数据处理芯片及其制造方法、数据处理系统
文献发布时间:2024-04-18 19:58:26
技术领域
本公开涉及数据处理技术领域,尤其涉及一种数据处理芯片及其制造方法、数据处理系统。
背景技术
随着科技的发展,越来越多的领域,例如人工智能、安全运算等领域都涉及大量的数据处理(即大数据处理)。大数据处理将会在处理器和存储器之间产生频繁且大量的数据交互,这就要求存储器具有更高的带宽,以满足算力需求。
然而,常规架构的设计中,内存的性能提升速度落后于处理器的性能提升速度,有限的内存带宽无法保证数据的高速传输,难以满足算力需求。
发明内容
本公开提供一种数据处理芯片及其制造方法、数据处理系统。
根据本公开的第一方面,提供一种数据处理芯片,包括:
第一晶粒,包括:运算器;
第二晶粒,与所述第一晶粒堆叠设置,包括:缓存器,所述缓存器通过键合与所述运算器耦接;其中,所述缓存器被配置为:在所述运算器与主机进行数据传输或在所述运算器与存储器进行数据传输时,对传输的所述数据进行缓存。
在一些实施例中,所述数据处理芯片还包括:
布线层,位于所述第一晶粒和所述第二晶粒之间的第三晶粒中;或者,位于第二晶粒中且位于所述第一晶粒和所述缓存器之间;
桥接电路,位于所述布线层中,所述桥接电路的第一端口通过第一接口协议与所述运算器耦接,所述桥接电路的第二端口通过第二接口协议与所述缓存器耦接;其中,所述第二接口协议和所述第一接口协议不同。
在一些实施例中,所述运算器包括:多个运算单元;所述缓存器包括:多个缓存单元;
所述数据处理芯片包括:
多个所述桥接电路,位于所述布线层中;其中,多个所述运算单元中的每个分别通过多个所述桥接电路中的每个与多个所述缓存单元耦接。
在一些实施例中,所述第一晶粒还包括:
处理器,通过键合与所述缓存器耦接;其中,所述缓存器还被配置为:在所述处理器与存储器进行数据传输时,对传输的所述数据进行缓存。
在一些实施例中,所述第二晶粒的正投影与所述第一晶粒的正投影重合。
在一些实施例中,所述缓存器的存储容量大于预设值;其中,所述预设值大于0兆且小于1千兆。
在一些实施例中,所述缓存器包括:动态随机存取存储器、闪存存储器、相变存储器或磁性隧道结存储器。
根据本公开的第二方面,提供一种数据处理芯片的制造方法,包括:
形成第一晶粒,所述第一晶粒包括运算器;
形成与所述第一晶粒堆叠设置的第二晶粒,所述第二晶粒包括缓存器,所述缓存器通过键合与所述运算器耦接;其中,所述缓存器被配置为:在所述运算器与主机进行数据传输或在所述运算器与存储器进行数据传输时,对传输的所述数据进行缓存。
在一些实施例中,所述制造方法还包括:
提供第一晶圆,所述第一晶圆包括多个所述第一晶粒;
提供第二晶圆,所述第二晶圆包括多个所述第二晶粒;
所述形成与所述第一晶粒堆叠设置的第二晶粒,包括:
键合所述第一晶圆和所述第二晶圆,使得所述运算器与所述缓存器耦接;
对键合的所述第一晶圆和所述第二晶圆执行切割处理。
在一些实施例中,在键合所述第一晶圆和所述第二晶圆之前,所述制造方法还包括:
提供第三晶圆,所述第三晶圆包括布线层和位于所述布线层中的桥接电路;
将所述第三晶圆的第一面和所述第一晶圆键合,使得所述桥接电路的第一端口通过第一接口协议与所述运算器耦接;
将所述第三晶圆的第二面和所述第二晶圆键合,使得所述桥接电路的第二端口通过第二接口协议与所述缓存器耦接;其中,所述第二接口协议和所述第一接口协议不同;所述第二面与所述第一面相对设置。
在一些实施例中,所述提供第二晶圆,包括:
形成所述缓存器;
在所述缓存器上形成布线层;
在所述布线层中形成桥接电路,所述桥接电路的第二端口通过第二接口协议与所述缓存器耦接;
所述键合所述第一晶圆和所述第二晶圆,包括:
倒置所述第二晶圆,使得所述布线层位于所述第一晶粒和所述缓存器之间;
键合所述桥接电路和所述运算器,使得所述桥接电路的第一端口通过第一接口协议与所述运算器耦接;其中,所述第二接口协议和所述第一接口协议不同。
在一些实施例中,所述第一晶圆采用第一制程工艺,所述第二晶圆采用第二制程工艺;其中,所述第二制程工艺对应的特征尺寸大于所述第一制程工艺对应的特征尺寸。
根据本公开的第三方面,提供一种数据处理系统,包括:
如上述任一实施例中所述的数据处理芯片;
至少一个所述存储器,与所述第一晶粒沿第一方向并列设置,所述第一方向垂直于所述第二晶粒与所述第一晶粒堆叠的方向。
在一些实施例中,所述数据处理芯片和所述存储器构成节点芯片;
所述数据处理系统包括:多个所述节点芯片;其中,多个所述节点芯片沿第二方向并列设置且集联,所述第二方向垂直于所述第二晶粒与所述第一晶粒堆叠的方向,第二方向与所述第一方向相交。
本公开实施例中,第一方面,通过设置第一晶粒与第二晶粒堆叠,缓存器和运算器之间可通过键合的方式耦接,从而为数据传输提供更高的带宽,实现高算力的同时降低了系统的带宽需求;第二方面,相较于设置片上缓存,本公开通过在第一晶粒之外(即片外)设置第二晶粒,第二晶粒中的缓存器用于缓存数据,有利于降低片上系统的设计复杂度,降低数据处理芯片的设计、生产成本。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。
图1是根据一示例性实施例示出的一种理论能够获得的最大计算性能模型图;
图2是根据本公开实施例示出的一种数据处理芯片的结构示意图;
图3是根据本公开实施例示出的一种数据处理系统的示意图;
图4是根据本公开实施例示出的另一种数据处理系统的示意图;
图5是根据本公开实施例示出的一种数据处理芯片的制造方法的流程图;
图6a是根据本公开实施例示出的一种数据处理芯片的制造过程示意图一;
图6b是根据本公开实施例示出的一种数据处理芯片的制造过程示意图二;
图6c是根据本公开实施例示出的一种数据处理芯片的制造过程示意图三。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置的例子。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本公开旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。
为了说明本公开的技术方案,下面将结合具体的实施例来进行说明。
随着计算算力的大幅提升,系统的带宽要求也随之上升,否则无限制的提升算力对系统整体性能并没有帮助。图1是根据一示例性实施例示出的一种理论能够获得的最大计算性能模型图(Roof-line model),参照图1可知,受限于内存的带宽瓶颈,系统的理论性能不再随着算力的增加而增加,如图1中虚线右侧所示。
系统的带宽需求透过不同的存储器形态持续演进,以动态随机存取存储器(Dynamic Random Access Memory,DRAM)为例,开发出了双倍速率同步动态随机存储器(Double Data Rate,DDR)、低功耗内存(Low Power Double Data Rate,LPDDR)、显卡内存(Graphics Double Data Rate,GDDR)以及高带宽内存(High Bandwidth Memory,HBM)等,以满足不同的系统带宽需求。
然而,提升系统的带宽需求伴随而来的代价是成本开销的大幅提升以及设计复杂度的增加。以上述示意的几种存储器为例,带宽大小满足:HBM>GDDR>LPDDR>DDR;设计复杂度满足:HBM>GDDR>LPDDR=DDR;成本开销满足:HBM>GDDR>LPDDR>DDR。
通过增加片上缓存(on-chip cache),例如,在片上系统(System on Chip,SOC)中集成静态随机存取存储器(Static Random-Access Memory,SRAM),可以减小系统访问片外存储器的带宽需求。然而,片上缓存的成本高昂,并且容量较小(SRAM最多达到MB等级),对于系统带宽需求减少的帮助有限。因此,如何实现高算力的同时降低系统带宽需求,成为亟待解决的技术问题。
有鉴于此,本公开提供一种数据处理芯片及其制造方法、数据处理系统。
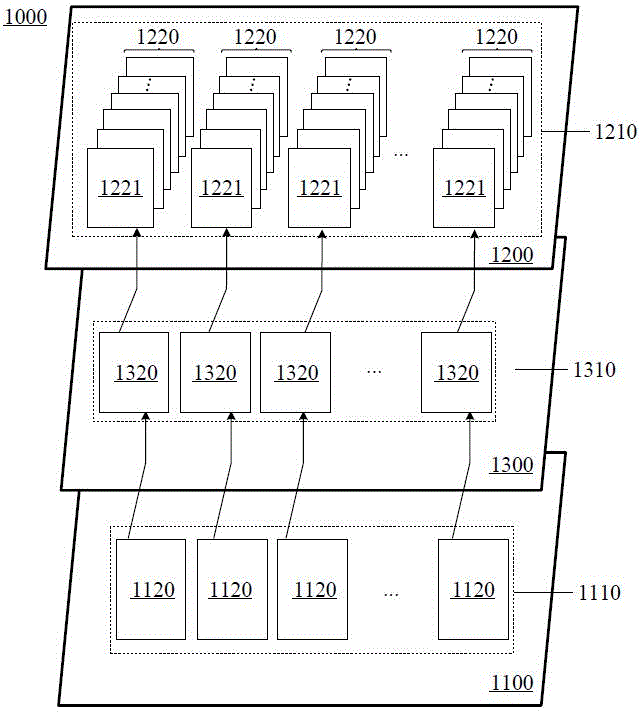
图2是根据本公开实施例示出的一种数据处理芯片1000的结构示意图。参照图2所示,数据处理芯片1000,包括:
第一晶粒1100,包括:运算器1110;
第二晶粒1200,与第一晶粒1100堆叠设置,包括:缓存器1210,缓存器1210通过键合与运算器1110耦接;其中,缓存器1210被配置为:在运算器1110与主机进行数据传输或在运算器1110与存储器进行数据传输时,对传输的数据进行缓存。
第一晶粒1100包括但不限于集成有多个功能电路的片上系统SOC。第一晶粒1100包括运算器1110;进一步地,结合图3所示,第一晶粒1100还包括处理器1130、存储器接口电路1150以及节点接口电路1160等,处理器1130、存储器接口电路1150以及节点接口电路1160将在下文中进行说明。需要说明的是,图2或图3中所示的功能电路仅作为示例示出,第一晶粒1100还可以包括本领域已知的其它功能电路,例如,第一晶粒1100还包括电源、电源管理电路以及时序控制电路等。
运算器1110被配置为响应于控制命令执行特定计算并输出计算结果。运算器1110包括中央处理器(Central Processing Unit,CPU)、图形处理器(Graphics ProcessingUnit,GPU)、张量处理器(Tensor Processing Unit,TPU)、处理器分散处理器(DataProcessing Unit,DPU)、智能处理器(Image Processing Unit,IPU)或神经网络处理器(Neural-network Processing Unit,NPU)等。运算器1110可以执行哈希算法、卷积算法或者神经网络算法等。
在一具体示例中,运算器1110为张量处理器TPU,包括矩阵乘法单元(Matrixmultiplication Unit,MXU),矩阵乘法单元又称为脉动阵列,可以处理65536次8位整数的乘法和加法,极大地提高了数据处理芯片的算力。
第二晶粒1200和第一晶粒1100之间可通过晶圆键合(Wafer on Wafer,WoW)技术实现堆叠,第二晶粒1200与第一晶粒1100之间可通过键合层(bonding layer)、硅穿孔(Through-Silicon-Via,TSV)、引线(wiring)或凸块(bump)中的至少一种实现电气连接。
缓存器1210可在执行写入操作时,缓存待写入存储器的数据;或者,在执行读取操作时,缓存从存储器中读取的数据;或者,缓存运算器1110待运算的数据;或者,缓存运算器1110执行运算后输出的数据。缓存器1210包括:动态随机存取存储器DRAM、闪存存储器(Flash Memory)、相变存储器(Phase Change Memory,PCM)或磁性隧道结存储器(MagneticTunnel Junction,MTJ)等。在其它实施例中,缓存器1210还可以是本领域已知的其它类型的存储器,本公开对此并无特殊限制。
在一具体示例中,缓存器1210为动态随机存取存储器DRAM,DRAM的容量通常为千兆(GigaByte,GB)等级并且具有更多的引脚(pin),可通过运行低速数字电路达到高带宽。可以理解的是,本示例中通过将存储容量更大并且引脚更多的DRAM用作数据处理芯片的缓存器,可极大的降低系统的带宽需求;并且相较于采用成本高昂的SRAM用作缓存,本示例中采用DRAM用作缓存可极大的降低成本。
需要说明的是,第一晶粒1100通常采用先进制程工艺,例如,5nm制程、3nm制程或1nm制程等,先进制程工艺需要更高昂的设计以及生产成本,在片上系统中集成片上缓存无疑会带来成本的浪费。基于此,在其它实施例中,缓存器1210还可以是SRAM,SRAM可采用大于20nm的制程工艺,例如,22nm制程、25nm制程或28nm制程等。可以理解的是,本示例中,通过将制程工艺要求更低的SRAM与第一晶粒1100堆叠,并且用作缓存,可节约数据处理芯片的设计以及生产成本。
在一些实施例中,第一晶粒1100采用第一制程工艺制造而成,第二晶粒1200采用第二制程工艺制造而成;其中,第二制程工艺对应的特征尺寸大于第一制程工艺对应的特征尺寸。例如,第一晶粒1100为SOC,SOC的制程工艺所对应的特征尺寸为5nm;第二晶粒1200为DRAM,DRAM的制程工艺所对应的特征尺寸为25nm。
需要强调的是,这里仅为示例,用以向本领域技术人员传达本公开,第一晶粒1100和第二晶粒1200还可以是本领域已知的其它类型,第一晶粒1100的制程工艺所对应的特征尺寸不限于5nm,第二晶粒1200的制程工艺所对应的特征尺寸不限于25nm,只需保证第二制程工艺对应的特征尺寸大于第一制程工艺对应的特征尺寸即可。当然,在其它实施例中,第二制程工艺对应的特征尺寸可以小于或等于第一制程工艺对应的特征尺寸。
本公开实施例中,第一方面,通过设置第一晶粒与第二晶粒堆叠,缓存器和运算器之间可通过键合的方式耦接,从而为数据传输提供更高的带宽,实现高算力的同时降低了系统的带宽需求;第二方面,相较于设置片上缓存,本公开通过在第一晶粒之外(即片外)设置第二晶粒,第二晶粒中的缓存器用于缓存数据,有利于降低片上系统的设计复杂度,降低数据处理芯片的设计以及生产成本。
在一些实施例中,参照图2所示,数据处理芯片1000还包括:
布线层(routing layer)1310,位于第一晶粒1100和第二晶粒1200之间的第三晶粒1300中;或者,位于第二晶粒1200中且位于第一晶粒1100和缓存器1210之间;
桥接电路1320,位于布线层1310中,桥接电路1320的第一端口通过第一接口协议与运算器1110耦接,桥接电路1320的第二端口通过第二接口协议与缓存器1210耦接;其中,第二接口协议和第一接口协议不同。
图2示出了布线层1310位于第三晶粒1300中,第一晶粒1100、第三晶粒1300、第二晶粒1200依次堆叠设置。在另一示例中,布线层1310位于第二晶粒1200中(图中未示出),即第一晶粒1100和第二晶粒1200依次堆叠设置。
需要说明的是,由于第一晶粒1100采用更先进的制程工艺,在片上系统中集成片上缓存导致设计以及生产成本进一步增加。本实施例中,通过第一晶粒与第二晶粒堆叠设置,并将布线层设置在第三晶粒中或第二晶粒中,由于第三晶粒或第二晶粒的制程工艺要求更低,有利于进一步降低数据处理芯片的设计以及生产成本。在其它实施例中,布线层还可以位于第一晶粒中且位于运算器和第二晶粒之间。
在一些实施例中,第三晶粒1300采用第三制程工艺制造而成,第三制程工艺对应的特征尺寸大于第一制程工艺对应的特征尺寸。例如,第三制程工艺所对应的特征尺寸为28nm。需要强调的是,这里仅为示例,用以向本领域技术人员传达本公开,第三晶粒1300的制程工艺所对应的特征尺寸不限于28nm,只需保证第三制程工艺对应的特征尺寸大于第一制程工艺对应的特征尺寸即可。当然,在其它实施例中,第三制程工艺对应的特征尺寸可以小于或等于第一制程工艺对应的特征尺寸。
在一些实施例中,第三制程工艺对应的特征尺寸和第二制程工艺对应的特征尺寸可以相同或者不同。
布线层1310包括绝缘层和位于绝缘层中的布线(图中未示出)。绝缘层的材料包括硅氧化物,氮氧化物或硅氮氧化物等;布线的材料包括导电材料,例如,铜、铝、铂、钛或锡中的至少一种。
桥接电路1320用于对运算器1110和缓存器1210之间传输的数据进行协议转换。桥接电路1320包括第一端口、转换单元和第二端口;第一端口用于耦接运算器1110,第二端口用于耦接缓存器1210;转换单元用于将第一端口和运算器1110之间遵从的第一接口协议转换为第二端口和缓存器1210之间遵从的第二接口协议,从而保证数据在运算器1110和缓存器1210之间的传输。
在一具体示例中,桥接电路1320的第一端口与运算器1110的输入/输出接口耦接,桥接电路1320的第一端口和运算器1110之间可遵从SRAM的接口协议(SRAM protocol);桥接电路1320的第二端口与缓存器1210的输入/输出接口耦接,桥接电路1320的第二端口和缓存器1210之间可遵从DRAM的接口协议(DRAM protocol)。当然,在其它实施例中,也可省略转换单元,桥接电路1320的第一端口和运算器1110之间以及桥接电路1320的第二端口和缓存器1210之间均可遵从DRAM的接口协议。
本公开实施例中,通过在第三晶粒或第二晶粒中设置布线层,并将桥接电路设置在布线层中,实现运算器和缓存器之间数据传输的同时,进一步降低数据处理芯片的设计以及生产成本。此外,通过设置桥接电路,即可实现运算器和缓存器之间的数据传输,可与现有的接口协议兼容。
在一些实施例中,数据处理芯片1000包括:至少两个第二晶粒,分别位于第一晶粒的两侧;至少两个布线层,分别位于第一晶粒的两侧,且位于第一晶粒和第二晶粒之间或位于第二晶粒中。
例如,数据处理芯片1000包括一对第二晶粒和一对布线层,一对第二晶粒分别记为第一个第二晶粒和第二个第二晶粒,一对布线层分别记为第一个布线层和第二个布线层;第一个第二晶粒、第一晶粒、第二个第二晶粒依次堆叠设置;第一个第二晶粒和第一晶粒之间通过第一个布线层耦接,第一晶粒和第二个第二晶粒之间通过第二个布线层耦接,第一个布线层可以位于第一个第二晶粒和第一晶粒之间的第三晶粒中,也可以位于第一个第二晶粒中;第二个布线层可以位于第一晶粒和第二个第二晶粒之间的第三晶粒中,也可以位于第二个第二晶粒中。这里,第二晶粒和布线层的数量不限于两个,还可以是三个甚至更多个。
在一些实施例中,参照图2所示,运算器1110包括:多个运算单元1120;缓存器1210包括:多个缓存单元1220;
数据处理芯片1000包括:多个桥接电路1320,位于布线层1310中;其中,多个运算单元1120中的每个分别通过多个桥接电路1320中的每个与多个缓存单元1220耦接。
这里,运算单元1120的数量可以是两个或者多个,缓存单元1220的数量可以是两个或者多个,桥接电路1320的数量可以是两个或者多个。运算单元1120的数量、缓存单元1220的数量和桥接电路1320的数量中的至少两者可以相同或者不同。
在一些实施例中,运算单元1120的数量、缓存单元1220的数量和桥接电路1320的数量相同。在一具体实施例中,运算单元1120的数量、缓存单元1220的数量和桥接电路1320的数量均为1024个。可以理解的是,本实施例中,多个运算单元1120可通过多个桥接电路1320分别与多个缓存单元1220一一对应耦接,每个运算单元1120可对缓存在对应的缓存单元1220中的数据进行管理,有利于提高数据处理芯片的计算性能。
在一具体实施例中,运算单元1120的存储容量为128B,缓存单元1220的存储容量为8MB。
在一些实施例中,缓存单元1220包括多个内存数组片(Memory Array Tile,MAT)1221。例如,缓存单元1220包括96个MAT。缓存单元1220包括的内存数组片的数量不限于此。
在一些实施例中,第一晶粒还包括:处理器,通过键合与缓存器耦接;其中,缓存器还被配置为:在处理器与存储器进行数据传输时,对传输的数据进行缓存。结合图3所示,处理器1130和运算器1110均位于第一晶粒1100中,且沿垂直于第一晶粒1100和第二晶粒1200堆叠的方向并列设置,处理器1130被配置为控制存储器的逻辑操作,例如,写入操作、读取操作或擦除操作等。
结合图2和图3所示,缓存器1210包括第一缓存区和第二缓存区(图中未示出);其中,第一缓存区与运算器1110耦接,第二缓存区与处理器1130耦接。可以理解的是,将容量更大的DRAM作为缓存器时,可对DRAM的存储空间进行分区,一部分存储空间作为运算器1110的缓存,另一部分存储空间作为处理器1130的缓存,如此,可提高DRAM存储空间的利用率。这里,第一缓存区和第二缓存区的容量大小可以相同或者不同,本领域技术人员可以根据实际需求进行合理设置,本公开对此并无特殊限制。
在一些实施例中,第二晶粒1200的正投影与第一晶粒1100的正投影重合,即第二晶粒1200和第一晶粒1100具有相同的面积,更有利于数据处理芯片制造过程中的切割和封装,提高数据处理芯片的制造良率。
在一些实施例中,第一缓存区的正投影和运算器1110的正投影重合,第二缓存区的正投影和处理器1130的正投影重合,即第一缓存区和运算器1110具有相同的面积,第二缓存区和处理器1130具有相同的面积。
在一些实施例中,缓存器1210的存储容量大于预设值;其中,预设值大于0兆(MebiByte,MB)且小于1千兆(GigaByte,GB)。
需要指出的是,出于成本的考量,片上SRAM的容量通常小于1GB,例如,片上SRAM的容量可以是MB等级。本公开实施例中,通过设置缓存器的存储容量大于预设值,可增大片外缓存器的存储容量,降低系统的带宽需求。
在一具体实施例中,在将SRAM用作缓存器的片上系统中,SRAM的存储容量为MB等级,其对应系统的带宽需求为每秒数太字节带宽,需要设置较高带宽的存储器,例如高带宽存储器HBM,才能满足系统带宽需求,其代价是设计复杂与高生产成本。本公开通过将缓存器1210的存储容量为GB等级的DRAM用作片外缓存器使用,可将系统的带宽需求降低至每秒数千兆字节带宽,无需再设置较高带宽的存储器,例如,高带宽存储器HBM,简化数据处理芯片设计复杂度的同时,降低了成本。
在一些实施例中,数据处理芯片1000应用于人工智能领域,数据处理芯片1000包括但不限于人工智能芯片(Artificial Intelligence,AI)。
基于上述数据处理芯片,本公开实施例还提供一种数据处理系统。数据处理系统,包括:上述任一实施例中的数据处理芯片;至少一个存储器,与第一晶粒沿第一方向并列设置,第一方向垂直于第二晶粒与第一晶粒堆叠的方向。
图3是根据本公开实施例示出的一种数据处理系统3000的示意图。参照图3所示,第一晶粒1100与多个存储器2000沿第一方向并列设置,第一晶粒1100通过存储器接口电路1150与存储器2000耦接。例如,图3示出了8个存储器2000a、2000b、2000c、2000d、2000e、2000f、2000g和2000h,存储器2000a、2000b、2000c和2000d位于第一晶粒1100的一侧,存储器2000e、2000f、2000g和2000h位于第一晶粒1100的另一侧。
存储器2000包括:双倍速率同步动态随机存储器(Double Data Rate,DDR)、低功耗内存(Low Power Double Data Rate,LPDDR)、显卡内存(Graphics Double Data Rate,GDDR)以及高带宽内存(High Bandwidth Memory,HBM)等。在一具体实施例中,缓存器1210为动态随机存取存储器DRAM,存储器2000为第五代低功耗内存LPDDR5,简称LP5。
在一些实施例中,参照图3所示,在第二晶粒中设置缓存器后,可省掉第一晶粒1100中的SRAM缓存1140(如图3中虚线框所示),有利于减小数据处理芯片的平面尺寸。在其它实施例中,结合图3所示,在第二晶粒中设置缓存器后,也可保留第一晶粒1100中的SRAM缓存1140,SRAM与第二晶粒中的缓存器共同作为缓存,有利于进一步减小带宽需求。本领域技术人员可以根据实际需求进行合理设置,本公开在此不作限制。
可以理解的是,本公开实施例通过设置第一晶粒与第二晶粒堆叠,第二晶粒中的缓存器用作缓存,降低了系统的带宽需求,从而可以选用低带宽高容量的存储器,且无需集联过多个计算芯片节点,有利于降低数据处理系统设计复杂度、生产成本以及提高集成度。
在一些实施例中,第一晶粒1100与多个存储器2000位于数据处理系统3000的第一层级中,第三晶粒1300位于数据处理系统3000的第二层级中,第二晶粒1200位于数据处理系统3000的第三层级。即第一晶粒1100与多个存储器2000位于相同的层级中,第三晶粒1300与多个存储器2000位于不同的层级中,第二晶粒1200与多个存储器2000位于不同的层级中。
需要说明的是,本公开中所使用的层级相同表示的是两个晶粒与封装基板(图中未示出)的顶表面或底表面之间具有相同的距离,层级不同表示的是两个晶粒与封装基板的顶表面或底表面之间具有不同的距离。
在一些实施例中,数据处理芯片和存储器构成节点芯片;数据处理系统包括:多个节点芯片;其中,多个节点芯片沿第二方向并列设置且集联,第二方向垂直于第二晶粒与第一晶粒堆叠的方向,第二方向与第一方向相交。这里,集联包括串联设置、网状(mesh)网络设置、环形(ring)设置或者一对多设置等,本公开实施例对多个节点芯片的连接方式并无特殊限制。
图3中的数据处理芯片1000和至少一个存储器2000可构成节点芯片,图4是根据本公开实施例示出的另一种数据处理系统4000的示意图。参照图4所示,数据处理系统4000包括多个节点芯片,例如,图4示出了4个节点芯片4000a、4000b、4000c和4000d,节点芯片之间可通过节点接口电路1160连接。通过集联多个节点芯片,可进一步提高数据处理系统的算力。
基于上述数据处理芯片,本公开实施例还提供一种数据处理芯片的制造方法。
图5是根据本公开实施例示出的一种数据处理芯片的制造方法的流程图。参照图5所示,该制造方法至少包括以下步骤:
S5100:形成第一晶粒,第一晶粒包括运算器;
S5200:形成与第一晶粒堆叠设置的第二晶粒,第二晶粒包括缓存器,缓存器通过键合与运算器耦接;其中,缓存器被配置为:在运算器与主机进行数据传输或在运算器与存储器进行数据传输时,对传输的数据进行缓存。
需要说明的是,图5中所示的步骤并非排他的,也可以在所示操作中的任何步骤之前、之后或之间执行其他步骤;图5中所示的各步骤可以根据实际需求进行顺序调整。
图6a至图6c是根据本公开实施例示出的一种数据处理芯片的制造过程示意图。下面将结合图5、图6a至图6c对本公开实施例提供的数据处理芯片的制造方法进行详细地说明。
参照图6a所示,提供第一晶圆6100A,第一晶圆6100A包括多个第一晶粒6100;提供第二晶圆6200A,第二晶圆6200A包括多个第二晶粒6200。
第一晶圆6100A和第二晶圆6200A可采用半导体领域已知的工艺(例如,薄膜沉积工艺、光刻工艺、刻蚀工艺、粒子注入工艺等)制造,此处不再赘述。第一晶圆6100A采用第一制程工艺,第二晶圆6200A采用第二制程工艺,第二制程工艺对应的特征尺寸大于第一制程工艺对应的特征尺寸。这里,特征尺寸表示的是第一晶圆6100A或第二晶圆6200A中的最小尺寸。当然,在其它实施例中,第二制程工艺对应的特征尺寸可以小于或等于第一制程工艺对应的特征尺寸。
第一晶圆6100A包括多个第一晶粒6100以及位于相邻的两个第一晶粒6100之间的第一切割道,第二晶圆6200A包括多个第二晶粒6200以及位于相邻的两个第二晶粒6200之间的第二切割道。在一具体实施例中,第一晶粒6100的尺寸与第二晶粒6200的尺寸相同,第一切割道的尺寸与第二切割道的尺寸相同。这里,尺寸包括长度和宽度。
在一些实施例中,上述步骤S5200,包括:键合第一晶圆和第二晶圆,使得运算器与缓存器耦接;对键合的第一晶圆和第二晶圆执行切割处理,然后将两个芯片共同封装。
参照图6b所示,在第一晶圆6100A和第二晶圆6200A制造完成后,可将第一晶圆6100A与第二晶圆6200A对准。具体地,将第一晶粒6100与第二晶粒(图中未示出)对准,第一切割道与第二切割道对准;进一步地,将第一晶粒6100中的运算器与第二晶粒中的缓存器对准(可参照图2中的运算器1110和缓存器1210)。这里,为了便于示意,未示出第二晶粒6200。应当理解的是,图6b中第二晶粒6200位于第二晶圆6200A朝向第一晶圆6100A的表面。
在第一晶圆6100A和第二晶圆6200A对准后,执行切割处理,将键合的第一晶圆6100A和第二晶圆6200A切割为多个数据处理芯片,例如,图2中所示的数据处理芯片;数据处理芯片包括堆叠的第一晶粒和第二晶粒,第一晶粒包括运算器,第二晶粒包括缓存器,运算器和缓存器之间通过键合耦接,然后将两个芯片共同封装。
在一些实施例中,在键合第一晶圆和第二晶圆之前,上述制造方法还包括:
提供第三晶圆,第三晶圆包括布线层和位于布线层中的桥接电路;
将第三晶圆的第一面和第一晶圆键合,使得桥接电路的第一端口通过第一接口协议与运算器耦接;
将第三晶圆的第二面和第二晶圆键合,使得桥接电路的第二端口通过第二接口协议与缓存器耦接;其中,第二接口协议和第一接口协议不同;第二面与第一面相对设置。
参照图6c所示,提供第三晶圆6300A,第三晶圆6300A包括多个第三晶粒(图中未示出)。第三晶圆6300A可采用半导体领域已知的工艺(例如,薄膜沉积工艺、光刻工艺、刻蚀工艺、粒子注入工艺等)制造,此处不再赘述。第三晶圆6300A采用第三制程工艺,第三制程工艺对应的特征尺寸大于第一制程工艺对应的特征尺寸,第三制程工艺对应的特征尺寸和第二制程工艺对应的特征尺寸可以相同或者不同。当然,在其它实施例中,第三制程工艺对应的特征尺寸可以小于或等于第一制程工艺对应的特征尺寸。
第三晶圆6300A包括多个第三晶粒以及位于相邻的两个第三晶粒之间的第三切割道,在一具体实施例中,第一晶粒6100的尺寸、第二晶粒6200的尺寸和第三晶粒的尺寸相同,第一切割道的尺寸、第二切割道的尺寸和第三切割道的尺寸相同,并且将三个晶粒共同封装在一起。
仍参照图6c所示,将第三晶圆6300A的第一面与第一晶圆6100A对准并键合,使得桥接电路的第一端口与运算器耦接(图中未示出);将第三晶圆6300A的第二面和第二晶圆6200对准并键合,使得桥接电路的第二端口与缓存器耦接(图中未示出),如此,运算器与缓存器之间可通过桥接电路进行数据传输。需要指出的是,在将第三晶圆6300A的第一面与第一晶圆6100A键合后,可先去除第三晶圆6300A的衬底,直至显露桥接电路的第二端口,再将第二晶圆与第三晶圆键合。为了便于示意,图6c中未示出第三晶粒。
这里,可先将第三晶圆与第一晶圆键合后再与第二晶圆键合;或者,先将第三晶圆与第二晶圆键合后再与第一晶圆键合,本公开实施例对键合的先后顺序并无特殊限制。
在一些实施例中,上述提供第二晶圆,包括:形成缓存器;在缓存器上形成布线层;在布线层中形成桥接电路,桥接电路的第二端口通过第二接口协议与缓存器耦接;上述键合第一晶圆和第二晶圆,包括:倒置第二晶圆,使得布线层位于第一晶粒和缓存器之间;键合桥接电路和运算器,使得桥接电路的第一端口通过第一接口协议与运算器耦接;其中,第二接口协议和第一接口协议不同。
在形成缓存器后,形成覆盖缓存器的绝缘层,通过光刻、刻蚀和薄膜沉积等工艺在绝缘层中形成布线和桥接电路,桥接电路和缓存器之间通过互连触点和/或互连线耦接;在第一晶圆和第二晶圆制造完成后,将第一晶圆与第二晶圆对准并键合。这里,第一晶圆与第二晶圆的对准、键合可以参照前述图6b或图6c。为了简洁,这里不再赘述。
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。
- 数据缓存装置及控制方法、数据处理芯片、数据处理系统
- 数据处理系统、方法、人工智能芯片、电子设备和介质