基于交互注意力机制的多级声学信息的语音情感识别方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及计算机语音识别技术领域,具体为一种基于交互注意力机制的多级声学信息的语音情感识别方法。
背景技术
语音情感的应用广泛,可以帮助人类去判断因情感所导致的不必要风险的发生;近年来,随着工作的压力增大,抑郁症成为越来越值得关注的病症。语音情感识别旨在通过情感识别,分析用户现有的情感,一旦发现抑郁症相关的情感时,及时介入,达到预防的目的。此外,还有更多的研究者会在语音情感与其他的方面,比如文字、视频等进行融合,以得到应用。但是,目前更多的研究专注于多模态情感识别,这就必须有一个文本或视频的输入,会使得语音情感识别变得更为复杂。语音中包含音色、音调、音素等多方面的特征,通过对以上信息的整合,对语音进行单模态识别,亦是一种有效的获取语音情感信息的方法。
随着人工智能和机器学习技术的不断发展,越来越多的研究者开始关注语音情感识别领域的研究。在传统的语音情感识别中,判别性特征的提取已经成为了一个非常重要的研究方向。然而,在情感特征提取过程中,存在一些不相关的噪声,这些噪声可能存在多种来源,如背景噪声、说话人的呼吸声等。这些不相关的因素会使提取的特征包含这些因素的变化,从而影响情感分类的效果。研究表明可以通过机器学习的语音情感识别模型达到良好的效果。
目前,将语音识别和语音情感识别相结合的场景有很多,这些应用场景包括客服、语音助手,亦可以帮助管理员做作业的安全管控等措施。但目前更多的技术聚焦于多模态的研究,即需要文字或视频作为输入一同与语音进行识别,这样会造成对语音识别时的复杂化以及资源的浪费,降低识别性能。
发明内容
针对现有技术的不足,本发明提出了一种基于交互注意力机制的多级声学信息的语音情感识别方法,通过多级声学信息的综合利用和交互式注意力机制的引入,提高了语音情感识别的性能,使其在实际应用中更加有效和可靠。
本发明为解决其技术问题所采用的技术方案是:
一种基于交互注意力机制的多级声学信息的语音情感识别方法,步骤包括:
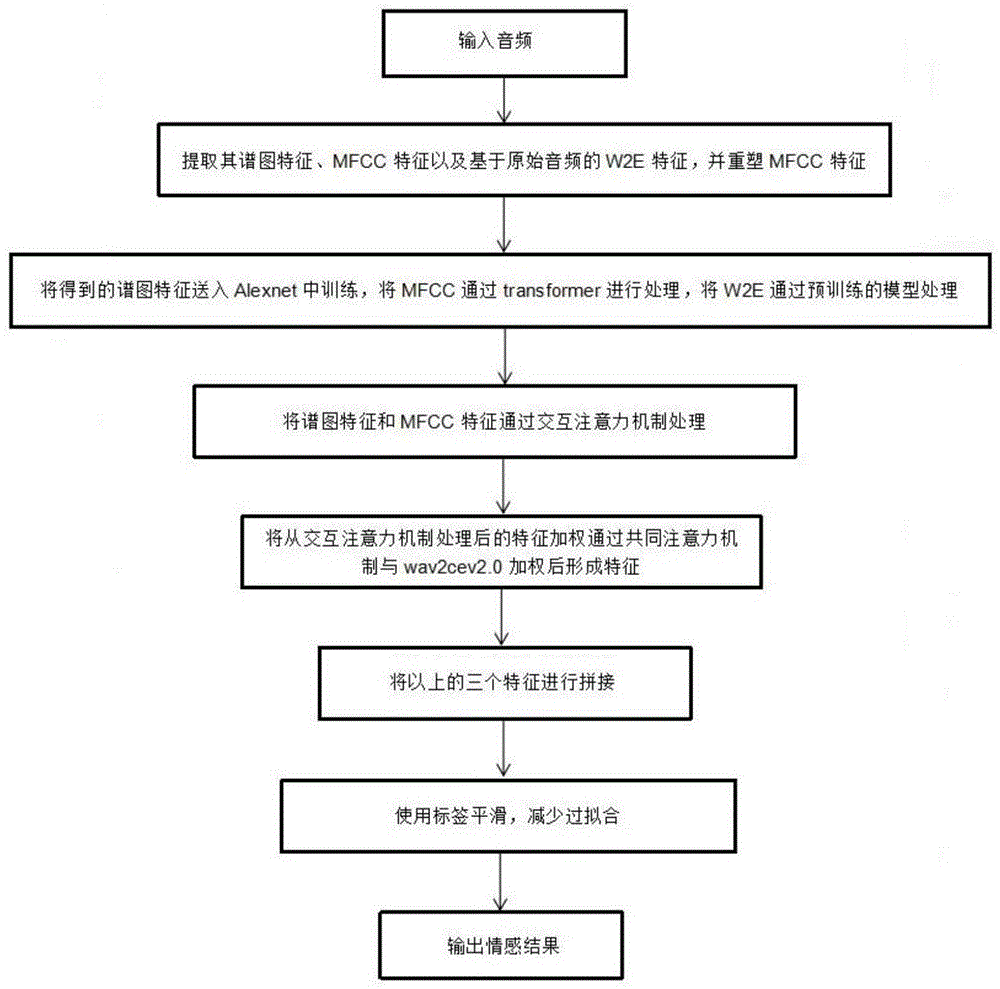
S1、将语音情感数据集区分训练集与测试集,并对训练集和测试集进行特征提取,所述特征包括基于卷积神经网络CNN的谱图特征、梅尔频率倒谱系数MFCC特征和高级声学信息W2E特征;
S2、设计包含Transformer模块和交互式注意力机制模块的用于多级声学信息的网络模型;对提取的谱图特征、MFCC特征和W2E特征进行特征处理;
S3、将特征处理后的谱图特征、MFCC特征输入至交互式注意力机制模块进行融合处理;
S4、将交互式注意力机制模块输出的处理后的谱图特征和MFCC特征与特征提取的W2E特征加权,并通过共同注意力机制模块形成最终的wav2vec2.0特征;
S5、将步骤S2得到的经过网络处理后的谱图特征、MFCC特征以及步骤S4得到的最终的wav2vec2.0特征进行拼接处理,形成最终的网络模型;
S6、利用训练集对步骤S5形成的最终的网络模型进行训练;
S7、利用测试集对步骤S6训练后的网络模型进行调整;
S8、将待识别的音频数据输入至步骤S7调整后的网络模型,对待识别的音频数据进行情感识别。
通过上述方法构建一个进行语音情感识别的网络模型,使用多级声学信息的融合处理识别,获取最终的情感,充分利用信息之间的相关性,从而提高任务的性能,交互式注意力机制的引入能够有效提高网络的特征表达能力,提高语音情感识别精度。
进一步的,步骤S1具体包括:
S11、将语音情感数据集按照十折交叉验证的方式区分训练集与测试集,将训练集与测试集中的音频等分为每段3秒的音频,不足3秒的音频进行填充处理;
S12、对每段音频通过卷积神经网络CNN提取其谱图特征;
S13、对每段音频提取其MFCC特征,并对提取后的MFCC特征进行张量重塑和排序;
S14、对每段音频提取其W2E特征。
通过上述方法可以将多级声学信息特征提取,提取后的特征以便送入网络中学习处理。十折交叉验证的方式可以增加数据的有效使用,每个样本都有机会出现在测试集和训练集中,有助于更全面地评估模型的性能;将音频等分为3秒的段落以及填充处理有助于使数据集更加均匀,避免数据不平衡问题。卷积神经网络(CNN)提取谱图特征,有助于捕捉音频中的频谱信息,包括声音的频率和强度分布,从而为情感识别提供更丰富的声学特征。MFCC特征提取对有助于捕捉音频的语音特征,张量重塑和排序可以将时间步和特征维度分开,有利于在不同的维度下独立地处理这些特征。提取W2E特征可以捕捉更高级的声学信息,有助于提高情感识别的性能,因为它可以包括音频中的语义和情感信息。这些细分步骤有助于准备丰富、均匀的声学特征数据,为后续的情感识别模型提供了更多有用的信息和更好的性能,提高情感识别系统的准确性和鲁棒性。
进一步的,步骤S2具体包括:
S21、对步骤S12中所提取的谱图特征通过Alexnet神经网络进行特征处理;
S22、对步骤S13中张量重塑和排序后的MFCC特征通过transformer模块进行特征处理;
S23、对步骤S14中所提取的W2E特征通过wav2vec2.0模型进行特征处理。
通过使用这些方法,可以对提取的信息进行进一步的处理和学习,从而能够从多级声学信息中学习和理解更复杂的特征,更好地理解声音的特性。通过AlexNet神经网络对谱图特征进行特征处理,可以进一步提取和加工谱图特征的抽象表达,有助于提高特征的表征能力和区分度,增强模型对谱图特征的理解。利用Transformer模块对MFCC特征进行处理,能够捕捉MFCC特征中的长期依赖关系和重要的时序信息。Transformer模块具有良好的序列建模能力,有助于更好地表示MFCC特征。通过wav2vec2.0模型对W2E特征进行处理,可以进一步提取高级声学信息,包括语义和情感特征,提高模型对语音信号的理解能力。通过不同的神经网络模型对各类声学特征进行特征处理,有助于提取更高层次的抽象特征,增强模型对不同特征的理解能力,从而提高情感识别模型的性能和准确度。这种细致的特征处理有助于使模型更具有表现力和泛化能力,使其更适用于多种情感识别任务。
进一步地,所述的MFCC特征进行张量重塑,具体为:
MFCC特征输入张量T
i′=i
j′=j
l′=(j-1)mod n+1
通过这个映射函数,将输入张量重新排列为新的张量,具体来说,新的张量中元素t′
通过以下方式计算:
t′
其中(i′,j′,k′,l′)=(i,j,k,l)。
进一步的,将张量重塑后形成的MFCC特征值,按照时间步维度和特征维度区分,重新排序,使网络模型在不同的维度上独立处理特征。
进一步的,步骤S3具体包括:
S31、交互式注意力机制模块通过其线性层将输入维度转换为目标维度;
S32、利用softmax函数将注意力分数转换为概率分布;
S33、将概率分布应用于输入。
通过使用这些方法,能够有效地调整输入的权重,使得模型能够动态地关注输入序列中不同部分的信息,从而提高了对关键特征的感知和利用能力,这种交互式注意力机制有助于改进模型的表达能力和整体性能。通过线性层将输入维度转换为目标维度,确保注意力机制模块能够处理输入的维度,使得输入能够有效地与后续处理步骤相结合;线性层可以映射输入特征到一个更有助于注意力计算的空间。通过softmax,将注意力分数映射到概率分布上,确保所有分数在0到1之间,且和为1,以便有效地表示相对权重,softmax函数强调了注意力机制中分数较高的部分,使得模型更专注于重要的输入信息。将概率分布应用于输入相当于对输入进行加权,更关注具有高概率的部分,有助于提高模型对关键信息的敏感性。将概率分布应用于输入,模型能够在整个输入序列上建立上下文关系,有助于更全面地理解和利用输入信息。
进一步的,所述的交互式注意力机制模块包含线性层、注意力层、计算模块以及分数;在后续输入过程中通过加权相乘的方式进行使用;
首先,通过一个线性层将输入的维度从input_dim转换为attention_dim,这个线性层用
一个权重矩阵W和一个偏置向量b来表示;对于input_1,其线性变换表示为:
Z
其中,W的维度为(attention_dim,input_dim),b的维度为attention_dim;
同样地,对于input_2,其线性变换表示为:
Z
然后,将Z
z=[Z
其中,z的维度是2*attention_dim;
接下来,使用softmax函数将这些注意力分数z转换为概率分布p:
p=softmax(z)
softmax函数转换为概率分布,其计算公式为:
其中:x
最后,将概率分布p应用于输入:其中概率分布p包含两部分:p
Att
通过引入交互注意力机制,可以深度关注两个来自同一段语音的频域特征之间的关系,这种关注使得模型能够更好地理解和利用这些特征,从而在语音处理效果上实现显著提升。
进一步的,步骤S5中将拼接处理后的特征通过标签平滑机制形成最终的网络模型。
通过引入标签平滑机制,可以提高模型的泛化能力、鲁棒性,降低过拟合的风险,从而使最终的网络模型更适应于实际应用场景,并在各类别间保持了良好的平衡与稳定性。
本发明的有益效果包括:
综合特征提取:通过使用卷积神经网络(CNN)的谱图特征、梅尔频率倒谱系数(MFCC)特征和高级声学信息(W2E)特征,该方法能够综合不同类型的声学特征,提供更全面的情感信息。
交互式注意力机制:采用交互式注意力机制,能够有效地捕捉不同声学特征之间的关联和互动,从而提高情感识别的性能。
多级声学信息:通过设计包含Transformer模块的网络模型,能够处理多级声学信息,包括谱图特征、MFCC特征和W2E特征,使得模型更富有表现力。
共同注意力机制:引入共同注意力机制,有助于有效融合不同特征,并生成最终的高级声学信息W2E特征,提高了情感识别的准确性。
训练和调整:采用训练集对网络模型进行训练,并通过测试集进行调整,可以确保模型在不同数据集上的性能稳定和可靠。
情感识别性能:通过上述方法,最终的网络模型能够对待识别的音频数据进行情感识别,提供更准确的情感分类结果。
总的来说,这种方法通过多级声学信息的综合利用和交互式注意力机制的引入,提高了语音情感识别的性能,进一步提高了语音情感识别的准确率,使其在实际应用中更加有效和可靠。
附图说明
图1为本发明网络模型的训练流程图;
图2为本发明网络模型结构图;
图3为交互式注意力机制模块结构图;
图4为谱图特征、MFCC特征拼接过程示意图。
具体实施方式
为了使本申请所要解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本申请,并不用于限定本申请。
实施例1
本实施例在PyTorch框架中实现,采用了Adam优化算法,学习率为1e-5,训练批处理大小为32,并设置了early-stop为8。实验的硬件平台是NVIDIA 3090。
一种基于交互注意力机制的多级声学信息的语音情感识别方法,包括:
对语音情感数据集,按照十折交叉验证的方式区分训练集与测试集,并对训练集和测试集进行特征提取。
本实施例采用的是开源数据集IEMOCAP,交互式情绪二元运动捕捉(IEMOCAP)数据库是一个包含动作、多模式和多峰值的数据集,由南加州大学的Sail实验室近期收集。该数据库包含约12小时的视听数据,包括视频、语音、面部运动捕捉和文本转录。数据库由两个阶段组成,参与者进行即兴表演或脚本场景,特别是有选择地引出情感表达。IEMOCAP数据库被多个注释员注释为类别标签,如愤怒、快乐、悲伤、中立,以及维度标签,如配价、激活和支配。该数据库具有详细的动作捕捉信息、激发真实情感的互动设置,且其规模使它成为社区现有数据库的重要补充,有助于研究和建模多模态和表达性的人类交流。
同时,采用常采用的加权精度(WA)和未加权精度(UA)作为评价指标。
接着,对每段音频进行特征提取,具体操作如下:
将每段音频切分为3秒长短音频,不足3秒填充至3秒。
通过卷积神经网络CNN对原始音频进行特征提取,获得其谱图特征:
对原始音频进行分帧、预加重和加窗,来将原始的wav文件划分成固定长度的多个小片段;通过预加重来加强语音信号每一帧高频部分的信号,以提高其高频信号的分辨率;通过加窗操作使时域信号更好地满足快速傅里叶变换(FFT)的周期性要求,减少频率泄漏。
经过上述处理后,采用傅里叶变换将时域转换到频域,并通过功率谱,获得语音信号的谱线能量;基于以上的信息,即可提取mel刻度,计算mel滤波器组,来提取频带;以上步骤中计算的滤波器组系数是高度相关的,可以利用常见的离散余弦变换对滤波器组系数去处理得到MFCC。
为了更有效地处理数据,将梅尔频率倒谱系数MFCC进行张量重塑与排序,以将其时间步和特征维度分开。这种处理方式使得模型可以在不同的维度上独立地处理这些特征,从而更好地捕捉语音信号的特征和模式:
MFCC输入张量T
i′=i
j′=j
l′=(j-1)mod n+1
通过这个映射函数,可以将输入张量重新排列为新的张量。具体来说,新的张量中元素t′
t′
然后,提取原始音频W2E特征。
将谱图特征送入Alexnet进行处理,获得处理后的结果,谱图特征。
将处理后的MFCC送入transformer进行处理,获得处理后的结果,MFCC特征。
所述的交互式注意力机制模块包含线性层、注意力层、计算模块以及分数;在后续输入过程中通过加权相乘的方式进行使用:
首先,通过一个线性层将输入的维度从input_dim转换为attention_dim。这个线性层可以用一个权重矩阵W和一个偏置向量b来表示。对于input_1,其线性变换可以表示为:
Z
其中,W的维度为(attention_dim,input_dim),b的维度为attention_dim。
同样地,对于input_2,其线性变换可以表示为:
Z
然后,将Z
z=[Z
其中,z的维度是2*attention_dim。
接下来,使用softmax函数将这些注意力分数z转换为概率分布p:
p=softmax(z)
softmax函数可以转换为概率分布,其计算公式为:
最后,将概率分布应用于输入。这里,概率分布p包含两部分:p
Att
将W2E特征送入wav2vec2.0中进行特征提取。
将谱图特征和MFCC特征进行拼接,并与wav2vec2.0特征进行加权并通过共同注意力机制,形成最终的W2E特征。
将以上的三个特征进行拼接并经过标签平滑形成最终结果。
为了评估本发明的有效性,将本实施例与集中最先进的多任务语音情感识别方法进行识别准确度比较。本实验将这些模型在同一个数据集上进行测试,均使用公开的IEMOCAP数据集,具体的测试结果如下表:
实验结果表明,本发明的语音情感识别方法在单模态上具有更高的准确率。
以上所述实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解;其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围,均应包含在本申请的保护范围之内。
- 基于时隙采样的干扰和通信一体化波形生成方法
- 一种基于间歇采样的探测干扰一体化波形生成方法