基于大型语言模型的测试用例生成系统
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及软件测试技术领域,具体涉及一种基于大型语言模型的测试用例生成系统。
背景技术
测试用例是在软件测试过程中使用的一组输入、执行步骤和预期结果的规范化描述。它用于验证软件系统是否按照预期工作,检测潜在的错误和缺陷。测试用例的设计和编写是软件测试过程中的关键步骤。良好的测试用例能够有效地检测潜在的错误和缺陷,提高软件的质量和可靠性。大型语言模型,是指使用大量文本数据训练的深度学习模型,可以生成自然语言文本或理解语言文本的含义。大语言模型可以处理多种自然语言任务,如文本分类、问答、对话等,是通向人工智能的一条重要途径。
现有技术中,已存在有通过软件辅助测试用例的生成的方案,比如,中国专利CN201610739639.0公开了一种测试用例生成方法,属于软件测试技术领域,方法包括:预设多个基础测试用例,并针对一个基础测试用例,根据正确值列表中的正确取值或者错误值列表中的错误取值,分别更改每个基础测试动作的数值,以分别形成多个不同的衍生测试动作,并且根据多个不同的衍生测试动作组成关联于基础测试用例的多个不同的衍生测试用例;将所有基础测试用例和所有衍生测试用例均作为测试用例,并将所有基础测试动作和所有衍生测试动作均作为测试动作,随后根据测试用例和测试动作对系统进行自动测试。上述技术方案的有益效果是:实现测试用例的自动编写,从而缩短测试用时、提升测试效率,节省人力成本。
但是,在实际实施过程中,发明人发现,上述方案在使用过程中,往往需要预先设计较为全面的测试用例,软件仅能够实现简单的变量、参数等的替换,无法实现自设计规范至用例的自动生成过程。
发明内容
针对现有技术中存在的上述问题,现提供一种基于大型语言模型的测试用例生成系统。
具体技术方案如下:
一种基于大型语言模型的测试用例生成系统,包括:
用例收集模块,所述用例收集模块自多个数据源获取测试样本数据形成用例数据集;
用例扩增模块,所述用例扩增模块分别连接所述用例收集模块和外部的大型语言模型,所述用例扩增模块依照所述用例数据集生成指示信息,所述用例扩增模块向所述大型语言模型输入所述指示信息;
所述大型语言模型依照所述指示信息生成预测用例;
用例修正模块,所述用例修正模块连接所述大型语言模型,所述用例修正模块对所述预测用例进行修正后形成扩充用例并输出。
另一方面,所述用例收集模块包括:
文本输入模块,所述文本输入模块分别连接所述数据源并从所述数据源中获取测试样本数据;
文本清洗模块,所述文本清洗模块连接所述文本输入模块,所述文本清洗模块对所述测试样本数据进行清洗得到清洗数据;
分词模块,所述分词模块连接所述文本清洗模块,所述分词模块对所述清洗数据进行分词得到分词序列;
语义标注模块,所述语义标注模块连接所述分词模块,所述语义标注模块对所述分词序列中的每一个分词单元分别标注词义信息;
数据集构建模块,所述数据集构建模块连接所述语义标注模块,所述数据集构建模块依照所述词义信息对所述分词序列进行整理,形成所述用例数据集并输出。
另一方面,所述用例扩增模块包括:
描述模块,所述描述模块依照所述用例数据集生成对应于所述扩充用例的描述信息;
模板组装模块,所述模板组装模块连接所述描述模块,所述模板组装模块依照所述描述信息调用对应的对话模板,随后采用所述对话模板对所述用例数集进行包装形成所述指示信息;
模型输入模块,所述模型输入模块分别连接所述模板组装模块和所述大型语言模型,所述模型输入模块将所述指示信息依次输入大型语言模型,以使得所述大型语言模型生成所述预测用例。
另一方面,所述用例扩增模块还包括:
模型提示模块,所述模型提示模块分别连接所述模型输入模块和所述大型语言模型,所述模型提示模块在所述模型输入模块输入所述指示信息后,获取所述大型语言模型的反馈信息,并判断所述反馈信息是否包含所述预测用例;
当不包含所述预测用例时,所述模型提示模块依照所述指示信息生成二次提示信息并再次输入所述大型语言模型,直至所述大型语言模型输出所述预测用例。
另一方面,所述用例修正模块包括:
用例分析模块,所述用例分析模块接收所述预测用例,并分别对每个所述预测用例进行仿真,以筛选得到可执行用例;
冗余分析模块,所述冗余分析模块连接所述用例分析模块,所述相似性分析模块对所述可执行用例进行去重得到冗余修正用例;
相似性分组模块,所述相似性分组模块连接所述冗余分析模块,所述相似性分组模块对所述冗余修正用例进行相似性分析,随后划分成多组所述扩充用例并输出。
另一方面,所述冗余分析模块包括:
特征提取模块,所述特征提取模块对每个所述可执行用例分别提取用例特征;
相似度计算模块,所述相似度计算模块连接所述特征提取模块,所述相似度计算模块依照所述用例特征计算多个所述可执行用例之间的相似度;
阈值判别模块,所述阈值判别模块连接所述相似度计算模块,所述阈值判别模块依照所述相似度和相似度阈值判断多个所述可执行用例之间是否相似,并将相似的所述可执行用例进行分组得到重复组;
用例剔除模块,所述用例剔除模块连接所述阈值判别模块,所述用例剔除模块对所述重复组中的所述可执行用例进行剔除并仅保留一项所述可执行用例;
冗余修正输出模块,所述冗余修正输出模块连接所述用例剔除模块,所述冗余修正输出模块将剩余的所述可执行用例收集后作为所述冗余修正用例输出。
另一方面,所述相似性分组模块包括:
向量表征模块,所述向量表征模块对每个所述冗余修正用例生成用例向量;
向量聚类模块,所述向量聚类模块连接所述向量表征模块,所述向量聚类模块对所述用例向量进行聚类,得到聚类结果;
分组模块,所述分组模块连接所述向量聚类模块,所述分组模块依照所述聚类结果对所述冗余修正用例进行分组后作为所述扩充用例输出。
另一方面,还包括:
覆盖范围判断模块,所述覆盖范围判断模块分别连接所述用例修正模块和所述用例扩增模块,所述覆盖范围判断模块对所述扩充用例进行比较以生成覆盖范围,所述覆盖范围判断模块依照所述覆盖范围向所述用例扩增模块输入用例倾向性指示信息;
所述用例扩增模块依照用例倾向性指示信息调整所述指示信息。
上述技术方案具有如下优点或有益效果:
针对现有技术中的用例生成软件仅能够实现简单的参数替换,无法依照设计规范自行生成用例的问题,本方案中,引入了大型语言模型对多方数据源输入的测试样本数据进行识别,从而使得大型语言模型能够理解所需要的测试用例的内容,包括典型的测试用例的形式、设计规范、边界条件等,进而使得大型语言模型自行生成扩充用例,仅需要进行简单的修正后即可使用。
附图说明
参考所附附图,以更加充分的描述本发明的实施例。然而,所附附图仅用于说明和阐述,并不构成对本发明范围的限制。
图1为本发明实施例的整体示意图;
图2为本发明实施例中用例收集模块示意图;
图3为本发明实施例中用例扩增模块示意图;
图4为本发明实施例中模型提示模块示意图;
图5为本发明实施例中用例修正模块示意图;
图6为本发明实施例中冗余分析模块示意图;
图7为本发明实施例中相似性分组模块示意图;
图8为本发明实施例中覆盖范围判断模块示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
本发明包括:
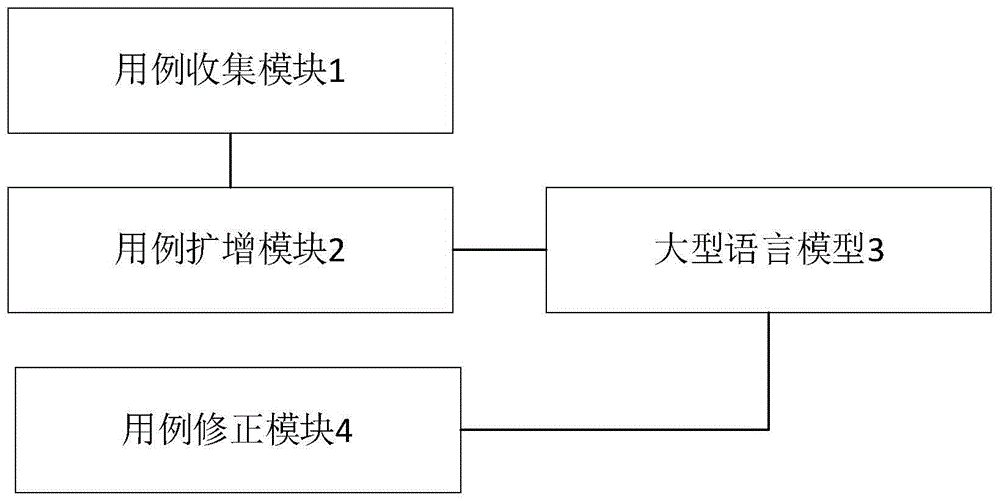
一种基于大型语言模型的测试用例生成系统,包括:
用例收集模块1,用例收集模块1自多个数据源获取测试样本数据形成用例数据集;
用例扩增模块2,用例扩增模块2分别连接用例收集模块1和外部的大型语言模型3,用例扩增模块2依照用例数据集生成指示信息,用例扩增模块2向大型语言模型3输入指示信息;
大型语言模型3依照指示信息生成预测用例;
用例修正模块4,用例修正模块4连接大型语言模型3,用例修正模块4对预测用例进行修正后形成扩充用例并输出。
具体地,针对现有技术中的测试用例生成软件仅能在原有的测试用例基础上进行扩增,不能自行生成用例的问题,本实施例中,通过用例收集模块1自多个数据源获取测试样本数据形成用例数据集,该用例数据集中包含了已预先构建的用例范本、系统文档、用例库、输入输出样本等,随后,用例扩增模块2依照用例数据集生成指示信息,用例扩增模块2向大型语言模型3输入指示信息,从而使得大型语言模型3能够理解当前需要生成的测试用例的形式,进而依照指示信息随机生成预测用例,该预测用例可能在相关文档的指示范围内随机分布,随后,用例修正模块4对预测用例进行修正,去除其中明显错误、超出设计规范的部分后形成扩充用例,用于后续的软件测试流程。
在实施过程中,上述测试用例生成系统主要作为软件实施例设置在特定的计算机设备中,用于对相关文档进行收集并输出扩充用例。其中,该软件实施例可以集成到现有的测试框架和工具中,和原有的用例库、测试环境进行对接,提供相应的API和接口,以便调用。测试样本数据指在开发过程中产生的,可用于对期望生成的测试用例进行描述的相关信息,包括设计规范、系统文档、已经编辑好的测试用例、在实际环境中采集到的日志数据等。
在一个实施例中,如图2所示,用例收集模块1包括:
文本输入模块11,文本输入模块11分别连接数据源并从数据源中获取测试样本数据;
文本清洗模块12,文本清洗模块12连接文本输入模块11,文本清洗模块12对测试样本数据进行清洗得到清洗数据;
分词模块13,分词模块13连接文本清洗模块12,分词模块13对清洗数据进行分词得到分词序列;
语义标注模块14,语义标注模块14连接分词模块13,语义标注模块14对分词序列中的每一个分词单元分别标注词义信息;
数据集构建模块15,数据集构建模块15连接语义标注模块14,数据集构建模块15依照词义信息对分词序列进行整理,形成用例数据集并输出。
具体地,为实现对大型语言模型3较好的输入效果,本实施例中,在用例收集模块1中,设置了文本输入模块11分别连接数据源并从数据源中获取测试样本数据,针对测试样本数据,文本清洗模块12对测试样本数据进行清洗,去除去除非关键字符、HTML标签、特殊符号等,再进行格式化处理得到清洗数据;然后,分词模块13对清洗数据进行分词,将文本分割成单个词语或短语得到分词序列,然后,语义标注模块14对分词序列中的每一个分词单元分别标注词义信息,帮助后续的数据集构建模块15依照词义信息对分词序列进行整理,将多余的修饰内容、无关项去除,仅保留测试相关的信息,形成用例数据集并输出,便于后续的模型输入。
在一个实施例中,如图3所示,用例扩增模块2包括:
描述模块21,描述模块21依照用例数据集生成对应于扩充用例的描述信息;
模板组装模块22,模板组装模块22连接描述模块21,模板组装模块22依照描述信息调用对应的对话模板,随后采用对话模板对用例数集进行包装形成指示信息;
模型输入模块23,模型输入模块23分别连接模板组装模块22和大型语言模型3,模型输入模块23将指示信息依次输入大型语言模型3,以使得大型语言模型3生成预测用例。
具体地,为使得大型语言模型3较好的理解待生成的预测用例,本实施例中,通过描述模块21依照用例数据集生成对应于扩充用例的描述信息,随后,模板组装模块22依照描述信息调用对应的对话模板,并采用对话模板对用例数集进行包装形成具有特定的对话格式的指示信息,该对话模板依照不同类型的输入文本和用例确定,用于向模型指示当前输入的信息属于哪一类关联于用例设计的信息,比如文档、样本示例等。最后,模型输入模块23将指示信息依次输入大型语言模型3,以使得大型语言模型3生成预测用例。
在一个实施例中,如图4所示,用例扩增模块2还包括:
模型提示模块24,模型提示模块24分别连接模型输入模块23和大型语言模型3,模型提示模块24在模型输入模块输入指示信息后,获取大型语言模型3的反馈信息,并判断反馈信息是否包含预测用例;
当不包含预测用例时,模型提示模块24依照指示信息生成二次提示信息并再次输入大型语言模型3,直至大型语言模型3输出预测用例。
具体地,为实现较为准确的用例生成过程,本实施例中,还通过模型提示模块监测大型语言模型3的反馈信息,并判断反馈信息是否包含预测用例,当不包含预测用例时,模型提示模块24依照指示信息生成二次提示信息并再次输入大型语言模型3,直至大型语言模型3输出预测用例,通过上述过程来避免大型语言模型3未能输出预期的内容的问题。
在一个实施例中,如图5所示,用例修正模块4包括:
用例分析模块41,用例分析模块41接收预测用例,并分别对每个预测用例进行仿真,以筛选得到可执行用例;
冗余分析模块42,冗余分析模块42连接用例分析模块41,冗余分析模块42对可执行用例进行去重得到冗余修正用例;
相似性分组模块43,相似性分组模块43连接冗余分析模块42,相似性分组模块43对冗余修正用例进行相似性分析,随后划分成多组扩充用例并输出。
具体地,考虑到大型语言模型3在输出预测用例时,难以对用例的范围进行有效约束的问题,本实施例中,先通过用例分析模块41接收预测用例,并分别对每个预测用例进行仿真,去除掉显然无法顺序执行的错误用例,以筛选得到可执行用例;考虑到可执行用例中,可能存在重复生成的问题,为提高测试效率,通过冗余分析模块42对可执行用例进行去重得到冗余修正用例,最后,由似性分组模块43对冗余修正用例进行相似性分析,随后划分成多组扩充用例,每一组扩充用例分别对应于一类测试场景,便于在测试过程中针对特定的问题通过同一组内的多个扩充用例进行快速测试。
在一个实施例中,如图6所示,冗余分析模块42包括:
特征提取模块421,特征提取模块421对每个可执行用例分别提取用例特征;
相似度计算模块422,相似度计算模块422连接特征提取模块421,相似度计算模块422依照用例特征计算多个可执行用例之间的相似度;
阈值判别模块423,阈值判别模块423连接相似度计算模块422,阈值判别模块423依照相似度和相似度阈值判断多个可执行用例之间是否相似,并将相似的可执行用例进行分组得到重复组;
用例剔除模块424,用例剔除模块424连接阈值判别模块423,用例剔除模块424对重复组中的可执行用例进行剔除并仅保留一项可执行用例;
冗余修正输出模块425,冗余修正输出模块425连接用例剔除模块424,冗余修正输出模块425将剩余的可执行用例收集后作为冗余修正用例输出。
具体地,为实现对可执行用例较好的去重效果,本实施例中,通过特征提取模块421对每个可执行用例分别提取用例特征,实现对各可执行用例较好的表征,随后,相似度计算模块422依照用例特征分别计算多个可执行用例两两之间的相似度,再通过阈值判别模块423依照相似度和相似度阈值判断多个可执行用例之间是否相似并将相似的可执行用例进行分组得到重复组,该重复组中包含的可执行用例其执行流程、变量等较为接近,可认为是冗余用例,随后,用例剔除模块424对重复组中的可执行用例进行剔除并仅保留一项可执行用例,再由冗余修正输出模块425将剩余的可执行用例收集后作为冗余修正用例输出。
在一个实施例中,如图7所示,相似性分组模块43包括:
向量表征模块431,向量表征模块431对每个冗余修正用例生成用例向量;
向量聚类模块432,向量聚类模块432连接向量表征模块431,向量聚类模块432对用例向量进行聚类,得到聚类结果;
分组模块433,分组模块433连接向量聚类模块432,分组模块433依照聚类结果对冗余修正用例进行分组后作为扩充用例输出。
具体地,为实现对冗余修正用例较好的分组效果,本实施例中,通过向量表征模块431对每个冗余修正用例生成用例向量,随后,向量聚类模块432对用例向量进行聚类,得到聚类结果,该聚类结果用于对向量相对接近的冗余修正用例进行归类,使得分组模块433可以依照聚类结果对冗余修正用例进行分组后作为扩充用例输出。
在一个实施例中,如图8所示,还包括:
覆盖范围判断模块5,覆盖范围判断模块5分别连接用例修正模块4和用例扩增模块2,覆盖范围判断模块5对扩充用例进行比较以生成覆盖范围,覆盖范围判断模块5依照覆盖范围向用例扩增模块2输入用例倾向性指示信息;
用例扩增模块2依照用例倾向性指示信息调整指示信息。
具体地,为实现用例较好的覆盖效果,本实施例中,还设置了覆盖范围判断模块5对输出的扩充用例和预期的测试规范进行比较,确定覆盖范围以及当前的测试用例并未覆盖的部分。针对并未覆盖的部分,覆盖范围判断模块5依照覆盖范围向用例扩增模块2输入用例倾向性指示信息,使得后续用例扩增模块2在向模型输入指示信息时,依照用例倾向性指示信息调整指示信息,来控制模型输出的用例能够覆盖特定范围。
以上仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书及图示内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
- 自动机器人控制方法、装置、自动机器人和介质
- 一种机器人避障控制方法、装置、存储介质及机器人
- 扫地机器人的清扫控制方法及其装置和扫地机器人
- 用于环卫作业的机器人的控制方法、装置以及机器人
- 机器人安全限位装置及其控制方法、机器人
- 机器人控制模型学习方法、机器人控制模型学习装置、机器人控制模型学习程序、机器人控制方法、机器人控制装置、机器人控制程序以及机器人
- 机器人控制装置、机器人控制方法及学习模型生成装置