicand Product-Producer,但是,该数据集要考虑方向,比如Entity-Origin(E1,E2)和Entity-Origin(E2,E1)是不同的,所以该数据集在最后判断的时候应当是有19种关系类型。该数据集包含10,717个样本,每个句子包含两个实体E1和E2,其中训练样本有8000个,测试样本有2717个,本实例使用SemEval-2010 Task 8(https://dl.acm.org/doi/10.5555/1621969.1621986)的官方脚本评估实例的实验,评价指标是M-F1。
2参数设置
本实例的参数设置如下所示:
表1实例的超参数
本实例在训练时的batch size为16,验证时的batch size为32。
3比较方法与比较结果
本实例将本发明的方法与在SemEval-2010 Task 8数据集上发布的经典多种方法作比较,包括CNN[1],RNN[2],Bi-LSTM[3],Attention CNN[4],TRE[5],Entity-Aware BERT[6],BERTEM+MTB[7],R-BERT[8],knowBert[9],A-GCN+BERT[10],RE-DMP+XLNet[11]具体比较情况如表2所示:
表2实验对比结果
表2的结果表明,本实例所实现的本发明提出的模型在M-F1值方面优于各种非BERT的关系抽取方法和基于BERT的关系抽取方法,以及优于BERT基线模型,这充分证明了本发明所提出的基于BERT神经网络与多方面语义学习的关系抽取方法是可行与优秀的。
参考文献:
[1]Zeng,D.,Liu,K.,Lai,S.,Zhou,G.,&Zhao,J.(2014).RelationClassification via Convolutional Deep Neural Network.International Conferenceon Computational Linguistics,2335–2344.
[2]Socher,R.,Huval,B.,Manning,C.D.,&Ng,A.Y.(2012).SemanticCompositionality through Recursive Matrix-Vector Spaces.In Empirical Methodsin Natural Language Processing(pp.1201–1211).
[3]Zhang,S.,Zheng,D.,Hu,X.,&Yang,M.(2015).Bidirectional Long Short-Term Memory Networks for Relation Classification.In Pacific Asia Conferenceon Language,Information,and Computation(pp.73–78).
[4]Shen,Y.,&Huang,X.(2016).Attention-Based Convolutional NeuralNetwork for Semantic Relation Extraction.In International Conference onComputational Linguistics(pp.2526–2536).
[5]Alt,C.,Hübner,M.P.,&Hennig,L.(2019).Improving Relation Extractionby Pre-trained Language Representations.arXiv(Cornell University).https://arxiv.org/abs/1906.03088
[6]Wang,H.,Tan,M.,Yu,M.,Chang,S.,Wang,D.,Xu,K.,Guo,X.,&Potdar,S.(2019).Extracting Multiple-Relations in One-Pass with Pre-TrainedTransformers.arXiv(Cornell University).
[7]Soares,L.,FitzGerald,N.,Ling,J.,&Kwiatkowski,T.(2019).Matching theBlanks:Distributional Similarity for Relation Learning.In Meeting of theAssociation for Computational Linguistics.https://doi.org/10.18653/v1/p19-1279
[8]Wu,S.,&He,Y.(2019).Enriching Pre-trained Language Model withEntity Information for Relation Classification.In Conference on Informationand Knowledge Management.https://doi.org/10.1145/3357384.3358119
[9]Peters,M.J.,Neumann,M.E.,Logan,R.K.,Schwartz,R.,Joshi,V.,Singh,S.,&Smith,N.A.(2019).Knowledge Enhanced Contextual WordRepresentations.https://doi.org/10.18653/v1/d19-1005
[10]Tian,Y.,Chen,G.,Song,Y.,&Wan,X.(2021).Dependency-driven RelationExtraction with Attentive Graph Convolutional Networks.https://doi.org/10.18653/v1/2021.acl-long.344
[11]Tian,Y.,Song,Y.,&Xia,F.(2022).Improving Relation Extractionthrough Syntax-induced Pre-training with Dependency Masking.In Findings ofthe Association for Computational Linguistics:ACL 2022.https://doi.org/10.18653/v1/2022.findings-acl.147
4.样本预处理示例
对于关系抽取样本:"He had chest pains and
表格3样本的预处理
/>
- 一种基于BERT语义增强的因果关系抽取方法
- 基于BERT神经网络的中文人物关系抽取构建方法