一种复杂场景下的号服识别方法
文献发布时间:2023-06-19 09:27:35
技术领域
本发明属于视频检测技术领域,尤其是涉及一种复杂场景下的号服识别方法。
背景技术
随着技术的进步与发展,视频监控系统在公安系统内部各单位的应用越来越广泛,尤其是对在押人员的监管和监控,视频监控系统起着尤为重要的作用。监室内的特殊人员通常有特定的号服,通过识别号服实现对特殊人员识别与跟踪是一种有效地手段,但受限于号服的褶皱、变形以及部分遮挡等因素,号服识别的可靠性难以满足实际需求。
发明内容
有鉴于此,本发明旨在提出一种复杂场景下的号服识别方法,以解决背景技术中号服因褶皱、变形以及部分遮挡等因素,使得号服识别的可靠性难以满足实际需求。
为达到上述目的,本发明的技术方案是这样实现的:
一种复杂场景下的号服识别方法,包括以下步骤:
S1、为号服设计类间差异大、特征丰富的数字外形,并对数字外形进行编码;
S2、建立并训练针对号服数字外形识别用的深度学习模型;
S3、对待检测的号服图像进行预处理;
S4、将预处理后的号服图像输入号服识别用的深度学习模型进行检测,得到号服数字外形,即号服序列。
进一步的,所述步骤S2中建立并训练针对号服数字外形识别用的深度学习模型,需要先采集身穿号服的人体图像,对号服数字进行标注,即根据号服数字在图像中的位置,标出真实的位置坐标及数字类别。
进一步的,所述步骤S2中号服识别用的深度学习模型训练采用随机梯度下降法对模型进行反复迭代训练,使用的损失函数如下式:
其中,s为特征网格图的边长,i为第i个网格,B为匹配目标框的个数,j为第j个匹配目标框,
进一步的,所述步骤S3中对待检测的号服图像进行预处理的具体方法为:使用高斯滤波对待检测图像进行平滑去噪处理。
进一步的,所述步骤S4中的深度学习模型号服数字检测,利用步骤S2训练出的深度学习模型,在整幅图像上进行检测,记录检测到目标的位置和得分,若目标得分大于0.5则认为是有效目标。
进一步的,所述步骤S4中得到号服序列,包括如下步骤:
S401、阈值过滤:滤除得分较低的检测结果;
S402、号服数字聚堆:对号服有效数字进行聚堆;
S403、号服序列筛选;对聚堆的号服有效数字进行序列筛选。
进一步的,所述步骤S401中的阈值过滤,获取步骤2中检测得到的号服数字的具体位置与相应得分,得分最低为0,最高为1,滤除得分小于0.5的结果,留下正确的检测结果。
进一步的,所述步骤S402中的号服数字聚堆,通过对步骤S4中得到的每帧视频图像的有效数字进行检测,根据检测出的单个数字框间中心点的距离进行聚堆,设定聚堆的有效间距为0.5倍的数字矩形宽、高。
进一步的,所述步骤S403中的号服序列筛选,对满足步骤S402中设定聚堆的有效间距为0.5倍的数字矩形进行筛选,以获得最终的号服组合序列。
相对于现有技术,本发明所述的一种复杂场景下的号服识别方法具有以下优势:
(1)本发明所述的一种复杂场景下的号服识别方法可较大程度提高号服的识别精度;
(2)本发明所述的一种复杂场景下的号服识别方法可实现对特殊人员进行无感识别与跟踪,在公安监管领域具有广泛的应用价值。
附图说明
构成本发明的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明实施例所述的一种复杂场景下的号服识别方法的号服字体设计示意图;
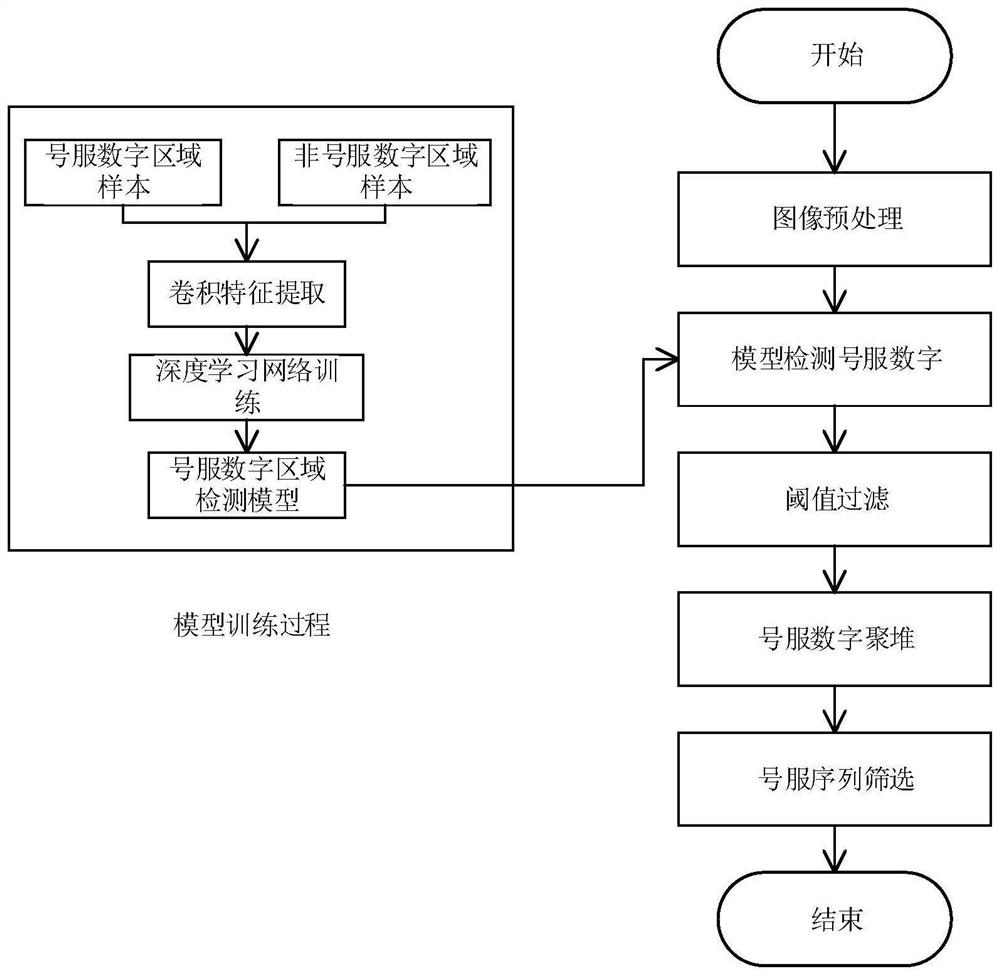
图2为本发明实施例所述的一种复杂场景下的号服识别方法的号服检测模型训练及检测流程示意图。
具体实施方式
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面将参考附图并结合实施例来详细说明本发明。
如图1、图2所示,一种复杂场景下的号服识别方法,包括以下步骤:
步骤一、设计易于识别的数字外形,进行号服编码。常规数字间差异较少,在褶皱或部分遮挡后容易造成歧义,导致识别错误,本方案通过构建了一套类间差异大,特征更丰富的数字外形,通过对数字进行编码,以提高号服的辨识度。
步骤二、深度学习模型训练。具体包括样本收集、数据增强、样本标注和darknet框架下得模型训练。其中,样本的收集需要覆盖应用场景下目标的各种可能的姿态和角度;样本收集完后对样本做图像增强,调整图像的亮度、角度、对比度等信息,增加样本的多样性,可以提高模型的鲁棒性;数据增强完成后,对样本中的数字进行标注,样本的标注要求所标注目标位置的准确性;标注完成后,在darknet框架下训练基于YOLO的数字检测模型。本发明中,获取号服数字区域样本和非号服数字区域样本,对样本进行卷积特征提取,对提取后的样本进行深度学习网络训练,建立号服数字区域检测模型。
步骤三、对视频图像进行预处理,去除图像噪点。图预处理是在检测前,对要处理的图像进行平滑去躁,以达到更好的检测效果;本发明中使用高斯滤波对图像进行预处理,能够有效的抑制噪声,平滑图像。
步骤四、深度学习模型号服数字检测。利用深度学习YOLO模型,对步骤二得到的图像进行检测,获得检测到号牌数字的位置相应的得分;本发明中,需要提前对检测模型进行训练,需要先采集身穿号服的人体图像,对号服数字进行标注,即根据号服数字在图像中的位置,标出真实的位置坐标及数字类别,采用随机梯度下降法对模型进行反复迭代训练,每次迭代使得损失函数更小,使用的损失函数如下式:
其中,s为特征网格图的边长,i为第i个网格,B为匹配目标框的个数,j为第j个匹配目标框,
最后用检测效果最好的YOLO模型对步骤二得到的图像进行检测,从而确定数字在图像中的具体位置。
步骤五、对步骤四中得到的检测结果进行后处理,滤除得分较低的检测结果;本发明中,获取步骤四中检测得到的号服数字的具体位置与相应得分,得分最低为0,最高为1,滤除得分小于0.5的结果,留下正确的检测结果。
步骤六、对步骤五中得到的每帧视频图像的有效数字进行聚堆,得到号牌的最终结果;本发明中,根据检测输出的单个数字框间中心点的距离进行聚堆,设定聚堆的有效间距为0.5倍的数字矩形宽、高,以获得最终的号服组合序列。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种复杂场景下的号服识别方法
- 一种适用于轨道沿线复杂场景下的杆号定位和识别方法