一种基于长短期时序感知的视频人脸表情识别方法及系统
文献发布时间:2024-04-18 20:01:55
技术领域
本发明涉及图像处理与计算机视觉技术领域,特别涉及一种基于长短期时序感知的视频人脸表情识别方法及系统。
背景技术
面部表情是人类表达自我情绪的一种最自然、最直接的方式,因此弄清人类情绪状态是许多计算机视觉任务的基本前提,这些任务包括人机交互、驾驶员疲劳监测和医疗保健等等。虽然视频人脸表情识别方法因深度学习的兴起已取得较大进展,但目前基于深度学习的视频人脸表情识别方法主要是基于三维卷积网络、循环神经网络、自注意力变换网络来进行的。
然而,现有的视频人脸表情识别模型在时序建模上没有同时考虑到人脸视频序列中帧与帧之间的短期和长期时序的重要性,从而导致模型提取到的时序特征不够全面。另外,考虑到在开放环境下,人脸表情通常伴随着光照变化、遮挡等干扰因素,因此还需要设计模块对每帧人脸表情提取更为鲁棒的深度网络特征,从而进一步提高识别结果的准确性。
发明内容
本发明的目的在于克服现有技术中所存在的视频人脸表情识别模型提取到的时序特征不够全面,导致识别的准确性不高的问题,提供一种基于长短期时序感知的视频人脸表情识别方法及系统,其设计了通道空间特征增强模块并结合了短期和长期两种时序信息来对人脸视频序列进行处理,从而获得增强的卷积网络特征和长短期时序感知的人脸表情特征,提高了识别的准确性。
为了实现上述发明目的,本发明提供了以下技术方案:
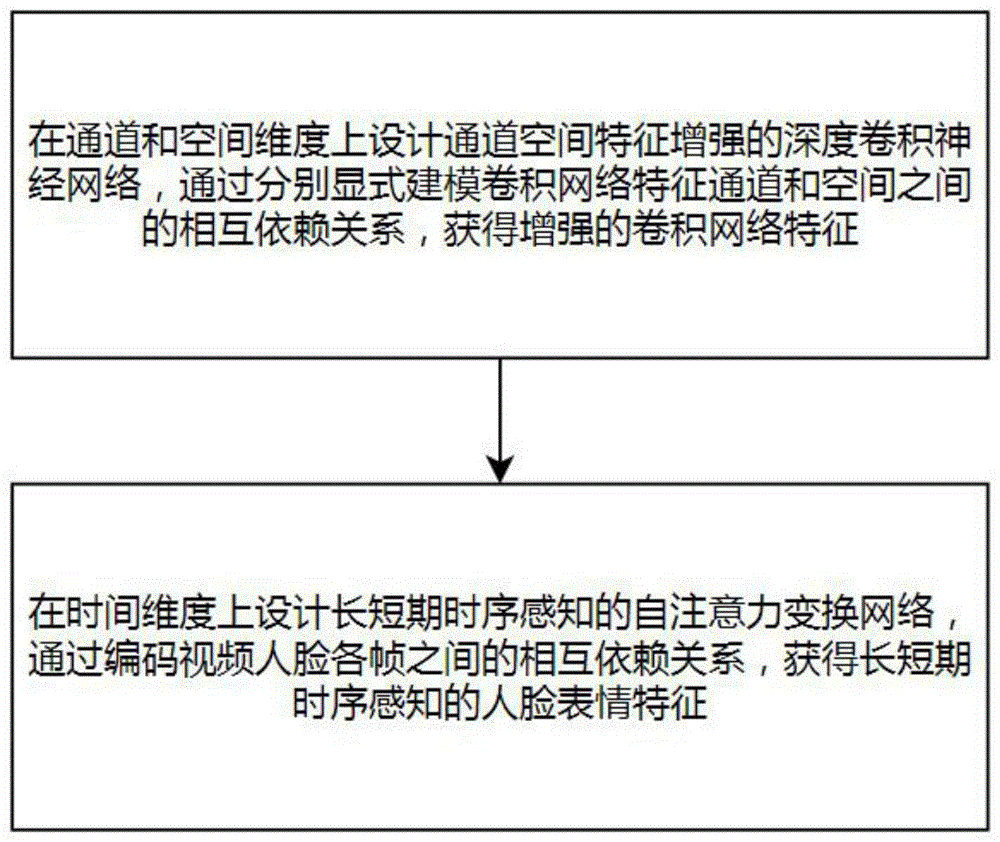
S1,在通道和空间维度上设计通道空间特征增强的深度卷积神经网络,通过分别显式建模卷积网络特征通道和空间之间的相互依赖关系,获得增强的卷积网络特征;
S2,在时间维度上设计长短期时序感知的自注意力变换网络,通过编码视频人脸各帧之间的相互依赖关系,获得长短期时序感知的人脸表情特征。
具体的,所述S1中的通道空间特征增强的深度卷积神经网络包括一个卷积头,M个深度残差网络块和一个全局平均池化层;其中,所述卷积头主要包括一个卷积层和一个最大池化层,每一个所述深度残差网络块包括一个通道空间特征增强模块和两个卷积层。
进一步的,所述S1中的通道空间特征增强的深度卷积神经网络的设计步骤包括:
S11:输入一段人脸视频,首先将该视频分成U个片段,然后从每个片段中随机采样V帧,最后将采样得到的T=U×V帧视频序列输入到人脸检测器中检测并裁剪人脸区域,从而得到T帧人脸序列X;
S12:输入T帧人脸序列X至所述深度卷积神经网络的卷积头,提取初步的特征图,包括:
X′=Maxpool(ReLU(BatchNorm(Conv(X))))(1)
其中,X′为所述深度卷积神经网络的卷积头输出的特征图;Conv为从人脸序列中提取特征的卷积层;BatchNorm为批归一化;ReLU为线性修正单元激活函数;Maxpool为最大池化层;
S13:所述网络包含M个深度残差网络块,第l-1个残差块的输出X
其中,
S14:对最后一个残差块输出的特征图X
X
其中,X
进一步的,所述S2中的所述长短期时序感知的自注意力变换网络包括N个长短期时序编码器、一个时间平均池化层和一个全连接层;其中,每个所述编码器包括时间维度上的多头自注意力模块和前向传播网络模块,所述前向传播网络模块包括一个一维时间卷积和两个线性层。
所述S2中的长短期时序感知的自注意力变换网络包含以下步骤:
S21:所述深度卷积神经网络包含N个长短期时序编码器,第j-1个编码器的输出Y
其中,MHSA为所述多头自注意力模块;LayerNorm为层归一化;
S22:对最后一个时序编码器输出的特征图Y
Y
其中,Y
S23:最终的表情识别结果由一个全连接层获得,可由以下操作计算:
p=FC(Y
其中,p为网络对人脸序列所属表情的分类结果;FC为全连接层。
一种基于长短期时序感知的视频人脸表情识别系统,包括至少一个处理器,以及与所述至少一个处理器通信连接的存储器;所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行权利要求上述的方法。
与现有技术相比,本发明的有益效果:。
1、通过通道空间特征增强的深度卷积神经网络获得增强的卷积网络特征对开放环境下的光照变化、遮挡等干扰因素具有鲁棒性;
2、通过长短期时序感知的自注意力变换网络得到的时序特征能够更全面地感知人脸表情的时序上下文信息,从而有效地提高识别性能,进一步提高识别结果的准确性。
附图说明
图1为本发明所提供的一种基于长短期时序感知的视频人脸表情识别方法的流程图;
图2为本发明所提供的一种基于长短期时序感知的视频人脸表情识别方法的网络结构示意图;
图3为本发明所提供的一种基于长短期时序感知的视频人脸表情识别方法的通道空间特征增强模块CSAM网络结构示意图;
图4为本发明所提供的一种基于长短期时序感知的视频人脸表情识别方法的长短期时序感知的自注意力变换网络LSTformer结构示意图。
具体实施方式
下面结合试验例及具体实施方式对本发明作进一步的详细描述。但不应将此理解为本发明上述主题的范围仅限于以下的实施例,凡基于本发明内容所实现的技术均属于本发明的范围。
实施例
本实施例提供一种基于长短期时序感知的视频人脸表情识别方法,方法主要包括以下步骤:
步骤1,在空间和通道维度上设计深度卷积神经网络,分别显式建模卷积网络特征通道或空间之间的相互依赖关系,得到增强的卷积网络特征。
步骤2,在时间维度上设计自注意力变换网络,编码视频人脸各帧之间的相互依赖关系,得到长短期时序感知的人脸表情特征。
所述的步骤1中的通道空间特征增强的深度卷积神经网络包括一个卷积头、M=4个深度残差网络块和一个全局平均池化层,其中,卷积头包括一个卷积层和一个最大池化层,每一个深度残差网络块主要包含一个通道空间特征增强模块和两个卷积层。
具体来说,本实施例中卷积子网络共有0~n(n=4)个层级,为:Conv-head(第0级),Res-l(l=1,...,4)。4个通道空间特征增强模块CSAM-l(l=1,...,4)按层级插入到Res-l中实现卷积特征通道和空间维度上的特征增强。卷积子网络第0-4层的输出为X
需要说明的是,相互依赖关系指的是经神经网络提取后的特征
通过计算这种相关性,就可以知道相互之间关联性较强的通道、空间、视频帧,从而能够引导神经网络专注学习对完成某个任务所必要的部分信息,提高了其学习效率。
优选的,步骤1中的通道空间特征增强的深度卷积神经网络包含以下步骤:
第一步:输入一段人脸视频,首先将该视频分成U=8个片段,然后从每个片段中随机采样V=2帧,最后将采样得到的T=U×V=16帧视频序列输入到人脸检测器中检测并裁剪人脸区域,从而得到T=16帧人脸序列X;
第二步:输入T帧人脸序列X至所述网络的卷积头,提取初步的特征图,包括:
X′=Maxpool(ReLU(BatchNorm(Conv(X))))(1)
其中,X′为所述网络卷积头输出的特征图;Conv为卷积核大小为7×7、步长为2、零填充为1、输出通道数为64的卷积层;BatchNorm为批归一化;ReLU为线性修正单元激活函数;Maxpool为池化核大小为3×3、步长为2的最大池化层。第三步:所述网络包含M=4个深度残差网络块,第l-1个残差块的输出X
其中,
第四步:对最后一个残差块输出的特征图X
X
其中,X
所述的步骤2中长短期时序感知的自注意力变换网络主要由N=2个长短期时序编码器、一个时间平均池化层和一个全连接层组成,其中每个编码器由时间维度上的多头自注意力模块和前向传播网络模块组成,前向传播网络模块主要包括一个一维时间卷积和两个线性层。
优选的,步骤2中长短期时序感知的自注意力变换网络包含以下步骤:第一步:所述网络包含N=2个长短期时序编码器,第j-1个编码器的输出Y
其中,MHSA为所述多头自注意力模块;LayerNorm为层归一化;
第二步:对最后一个时序编码器输出的特征图Y
Y
其中,Y
第三步:最终的表情识别结果由一个全连接层获得,可由以下操作计算:
p=FC(Y
其中,p为网络对人脸序列所属表情的分类结果;FC为全连接层。
一种基于长短期时序感知的视频人脸表情识别系统,包括至少一个处理器,以及与所述至少一个处理器通信连接的存储器;所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述的视频人脸表情识别方法。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种户外低光粉末涂料及其制备方法
- 一种环氧树脂粉末涂料用消光固化剂及其制备方法与应用
- 一种具有自洁效果的疏水耐玷污环氧树脂防腐粉末涂料及其制备方法
- 一种掺杂气相二氧化硅改性不饱和聚酯树脂的珠光型环氧粉末涂料的制备方法
- 一种本征型无卤低烟阻燃环氧树脂复合材料的制备方法
- 一种低光粉末涂料用环氧树脂及制备方法
- 一种粉末涂料用低氯支化型环氧树脂及其制备方法与应用