基于人工神经网络的片上网络延时预测器
文献发布时间:2024-04-18 19:58:30
技术领域
本发明属于片上网络(Network on chip,NoC)领域,涉及一种基于人工神经网络的片上网络延时预测器。
背景技术
目前存在众多的基于多核互连的类脑计算平台仅通过扩展神经元数量实现更高的智能计算,在硬件映射的利用率上没有做深入探索。事实上,映射方式对硬件平台的能效有着至关重要的影响,随机映射中最好的与最差的相比能效相差17倍,为了在庞大且复杂度极大的硬件映射探索空间中搜寻最优映射,需要反复调用类脑计算平台或其对应的片上网络仿真器模拟真实计算与通信传输情况,得到运行总时间最短的映射。
然而,类脑计算平台一轮计算时间过长,即使是其对应的片上网络仿真器,根据实验,完整地将一个小型卷积神经网络(如LeNet)计算完成,需要运行5分钟的时间,这对穷举、启发式、迭代算法探索最优映射的过程是十分不利的,导致算法需要更加漫长的时间进行收敛。
发明内容
发明目的:本发明提出了一种基于人工神经网络的片上网络延时预测器,以解决现有技术存在的上述问题。
技术方案:一种基于人工神经网络的片上网络延时预测器,包括以下步骤:
步骤1:收集随机硬件映射和与其对应的网络特征值,将硬件映射和网络特征值组成数据集,数据集包括训练集和测试集;
步骤2:根据所述数据集设置片上网络延时预测模型的网络结构与训练参数;
所述预测模型包括一层输入层、若干全连接隐藏层、一层输出层;输入层的神经元个数为输入硬件映射特征值个数;输出层只有一个神经元,代表预测的片上网络所需仿真时间;每层全连接隐藏层后都有激活函数;
步骤3:通过优化器,使用K折交叉验证法训练片上网络延时预测模型,得到模型的最优超参数;
所述K折交叉验证法采用预定值折交叉验证,将可用数据划分为预定值个分区,实例化预定值个相同的模型,将每个模型在预定值减一个分区上训练,并在剩下的一个分区上进行评估,模型的验证分数为预定值个验证分数的平均值;
步骤4:使用最优超参数在所有训练数据上重新训练片上网络延时预测模型,得到最终的片上网络延时预测模型;
步骤5:评估最终的片上网络延时预测模型在测试集上的泛化能力,若符合要求,则保存模型,否则调整模型网络结构,重新进行训练;
步骤6:载入保存的片上网络延时预测模型,与穷举、启发式、迭代算法平台结合,得到最优的硬件映射方案。
根据本申请的一个方面,所述步骤1中的数据集的数据具体包括:片上网络的输入映射、总计算延时、分层计算延时、空域网络延时、总时域网络延时、片上网络总跳数、层间跳数、X与Y方向的时域网络延时、层间拥塞特征值、片上网络计算单元分配情况。
根据本申请的一个方面,所述片上网络的输入映射具体为:设定片上网络平台单个计算单元的计算能力为M个神经元,将卷积神经网络转化为类人工神经网络,以M个神经元为一组进行分组,将分组后的神经元组分配到不同的片上网络计算单元进行运算,得到片上网络计算单元序号,神经元组序号对应的片上网络计算单元序号组成的数组即为片上网络的输入映射。
根据本申请的一个方面,所述总计算延时为所有神经网络层的计算单元延时之和;分层计算延时为不同神经网络层计算任务分配到的计算单元延时之和,其中计算单元延时特征由输入神经元数和输出神经元数决定,估算公式如下:
T
其中[]为向下取整运算符,mod为取模运算符,n
根据本申请的一个方面,所述层间跳数为不同神经网络层网络跳数之和;片上网络总跳数为不同神经网络层层间跳数之和,其中网络跳数由计算单元间连接关系决定,具体为:
确定某一映射后,可以确定片上网络各计算单元之间的连接关系,路由方式选择XY路由,则从原节点到目的节点所经过的链路个数即为两个节点间的网络跳数;通过两个连接的计算单元序号可知该计算单元在片上网络二维网状架构中的行列信息,网络跳数计算公式如下:
hops
其中PE
根据本申请的一个方面,所述空域网络延时计算公式如下:
T
其中m为映射,h(m)为映射决定的总跳数,T
根据本申请的一个方面,所述总时域网络延时与层间拥塞特征值计算方式如下:
将所有计算单元之间连接的链路设为集合{L},其中横向的记为{L
congestion
其中{n}
Y方向上的时域网络延时的计算公式如下:
Congestion
总时域网络延时的计算公式如下:
Congestion
层间拥塞特征值为层间总超额数据量,总时域网络延时为层间拥塞特征值之和。
根据本申请的一个方面,所述片上网络为二维网状网络。
根据本申请的一个方面,还包括对所述数据集进行预处理,将网络特征值和硬件映射特征值进行目标编码与离差标准化。
根据本申请的一个方面,还包括在所述步骤2中的每层隐藏层前加入批量归一化层,用于加快模型收敛速度。
根据本申请的一个方面,所述激活函数采用线性修正函数增加网络非线性,优化器采用适应性矩估计算法训练,此时预测误差最低。
有益效果:第一,本发明提供一种基于人工神经网络的片上网络延时预测器,适用于随机输入映射预测系统运行完成时间。
第二,本发明的方法基于人工神经网络算法,相较于传统的多项式模型能更准确地捕捉输入特征与片上网络延时之间的非线性关系。
第三,本发明训练的预测模型保存权重后,在利用穷举、启发式、迭代算法探索最优映射时调用训练好的模型,可为算法提供高效、快速地片上网络仿真所需时间,辅助最优映射探索,无需调用片上网络仿真器,节省了计算成本与算法收敛所需运行时间,有良好的实际应用价值。
附图说明
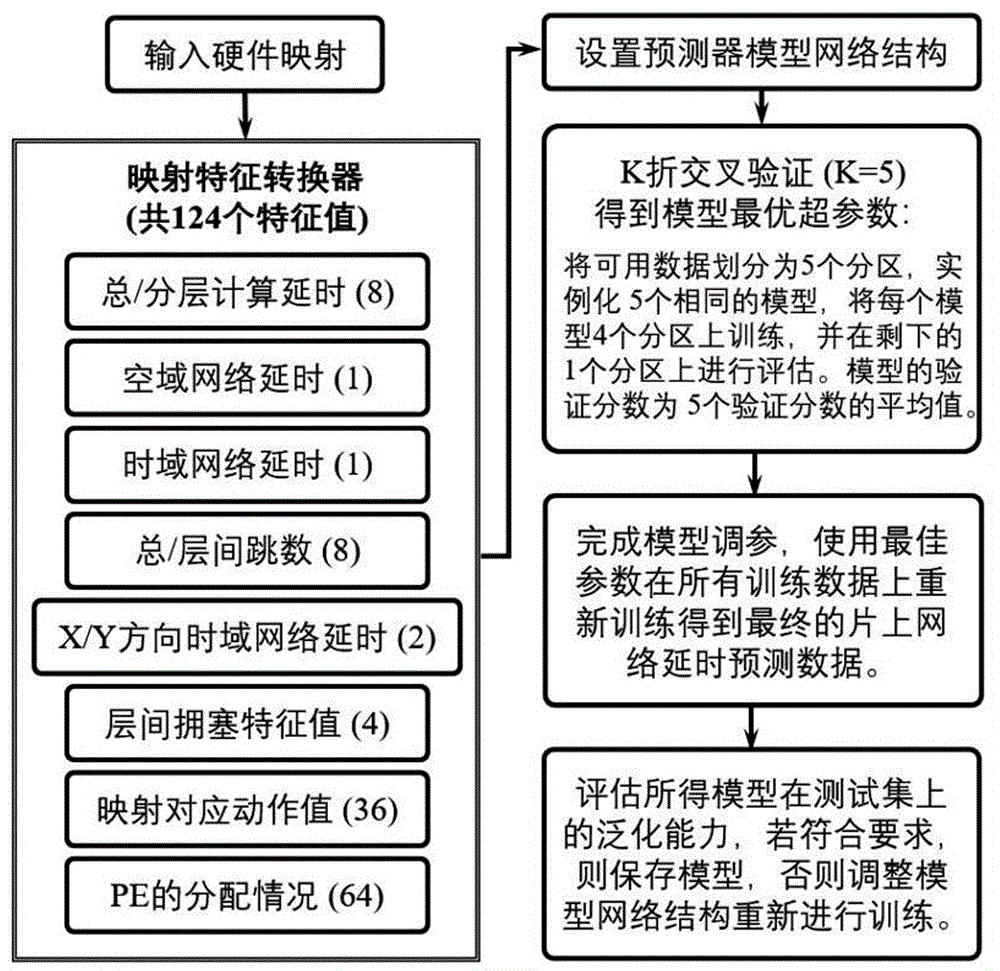
图1为本发明的训练流程图。
图2是本发明的人工神经网络模型结构图。
图3是本发明的验证集的损失值收敛情况图。
图4是本发明的部分测试集中预测值与目标值的散点图对比图。
图5是本发明的部分测试集中的预测值的误差图。
具体实施方式
下面结合附图和具体实施方式,对本发明进行详细的说明。
如图1所示的是基于人工神经网络的片上网络延时预测模型训练流程图,本实施例所述的片上网络为二维网状(Mesh)片上网络。首先需要收集随机硬件映射与其对应的网络特征值作为数据集,包括训练集和测试集。
总共收集26000个随机映射对应的片上网络延时,输入特征数据集的内容包括片上网络的输入映射、总计算延时、分层计算延时、空域网络延时、总时域网络延时、片上网络总跳数、层间跳数、X与Y方向的时域网络延时、层间拥塞特征值、片上网络计算单元(PE,Processing Element)分配情况。
其中片上网络的输入映射为神经元组序号对应的片上网络计算单元序号组成的数组。设定片上网络平台单个计算单元的计算能力为M个神经元,故将所需计算的卷积神经网络转化为类人工神经网络后,以M个神经元为一组进行分组,分组后的神经元组分配去不同的片上网络计算单元进行运算。
单个计算单元的计算延迟(以时钟周期为单位)特征由输入神经元数n
T
其中[]为向下取整运算符,标准的向下取整运算符无法正常显示,故用这个符号来表示,mod为取模运算符,n
网络跳数由计算单元间连接关系决定。确定某一映射后,片上网络各计算单元之间的连接关系即可确定,路由方式选择XY路由,则从原节点到目的节点所经过的链路个数即为两个节点间的网络跳数。层间跳数为不同神经网络层分配到的计算单元连接链路个数之和;片上网络总跳数为不同神经网络层层间跳数之和。设两个连接的计算单元序号分别为PE
hops
其中row(PE)和col(PE)分别代表当前PE在片上网络二维网格架构中的行序号和列序号。
空域网络延时计算方式如下:设映射为m,映射决定的总跳数为h(m),路由延迟为T
T
总时域网络延时与层间拥塞特征值计算方式如下:将所有计算单元之间连接的链路设为集合{L},其中横向的记为{L
congestion
其中{n}
Y方向上的时域网络延时的计算公式如下:
Congestion
层间拥塞特征值为层间总超额数据量,总时域网络延时为层间拥塞特征值之和,总时域网络延时的计算公式如下:
Congestion
至此,准备好了训练预测模型需要的数据集。接着,需要进行数据的预处理,本发明的数据预处理分为两步,目标编码与离差标准化。
步骤1:目标编码(Target Encoder),也称为均值编码,是特征编码的一种非常有效的方法,该方法是统计每个类别标签对应片上网络延迟值,每个类别标签都被该类别的片上网络平均延迟替代。
步骤2:离差标准化,也称Min-Max归一化,将数据缩放到[0, 1]之间。将不同特征转化成同一数量级以便于综合对比。同时,能提高梯度下降最优解时的速度并提高计算精度。将序列{
y
下面展示了使用目标编码与离差标准化与不使用的平均绝对误差延迟时钟周期值对比。对比时,采用批处理值为16。即使后面使用了批量化归一层对数据进行标准化,可以无需对输入数据进行归一化,但经实验发现,加上离差标准化还是能够降低一定误差,具体如下:
当无目标编码,有离差标准化时,平均绝对误差值为262.50;当有目标编码,且有离差标准化时,平均绝对误差值为254.89;当无目标编码,且无离差标准化时,平均绝对误差值为266.61;当有目标编码,无离差标准化时,平均绝对误差值为258.69。
数据预处理完毕后,设置神经网络结构。如图2所示,预测模型包括一层输入层、若干全连接隐藏层、一层输出层;输入层的神经元个数为输入硬件映射特征值个数;输出层的神经元个数为1,代表预测的片上网络所需仿真时间;每层全连接隐藏层后都有激活函数。
进一步的,每层隐藏层前加入批量归一化层,以加快模型收敛速度,避免深层网络的梯度消失或爆炸问题,并减少对参数初始化方法的依赖。
进一步的,每层全连接隐藏层后的激活函数采用线性修正函数(ReLU,RectifiedLinear Unit),使模型去线性化。且采用ReLU的神经元只需要进行加、乘和比较的操作,计算上更加的高效。线性修正函数公式如下:
ReLU(x) =max(0,x)=(x,x>0;0,x≤0),当x>0时,取x;当x≤0时,取0。
可见,ReLU函数为左饱和函数,且在
同时,在每层全连接层前,增加批量归一化层(BN,Batch Normalization),相当于每一层都进行一次数据预处理,从而加快模型收敛速度。逐层归一化不但可以提高优化效率,还可以作为一种隐形的正则化方法。在训练时,神经网络对一个样本的预测不仅和该样本自身相关,也和同一批次中的其他样本相关。由于在选取批次时具有随机性,因此使得神经网络不会过拟合到某个特定样本,从而提高网络的泛化能力。
经实验,BN层在批处理量过小(小于等于8)时无法发挥作用,在本发明中,批处理量为24的情况下,验证集的平均绝对误差最低,如下所示:
当批处理量为8时,平均绝对误差值为65049.15;当批处理量为16时,平均绝对误差值为254.88;当批处理量为20时,平均绝对误差值为249.73;当批处理量为24时,平均绝对误差值为248.69;当批处理量为32时,平均绝对误差值为255.25。
综上所述,模型网络结构中总共有神经元参数1558097个,可训练参数有1552449个,不可训练参数有5648个,如下所示:
当网络层类型为批归一化层1时,输出神经元数为124,参数量为496;当网络层类型为全连接层1时,输出神经元数为1000,参数量为125000;当网络层类型为批归一化层2时,输出神经元数为1000,参数量为4000;当网络层类型为全连接层2时,输出神经元数为1000,参数量为1001000;当网络层类型为批归一化层3时,输出神经元数为1000,参数量为4000;当网络层类型为全连接层3时,输出神经元数为300,参数量为300300;当网络层类型为批归一化层4时,输出神经元数为300,参数量为1200;当网络层类型为全连接层4时,输出神经元数为300,参数量为90300;当网络层类型为批归一化层5时,输出神经元数为300,参数量为1200;当网络层类型为全连接层5时,输出神经元数为100,参数量为30100;当网络层类型为批归一化层6时,输出神经元数为100,参数量为400;当网络层类型为全连接层6时,输出神经元数为1,参数量为101;总参数量为1558097,可训练参数量为1552449,不可训练参数量为5648。
其中,不可训练参数是由BN层的加入带来的,每个BN层的每个输入添加了四个参数:γ、β、μ和σ。后两个参数μ和σ是移动平均值,他们不受反向传播的影响,因此是不可训练参数。
模型设置完成后,开始进行人工神经网络的训练,训练时,采用适应性矩估计(Adaptive Moment Estimation Algorithm,Adam)优化器,它吸收了自适应学习率的梯度下降算法和动量梯度下降算法的优点,既能适应稀疏梯度,又能缓解梯度震荡的问题。Adam优化器的公式如下,第一条公式为历史梯度的一阶矩,可以看作梯度的均值;第二条公式为历史梯度二阶矩,可以看作未减去均值的方差,用于得到每个权重参数的学习率权重参数;第三条公式为Adam算法参数更新值:
m
v
variable= variable-(lr
其中,β
模型的损失函数采用均方差损失(MSE,Mean Squared Error)函数,为预测值与目标值之差的平方,设N为训练迭代次数,该函数运算公式如下:
MSE(y
其中,y
但为了更加直观地监控模型,本发明中所有误差均展现平均绝对误差(MAE,MeanAbsolute Error)函数,该函数运算公式如下:
MSE(y
其中,y
训练方法采用5折交叉验证,将可用数据划分为5个分区,实例化5个相同的模型,将每个模型在4个分区上训练,并在剩下的1个分区上进行评估。模型的验证分数为5个验证分数的平均值。K折验证将所有数据得到充分利用,有助于促进网络泛化,防止过拟合。
在5折验证中,每折验证的平均绝对延迟误差情况如下:
当交叉验证次数为1时,平均绝对误差为254.11;当交叉验证次数为2时,平均绝对误差为257.10;当交叉验证次数为3时,平均绝对误差为248.08;当交叉验证次数为4时,平均绝对误差为246.81;当交叉验证次数为5时,平均绝对误差为251.88。 取5折验证的平均分数作为模型最终的平均绝对误差值,故最终的误差值为251.60时钟周期。
完成片上网络延时预测模型调参后,使用最佳参数在所有训练数据上重新训练,此时令90%的数据为训练集,10%的数据为测试集,得到最终的片上网络延时预测模型。该神经网络模型的优化过程可以分为两个阶段,第一个阶段先通过前向传播算法计算得到预测值,井将预测值和真实值做对比得出两者之间的差距。然后在第二个阶段通过反向传播算法计算损失函数对每一个参数的梯度,再根据梯度和学习率使用梯度下降算法更新每一个参数。最终的预测模型的损失值收敛情况如图3所示。
如图4所示,展示了部分测试集中预测值与目标值的散点图对比。
如图5所示,展示了部分测试集中的预测值的误差。由图可知,预测值的误差均低于5%,模型的拟合度良好。
最后,载入保存的片上网络延时预测模型,与穷举、启发式、迭代算法平台结合,探索最优硬件映射。以上示意性地对本发明创造及其实施方式进行了描述,该描述没有限制性,在不背离本发明的精神或者基本特征的情况下,能够以其他的具体形式实现本发明。附图中所示的也只是本发明创造的实施方式之一,实际的结构并不局限于此,权利要求中的任何附图标记不应限制所涉及的权利要求。所以,如果本领域的普通技术人员受其启示,在不脱离本创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本专利的保护范围。此外,“包括”一词不排除其他元件或步骤,在元件前的“一个”一词不排除包括“多个”该元件。产品权利要求中陈述的多个元件也可以由一个元件通过软件或者硬件来实现。第一,第二等词语用来表示名称,而并不表示任何特定的顺序。
以上详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种等同变换,这些等同变换均属于本发明的保护范围。
- 基于人工神经网络的自动化数据切片
- 片上系统、电子设备和基于片上系统的功率管理方法