一种跨模态视觉与文本信息匹配方法和装置
文献发布时间:2023-06-19 13:49:36
技术领域
本发明涉及人工智能领域,尤其是涉及一种跨模态视觉与文本信息匹配方法和装置。
背景技术
跨模态数据匹配在许多商业应用中扮演者核心角色。例如视频检索技术需要系统对于查询的文字和所有的视频关键帧信息进行匹配,从而找到相关的视频帧。再例如视频自动生成技术中,需要根据文字的脚本,自动在视频库中找到相关的素材,然后再由视频生成软件将这些素材组合为最终产品。再例如,智能办公场景中,当PPT的文字内容被制作完毕后,需要通过跨模态匹配技术,自动从图库中给标题等关键文字进行配图。因此,提高跨模态视觉-文字匹配算法可以从底层提高上述和其他相关应用的性能,产生更大的商业价值。
发明内容
本发明主要是提供一种跨模态视觉与文本信息匹配方法和装置,具有较高的匹配准确度。
本发明针对上述技术问题主要是通过下述技术方案得以解决的:一种跨模态视觉与文本信息匹配方法,包括以下步骤:
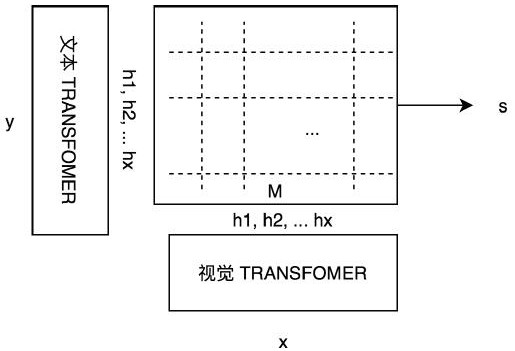
S1、通过目标识别系统检测出图片中重要物体场景的区块,区块总数量为X;
S2、将这些区块的视觉向量信息输入到TRANSFOMER模型中,构建这些区块之间的关系和综合信息,获得包含上下文的视觉向量信息h
S3、对于长度为Y文本信息,采用已经预训练的文本TRANSFOMER编码器模型进行编码,获得每个单词的上下文嵌入向量h
S4、用dot product(向量点积)对于所有的h
S5、对于矩阵的x轴(行)和y轴(列)分别取出每一列和每一行的最大分数,一共获得X+Y个分数,这些分数表示为g,通过g′=log ReLU(g)对被取出的分数进行非线性变换;
S6、计算最终得分s即为匹配度,最终得分s为所有g′的平均数。
作为优选,跨模态视觉与文本信息匹配方法还包括训练过程,训练过程如下:
训练数据的采集:首先采集配对的图片和文字信息;
损失函数和训练:在给定上述模型和数据后,使用mini-batch的方式进行训练,训练损失函数为交叉熵损失函数,人工标注的文字作为正确答案,而同一个mini-batch中其他的文字信息作为错误答案,交叉熵损失函数为:
式中,A是一个mini-batch中文本的数量,g是计算得到的分数,e是自然常数。
一种跨模态视觉与文本信息匹配装置,包括:
视觉TRANSFOMER编码器:此模块可以分为两大部分,第一步通过成熟的目标识别系统检测出图片中重要物体场景的区块,区块总数为X,将这些区块的视觉向量信息输入到TRANSFOMER模型中,从而构建这些区块之间的关系和综合信息,获得包含上下文的视觉向量信息h
文本TRANSFOMER编码器:对于长度为Y文本信息,采用已经预训练的文本TRANSFOMER编码器模型进行编码,获得每个单词的上下文嵌入向量h
匹配算分模型:给定h
首先,用dot product对于所有的h
作为优选,装置的模型训练按如下方式进行:
训练数据的采集:首先采集配对的图片和文字信息;
损失函数和训练:在给定上述模型和数据后,使用mini-batch的方式进行训练,训练损失函数为交叉熵损失函数,人工标注的文字作为正确答案,而同一个mini-batch中其他的文字信息作为错误答案,交叉熵损失函数为:
式中,A是一个mini-batch中文本的数量,g是计算得到的分数,e是自然常数。
本发明带来的实质性效果是,具有较高的准确度,为后续的应用提供基础。
附图说明
图1是本发明的一种跨模态匹配神经网络模型架构示意图。
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
实施例:本方案提出了一种新颖的基于神经网络的跨模态信息匹配技术。通过对于图片细节区域和每个文字进行细颗粒的匹配计算高效的匹配分数。整体架构如图1所示,包括:
1.视觉TRANSFOMER编码器:此模块可以分为两大部分。第一步通过成熟的目标识别系统(例如FasterRCNN,Yolov等)检测出图片中重要物体场景的区块。假设一共有X个区块,这些区块的视觉向量信息将被输入到TRANSFOMER中,从而构建这些区块之间的关系和综合信息,获得包含上下文的视觉向量信息h
2.文本TRANSFOMER编码器:对于长度为Y文本信息,我们采用已经预训练的文本TRANSFOMER编码器(例如BERT,ROBERTA)等模型进行编码,获得每个单词的上下文嵌入向量h
3.匹配算分模型:给定h
首先,我们先用dot product对于所有的h
通过SGD来训练上述模型。具体来说,训练分为两部分:
训练数据的采集:首先需要采集配对的图片和文字信息。数据采集可以通过爬取网络上的图片和相关的文字标题获得。或者也可以通过人工标注的方式,对于一个图库通过看图写话的方式进行文字标注,让每一个图片都有对应的文字描述信息。
损失函数和训练:在给定上述模型和数据后,我们使用mini-batch的方式进行训练。训练损失函数为常规的交叉熵损失函数。人工标注的文字作为正确答案,而同一个mini-batch中其他的文字信息作为错误答案。
在模型训练完成之后,利用它对于任意图片和文字的输入进行匹配计算,分数越大代表他们的匹配度越高。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
尽管本文较多地使用了编码器、损失函数等术语,但并不排除使用其它术语的可能性。使用这些术语仅仅是为了更方便地描述和解释本发明的本质;把它们解释成任何一种附加的限制都是与本发明精神相违背的。
- 一种跨模态视觉与文本信息匹配方法和装置
- 一种数据检索方法、跨模态数据匹配模型处理方法和装置