基于YOLO的网页视频组件非侵入式检测方法
文献发布时间:2024-04-18 20:01:23
技术领域:
本发明涉及一种基于YOLO的网页视频组件非侵入式检测方法,属于计算机技术软件领域。
背景技术:
随着互联网在人们生活中的普及,残疾人应该能够像普通人一样享受互联网带来的便利。对于视障人士而言,他们只能依靠无障碍应用来获取网页中控件的内容和使用功能,因此网页中控件的检测变得至关重要。通过进行检测,可以及时向网页开发者反馈,提醒他们修改存在无障碍问题的控件,从而提升视障人士的使用体验。
目前,视频控件的检测主要分为侵入式和非侵入式两种方法。侵入式方法通过获取网页源码能够准确识别控件位置,然而这种方法面临着难以获取网页源码和法律风险的问题。而传统的非侵入式方法采用模板匹配,适用于数据量较小的情况,但在视频组件具有多样化的“播放”图标时,可能会漏检视频组件。这促使我们考虑采用深度学习算法进行算法升级。然而,由于深度学习模型对数据量的要求较高,也面临着真实数据数量难以满足深度学习模型训练需求的困境
发明内容:
针对以上问题和难点,本发明提出了一种基于YOLO的网页视频组件非侵入式检测方法。
与利用源码进行检测的侵入式方法相比,本发明是非侵入式的,不需要获得软件的源代码,可用于黑盒测试场景,有更广阔的应用范围与普适性。同时采用深度学习方法,通过人工合成数据集的方式解决深度学习方法数据量不足的困境,为视频组件检测提供了高效高可靠的解决方案。
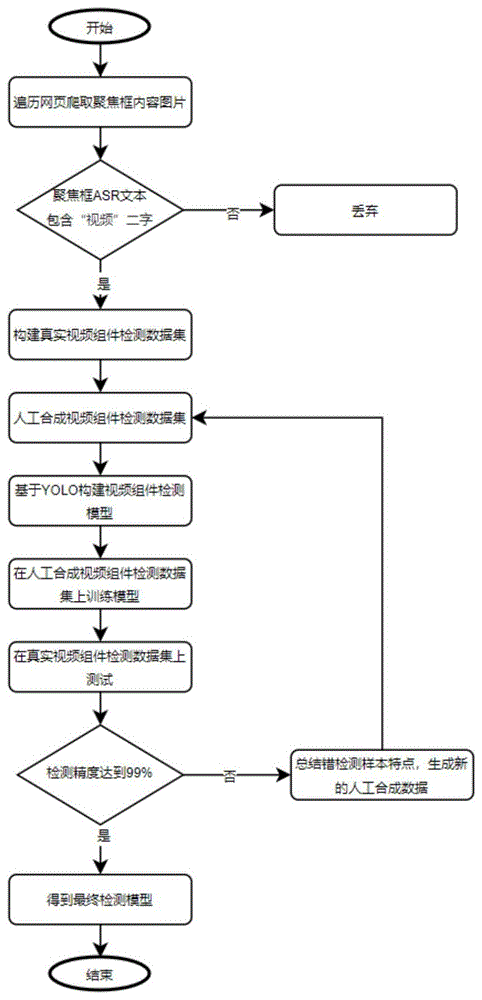
基于YOLO的网页视频组件非侵入式检测方法,具体步骤如下:
S101:以爬虫的方式从互联网中爬取含视频组件的图片;
S102:清洗图片数据集,人工过滤掉不包含视频组件的图片并通过人工方式对视频组件位置进行打标,构建真实视频组件检测数据集;
S103:采用人工合成页面视频组件检测数据的方式构建人工合成视频组件检测数据集;
S104:基于YOLO构建视频组件检测模型;
S105:利用步骤S103人工合成的页面视频组件检测数据集对步骤S104构建的视频组件检测模型进行训练;
S106:利用步骤S102所产生的真实页面视频组件检测数据集对步骤S105所得到的训练完成的页面视频组件检测模型进行测试;
S107:获取步骤S106测试中的错检图片,总结错检图片特点生成新的合成图片加入现有合成数据集中;
S108:重复步骤S105、S106、S107,直到模型在真实数据集上检测精度达到99%,停止迭代,得到最终模型。
具体地,步骤S101中,爬取的图片具体要求为图片必须为png或者jpg格式的聚焦框图片。
具体所述步骤S102中,数据清洗的具体方法为:
S1021:利用ASR工具获取图片内的纯文本内容,过滤掉ASR文本内容中不包含“视频“二字的图片;
S1022:对经过S1021过滤后得到的图片数据集进行人工筛查和打标,标记出图片上视频组件的位置信息,进一步过滤掉不包含视频组件的图片。
具体所述步骤S103中,人工合成网页视频组件检测数据集的步骤为:
S1031:从S1022中获取的网页视频组件检测图片中截取不同样式的播放图标;
S1032:从iconfont UI矢量图标库获得播放图标;
S1033:从bilibili,youtube中爬取视频封面图像;
S1034:将S1033所获得的视频封面图片作为背景图片,随机选取S1031、S1032中获得的播放图标,随机放置在背景图片的中央、左上角、左下角、右上角、右下角或者是视频框外的留白处。播放图标的大小设置为小、中、大三种尺寸,图标的透明度设置为0%,20%,40%,60%,80%五种选项,在人工合成图片时随机选择图标大小和透明度。
具体所述步骤S104中,基于YOLO构建的视频组件检测模型结构为:
S1041:构建的视频组件检测模型至少包括输入层、卷积层、全连接层、池化层、输出层;
S1042:视频组件检测模型在MSCOCO数据集上进行预训练,获得模型的初始权重;
S1043:为了避免给将大分辨率的图片压缩导致信息丢失,模型的input size设置为1280。
具体所述步骤S105中,利用S103人工合成的页面视频组件检测数据集对S104构建的视频组件检测模型进行训练的步骤为:对S103获得的人工合成视频组件检测数据集按照9:1的比例进行划分,其中90%的数据作为训练集用于视频组件检测模型的训练,10%的数据作为验证集用于观测训练过程中是否会出现过拟合现象以及选取模型的最佳参数。
具体所述步骤S106中,利用真实页面视频组件检测数据集对S105所得到的训练完成的页面视频组件检测模型进行测试具体的测试方法为:
S1061:使用精度、召回率、平均精确度评估模型在真实数据集上的准确性和鲁棒性;
S1062:收集检测错误的错检图片。
具体所述步骤S107中,生成新合成样本的方法:
S1071:统计错检图片中视频组件的大小,位置,透明度,背景图片类型;
S1072:根据错检图片中视频组件的大小,位置,透明度,背景图片类型生成相应的人工合成数据。
综上所述,本发明实现了一种基于YOLO的网页视频组件非侵入式检测方法,具有以下有益效果:(1)高准确率,其在真实数据集上的检测精度可达到0.99以上。(2)高鲁棒性,能够检测分布在不同位置和不同样式的视频控件。(3)非侵入式方法,无需获取源码,可应用于黑盒测试场景,具有广泛适用性。
附图说明:
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明提供的网页视频组件检测模型构建流程图.
图2是本发明提供的网页视频组件检测效果图。
图3是本发明提供的人工合成视频组件数据方法中插入视频组件的位置示意图。
具体实施方法:
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
本实例以某个网页为例,基于YOLO的网页视频组件非侵入式检测方法,包括如下步骤
S101:以爬虫的方式从互联网中爬取含视频组件的图片;
S102:清洗图片数据集,人工过滤掉不包含视频组件的图片并通过人工方式对视频组件位置进行打标,构建真实视频组件检测数据集;
S103:采用人工合成页面视频组件检测数据的方式构建人工合成视频组件检测数据集;
S104:基于YOLO构建视频组件检测模型;
S105:利用步骤S103人工合成的页面视频组件检测数据集对步骤S104构建的视频组件检测模型进行训练;
S106:利用步骤S102所产生的真实页面视频组件检测数据集对步骤S105所得到的训练完成的页面视频组件检测模型进行测试;
S107:获取步骤S106测试中的错检图片,总结错检图片特点生成新的合成图片加入现有合成数据集中;
S108:重复步骤S105、S106、S107步骤,直到模型在真实数据集上检测精度达到99%,停止迭代,得到最终模型。
具体地,步骤S101中,爬取的图片具体要求为图片必须为png或者jpg格式的聚焦框图片。
具体所述步骤S102中,数据清洗的具体方法为:
S1021:利用ASR工具获取图片内的纯文本内容,过滤掉ASR文本内容中不包含“视频“二字的图片;
S1022:对经过S1021过滤后得到的图片数据集进行人工筛查和打标,标记出图片上视频组件的位置信息,进一步过滤掉不包含视频组件的图片。
具体所述步骤S103中,人工合成网页视频组件检测数据集的步骤为:
S1031:从S1022中获取的网页视频组件检测图片中截取不同样式的播放图标;
S1032:从iconfont UI矢量图标库获得播放图标;
S1033:从bilibili,youtube中爬取视频封面图像;
S1034:将S1033所获得的视频封面图片作为背景图片,随机选取S1031、S1032中获得的播放图标,随机放置在背景图片的中央、左上角、左下角、右上角、右下角或者是视频框外的留白处。播放图标的大小设置为小、中、大三种尺寸,图标的透明度设置为0%,20%,40%,60%,80%五种选项,在人工合成图片时随机选择图标大小和透明度。
具体所述步骤S104中,基于YOLO构建的视频组件检测模型结构为:
S1041:构建的视频组件检测模型至少包括输入层、卷积层、全连接层、池化层、输出层;
S1042:视频组件检测模型在MSCOCO数据集上进行预训练,获得模型的初始权重;
S1043:为了避免给将大分辨率的图片压缩导致信息丢失,模型的input size设置为1280。
具体所述步骤S105中,利用S103人工合成的页面视频组件检测数据集对S104构建的视频组件检测模型进行训练的步骤为:对S103获得的人工合成视频组件检测数据集按照9:1的比例进行划分,其中90%的数据作为训练集用于视频组件检测模型的训练,10%的数据作为验证集用于观测训练过程中是否会出现过拟合现象以及选取模型的最佳参数。
具体所述步骤S106中,利用真实页面视频组件检测数据集对S105所得到的训练完成的页面视频组件检测模型进行测试具体的测试方法为:
S1061:使用精度、召回率、平均精确度评估模型在真实数据集上的准确性和鲁棒性;
S1062:收集检测错误的错检图片。
具体所述步骤S107中,生成新合成样本的方法:
S1071:统计错检图片中视频组件的大小,位置,透明度,背景图片类型;
S1072:根据错检图片中视频组件的大小,位置,透明度,背景图片类型生成相应的人工合成数据。
以上所述仅为本发明的实施例而已,并不用于限制本发明。对于本领域技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。