基于格基约减的JPEG图像压缩色彩空间估计方法
文献发布时间:2024-04-18 19:52:40
技术领域
本发明提出了一种基于格基约减的JPEG图像压缩色彩空间估计方法,属于图像压缩技术领域。
背景技术
在JPEG压缩过程中,给定一个在压缩色彩空间中被量化的彩色图像,JPEG图像压缩色彩空间估计就是从该图像中估计未知的压缩色彩空间。假设该图像初始时在某个未知色彩空间PQR中,经过JPEG压缩,到了某个任意的色彩空间ABC中,我们需要估计PQR色彩空间与ABC色彩空间之间的线性变换。这些知识对于彩色图像增强和JPEG再压缩有重要作用。
本发明使用强化学习优化了图像压缩色彩空间估计步骤中的LLL算法,LLL算法是一个经典的格基约减算法,LLL算法中涉及到向量的排序问题,本发明用强化学习来对其进行优化,在原LLL算法中,不满足Lovász条件时会简单交换两个相邻的向量,而优化过后的算法会将前一个向量继续后移到合适的位置,实验表明,本发明可以减少算法的执行轮次,提高算法的运行效率并提高算法的准确性。
发明内容
针对上述问题,本发明的目的在于提供一种基于格基约减的JPEG图像压缩色彩空间估计方法,相比传统的LLL算法,经过强化学习优化的LLL算法能够有效提高算法的运行效率和准确性。
为了达到上述目标,本发明提供了一种基于格基约减的JPEG图像压缩色彩空间估计方法,包括以下步骤:
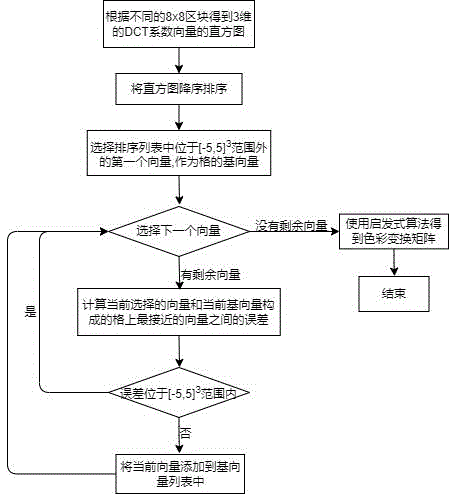
S1.选择一个彩色图像并进行DCT变换;
S2.选择一个DCT频率,根据不同的8x8区块得到3维的DCT系数向量的直方图,每个像素点对应的是一个3维向量,以表示任意颜色的一个像素点;
S3.将步骤S2中得到的直方图进行降序排序;
S4.选择排序列表中位于
S5.选择下一个向量,如果列表中没有剩余的向量,则退出;
S6.计算当前选择的向量和当前基向量构成的格上最接近的向量之间的误差,使用格基约减算法求解;
S7.对步骤S6中计算的误差向量进行评估,如果计算的误差向量位于
S8.得到两个从不同DCT频率中估计的基向量
进一步的,步骤S2中涉及到离散余弦DCT变换,即用64个基本余弦波组合成8*8的区块,通过给出单个基础余弦波都要去乘的一个值,来表示该基础余弦波的使用量,原本的8*8矩阵变为表示每个余弦波对应的系数的矩阵,这些系数就是DCT频率。
进一步的,步骤S6中要求的误差是最近向量问题CVP,具体包括:
S61.给定一组基向量
S62.使用强化学习优化过的LLL算法,将输入的基向量A输出为LLL约减基
S63.使用Babai算法,将输入的
S64.求误差向量
进一步的,步骤S62中的LLL约减基
进一步的,步骤S62中的LLL算法将所述矩阵A看作n个m维向量(
进一步的,步骤S62具体为:
S621.对第k个向量
S622.对第k-1、k个向量
S623.若满足性质(2),则继续向后判断后面的向量是否满足,即回到步骤S621;
S624.向量
S625.根据前面已经正确排序的向量,使用强化学习判断向量
S626.在强化学习中,做动作或决策的主体称为智能体,状态是对当前环境的概括,动作是智能体基于当前状态所作出的决策,奖励是智能体执行一个动作后,环境返回给智能体的一个数值,强化学习主要的学习过程是根据环境的反馈不断调整训练智能体,通过与环境的不断交互、试错,最终达到特定目标或使整体行动效益最大化。将状态设置为两个向量之间的长度平方差,动作设置为向量向后换几个,奖励根据前面正确排序的向量设定;
S627.根据前面正确排序的向量,当状态为s时,对应的动作为a,则将动作为s时采取动作a的奖励加1,如果有k组状态为s、动作为a的向量,则将动作为s时采取动作a的奖励加k;
S628.所述动作为随即动作,如果所有动作对应的奖励值都为0,则也是随机选择动作,否则选择最大奖励值对应的动作,若有多个动作的奖励值为最大奖励值,则对这些动作取平均;
S629.当向量
进一步的,步骤S63中,所述近似向量
进一步的,步骤S7中对基向量执行的格基约减算法仍是经过强化学习优化的LLL算法。
相较于现有技术,本发明的有益效果如下:可以减少算法的执行轮次,提高算法的运行效率和准确性,并且强化学习对LLL算法的优化可以扩展应用到其它格基约减算法中,为解决LWE问题提供新的思路。
附图说明
图1为一种基于格基约减的JPEG图像压缩色彩空间估计方法的流程图。
图2为S52中使用强化学习优化的LLL算法的流程图。
图3为本发明强化学习优化后的算法与LLL算法的比较图。
具体实施方式
为了使本发明实施例的目标、技术方案和优势更为清晰,以下内容将借助于附图对本发明实施例的技术策略进行详尽、全面的阐述。显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。根据本发明实施例的描述,本领域中具备一定技术水平的人员可得出的所有其他实施例,都应视为本发明的保护范围所涵盖。
如图1至图2所示,本发明提出了一种基于格基约减的JPEG图像压缩色彩空间估计方法,通过使用强化学习对LLL算法中的交换步做优化,有效地减少了原LLL算法的执行轮次,提高了用LLL算法解决JPEG图像压缩色彩空间估计问题的效率和准确性,具有较好的使用价值,主要包括以下步骤:
S1.选择一个彩色图像并进行DCT变换;
S2.选择一个DCT频率,根据不同的8x8区块得到3维的DCT系数向量的直方图,每个像素点对应的是一个3维向量,因为有3个色彩空间,就可以通过给这些色彩空间加上系数来组成任意颜色,所以一个三维向量可以表示任意颜色的一个像素点。
S3.将步骤S2中得到的直方图降序排序。
S4.选择排序列表中位于
S5.选择下一个向量,如果列表中没有剩余的向量,则退出。
S6.计算当前选择的向量和当前基向量构成的格上最接近的向量之间的误差,使用格基约减算法求解。
S7.对步骤S6中计算的误差向量进行评估,如果计算的误差向量位于
S8.得到两个从不同DCT频率中估计的基向量
以下将对步骤S2-S6进行具体说明。
步骤S2中,涉及到离散余弦变换DCT变换,即用64个基本余弦波组合成8*8的区块,通过给出单个基础余弦波都要去乘的一个值,来表示该基础余弦波的使用量是多少,原本的8*8矩阵变为表示每个余弦波对应的系数的矩阵,这些系数就是DCT频率。
步骤S3中,将步骤S2中得到的直方图降序排序,这确保了格基约减算法以最小噪声向量启动。
步骤S4中,若向量中所有元素都在[-5,5]范围内,则将该向量视为原点的噪声实现形式,因此只有在该范围外的向量才会加入到基向量中。
步骤S5中,当排序列表中没有剩余的向量,则进入该发明的最后一步,即根据不同的DCT频率估计的基向量组来推算出色彩变换矩阵。
步骤S6中,所求误差相当于求解一个最近向量问题CVP,具体包括:
S61.CVP问题描述如下:给定一组基向量
S62.使用强化学习优化过的LLL算法,将输入的基向量A输出为LLL约减基
S63.使用Babai算法,将输入的
S64.求误差向量
步骤S62中,格基约减的主要目的是将一组任意给定的基转换为一组正交性较好的基,且各个向量尽可能短,LLL约减基需要满足两个性质,(1)对于任意的
步骤S62具体包括:
S621.对第k个向量
S622.对第k-1、k个向量
S623.若满足性质(2),则继续向后判断后面的向量是否满足,即回到步骤S621;
S624.向量
S625.根据前面已经正确排序的向量,使用强化学习判断向量
S626.在强化学习中,做动作或决策的主体称为智能体,状态是对当前环境的概括,动作是智能体基于当前状态所作出的决策,奖励是智能体执行一个动作后,环境返回给智能体的一个数值。强化学习主要的学习过程是根据环境的反馈不断调整训练智能体,通过与环境的不断交互、试错,最终达到特定目标或使整体行动效益最大化。将状态设置为两个向量之间的长度平方差,动作设置为向量向后换几个,奖励根据前面正确排序的向量设定;
S627. 根据前面正确排序的向量,当状态为s时,对应的动作为a,则将动作为s时采取动作a的奖励加1,如果有k组状态为s、动作为a的向量,则将动作为s时采取动作a的奖励加k,例如,若3个向量的两两组合(
S628.在选择动作时,有一定的概率随机选择动作,以此来保证智能体有机会发现新的交换方法。如果所有动作对应的奖励值都为0,则也是随机选择动作,否则选择最大奖励值对应的动作,若有多个动作的奖励值为最大奖励值,则对这些动作取平均;
S629.向量
步骤S63中,Babai算法是一种基于格的近似算法,它可以用来解决appr-CVP问题,其基本思想是将输入向量投影到格的基向量上,然后通过对投影向量进行舍入得到一个近似的最近向量。输入是基向量和目标向量,输出是距目标向量最近的格向量。具体的,输入
伪代码如下所示:
步骤S7中,如果步骤S6计算的误差向量位于
步骤S8中,通过对
相关术语解释:
施密特正交化:一种将一组线性无关的向量转换为一组正交向量的方法,过程如下:
,/>
,/>
,/>
,/>
……
其中,
以下将结合具体实例进行说明。
这里讨论的实际问题设置为:假设从色彩空间ITU.BT-601 YCbCr转换到色彩空间RGB,实际上的色彩转换矩阵
S1.选择一个彩色图像并进行DCT变换;
S2.将经过JPEG压缩的图片分为若干个8*8大小的区块,每个区块的每个像素点都可以表示为一个三维向量,根据这些向量得到三维直方图;
S3.将步骤S2中得到的直方图降序排序,方便接下来的步骤按顺序选择向量;
S4.选择排序列表中位于
S5.按照步骤S3中排列的顺序选择下一个向量,如果列表中没有剩余的向量,则退出;
S6.计算当前选择的向量和当前基向量构成的格上最接近的向量之间的误差,使用的是强化学习优化过的LLL算法和Babai算法。
首先使用强化学习优化过的LLL算法,将输入的基向量A输出为LLL约减基
由于初始的A矩阵在格基约减中是不好的基,所以需要将它转换为好的基,即既正交又较短的基。LLL算法就是这样的一种格基约减算法,本发明使用强化学习对其进行优化。
初始时,k设为2,对第2个向量
当前面符合Lovász条件的序列有两个及两个以上向量时,可以根据该序列对奖励做更新。当状态s对应的动作为a时,则将其对应的奖励加1,如果状态s有k个对应的动作为a,则将其对应的奖励加k。例如,当
在选择动作时,有一定的概率随机选择动作,以此来保证智能体有机会发现新的交换方法。如果所有动作对应的奖励值都为0,则也是随机选择动作,否则选择最大奖励值对应的动作,若有多个动作的奖励值为最大奖励值,则对这些动作取平均。例如,如果向后换2个向量、向后换5个向量、向后换10个向量都对应着最大奖赏值,则向后交换的向量个数为
当循环来到序列结尾,说明整个向量序列满足Lovász条件,这时就有一个任意的基转变为LLL约减基。
如图3所示,将本发明使用的方法和原LLL算法进行对比,可以看到,算法的执行轮次有明显减少。
这时,已经通过格基约减算法得到一组较好的基,将得到的A_LLL约减基和目标向量b输入到Babai算法中,将b向量投影到LLL约减基代表的各个基向量上,对投影向量做四舍五入,得到近似的格向量b’。具体执行步骤依据如下伪代码。
S7.如果步骤S6计算的误差向量位于
S8.经过上述步骤,得到两个基向量组,表示成矩阵的形式为
最后需要特别指出:上述实施例只是用来阐述本发明的技术方案,并不对其加以限制。在不偏离本发明设计理念的基础上,本领域技术人员对本发明的技术方案所进行的各种调整和改进,都应纳入本发明的保护范围。