一种基于半监督学习的全切片病理图像分类方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明属于图像处理与医学技术领域,特别涉及一种基于半监督学习的全切片病理图像分类方法。
背景技术
组织病理图像包含丰富的癌症组织形态特征和表型信息,是癌症临床诊断的金标准,为患者的术前诊断、术后预后、靶向治疗提供了重要参考依据。病理学家通过人眼观察病理切片来评估癌症类型及其分期,这种人工分析需要丰富的临床经验,且评估具有一定的主观性。计算机辅助病理分析技术有望减少病理医师的工作量,提高诊断的效率和可靠性。全切片(Whole Slide Image, WSI),它以金字塔形式存储了不同放大倍率的图像,为病理图像自动分析任务奠定了基础。近年来,深度学习因具有强大的特征提取能力,在病理图像分析任务中取得了诸多成果,如癌症分类、病灶分割、肿瘤检测、癌症转移预测等等。大多数深度学习模型都需要大量的标签信息,然而病理图像具有很高的类内变异性和类间相似性。WSI的标注费时费力,即使有专业知识的病理医生标注一张全切片图像也需要几个小时以上,因此大量的标签需求和标注复杂度限制了基于深度学习的方法在病理图像分析中的应用。
例如现有技术使用一种局部增强技术来提高病理图像的多样性,同时提出了两个双向一致性损失,分别对弱增强和强增强两条支路的中间特征和预测结果进行一致性约束,以提高分类网络的特征表示的稳健性以及预测的准确性。再例如现有技术一个半监督像素对比学习框架,实现了组织病理图像分割,该框架通过引入一种相互双重一致性方法,旨在从未标记数据中提取有效的语义信息,同时提出了一种基于不确定性策略过滤伪标签中的错误信息,有助于提高模型学习的稳健性。以上工作主要聚焦于特定分辨率下的病理图像分析,这与临床实践并不完全相符。在临床实践中,病理专家通常需要在不同的显微镜倍率下观察组织样本,结合癌症病变的局部特征和全局特性判断癌症亚型。
由于病理图像呈现出高度的异质性,可能包含多种类型的细胞、组织以及病变。同时,受取样、染色与成像过程影响,病理图像存在各种噪声与干扰使得分析难度加大。
发明内容
为了解决上述问题,本发明提出了一种基于半监督学习的全切片病理图像分类方法,为达此目的,本发明采用以下技术方案:
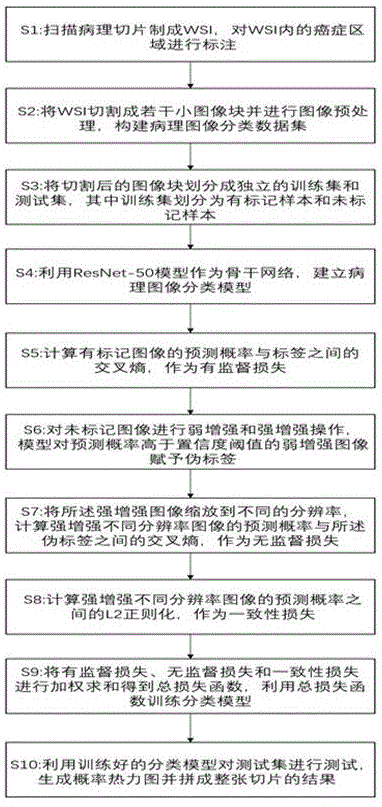
一种基于半监督学习的全切片病理图像分类方法,所述图像分类方法包括如下步骤:
S1:通过数字扫描仪将病理切片扫描成WSI,在ASAP软件内对WSI内的癌症区域进行标注;
S2:在10x倍率下对WSI进行切图,将WSI切成若干256x256像素大小的图像块,对图像块进行预处理,构建病理图像分类数据集;
S3:将切割后的图像块划分成独立的训练集和测试集,其中训练集划分为有标记样本和未标记样本;
S4:利用ResNet-50模型作为骨干网络,建立病理图像分类模型
S5:将有标记集中的图像
S6:将未标记集中的图像
S7:将未标记集中的图像
S8:计算强增强的不同分辨率图像的预测概率之间的
S9:将有监督损失、无监督损失以及
S10:利用训练好的分类模型
进一步的,所述S2中,对图像进行预处理的步骤包括:
S21:舍去白色背景区域超过50%的图像块;
S22:保留癌症区域超过75%以上的图像块并标记为癌症;
S23:保留癌症区域为0%的图像块并标记为非癌症。
进一步的,所述S3中,依据不同的WSI切片名将切割后的图像块划分成训练集和测试集,以保证训练集和测试集之间的独立性;
进一步的,将训练集划分为30%有标记数据集
进一步的,所述S4中,所述ResNet-50模型包括49个卷积层以及1个全连接层,将最后一层全连接层的样本类别数目设置为病理分类数据集样本类别数目2。
进一步的,所述S5中,计算有标记图像的预测概率与其标签之间的交叉熵,作为有监督的损失函数
;
其中,
进一步的,所述S6中,针对肺鳞癌类和非癌症类,所述置信度阈值
S61:设置原始置信度阈值
S62:计算每个类别中预测概率超过原始置信度阈值
;
其中
S63:根据所有类别的学习状态,将
;
其中
S64:利用式
;
进一步的,所述S7中,无监督损失函数计算步骤如下:
S71:将未标记图像
S72:将强增强的不同分辨率图像输入到分类模型
;
其中
进一步的,所述S8中,计算强增强的不同分辨率图像的预测概率之间的
;
其中
进一步的,所述S9中,将有监督损失、无监督损失以及
;
其中
进一步的,所述S10中,利用训练好的分类模型对测试集进行测试,生成每个小图的概率热力图,其中癌症类别颜色为红色,非癌症类别颜色为蓝色,颜色的深浅表示属于该类别的概率大小,将小图的概率热力图拼成整张切片的结果,用于切片分类效果可视化。
本发明的有益效果:本发明提出了一种基于半监督学习的全切片病理图像分类方法,能够减少深度学习模型对大量标签的依赖性,减轻病理医师的工作负担,该方法约束模型对不同分辨率病理图像预测的一致性,充分利用不同分辨率病理图像的潜在特征,提高模型的泛化能力。本发明提出的方法能够减少深度学习模型对大量标签的依赖性,减轻病理医师的工作负担,辅助病理医师进行诊断。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例中所需要使用的附图作简单地介绍。显而易见地,下面所描述的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请的方法流程图。
图2为Mean Teacher、MixMatch、FixMatch、FlexMatch、FreeMatch以及本发明提出的MCSSL在1
图3为Mean Teacher、MixMatch、FixMatch、FlexMatch、FreeMatch以及本发明提出的MCSSL在ACDC-LungHP数据集上的分类可视化图。
具体实施方式
下面结合附图并通过具体实施方式来进一步说明本发明的技术方案。
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
实施例一:如图1所示,本实施例提供一种基于半监督学习的全切片病理图像分类方法,所述图像分类方法包括如下步骤:
S1:通过数字扫描仪将病理切片扫描成WSI,在ASAP软件内对WSI内的癌症区域进行标注;
S2:在10x倍率下对WSI进行切图,将WSI切成若干256x256像素大小的图像块,对图像块进行预处理,构建病理图像分类数据集;
S3:将切割后的图像块划分成独立的训练集和测试集,其中训练集划分为有标记样本和未标记样本;
S4:利用ResNet-50模型作为骨干网络,建立病理图像分类模型
S5:将有标记集中的图像
S6:将未标记集中的图像
S7:将未标记集中的图像
S8:计算强增强的不同分辨率图像的预测概率之间的
S9:将有监督损失、无监督损失以及
S10:利用训练好的分类模型
进一步的,所述S2中,对图像进行预处理的步骤包括:
S21:舍去白色背景区域超过50%的图像块;
S22:保留癌症区域超过75%以上的图像块并标记为癌症;
S23:保留癌症区域为0%的图像块并标记为非癌症。
进一步的,所述S3中,依据不同的WSI切片名将切割后的图像块划分成训练集和测试集,以保证训练集和测试集之间的独立性;
进一步的,将训练集划分为30%有标记数据集
进一步的,所述S4中,所述ResNet-50模型包括49个卷积层以及1个全连接层,将最后一层全连接层的样本类别数目设置为病理分类数据集样本类别数目2。
进一步的,所述S5中,计算有标记图像的预测概率与其标签之间的交叉熵,作为有监督的损失函数
;
其中,
进一步的,所述S6中,针对肺鳞癌类和非癌症类,所述置信度阈值
S61:设置原始置信度阈值
S62:计算每个类别中预测概率超过原始置信度阈值
;
其中
S63:根据所有类别的学习状态,将
;
其中
S64:利用式
;
进一步的,所述S7中,无监督损失函数计算步骤如下:
S71:将未标记图像
S72:将强增强的不同分辨率图像输入到分类模型
;
其中
进一步的,所述S8中,计算强增强的不同分辨率图像的预测概率之间的
;
其中
进一步的,所述S9中,将有监督损失、无监督损失以及
;
其中
进一步的,所述S10中,利用训练好的分类模型对测试集进行测试,生成每个小图的概率热力图,其中癌症类别颜色为红色,非癌症类别颜色为蓝色,颜色的深浅表示属于该类别的概率大小,将小图的概率热力图拼成整张切片的结果,用于切片分类效果可视化。
实施例二:本实施例应当理解为至少包含前述实施例的全部特征,并在其基础上进一步实施。
实验数据
(1)1
该数据集包含16张HE染色的非小细胞肺癌切片,包括肺鳞癌和正常组织两种类型。所有切片都由40x的数字切片扫描仪扫描制成,切片格式为MRXS,每张切片尺寸大约18000×37000像素。在ASAP软件上对癌症区域进行标注,生成XML标签文件。所有WSIs被随机分成两组,12张WSI用于训练和4张WSI用于测试并对数据进行预处理。首先将每张WSI在10x放大倍率下以50%的重叠率切成256x256像素大小的图像块,剔除模糊、肮脏、过度染色以及白色背景区域超过50%的图像块;癌症区域超过75%以上的图像块标记为鳞癌,所有区域都为正常组织的图像块标记为正常。最终训练集图像块数量为135034,测试集图像块数量为46558。
(2)ACDC-LungHP数据集
该数据集由ACDC@LungHP Challenge 2019发布,包含了来自不同病人的200张带标记切片。切片由数字切片扫描仪(3DHISTECH Pannoramic 250)进行 H&E 染色扫描,放大倍率为 20 x。切片格式为TIFF,标签格式为XML。本文从中选取了24张染色质量好的活检样本作为训练集和测试集,18张WSI用于训练,6张WSI用于测试。每张WSI切成256x256像素大小的图像块,采用上述数据预处理方式,最终训练集图像块数量为135595,测试集图像块数量为48436。
实验配置及参数设置
本实施例采用的网络模型为ResNet-50,包括49个卷积层以及1个全连接层。训练时batchsize为16,Epoch为100,使用30%的标签数据,每个mini batch中未标记样本的数量与有标记样本的数量比例是3:1。模型优化器采用SGD,动量为0.9。初始学习率为0.03,使用余弦学习率衰减。测试阶段采用了EMA,动量为0.999。原始置信度阈值
实验结果及分析
为了证明本文所提MCSSL方法的有效性,本发明对比了Mean Teacher方法、MixMatch方法、FixMatch方法、FlexMatch方法和FreeMatch方法。表1、表2分别给出了不同方法在1
从表 1 的第二行可以看出,与其他 SSL 方法相比,本发明提出的 MCSSL 方法取得了最佳性能。虽然 FlexMatch 是这些半监督学习方法中最有力的竞争者,但与FlexMacth 相比, MCSSL 在各项评价指标上都胜过FlexMacth。F1-score综合考虑了Precision和Recall的性能,能够体现模型的稳健性,MSSL在F1-score上超出各方法3.39%-9.11%。与其他 SSL 方法不同的是, MCSSL 方法可以通过类似病理学家的诊断方法,从不同分辨率的图像中充分提取更多的潜在特征和互补信息。表2展示了不同方法在ACDC-LungHP数据集上的性能。本发明所提出的MSSL在Accuracy,Precision,Recall,F1-score上取得最好的性能,显示了提出多分辨率一致性方法的优越性。相比于Accuracy和Precision,MSSL在Recall取得了更多改进,分别超出其他方法4.58%,2.35%,4.96%,1.87%,3.45%,说明MSSL在判断样本是否为癌症时更少出现漏判的情况。通常在临床实践中,癌症漏判所带来的风险比将正常误判为癌症的风险要大,漏判可能会导致患者错过黄金治疗时间。实验结果表明,本发明所提出的方法具有卓越的性能以及在临床应用的巨大潜力。
表1 不同方法在1
表2 各类方法在ACDC-LungHP肺癌数据集上的性能
为了更直观地显示本发明所提出方法的优越性,图2、图3给出了不同方法在1
需要声明的是,上述具体实施方式仅仅为本发明的较佳实施例及所运用技术原理。本领域技术人员应该明白,还可以对本发明做各种修改、等同替换、变化等等。但是,这些变换只要未背离本发明的精神,都应在本发明的保护范围之内。另外,本申请说明书和权利要求书所使用的一些术语并不是限制,仅仅是为了便于描述。