一种基于LSTM的冷链监测温湿度数据拟合方法
文献发布时间:2023-06-19 09:33:52
技术领域
本发明涉及了温湿度监测系统,具体的是一种基于LSTM的冷链监测温湿度数据拟合方法。
背景技术
温湿度监测系统是为了维护仓储商品的质量完好,创造适宜于商品储存的环境,当库内温湿度适宜商品储存时,就要设法防止库外气候对库内的不利影响;当监控到库内温湿度不适宜商品储存时,就要及时采取有效措施调节库内的温湿度。因此,建立实时的温湿度监控系统,保存完整的历史温度数据都已经进入了行业规范。然而,目前的监测仪器普遍存在记录值丢失的现象,完整的监测数据对于分析研究是必不可少的,因此对于监测缺失记录补全的研究也就提上了日程。
缺失值的填补方法众多,概括有:删除法(Deletion)、加权调整法(Weighting)、填补法。删除法与加权调整法都比较简单易行,但是代价是这两种方法给出的填补值信息量较少,偏离真值。填补法是对各种填补措施的概括,常见的填补方法有替代法和建模估计法。回归填补法、热平台填补法和冷平台填补法以及多重填充法。研究的比较多的多重填充法有以下几种:PMM法(Predictive Mean Matching,PMM)、趋势得分法(Propensity Score,PS)、马尔科夫链蒙特卡罗法(Markov Chain Monte Carlo,MCMC)。目前应用于时间序列的新插值方法主要有:抛物线法、牛顿法、分段法等。这些方法直接应用于时间序列数据时存在以下的问题:①多数缺失值填补方法并不是针对时间序列数据设计的,很多方法在应用于时间序列数据研究时受到限制,难以进行。②缺失值的填补方法一般通过简单的替代和删除获得新的样本,但是由于时间的不可逆性导致每个时间点的测量值的不可重现性,致使这种思路在时间序列中是行不通的。③各种缺失值的填补方法对连续型缺失的耐受性比较差;随机型缺失在达到30%以上时一般的填补方法效果不佳。
发明内容
为了克服现有技术中的至少部分缺陷,本发明实施例提供了一种基于LSTM的冷链监测温湿度数据拟合方法,能够对缺失的数据进行预测,并将预测的数据填补到原始数据中。
本申请实施例公开了:一种基于LSTM的冷链监测温湿度数据拟合方法,包括以下步骤:
数据采集,监测站点获取实时周期性测点数据;
数据预处理,将实时周期性测点数据转化时序数据,
构建模型并训练,将经过预处理的数据作为训练数据集,输入LSTM神经网络模型,对LSTM神经网络模型进行训练,获得训练好的预测模型;
缺失值自动填补,将需要修补的原始数据输入到预测模型,预测模型通过测点时间间隔异常值找到需要缺失值,预测并自动输出修补好的温湿度监测数据。
进一步地,所述LSTM模型,包括输入层、输出层和隐藏层,其中:
所述输入层用于对原始的温湿度数据进行结构调整以满足训练要求;
所述隐藏层用于使用了LSTM结构用于提取不同层面输入数据的特征;
所述输出层用于提供温湿度预测的结果。
进一步地,所述LSTM结构,由输入门、遗忘门、输出门,记忆单元组成,其中:
所述输入门用于在产生新记忆之前,判定一下当前看到的信息更新多少;
所述遗忘门用于根据过去记忆单元对当前记忆单元的计算是否有用进行信息筛选;
所述记忆单元用于记录到当前时刻为止的所有历史信息;
输出门用于从隐层状态分离最终的记忆。
进一步地,所述构建模型并训练还包括:
S1、定义初始的温湿度时间序列数据:
a=(a1,a2,…,an),
其中a1=(a11,a12),a11代表温度数据,a12代表湿度数据,
然后,按照9∶1的比例划分的训练集和测试集,
atr=(a1,a2,…,am),
ate=(am+1,am+2,…,an),
其中,atr为训练集,ate为测试集,满足约束条件m<n和m,n∈N;
S2、对训练集中的进行标标准化处理,采用经典的min-max标准化公式,标准化后的训练集a
a
a
a
其中:1≤t≤m,t∈N;
S3、构建短时间输入序列使其适应隐藏层的特点,通过固定步长来确定时间序列的长度,并对atr'进行处理,设固定步长取值为L,则模型输入为:
X=(X1,X2,…,Xm-L),
Xf=(af',af+1',…,af+L-1'),
满足:1≤f≤m-L,f&L∈N;
S4、将X输入隐藏层,隐藏层由m-L个LSTM结构组成,每个LSTM结构内含L个LSTM单元,其工作原理是根据L个输入数据预测第L+1个数据并将其输出,其工作过程如下式所示,
Pf=LSTMpredict(Xf,Cfl,Hfl),
P=(P1,P2,…,Pm-L),
其中:Pf表示利用第f组温湿度数据中的L个温湿度数据预测的第L+1个数据,也是f+1组温湿度数据中的第一个数据;Cf-1和Hf-1分别为第f个LSTM结构中内含的第L个LSTM细胞的状态和输出;P表示模型的输出;
S5、计算隐藏层的输出,
Y=(aL+1',aL+2',…,am'),
其中,Y表示隐藏层的输出;
S6、确定损失函数,选用均绝对值误差作为误差计算公式,训练过程的损失函数可以定义为:
其中,loss表示损失函数的损失值。
进一步地,在所述缺失值自动填补步骤中包括:观测点每间隔t分钟进行一次记录,相邻两次记录的时间间隔之差若不在零值附近则可认为此处有缺失值,缺失值数量为差值与t相除的商,记为lost_num,应用预测模型进行预测,输入数据可表示为如下:
Xinput=(X1,X2,…,Xn),
将Xinput输入LSTM模型中,得到输出结果:
Y=(Y1,Y2,…,Ylost_num),
然后,通过对Y进行min-max去标准化得到预测序列Yfinal,
Yfinal=re_minmax(Y),
最后,将预测得到的结果序列,也就是待填补的缺失值序列并入原始数据,重复此步骤直至数据全部处理完成,将结果保存为.csv文件存入数据库中。
进一步地,所述数据预处理的步骤包括:对数据进行归一化处理,归一化方法采取min-max标准化,
通过原始数据的线性变换,使结果落到[0,1]区间。
本发明的有益效果如下:充分利用了时间序列数据的周期性特点,基于周期信息通过谱峰值加权填补时间序列缺失值,具有时间序列的个性化特点,并融合了时域技术和频域技术,能够较全面地反映时间序列的缺失值信息;避免了简单处理时间序列缺失值造成的信息损失和浪费,以及生搬硬套式的填补造成原序列数据信息的丢失和扭曲;该方法对于随机型缺失以及连续型缺失数据的填补均有较稳健的填补效果。
为让本发明的上述和其他目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附图式,作详细说明如下。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
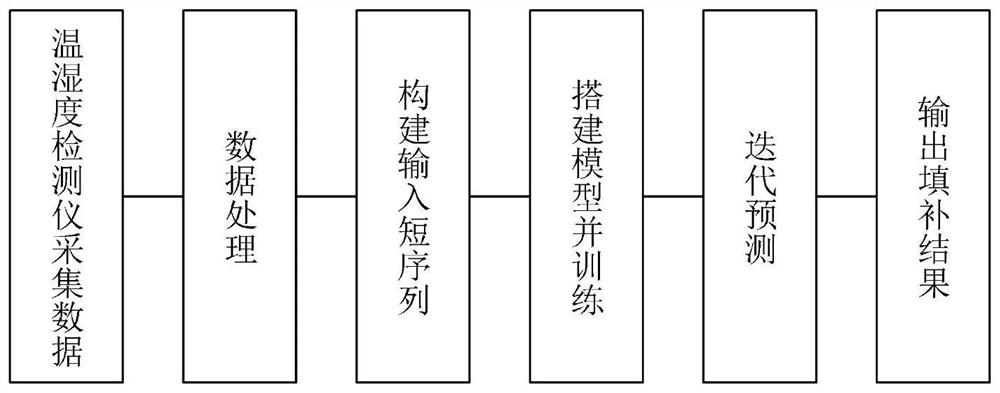
图1是基于LSTM的冷链监测温湿度数据拟合方法的步骤示意图。
图2是LSTM结构的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参照图1和图2,在本发明一较佳实施例中涉及的一种基于LSTM的冷链监测温湿度数据拟合方法,包括以下步骤:
步骤1:数据采集。温湿度监测点每间隔5分钟记录一次当前环境下的温度信息和湿度信息并保存为.csv格式,在记录完一天的数据后上传到服务器进行处理。
步骤2:数据预处理。数据集中的温度和湿度可能拥有不同的量纲,通过归一化处理以方便后面的数据处理,此外,可以加快梯度下降的收敛速度,归一化方法采取min-max标准化。
该方法是对原始数据的线性变换,使结果落到[0,1]区间。
步骤3:搭建模型并训练。模型包括输入层、输出层和隐藏层。输入层对原始的温湿度数据进行结构调整以满足训练要求;隐藏层使用了LSTM结构用于提取不同层面输入数据的特征;输出层提供温湿度预测的结果。LSTM结构是一种特殊的循环体结构,它是由输入门、遗忘门、输出门,记忆单元组成,如图2所示。输入门是在产生新记忆之前,判定一下当前看到的信息更新多少;遗忘门根据过去记忆单元对当前记忆单元的计算是否有用,并进行信息筛选;记忆单元用来记录到当前时刻为止的所有历史信息;输出门目的是从隐层状态分离最终的记忆。
训练过程采用BPTT(backpropagation through time)算法和Adam(adaptivemoment estimation)优化器。
首先在输入层中,定义初始的温湿度时间序列数据a=(a1,a2,…,an),其中a1=(a11,a12),a11代表温度数据,a12代表湿度数据,按照9∶1的比例划分的训练集和测试集可以表示为atr=(a1,a2,…,am)和ate=(am+1,am+2,…,an),满足约束条件m<n和m,n∈N。然后对训练集中的进行标采用经典的min-max标准化公式,标准化后的训练集atr'和测试集ate'可以表示为:
atr'=(a1',a2',…,am')
ate'=(am+1',am+2',…,an')
at'=(at-min∑at)/(max∑at-min∑at)
满足:
1≤t≤m,t∈N
构建短时间输入序列使其适应隐藏层的特点,通过固定步长来确定时间序列的长度,并对atr'进行处理,设固定步长取值为L,则模型输入为:
X=(X1,X2,…,Xm-L)
Xf=(af',af+1',…,af+L-1')
满足:
1≤f≤m-L,f&L∈N
接下来,将X输入隐藏层。隐藏层由m-L个LSTM结构组成,每个LSTM结构内含L个LSTM单元,其工作原理是根据L个输入数据预测第L+1个数据并将其输出,其工作过程如下式所示。
Pf=LSTMpredict(Xf,Cfl,Hfl)
P=(P1,P2,…,Pm-L)
式中:Pf表示利用第f组温湿度数据中的L个温湿度数据预测的第L+1个数据,也是f+1组温湿度数据中的第一个数据;Cf-1和Hf-1分别为第f个LSTM结构中内含的第L个LSTM细胞的状态和输出;P表示模型的输出,其输出如下:
Y=(aL+1',aL+2',…,am')
选用均绝对值误差作为误差计算公式,训练过程的损失函数可以定义为:
多轮迭代训练后得到最终的网络权重,训练完成。
步骤4:缺失值自动填补。观测点每间隔5分钟进行一次记录,相邻两次记录的时间间隔之差若不在零值附近则可认为此处有缺失值,缺失值数量为差值与5相除的商,记为lost_num,应用LSTM模型进行预测。输入数据可表示为如下:
Xinput=(X1,X2,…,Xn)
将Xinput输入LSTM,得到输出结果:
Y=(Y1,Y2,…,Ylost_num)
然后,通过对Y进行min-max去标准化得到预测序列Yfinal。
Yfinal=re_minmax(Y)
最后,将预测得到的结果序列,也就是待填补的缺失值序列并入原始数据,重复此步骤直至数据全部处理完成,将结果保存为.csv文件存入数据库中。
本发明中应用了具体实施例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 一种基于LSTM的冷链监测温湿度数据拟合方法
- 冷链保温箱、冷链保温箱的温湿度数据识别系统及方法