短文本主题分布的推理方法、系统、计算机设备和存储介质
文献发布时间:2023-06-19 09:26:02
技术领域
本申请涉及大数据领域,特别是涉及一种短文本主题分布的推理方法、系统、计算机设备和存储介质。
背景技术
主题模型是一类从文本数据中挖掘并抽取主题,为了设计出适用于短文本数据的主题模型,研究人员通常会使用几种比较有用策略。第一种,限制每一篇短文本的主题数量,,通过Dirichlet Multinomial Mixture Model(DMM)模型进行获取,其中通过该模型假定每个短文本只包含一个主题。这种策略通过限制目标数据中的主题信息,进一步简化主题模型,以期能够更准确的进行主题的挖掘、抽取和分配。第二种,在包含足够主题信息的单词模式上建立主题模型。典型的代表是Attentional Segments Topic Model(ASTM),ASTM会抽取出短文本中的segment模式,具体而言是数个语义相似的单词组成的集合。从segment这样模式中获得的主题具有很好的代表性。第三种,从外部的语料中获得新的信息,并将其补充到目标短文本数据的主题模型中。这种方法是针对目标数据短文本自身的信息稀疏性而设计的。既然目标数据的信息不够,那么就从外部引入信息来补充目标数据的上下文信息,以此来获得更好的主题模型。比较典型的代表是Semantic Assisted Non-negative Matrix Factorization(SeaNMF).
但是上述介绍的每一种策略都有各自的缺陷。第一种,虽然限制每个短文本的主题数量能够有效地简化主题模型,但是同时也会导致目标短文本数据的主题信息丢失。这种信息丢失很多情况下是不可以接受的,并且实验证明,基于该策略设计的主题模型在真实数据下表现并不算良好。第二种,这类策略通常涉及到全新的字词模式设计,在实际的短文本数据上的表现也不错。但是,设计全新的能够准确的表现短文本的主题信息并不是一件简单的事情。并且,这列方法依然没有克服传统方法的束缚,整个主题模型能够获得的信息都被局限在了目标数据上,并没有获得新的信息。因此,单纯依赖此类策略设计出来的主题模型的表现并不算优秀。第三种,通过从外部获得指定的信息,来丰富目标数据的上下文信息。这种策略的问题在于两点:1.如何合理的利用外部信息来指导主题模型的工作;2.现有的主题模型通常只考虑语义信息来作为外部信息,而忽略了一些其他的重要信息。
发明内容
基于此,有必要针对上述技术问题,提供一种短文本主题分布的推理方法、系统、计算机设备和存储介质。
第一方面,本发明实施例提供了一种短文本主题分布的推理方法,包括以下步骤:
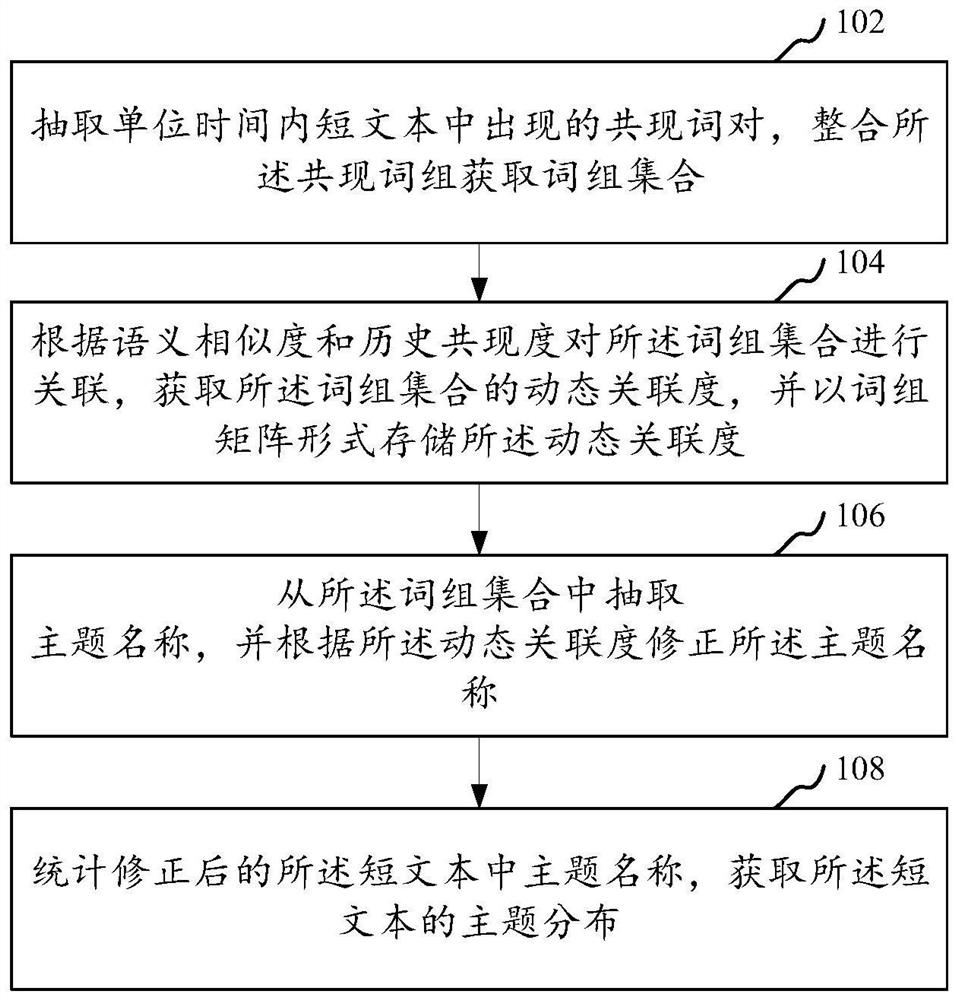
抽取单位时间内短文本中出现的共现词对,整合所述共现词对获取词组集合;
根据语义相似度和历史共现度对所述词组集合进行关联,获取所述词组集合的动态关联度,并以词组矩阵形式存储所述动态关联度;
从所述词组集合中抽取主题名称,并根据所述动态关联度修正所述主题名称;
统计修正后的所述短文本中主题名称,获取所述短文本的主题分布。
进一步地,所述抽取单位时间内短文本中出现的共现词对,整合所述共现词对获取词组集合;包括:
预处理单位时间内的短文本,获取所述短文本的数据集合信息;
从所述数据集合信息中抽取出现在同一个短文本中的单词,将所述单词组合为所述共现词对;
将所述共现词对整合为一个全局级别的所述词组集合。
进一步地,所述根据语义相似度和历史共现度对所述词组集合进行关联,获取所述词组集合的动态关联度,并以词组矩阵形式存储所述动态关联度;包括:
通过相似度模型训练所述词组集合获取词嵌入向量,使用余弦相似度计算所述词组集合对词嵌入向量上的所述语义相似度,根据所述语义相似度生成词组矩阵;
对历史短文本中高度重要的共现词对进行关联,获取所述共现词对的历史共现度,量化所述历史共现度并动态更新所述词组矩阵,获取所述词组集合的动态关联度;
将所述动态关联度存储到所述词组矩阵中。
进一步地,所述从所述词组集合中抽取主题名称,并根据所述动态关联度修正所述主题名称;包括:
根据权重吉布斯采样算法对所述词组集合进行迭代,抽取和分配所述词组集合,推理得到所述短文本的主题名称;
根据所述动态关联度对所述主题名称进行修正,获取偏向和强调的所述主题名称。
另一方面,本发明实施例还提供了一种短文本主题分布的推理系统,包括:
词组集合模块,用于抽取单位时间内短文本中出现的共现词对,整合所述共现词对获取词组集合;
动态关联模块,用于根据语义相似度和历史共现度对所述词组集合进行关联,获取所述词组集合的动态关联度,并以词组矩阵形式存储所述动态关联度;
主题抽取模块,用于从所述词组集合中抽取主题名称,并根据所述动态关联度修正所述主题名称;
分布统计模块,用于统计修正后的所述短文本中主题名称,获取所述短文本的主题分布。
进一步地,所述词组集合模块包括词组整合单元,所述词组整合单元用于:
预处理单位时间内的短文本,获取所述短文本的数据集合信息;从所述数据集合信息中抽取出现在同一个短文本中的单词,将所述单词组合为所述共现词对;将所述共现词对整合为一个全局级别的所述词组集合。
进一步地,所述动态关联模块包括词组矩阵单元,所述词组矩阵单元用于:
通过相似度模型训练所述词组集合获取词嵌入向量,使用余弦相似度计算所述词组集合对词嵌入向量上的所述语义相似度,根据所述语义相似度生成词组矩阵;
对历史短文本中高度重要的共现词对进行关联,获取所述共现词对的历史共现度,量化所述历史共现度并动态更新所述词组矩阵,获取所述词组集合的动态关联度;
将所述动态关联度存储到所述词组矩阵中。
进一步地,所述主题抽取模块包括主题确定单元,所述主题确定单元用于:
根据权重吉布斯采样算法对所述词组集合进行迭代,抽取和分配所述词组集合,推理得到所述短文本的主题名称;
根据所述动态关联度对所述主题名称进行修正,获取偏向和强调的所述主题名称。
本发明实施例还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
抽取单位时间内短文本中出现的共现词对,整合所述共现词对获取词组集合;
根据语义相似度和历史共现度对所述词组集合进行关联,获取所述词组集合的动态关联度,并以词组矩阵形式存储所述动态关联度;
从所述词组集合中抽取主题名称,并根据所述动态关联度修正所述主题名称;
统计修正后的所述短文本中主题名称,获取所述短文本的主题分布。
本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
抽取单位时间内短文本中出现的共现词对,整合所述共现词对获取词组集合;
根据语义相似度和历史共现度对所述词组集合进行关联,获取所述词组集合的动态关联度,并以词组矩阵形式存储所述动态关联度;
从所述词组集合中抽取主题名称,并根据所述动态关联度修正所述主题名称;
统计修正后的所述短文本中主题名称,获取所述短文本的主题分布。
上述短文本主题分布的推理方法、系统、计算机设备和存储介质,所述方法中包括:抽取单位时间内短文本中出现的共现词对,整合所述共现词对获取词组集合;根据语义相似度和历史共现度对所述词组集合进行关联,获取所述词组集合的动态关联度,并以词组矩阵形式存储所述动态关联度;从所述词组集合中抽取主题名称,并根据所述动态关联度修正所述主题名称;统计修正后的所述短文本中主题名称,获取所述短文本的主题分布。通过该方法,通过设计的动态关联度这一指标,赋予了各个共现词对不同的重要性。动态关联度同时考虑到了单词的语义相似度和时间共现信息,能够体现出词对在不同时间段的重要性不同这一特点。此外,在进行主题名称的挖掘过程中,使得重要的词对的主题信息能够被强调,这说明该方法对主题名称的提取是一种具有偏向性的主题模型,从而能够抽取出更加连续紧凑的各种主题名称,更加准确的推理出各个短文本的主题分布。
附图说明
图1是本发明实施例提供的短文本主题分布的推理方法的流程示意图;
图2是本发明实施例提供的对共现词对进行整合的流程示意图;
图3是本发明实施例提供的获取动态关联度的流程示意图;
图4是本发明实施例提供的主题名称抽取的流程示意图;
图5是本发明实施例提供的短文本主题分布的推理系统的结构框图;
图6是本发明实施例提供的一种计算机设备的内部结构图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
主题模型是一类从文本数据中挖掘并抽取主题,同时获得单个文本的主题分布的无监督方法。在主题模型中,一个主题被表示为单词库上的一个概率分布,每个文本可以被表示为一个主题群上的概率分布。
在一个实施例中,如图1所示,提供了一种短文本主题分布的推理方法,以该方法为例进行说明,包括以下步骤:
步骤102,抽取单位时间内短文本中出现的共现词对,整合所述共现词对获取词组集合;
步骤104,根据语义相似度和历史共现度对所述词组集合进行关联,获取所述词组集合的动态关联度,并以词组矩阵形式存储所述动态关联度;
步骤106,从所述词组集合中抽取主题名称,并根据所述动态关联度修正所述主题名称;
步骤108,统计修正后的所述短文本中主题名称,获取所述短文本的主题分布。
具体地,该方法是一种面向短文本数据的主题模型,它具有优秀的短文本数据主题挖掘、抽取和分配的能力。首先通过建立共现词对,根据引入外部信息(语义信息和历史共现信息),并使用动态关联度来整合这些信息,进一步的使用动态关联度来指出各个共现词对的重要性,以此来指导主题模型的工作。在后续的主题抽取和分配过程中,重要的共现词对将会被赋予更多的注意力,最后生成的主题群和主题分布也会更加偏向于这些重要的共现词对所携带的主题信息。这样一种方法能够有效的缓解短文本数据中的稀疏性问题,抽取出连贯紧凑的主题群,合理准确的为每一个短文本推理主题分布。此外,通过设计的动态关联度这一指标,赋予了各个共现词对不同的重要性。动态关联度同时考虑到了单词的语义相似度和时间共现信息,能够体现出词对在不同时间段的重要性不同这一特点。此外,在进行主题名称的挖掘过程中,使得重要的词对的主题信息能够被强调,这说明该方法对主题名称的提取是一种具有偏向性的主题模型,从而能够抽取出更加连续紧凑的各种主题名称,更加准确的推理出各个短文本的主题分布。因为考虑到了数据的历史信息,所以,从大体上来说,该方法是将目标数据按照时间划分为多个不同时间段,对一个时间段内的短文本做主题挖掘的工作。能够串联各个时间段的便是绿色框中的词组矩阵。词组矩阵实际表示为一个矩阵,它记录了各个时间段内的共现词对的重要性。整个技术方案的框架在针对一个时间段内的短文本数据进行主题挖掘时,主要涉及到上述4个过程。
在一个实施例中,如图2所示,对共现词对进行整合的方法包括:
步骤202,预处理单位时间内的短文本,获取所述短文本的数据集合信息;
步骤204,从所述数据集合信息中抽取出现在同一个短文本中的单词,将所述单词组合为所述共现词对;
步骤206,将所述共现词对整合为一个全局级别的所述词组集合。
具体地,短文本数据不同于长文档,每一个短文本通常只包含数十个乃至于数个字词。当把短文本进行嵌入表示时,得到的向量只有少部分是具有信息的,即数据表示稀疏性。数据稀疏性导致短文本数据的主题挖掘抽取工作富有挑战性。不同于传统的建立在单个单词上的主题模型,对共现词对进行整合是对目标数据中的共现词对进行主题建模后提取和整合的。每一个共现词对是由两个出现在同一个短文本内的单词组成的。我们按照短文本为单位,抽取出所有的共现词对,并整合为一个全局级别的词组集合,后面的主题名称的抽取和挖掘工作将建立在这个词组集合上。
在一个实施例中,如图3所示,获取动态关联度的的过程,包括:
步骤302,通过相似度模型训练所述词组集合获取词嵌入向量,使用余弦相似度计算所述词组集合对词嵌入向量上的所述语义相似度,根据所述语义相似度生成词组矩阵;
步骤304,对历史短文本中高度重要的共现词对进行关联,获取所述共现词对的历史共现度,量化所述历史共现度并动态更新所述词组矩阵,获取所述词组集合的动态关联度;
步骤306,将所述动态关联度存储到所述词组矩阵中。
具体地,通过词组集合的语义相似度和历史共现程度,总结出动态关联度,并存储到词组矩阵中。具体而言,就是使用GloVe模型,从大量的外部语料中训练出词嵌入向量,这些向量很好的表征了单词之间的关联。使用余弦相似度计算出各个单词词对组合的向量上的相似度。这便是词组矩阵的基础值。我们还会总结之前时间段的数据中单词共现的情况。具体而言,就是之前的时间段中短文本同时高度重要的单词,我们认为它们是由关联的。我们量化他们的这种关联,并将其更新到词组矩阵中对应的元素中,以此实现了词组集合的重要程度,使得动态关联度随时间的动态更新。该过程是为了从外部语料和历史数据中获取词组集合在各个时间段的重要程度动态关联度,这些重要程度将会被用来指导后续的主题挖掘过程。
在一个实施例中,如图4所示,在词组集合中进行主题名称的抽取,包括:
步骤402,根据权重吉布斯采样算法对所述词组集合进行迭代,抽取和分配所述词组集合,推理得到所述短文本的主题名称;
步骤404,根据所述动态关联度对所述主题名称进行修正,获取偏向和强调的所述主题名称。
其中,采用权权重吉布斯采样(Weighted Gibbs Sampling)从预先准备的词组集合中进行主题抽取和分配,此间,还会涉及到使用事先获得的词组集合权重信息指导采样推理的步骤。具体而言,权权重吉布斯采样是一个全局的迭代算法。每一轮迭代,都会对词组集合中的一个共现词对进行主题的推理,这种推理是以词组集合中剩下的词组集合的主题分配情况为基础的。推理得到一个词组集合的主题名称之后,需要对这个主题名称的统计信息进行修正,而这个修正的因子就是词组集合的权重,也即动态关联度的值。通过这种带有权重的吉布斯采样,最后各个主题的统计信息将会出现偏向的情况,真正重要的主题将会得到强调。最后,使用各个主题下的统计信息,计算出各个主题,同时结合各个短文本内的词组集合,推理出各个短文本的主题分布情况。
应该理解的是,虽然上述流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,上述流程图中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
在一个实施例中,如图5所示,提供了短文本主题分布的推理系统,包括:词组集合模块502、动态关联模块504、主题抽取模块506、分布统计模块508,其中:
词组集合模块502,用于抽取单位时间内短文本中出现的共现词对,整合所述共现词对获取词组集合;
动态关联模块504,用于根据语义相似度和历史共现度对所述词组集合进行关联,获取所述词组集合的动态关联度,并以词组矩阵形式存储所述动态关联度;
主题抽取模块506,用于从所述词组集合中抽取主题名称,并根据所述动态关联度修正所述主题名称;
分布统计模块508,用于统计修正后的所述短文本中主题名称,获取所述短文本的主题分布。
在一个实施例中,如图5所示,词组集合模块502还包括:词组整合单元5022,所述词组整合单元5022用于:预处理单位时间内的短文本,获取所述短文本的数据集合信息;从所述数据集合信息中抽取出现在同一个短文本中的单词,将所述单词组合为所述共现词对;将所述共现词对整合为一个全局级别的所述词组集合。
在一个实施例中,如图5所示,动态关联模块504包括词组矩阵单元5042,所述词组矩阵单元5042用于:通过相似度模型训练所述词组集合获取词嵌入向量,使用余弦相似度计算所述词组集合对词嵌入向量上的所述语义相似度,根据所述语义相似度生成词组矩阵;对历史短文本中高度重要的共现词对进行关联,获取所述共现词对的历史共现度,量化所述历史共现度并动态更新所述词组矩阵,获取所述词组集合的动态关联度;将所述动态关联度存储到所述词组矩阵中。
在一个实施例中,如图5所示,主题抽取模块506包括主题确定单元5062,所述主题确定单元5062用于:根据权重吉布斯采样算法对所述词组集合进行迭代,抽取和分配所述词组集合,推理得到所述短文本的主题名称;根据所述动态关联度对所述主题名称进行修正,获取偏向和强调的所述主题名称。
图6示出了一个实施例中计算机设备的内部结构图。如图6所示,该计算机设备包括该计算机设备包括通过系统总线连接的处理器、存储器、网络接口、输入装置和显示屏。其中,存储器包括非易失性存储介质和内存储器。该计算机设备的非易失性存储介质存储有操作系统,还可存储有计算机程序,该计算机程序被处理器执行时,可使得处理器实现权限异常检测方法。该内存储器中也可储存有计算机程序,该计算机程序被处理器执行时,可使得处理器执行权限异常检测方法。计算机设备的显示屏可以是液晶显示屏或者电子墨水显示屏,计算机设备的输入装置可以是显示屏上覆盖的触摸层,也可以是计算机设备外壳上设置的按键、轨迹球或触控板,还可以是外接的键盘、触控板或鼠标等。
本领域技术人员可以理解,图6中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
在一个实施例中,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现以下步骤:抽取单位时间内短文本中出现的共现词对,整合所述共现词对获取词组集合;根据语义相似度和历史共现度对所述词组集合进行关联,获取所述词组集合的动态关联度,并以词组矩阵形式存储所述动态关联度;从所述词组集合中抽取主题名称,并根据所述动态关联度修正所述主题名称;统计修正后的所述短文本中主题名称,获取所述短文本的主题分布。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:预处理单位时间内的短文本,获取所述短文本的数据集合信息;从所述数据集合信息中抽取出现在同一个短文本中的单词,将所述单词组合为所述共现词对;将所述共现词对整合为一个全局级别的所述词组集合。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:通过相似度模型训练所述词组集合获取词嵌入向量,使用余弦相似度计算所述词组集合对词嵌入向量上的所述语义相似度,根据所述语义相似度生成词组矩阵;对历史短文本中高度重要的共现词对进行关联,获取所述共现词对的历史共现度,量化所述历史共现度并动态更新所述词组矩阵,获取所述词组集合的动态关联度;将所述动态关联度存储到所述词组矩阵中。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:根据权重吉布斯采样算法对所述词组集合进行迭代,抽取和分配所述词组集合,推理得到所述短文本的主题名称;根据所述动态关联度对所述主题名称进行修正,获取偏向和强调的所述主题名称。
在一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现以下步骤:抽取单位时间内短文本中出现的共现词对,整合所述共现词对获取词组集合;根据语义相似度和历史共现度对所述词组集合进行关联,获取所述词组集合的动态关联度,并以词组矩阵形式存储所述动态关联度;从所述词组集合中抽取主题名称,并根据所述动态关联度修正所述主题名称;统计修正后的所述短文本中主题名称,获取所述短文本的主题分布。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:预处理单位时间内的短文本,获取所述短文本的数据集合信息;从所述数据集合信息中抽取出现在同一个短文本中的单词,将所述单词组合为所述共现词对;将所述共现词对整合为一个全局级别的所述词组集合。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:通过相似度模型训练所述词组集合获取词嵌入向量,使用余弦相似度计算所述词组集合对词嵌入向量上的所述语义相似度,根据所述语义相似度生成词组矩阵;对历史短文本中高度重要的共现词对进行关联,获取所述共现词对的历史共现度,量化所述历史共现度并动态更新所述词组矩阵,获取所述词组集合的动态关联度;将所述动态关联度存储到所述词组矩阵中。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:根据权重吉布斯采样算法对所述词组集合进行迭代,抽取和分配所述词组集合,推理得到所述短文本的主题名称;根据所述动态关联度对所述主题名称进行修正,获取偏向和强调的所述主题名称。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 短文本主题分布的推理方法、系统、计算机设备和存储介质
- 推理系统、推理方法、电子设备及计算机存储介质