一种可语音识别的电梯视频通话系统
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及语音识别技术领域,尤其涉及一种可语音识别的电梯视频通话系统。
背景技术
传统电梯中的报警通常依赖于乘客按下报警键才能被触发。一旦乘客按下报警键,电梯系统会警示相关人员并采取相应措施来应对紧急情况。这种传统的报警系统在正常情况下能够满足乘客的安全需求。
然而,并非所有情况下乘客都能按下报警键,例如在疼痛难忍、摔倒或被歹徒控制等暂时丧失行动力的情况下。此外,还有些乘客可能由于年龄或身体缺陷等原因无法直接触碰报警键,或者因为报警键故障无法正常触发报警求助功能。在这种情况下,采用语音识别技术来识别乘客的求助行为变得非常必要。
可是,电梯中持续进行语音监测虽然能够识别乘客的求助行为,对计算资源的占用过大,同时也会涉及个人隐私问题。因此,为了解决这一问题,人们需要一种能够在乘客无法通过报警键报警的条件下,仅在乘客需要的时刻主动进行语音识别的电梯通话系统。
发明内容
有鉴于此,有必要提供一种可语音识别的电梯视频通话系统,用以解决如何在乘客无法通过报警键报警的条件下,仅在乘客需要的时刻主动进行语音识别的问题。
本发明提供了一种可语音识别的电梯视频通话系统,包括:
图像获取模块,用于获取电梯轿厢内的监控视频,并得到图像帧序列;
网络建立模块,用于根据所述图像帧序列中的第一帧图像,建立激活函数,并根据所述激活函数建立3D卷积神经网络;
动作识别模块,用于根据所述图像帧序列,基于所述3D卷积神经网络识别乘客的求助动作;
语音识别模块,用于根据所述求助动作,开始获取并识别轿厢内的语音数据,并根据所述语音数据,向乘客发出相应的反馈提示。
进一步的,所述3D卷积神经网络包括依次相连的预设输入层、激活层、预设隐藏层和预设全连接层,所述预设隐藏层包括多个预设卷积层和多个预设池化层;所述激活层的输入为所述预设输入层输出的特征图,所述激活层的输出为目标提取特征图,所述目标提取特征图用于表征所述图像帧序列的第一帧图像和所述预设输入层输出的特征图的差异,所述目标提取特征图中的每个像素值根据所述激活函数得到。
进一步的,所述根据所述图像帧序列中的第一帧图像,建立激活函数,并根据所述激活函数建立3D卷积神经网络,包括:
获取电梯轿厢内无人时的背景图片;
根据所述背景图片和所述图像帧序列中的第一帧图像,建立所述激活层的激活函数;
根据所述激活函数,建立所述激活层;
获取已经训练好的所述预设输入层、所述预设隐藏层和所述预设全连接层;
根据所述激活层、所述预设输入层、所述预设隐藏层和所述预设全连接层,建立所述3D卷积神经网络。
进一步的,所述预设输入层的输出为所述图像帧序列在三个颜色通道下的灰度特征图序列,每一个所述灰度特征图为所述预设输入层输出的特征图;所述根据所述背景图片和所述图像帧序列中的第一帧图像,建立所述激活层的激活函数,包括:
根据所述背景图片,得到所述背景图片在三个颜色通道下的背景灰度图;
根据所述图像帧序列中的第一帧图像,得到所述图像帧序列中的第一帧图像在三个颜色通道的第一帧灰度图;
根据所述背景灰度图和所述第一帧灰度图中的每个像素的灰度值,建立所述激活函数。
进一步的,所述激活函数为:
k∈{R,G,B}
其中,x
进一步的,所述获取电梯轿厢内的监控视频,并得到图像帧序列,包括:
获取所述监控视频,并从所述监控视频中截取预设时长的视频片段,得到初始图像帧序列;
选取所述初始图像帧序列中,位于奇数位置的图像帧,得到所述图像帧序列。
进一步的,所述根据所述求助动作,开始获取并识别轿厢内的语音数据,并根据所述语音数据,向乘客发出相应的反馈提示,包括:
根据所述求助动作,向电梯轿厢内的乘客发出语音提示,并开始获取语音数据;
基于预设语音识别模型识别所述语音数据,得到所述语音数据对应的求助内容;
根据所述语音数据对应的求助内容,向乘客发出相应的反馈提示。
进一步的,所述预设语音识别模型为隐马尔可夫模型;所述基于预设语音识别模型识别所述语音数据,得到语音数据对应的求助内容,包括:
从所述语音数据中提取出声学特征;
根据所述预设语音识别模型解码所述声学特征,得到隐藏状态标签序列;
将所述隐藏状态标签序列中的每个隐藏状态标签与多个预设状态标签进行匹配,得到所述语音数据对应的求助内容;
其中,每个所述预设状态标签分别用于表征一种预设求助动作。
进一步的,将所述隐藏状态标签序列中的每个隐藏状态标签与多个预设状态标签进行匹配,得到所述语音数据对应的求助内容,包括:
匹配所述隐藏状态标签序列中的每个隐藏状态标签与每个预设求助动作对应的预设状态标签,得到匹配成功的预设求助动作的数量;
根据所述匹配成功的预设求助动作的数量,得到所述隐藏状态标签序列与每个预设求助动作的对应概率;
选择对应概率最高的预设求助动作作为所述语音数据对应的求助内容。
本发明提供了一种可语音识别的电梯视频通话系统,其先通过图像获取模块获取电梯轿厢内的监控视频,并得到图像帧序列,然后通过网络建立模块根据所述图像帧序列中的第一帧图像,建立激活函数,并根据所述激活函数建立3D卷积神经网络,再通过动作识别模块根据所述图像帧序列,基于所述3D卷积神经网络识别乘客的求助动作,最后通过语音识别模块根据所述求助动作,开始获取并识别轿厢内的语音数据,并根据所述语音数据,向乘客发出相应的反馈提示。相比于现有技术,本发明通过根据第一帧图像自定义激活函数的方式,完成对电梯内乘客求助动作的快速识别,并根据识别的动作决定是否开启语音监控,达到了仅在需要的时刻开启语音监测功能的目的,解决了侵犯个人隐私的问题。同时,视频动作识别配合语音识别两个功能模块,又共同实现了乘客在无法触碰到报警键的情况下,如何进行报警求助的问题,实现了更全面和灵活的紧急求助方式,提高乘客的安全和保障水平。
附图说明
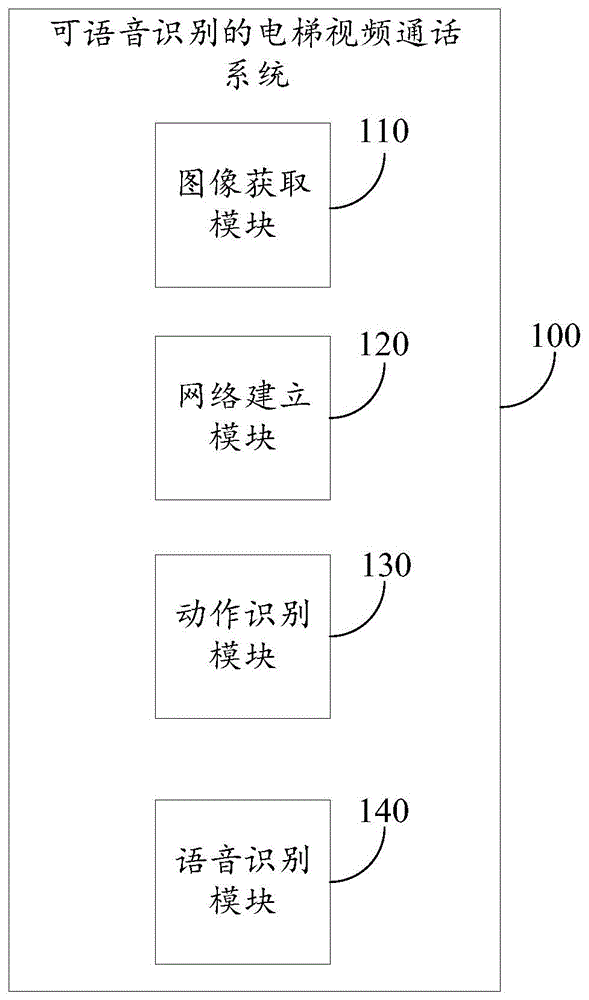
图1为本发明提供的可语音识别的电梯视频通话系统一实施例的系统架构图;
图2为本发明提供的可语音识别的电梯视频通话系统一实施例的执行流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
结合图1所示,本发明的一个具体实施例,公开了一种可语音识别的电梯视频通话系统100,包括:
图像获取模块110,用于获取电梯轿厢内的监控视频,并得到图像帧序列;
网络建立模块120,用于根据所述图像帧序列中的第一帧图像,建立激活函数,并根据所述激活函数建立3D卷积神经网络;
动作识别模块130,用于根据所述图像帧序列,基于所述3D卷积神经网络识别乘客的求助动作;
语音识别模块140,用于根据所述求助动作,开始获取并识别轿厢内的语音数据,并根据所述语音数据,向乘客发出相应的反馈提示。
相比于现有技术,本发明通过根据第一帧图像自定义激活函数的方式,完成对电梯内乘客求助动作的快速识别,并根据识别的动作决定是否开启语音监控,达到了仅在需要的时刻开启语音监测功能的目的,解决了侵犯个人隐私的问题。同时,视频动作识别配合语音识别两个功能模块,又共同实现了乘客在无法触碰到报警键的情况下,如何进行报警求助的问题,实现了更全面和灵活的紧急求助方式,提高乘客的安全和保障水平。
具体地,在一个优选的实施例中,上述图像获取模块110中,获取电梯轿厢内的监控视频,并得到图像帧序列,具体包括:
获取所述监控视频,并从所述监控视频中截取预设时长的视频片段,得到初始图像帧序列;
选取所述初始图像帧序列中,位于奇数位置的图像帧,得到所述图像帧序列。
其中截取预设时长的视频片段的时机可以根据实际情况灵活设定,例如在随机时刻截取片段,将该片段中的所有帧图像共同作为初始图像序列。同时,本实施例还进一步对初始图像帧序列进行了筛选,即丢弃了每个相邻的两帧图像中的一帧,使图像帧序列既能够保留乘客的动作信息,又有效地缩减了其体积,减少了后续的数据处理量,提高处理速度。
进一步的,在一个优选的实施例中,所述3D卷积神经网络包括依次相连的预设输入层、激活层、预设隐藏层和预设全连接层,所述预设隐藏层包括多个预设卷积层和多个预设池化层;所述激活层的输入为所述预设输入层输出的特征图,所述激活层的输出为目标提取特征图,所述目标提取特征图用于表征所述图像帧序列的第一帧图像和所述预设输入层输出的特征图的差异,所述目标提取特征图中的每个像素值根据所述激活函数得到。
3D卷积神经网络(3D Convolutional Neural Network)是一种深度学习模型,特别设计用于处理三维数据的神经网络结构。与传统的二维卷积神经网络不同,3D卷积神经网络通过考虑额外的时间维度,可以处理视频、时间序列或体积数据等具有时间和空间信息的三维数据。
本实施例中的图像帧序列包括了图像的宽度、高度,以及时间(即图像帧的序列顺序)三个维度,因此特别适合通过3D卷积神经网络处理。可以理解的是,本实施例中上述预设输入层、预设隐藏层和预设全连接层的具体结构及具体原理均为本领域技术人员能够理解的现有技术,因此本文不作过多说明。
激活层能够以图像帧序列中的第一帧图像为基准,对每个特征图进行去噪处理,剔除变化较小的像素,即剔除包含动作信息较少的像素,使得神经网络能够针对包含动作信息的像素进行识别处理,提高识别速度。
进一步的,在一个优选的实施例中,所述网络建立模块120中,根据所述图像帧序列中的第一帧图像,建立激活函数,并根据所述激活函数建立3D卷积神经网络,具体包括:
获取电梯轿厢内无人时的背景图片;
根据所述背景图片和所述图像帧序列中的第一帧图像,建立所述激活层的激活函数;
根据所述激活函数,建立所述激活层;
获取已经训练好的所述预设输入层、所述预设隐藏层和所述预设全连接层;
根据所述激活层、所述预设输入层、所述预设隐藏层和所述预设全连接层,建立所述3D卷积神经网络。
以上过程在第一帧图像的基础上,进一步结合背景图片建立激活层,使得激活层能够进一步剔除电梯中的背景信息,进一步提高了后续的处理精确性和处理速度。
此外,本实施例中的预设输入层、预设隐藏层和预设全连接层并非在本实施例中的系统中进行训练,而是在其他条件下预先训练好并直接搭载在本系统中。本实施例对于现有的3D卷积神经网络的主要改进在于增加了一个激活层,该激活曾在系统的本地设置,然后跟预设输入层、预设隐藏层和预设全连接层组合成一个完整的3D卷积神经网络,最大程度地减少了数据的分析时间,以提高数据实时处理能力,使得求助动作能够以最快的速度被识别。
具体地,在一个优选的实施例中,所述预设输入层的输出为所述图像帧序列在三个颜色通道下的灰度特征图序列,每一个所述灰度特征图为所述预设输入层输出的特征图。上述过程中,所述根据所述背景图片和所述图像帧序列中的第一帧图像,建立所述激活层的激活函数,具体包括:
根据所述背景图片,得到所述背景图片在三个颜色通道下的背景灰度图;
根据所述图像帧序列中的第一帧图像,得到所述图像帧序列中的第一帧图像在三个颜色通道的第一帧灰度图;
根据所述背景灰度图和所述第一帧灰度图中的每个像素的灰度值,建立所述激活函数。
具体地,在一个优选的实施例中,建立的激活函数为:
k∈{R,G,B}
其中,x
上述公式通过直接比较每个颜色通道中的灰度特征图、第一帧灰度图和背景灰度图的灰度值,进行差异的甄别,即将灰度特征图与第一帧灰度图和背景灰度图的灰度值均不一致的像素保留,而在三种图片中灰度值均一致的像素视为不包含动作信息的像素,将其置0以实现包含动作信息的像素的筛选。可以理解的是,实际中也可以根据具体情况,灵活地采用其他运算方式建立激活函数。
进一步的,在一个优选的实施例中,语音识别模块140中,所述根据所述求助动作,开始获取并识别轿厢内的语音数据,并根据所述语音数据,向乘客发出相应的反馈提示,具体包括:
根据所述求助动作,向电梯轿厢内的乘客发出语音提示,并开始获取语音数据;
基于预设语音识别模型识别所述语音数据,得到所述语音数据对应的求助内容;
根据所述语音数据对应的求助内容,向乘客发出相应的反馈提示。
具体地,在一个优选的实施例中,所述预设语音识别模型为隐马尔可夫模型,上述步骤:基于预设语音识别模型识别所述语音数据,得到语音数据对应的求助内容,具体包括:
从所述语音数据中提取出声学特征;
根据所述预设语音识别模型解码所述声学特征,得到隐藏状态标签序列;
将所述隐藏状态标签序列中的每个隐藏状态标签与多个预设状态标签进行匹配,得到所述语音数据对应的求助内容;
其中,每个所述预设状态标签分别用于表征一种预设求助动作。
隐马尔可夫模型(Hidden Markov Model,HMM)是一种常用的统计模型,用于描述具有潜在状态序列的时序数据。它是一种具有状态的随机过程,其中观测数据是通过这些状态生成的。
HMM由两个关键组成部分组成:隐藏状态和观测状态。隐藏状态是无法直接观测到的状态,代表系统内部的某种状态。观测状态是可以直接观测到的状态,代表我们能够观察到的数据。HMM的基本原理是,隐藏状态形成了一个概率转移矩阵,定义了状态之间的转移概率。而每个隐藏状态生成相应的观测状态的概率分布。这些概率分布可以是连续的(如高斯分布)或离散的(如多项式分布)。HMM的关键假设是马尔可夫性质,即当前时刻的隐藏状态仅依赖于前一个时刻的隐藏状态。这一假设使得HMM具有良好的推理和学习性质,并可用于对观测序列进行建模和预测。
隐马尔可夫模型常用于序列数据的建模和分析,如语音识别、手写识别、自然语言处理等。在语音识别中,隐藏状态通常对应于特定的语音单位,如音素或词语;而观测状态对应于语音信号的声学特征。
可以理解的是,实际中也可以采用其他的现有的语音识别模型作为预设语音识别模型。
上述过程中,隐藏状态序列是在语音识别任务中,通过解码算法得到的一系列隐藏状态的标签序列,用于表示输入语音的演变过程和对应的语音单位。它是由一系列隐藏状态的标签组成的序列。每个隐藏状态都对应着一个特定的标签,代表了语音信号在某个时间点上所对应的语音单位(如音素、单词、音节等)。
隐藏状态序列的生成基于语音信号的解码过程,通过在HMM模型中根据观测概率和状态转移概率进行推断。在解码过程中,根据音频信号的特征提取以及HMM模型的参数,利用Viterbi算法等解码算法,找到最可能的隐藏状态序列,从而实现对输入语音的建模和识别。
隐藏状态序列是语音信号在时间上的离散表示,在一段语音中每个时间点都对应着一个隐藏状态标签。通过获取隐藏状态序列,根据标签的顺序和转换关系,我们可以了解语音信号在时间上的变化和语音单位的组成,进而进行语音识别、语音理解和语音合成等任务。
进一步的,在一个优选的实施例中,所述将所述隐藏状态标签序列中的每个隐藏状态标签与多个预设状态标签进行匹配,得到所述语音数据对应的求助内容,具体包括:
匹配所述隐藏状态标签序列中的每个隐藏状态标签与每个预设求助动作对应的预设状态标签,得到匹配成功的预设求助动作的数量;
根据所述匹配成功的预设求助动作的数量,得到所述隐藏状态标签序列与每个预设求助动作的对应概率;
选择对应概率最高的预设求助动作作为所述语音数据对应的求助内容。
本发明还提供一更加详细的实施例,用以清楚地说明上述匹配隐藏状态标签得到对应的求助内容的过程:
事先定义几个常见的预设状态标签,比如:"哭泣"、"呼喊求助"、"报警"、"求医"等。上述每个状态标签可以通过字符串的形式表示。
现在解码得到的一个隐藏状态序列:[S1,S2,S3,S4,S5],其中每个隐藏状态也均通过字符串的形式表示,也分别对应着一个标签。可将解码得到的隐藏状态序列中的每个隐藏状态的标签与事先定义的预设状态标签进行匹配。匹配可以使用简单的字符串比对或计算标签之间的相似度。
例如,一个匹配结果如下:
-S1对应"报警"
-S2对应"哭泣"
-S3对应"呼喊求助"
-S4对应"求医"
-S5对应"求医"
通过统计上述每种预设状态标签的数量,便可以得到隐藏状态序列与“求医”这种预设状态标签的对应概率最高,那么便可以认为语音数据对应的求助内容为"求医"。
得到求助内容后,便可以向乘客发出相应的反馈提示,例如动作指示,安抚等,其可以根据实际需要灵活设定,本文中不做过多说明。
本发明提供了一种可语音识别的电梯视频通话系统,其先通过图像获取模块获取电梯轿厢内的监控视频,并得到图像帧序列,然后通过网络建立模块根据所述图像帧序列中的第一帧图像,建立激活函数,并根据所述激活函数建立3D卷积神经网络,再通过动作识别模块根据所述图像帧序列,基于所述3D卷积神经网络识别乘客的求助动作,最后通过语音识别模块根据所述求助动作,开始获取并识别轿厢内的语音数据,并根据所述语音数据,向乘客发出相应的反馈提示。相比于现有技术,本发明通过根据第一帧图像自定义激活函数的方式,完成对电梯内乘客求助动作的快速识别,并根据识别的动作决定是否开启语音监控,达到了仅在需要的时刻开启语音监测功能的目的,解决了侵犯个人隐私的问题。同时,视频动作识别配合语音识别两个功能模块,又共同实现了乘客在无法触碰到报警键的情况下,如何进行报警求助的问题,实现了更全面和灵活的紧急求助方式,提高乘客的安全和保障水平。
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 一种电梯关门异常的检测系统、检测方法和电梯
- 一种电梯振动信号预处理方法及电梯网关系统
- 一种正态速度曲线电梯门控制的电梯系统
- 一种监测电梯困人故障的应急救援视频通话系统及方法
- 一种支持多方视频通话的电梯安全管理系统及其方法