一种基于爬虫采集的情感分类方法及系统
文献发布时间:2023-06-19 09:26:02
技术领域
本发明涉及文本信息分析技术领域,具体涉及一种基于爬虫采集的情感分类方法及系统。
背景技术
情感分析(Sentiment analysis),又称倾向性分析,意见抽取(Opinionextraction),意见挖掘(Opinion mining),情感挖掘(Sentiment mining),主观分析(Subjectivity analysis),它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。那么情感分类的主要方法有两种:基于词典的方法和基于ML的方法:基于词典的方法主要通过制定一系列的情感词典和规则,对文本进行拆句、分析及匹配词典(一般有词性分析,句法依存分析),计算情感值,最后通过情感值来作为文本的情感倾向判断的依据;基于ML方法就是将情感分类当做普通的分类问题。
现有的情感分类方法在使用过程中存在一定的不足:情感分类语言本身复杂,软硬件技术限制;无法很好地完成文本聚类、关键词提取、实体识别(对于一段文本中,可识别出文本中的主语内容以及主语内容在整个情感分类中的打分)等任务;而且使用上性能差、结构复杂。因此,提出一种基于爬虫采集的情感分类方法及系统。
发明内容
本发明所要解决的技术问题在于:如何解决现有情感分类方法中存在的分类语言复杂、受到软硬件技术限制、使用性能不够好的问题,提供了一种基于爬虫采集的情感分类方法。
本发明是通过以下技术方案解决上述技术问题的,本发明包括以下步骤:
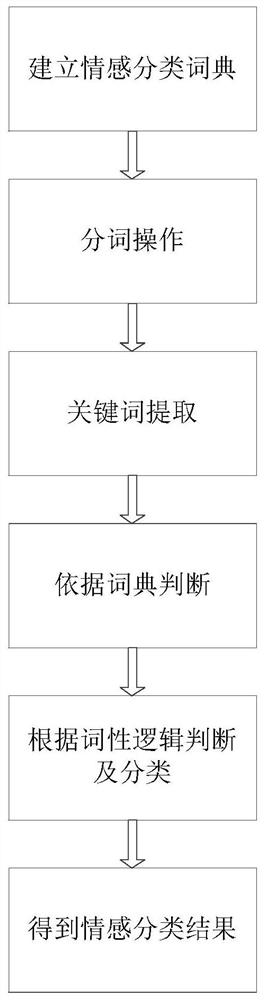
S1:建立情感分类词典
定义情感分类词典,词典中包括通用词语以及相应情感分数;
S2:分词操作
根据用户输入的句子,先通过结巴分词器进行分词,形成向量词组;
S3:关键词提取
对向量词组中的词提取相应的关键词,并统计该关键词在句子中的频率;
S4:依据词典判断
对向量词组里的词逐词进行判断,先根据词性判断属于积极还是消极,如果不属于词语,直接输出最终权值;
S5:根据词性逻辑判断及分类
如果词性类别属于积极,那么检查前后词语,如果前一词语为程度副词,则权值分加2,如果前一词语为否定词/消极词,则权值分减1;如果后一词语为消极词,则权值分减1;其他情况,权值分加1;如果词性类别属于消极,那么检查前一词语:如果前一词语为程度副词,则权值分减2;如果前一词语为否定词,则权值分加1;其他情况,权值分减1;
S6:得到情感分类结果
最后输出各词的最终权值,计算该句子的情感词得分,判断得到该句子的情感分类结果。
更进一步地,在所述步骤S1中,用户可根据需要选择是否在情感分类词典添加自定义词语。
更进一步地,在所述步骤S3中,统计关键词在句子中出现的频率的具体过程如下:
S31:获取关键词整体长度
获取关键词在整个句子中开始位置索引以及关键词自身的长度,从而获取到关键词占整个句子的长度;
S32:字符串截取
将步骤S31中获取到的关键词占整个句子的长度作为截取开头,将句子长度作为截取末端进行截取,将截取后的字符串赋值给原句子,截取成功一次,则统计一次该关键词在句子中出现的频率;
S33:循环遍历步骤S31、S32,直到原句子中不再包含关键词时,则停止统计,返回统计的频率数量。
更进一步地,在所述步骤S3中,提取关键词时,利用词频-逆向文件频率(TF-IDF)对停用词进行过滤,TF-IDF的表达式如下:
TF-IDF=TF*IDF
其中:
TF表示词在文档中出现的频率;
IDF表示词在文档中的分布状况。
更进一步地,停用词即在进行情感分类时不纳入最终的情感词得分的词;利用停用词可以过滤掉不必要的词,以免影响最终词性的情感打分。
更进一步地,在所述步骤S4中,积极或消极的词性判断根据该词语的情感分数的值进行,当该词语的情感分数大于0时,判断词性为积极;当该词语的情感分数小于0时,判断词性为消极,当该词语的情感分数等于0时,判断词性为中性。
更进一步地,在所述步骤S6中,所述情感词得分大于0时,则判断句子的情感分类结果为积极,所述情感词得分小于0时,则判断句子的情感分类结果为消极,所述情感词得分等于0时,则判断句子的情感分类结果为中性。
本发明还提供了一种基于爬虫采集的情感分类系统,用于利用上述的分类方法进行分类,包括:
词典建立模块,用于定义情感分类词典;
分词模块,用于根据用户输入的句子,先通过结巴分词器进行分词,形成向量词组;
关键词模块,用于对向量词组中的词提取相应的关键词,并统计该关键词在句子中的频率;
第一判断模块,用于依据词典对向量词组里的词逐词进行判断,先根据词性判断属于积极还是消极,如果不属于词语,直接输出最终权值;
第二判断模块,用于根据词性判断结果对词语的最终权值进行调整;
情感分类模块,用于根据最后输出各词的最终权值,计算该句子的情感词得分,判断得到该句子的情感分类结果;
中央处理模块,用于向各模块发出指令,完成相关动作;
所述词典建立模块、分词模块、关键词模块、第一判断模块、第二判断模块、情感分类模块均与中央处理模块电连接。
本发明相比现有技术具有以下优点:该基于爬虫采集的情感分类方法,本身语言环境简单,没有涉及过多复杂的语境,支持python、java语言开发,不受软硬件技术限制;相对其他方法而言可以很好的实现情感分析、信息分类、实体识别、文本聚类、关键词提取等功能;使用简单,开箱即用,只需简单部署即可上手使用,只需要将词典文件与程序文件放到同级目录下,直接用启动命令启动即可,值得被推广使用。
附图说明
图1是本发明实施例一种分类方法的流程示意图;
图2是本发明实施例二中分类方法的判断逻辑图;
图3是本发明实施例二中部分情感词典的示意图;
图4是本发明实施例二中部分停用词词典的示意图;
图5是本发明实施例三中情感分类方法的流程示意图;
图6是本发明实施例三中进行分词和词性标注的结果图;
图7是本发明实施例三中情绪分析的结果图;
图8是本发明实施例三中关键词提取的结果及提取思路实施过程示意图;
图9是本发明实施例三中词语联想的结果图;
图10是本发明实施例三中文本分析的流程图。
具体实施方式
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
实施例一
如图1所示,本实施例提供一种技术方案:一种基于爬虫采集的情感分类方法,包括以下步骤:
S1:建立情感分类词典
定义情感分类词典,词典中包括通用词语以及相应情感分数;
S2:分词操作
根据用户输入的句子,先通过结巴分词器进行分词,形成向量词组;
S3:关键词提取
对向量词组中的词提取相应的关键词,并统计该关键词在句子中的频率;
S4:依据词典判断
对向量词组里的词逐词进行判断,先根据词性判断属于积极还是消极,如果不属于词语,直接输出最终权值;
S5:根据词性逻辑判断及分类
如果词性类别属于积极,那么检查前后词语,如果前一词语为程度副词,则权值分加2,如果前一词语为否定词/消极词,则权值分减1;如果后一词语为消极词,则权值分减1;其他情况,权值分加1;如果词性类别属于消极,那么检查前一词语:如果前一词语为程度副词,则权值分减2;如果前一词语为否定词,则权值分加1;其他情况,权值分减1;
S6:得到情感分类结果
最后输出各词的最终权值,计算该句子的情感词得分,判断得到该句子的情感分类结果。
在所述步骤S1中,用户可根据需要选择是否在情感分类词典添加自定义词语。
在所述步骤S3中,统计关键词在句子中出现的频率的具体过程如下:
S31:获取关键词整体长度
获取关键词在整个句子中开始位置索引以及关键词自身的长度,从而获取到关键词占整个句子的长度;
S32:字符串截取
将步骤S31中获取到的关键词占整个句子的长度作为截取开头,将句子长度作为截取末端进行截取,将截取后的字符串赋值给原句子,截取成功一次,则统计一次该关键词在句子中出现的频率;
S33:循环遍历步骤S31、S32,直到原句子中不再包含关键词时,则停止统计,返回统计的频率数量。
在所述步骤S3中,提取关键词时,利用词频-逆向文件频率(TF-IDF)对停用词进行过滤,TF-IDF的表达式如下:
TF-IDF=TF*IDF
其中:
TF表示词在文档中出现的频率;
IDF表示词在文档中的分布状况。
停用词即在进行情感分类时不纳入最终的情感词得分的词,利用停用词可以过滤掉不必要的词,以免影响最终词性的情感打分;
在所述步骤S4中,积极或消极的词性判断根据该词语的情感分数的值进行,当该词语的情感分数大于0时,判断词性为积极;当该词语的情感分数小于0时,判断词性为消极,当该词语的情感分数等于0时,判断词性为中性。
在所述步骤S6中,所述情感词得分大于0时,则判断句子的情感分类结果为积极,所述情感词得分小于0时,则判断句子的情感分类结果为消极,所述情感词得分等于0时,则判断句子的情感分类结果为中性。
本实施例还提供了一种基于爬虫采集的情感分类系统,用于利用上述的分类方法进行分类,包括:
词典建立模块,用于定义情感分类词典;
分词模块,用于根据用户输入的句子,先通过结巴分词器进行分词,形成向量词组;
关键词模块,用于对向量词组中的词提取相应的关键词,并统计该关键词在句子中的频率;
第一判断模块,用于依据词典对向量词组里的词逐词进行判断,先根据词性判断属于积极还是消极,如果不属于词语,直接输出最终权值;
第二判断模块,用于根据词性判断结果对词语的最终权值进行调整;
情感分类模块,用于根据最后输出各词的最终权值,计算该句子的情感词得分,判断得到该句子的情感分类结果;
中央处理模块,用于向各模块发出指令,完成相关动作;
所述词典建立模块、分词模块、关键词模块、第一判断模块、第二判断模块、情感分类模块均与中央处理模块电连接。
实施例二
本方法采用的为最大边缘相关模型(MMR Maximal Marginal Relevance)的一个变种。MMR是无监督学习模型,它的提出是为了提高信息检索(Information Retrieval)系统的表现。相比于其他无监督学习方法,如TextRank(TR),PageRank(PR)等,MMR是考虑了信息的多样性来避免重复结果。而MMR方法可以较好地解决句子选择多样性的问题。
具体地说,在本方法的MMR模型中,同时将相关性和多样性进行衡量。因此,可以方便地调节相关性和多样性的权重,来满足偏向“需要相似的内容”或者偏向“需要不同方面的内容”的要求。对于相关性和多样性的具体评估,本方法是通过定义句子之间的语义相似度实现。句子相似度越高,则相关性越高而多样性越低。
自动摘要的核心便是要从原文句子中选一个句子集合,使得该集合在相关性与多样性的评测标准下,得分最高。数学表达式如下:
需要说明的是,上式中,D,Q,R,S都为句子集,其中,D表示当前文章,Q表示当前中心意思,R表示当前非摘要,S表示当前摘要。可以看出,在给定句子相似度的情况下,上述MMR的求解为一个标准的最优化问题。但是,上述无监督学习的MMR所得摘要准确性较低,因为全文的结构信息难以被建模,如段落首句应当有更高的权重等。
为了提高在新闻中自动摘要的表现,在模型中加入了全文结构特征,将MMR改为有监督学习方法。从而模型便可以通过训练从“标准摘要”中学习特征以提高准确性。
本方法采用摘要公认的Bi-gram ROUGE F1方法来判断自动生成的摘要和“标准摘要”的接近程度。经过训练,在训练数集上的表现相对于未学习的模型所得摘要结果有了明显的提升——训练后的摘要系统F1提高了30%。
本方法的判断逻辑图如图2所示,具体过程为:
1.根据用户输入的句子,先通过结巴分词器进行分词,形成向量词组;
2.对向量词组里的词逐词进行判断,先根据词性判断属于积极还是消极(根据词典中各词的情感分数的正负来判断各词的词性),如果不属于词语,直接输出最终权值;
3.如果词性类别属于积极,那么检查前后词语:如果前一词语为程度副词,则权值分加2;如果前一词语为否定词/消极词,则权值分减1;如果后一词语为消极词,则权值分减1;其他情况,权值分加1;
4.如果词性类别属于消极,那么检查前一词语:如果前一词语为程度副词,则权值分减2;如果前一词语为否定词,则权值分加1;其他情况,权值分减1(权值分的加减就是对词频数值的加减);
通过前述的积极词和消极词判断排除之后的词,就是中性词,中性词也是情感分类的一个类别,当该词语的情感分数等于0时,判断词性为中性。
5、最后输出各词的最终权值,计算该句子的情感词得分。
根据输出的最终权值判断词性的情感得分,如果分值大于0,表示情感倾向为积极的;如果小于0,则表示情感倾向为消极的。
本方法还提供了情感词典与停用词词典,情感词典部分如图3所示(详情见BosonNLP_sentiment_score.txt),在图中左侧为情感词语,右侧为相对应的情感分数。停用词词典部分如图4所示,图中的各符号在进行情感分类时不纳入最终的情感词得分,停用词即不充当词语进行情感分类的符号等。利用停用词词典可以过滤掉不必要的词,以免影响最终词性的情感打分。
本方法的功能介绍如下:
1.中文词性标注:中文词汇大致可以分为名词、动词、形容词、数词、量词、代词、介词、副词、连词、感叹词、助词和拟声词等。词性在语言识别、句法分析、信息抽取等任务中有重要作用。词性标注的难点是,具有两个或两个以上词性的词,即兼类词的问题。目前,针对兼类词的歧义排除经典算法有:基于规则的算法;基于概率统计模型的算法;规则和统计相结合的算法。兼类词歧义排除算法为现有的基于概率统计模型的算法。
2.关键词提取:关键词是一篇文档中表达的主要话题,指能够反映文本语料主题的词语或短语。在进行了关键词提取的时候,除了根据词频,我们会计算另一个值TF-IDF(词频-逆向文件频率),可以用来过滤。词频TF衡量了一个词在文档中出现的频率,越高表示词越重要。但要主要的是想要把一些停用词过滤掉,否则像“的”这样的词出现次数可能是最多的。
逆向文件频率IDF则表示词在文档中的分布状况,如果一个词集中出现在某些文档,则这个词比较重要。
TF*IDF值(TF与IDF之积,TF-IDF)越大,则表示这个词成为一个关键词的概率越大,当词语的TF*IDF值大于设置阈值时,提取为关键词。
实施例三
如图5所示,本实施例中情感分类方法的具体流程为:首先,需要对文本进行分句、分词;其次,将分词好的列表数据对应词典进行逐个匹配,并记录匹配到的情感词分值;最后,统计计算每句情感词分值总和,如果分值大于0,表示情感倾向为积极的;如果小于0,则表示情感倾向为消极的。
如图6所示,为本实施例中进行分词和词性标注的结果图,在图中,右侧为类别图示,根据不同程度的灰阶定义不同的词性类别,左侧根据具体的词性来标注词语。
如图7所示,为本实施例中情绪分析的结果图,在图中,指数在0~50之间判断为正面,指数在50~100之间判断为负面;
图7中的情感比例为举例,为实际的算法使用场景,45和90为实际的使用场景中的数量,比如正面评论的有45个,负面评论的有90个。
如图8a所示,为本实施例中关键词提取的结果图,关键词提取指的是从一段文本中提取到的关键词在该文本中出现的频率。
需要说明的是,该方法中会先将句子中提取出独立的、可用的关键词,然后再统计该关键词在句子中出现的频率。
如图8b所示,统计出现的频率具体实现思路如下:
(1)获取关键词整体长度:如图8c所示,获取关键词在整个句子中开始位置索引以及关键词自身的长度,从而可以获取到关键词占整个句子的长度;
(2)字符串截取:如图8d、8e所示,将上一步获取到的关键词占整个句子的长度作为截取开头,将句子长度作为截取末端进行截取,将截取后的字符串赋值给原句子,截取成功一次,则统计一次该关键词在句子中出现的频率;
(3)如图8f所示,循环遍历上面两个步骤,直到原句子中不再包含关键词时,则停止统计,返回统计的频率数量。
根据图示,所以“abc”这个关键词在原句中出现的次数为3次。
如图9所示,为对词语联想的结果图,图中左侧为对词联想得到的相关词,右侧为相关词与该词的相似度。对一个词语的语义联想功能,是可以通过一个词语联想到与当前词相近的词,从而实现对词典中没有的词但是相近的词不会影响到情感分类。
本方法还可以根据一端文本,提炼出新闻的摘要。
如图10所示,为本实施例中文本分析的流程图。
其中,文本挖掘的应用一般包括:
(1)文本分类,即在给定分类体系下,根据文本特征构建有监督机器学习模型,达到识别文本类型或内容主旨的目的。
(2)文本关联,是传统关联规则挖掘方法在文本特征上的直接应用,包含文档类型关联、词汇关联、实体关联等内容。
(3)情绪分析,包括识别文本隐含的主观内容、挖掘不同形态的观点信息,如:情绪、情感、语气、观点等,目前的文本分析技术可以细化到实体、概念、话题等级的情感分析。
(4)命名实体识别,即利用词典或统计方法识别命名的文本特征,如:人名、地名、组织机构、特定的缩写等。
(5)文本聚类,文本聚类就是从众多的文档中把一些内容相似的文档聚为一类的技术,同类的文本相似度较大,而不同类的文本相似度较小,是一种无监督的机器学习方法。
(6)关系识别,识别代指同一对象的不同词汇。
综上所述,上述实施例的基于爬虫采集的情感分类方法,本身语言环境简单,没有涉及过多复杂的语境,支持python、java语言开发,不受软硬件技术限制;相对其他方法而言可以很好的实现情感分析、信息分类、实体识别、文本聚类、关键词提取等功能;使用简单,开箱即用,只需简单部署即可上手使用,只需要将词典文件与程序文件放到同级目录下,直接用启动命令启动即可,值得被推广使用。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 一种基于爬虫采集的情感分类方法及系统
- 一种基于不平衡多源数据的情感分类方法及系统