一种电力设备状态监测数据的完整样本集的构建方法
文献发布时间:2023-06-19 09:35:27
技术领域
本发明涉及一种基于机器学习算法的电力变压器铁芯接地电流状态监测数据处理方法,属于电力设备状态数据处理领域。
背景技术
电力变压器是保证输配电网稳定运行的重要设备,变压器的铁芯接地电流监测数据是对变压器进行状态评估的重要依据。一段时间的监测数据,包含其整体变化趋势、变化中的极值点及跃变点以及数据统计特征,可以从多方面反映电力变压器的内部可能存在的异常情况。
由于电磁干扰及恶劣的运行环境等影响,会出现变压器状态监测传感器故障、通信装置产生错误数据传输、通信中断等情况,导致在线铁芯接地电流采集的数含有大量的缺失值及检测系统故障产生的异常数据。对于数据异常值常采取删除操作,使得采样时间点数据缺失。数据中本就存在缺失值以及删除异常值产生的缺失数据点破坏在线监测数据时间序列的连续性,一定程度上改变了其数据特征即变化趋势,甚至出现关键极值点与跃变点缺失的情况。而造成各种基于数据样本的状态诊断评价技术因数据缺失而无法对变压器状态进行评价或评价结果不符合实际的情况。
经过电力变压器的长时间运行,电网公司已储备了大量的电力变压器基本台账信息以及状态运行信息,通过对设备的历史状态数据预处理,机器学习算法对数据所蕴藏信息的挖掘,可对缺失的数值采样点进行补全,进一步提高数据质量,并在此基础上提高基于数据的电力设备状态评价技术的准确性以及可信度。
发明内容
为了解决现有技术中电力设备状态监测数据缺失数据点,影响电力设备评价结果的问题,本发明所解决的技术问题在于提供一种基于历史数据挖掘的电力设备状态监测数据完整样本集的构建方法。
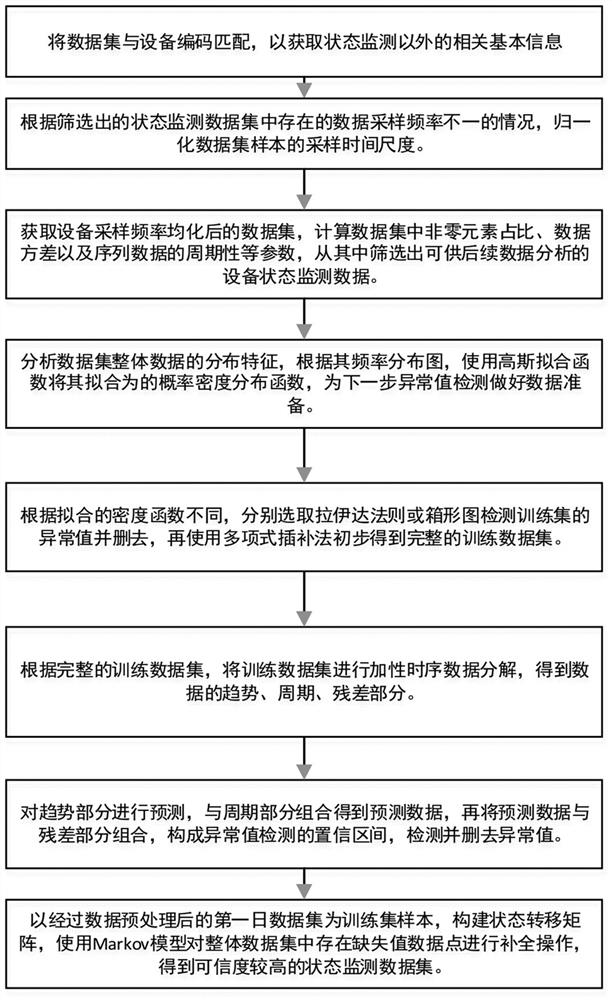
本发明通过以下技术方案来实现,一种电力设备状态监测数据的完整样本集的构建方法,步骤如下:
S1、状态数据集与设备编码匹配:将数据集与设备编码匹配,以获取状态监测意外的相关基本信息;
S2、数据采样频率归一化:根据筛选出的状态监测数据集中存在的数据采样频率不一的情况,归一化数据集样本的采样时间尺度;
S3、具有分析意义的状态数据集筛选:获取设备采样频率均化后的数据集,计算数据集中非零元素占比、数据方差以及序列数据的周期性参数,从其中筛选出可供后续数据分析的设备状态监测数据;
S4、数据频率分布拟合:分析数据集整体数据的分布特征,根据其频率分布图,使用高斯拟合函数将其拟合为概率密度分布函数,为下一步异常值检测做好数据准备;
S5、完整训练样本的构建:根据拟合的密度函数不同,分别选取拉伊达法则或箱形图检测训练集的异常值并删去,再使用多项式插补法初步得到完整的训练数据集;
S6、数据集的周期性检验:根据完整的训练数据集,将训练数据集进行加性时序数据分集,得等数据的趋势、周期、残差部分;
S7、基于训练样本的状态数据集回归预测及整体异常值检测:对趋势部分进行预测,与周期部分组合得等预测数据,再将预测数据与残差部分组合,构成异常值检查的置信区间,检测并删去异常值;
S8、以经过数据预处理之后的第一日数据集作为训练集样本,构建状态转移矩阵
具体地,步骤S1中,基于设备的基本台账信息,对状态监测数据集进行设备关键编码匹配,生成带有主变设备相关基本信息的状态监测数据集(主要为设备电压等级、生产厂家、设备所在地等基本信息),以便获取设备除监测状态值以外的特征变量数据。
具体地,步骤S2中、数据采样频率归一化:鉴于外界因素的影响,状态监测设备可 能存在受到干扰而出现状态数据集中数据采样频率不一的情况(同一时间段内采样的数据 量不同),以
具体地,步骤S3中、具有分析意义的数据集筛选:基于采样频率归一化之后的状态 数据集
具体地,步骤S4中、数据频率分布拟合:划分状态数据集的训练集与预测集,以前 两日作为训练集,后一日作为预测集,提取所有设备的前两日的状态监测数据,按不同设备 的状态编码,逐一绘制各设备的状态数据频率分布直方图,首先简单将直方图拟合为曲线, 筛选出符合正态分布直方图曲线,使用K-S方法根据对应曲线频率直方图拟合的曲线计算P 值,筛选得到符合正态分布的设备状态数据集
具体地,步骤S5中、完整训练样本的构建:对于状态数据集
具体地,步骤S6中、数据集
具体地,步骤S7中,对数据进行周期性分解,结果原始数据分解趋势部分、周期部 分以及残差部分,以两日数据作为训练集
具体地,步骤S8中的基于Markov状态转移模型进行空值点补全的具体过程为:
S8-1.数据空间划分:马尔科夫过程是依照一定概率分布在离散状态之间转移的过程, 对与变压器铁芯接地电流的时间序列数据,需要将每个采样时间点转化为对应的状态,构 成一个马尔科夫链;取单日铁芯接地电流状态数据中最大值
S8-2.状态转移矩阵的生成:在马尔科夫过程中,从状态
其中
根据上式计算两两状态之间的转移概率,各个状态之间的转移概率共同构成变压器铁 芯接地电流状态转移矩阵,将状态时间序列倒序排列,按相同原理计算反向状态转移矩阵
S8-3.权重分配:对于含有缺失数据的铁芯接地电流状态监测数据,设在第
经正向、反向生成的补全值原理相同,因此两个补全值的初始权重相同,都为0.5,当某 一状态在训练集中出现的次数越多,则说明在生成状态转移矩阵时对该状态的下一状态考 虑的越充分,以此状态作为初始状态的状态转移可信度就越高;因此,
则两个补全值的权重值分别为
式中,t
本发明具有以下技术效果:本发明根据变压器状态监测设备采集数据存在缺陷的情况,设计融入机器学习的数据预处理方法;根据传回的主变设备采集数据信息,计算数据集的非零参数的占比以及数据的方差等参数,选取非零参数占比大于80%以及存在一定方差的数据作为可供数据分析的数据集(一种分析序列数据周期性的方法,最好选取一定时间内状态监测数据具有周期性的设备,有利于提高后续的回归预测分析的精确度),并标记主变设备采集编号;以初始采集数据作为研究样本,针对数据集中采样频率不一的情况,均化数据集样本的采样时间尺度;使用K-S方法检验数据与正态分布的相似度,根据相似度决策进行异常值监测的措施,使用多项式插值的方法补充异常数据点;对补充后的数据集使用自回归平均模型(ARMA)分析设备的状态监测数据,分析训练数据集的平稳性与周期性,基于处理后的训练集样本对整个数据集进行回归预测分析,以数据集的残差序列作为预测数据置信区间,检验监测并删去数据集中存在的异常值数据点;根据得到存在少量缺失点的数据集,基于前期处理的训练集数据构建数据状态转移矩阵,使用Markov模型根据第一日的数据集合,对整体数据集中存在的空缺值进行补全操作,完成数据清洗操作,初始数据集中的缺失数据与异常数据已去除,得到一个准确度较高的完整数据集样本。
附图说明
图1为本发明的流程图。
图2为数据周期性检测流程图。
图3为设备状态监测曲线。
图4为数据日采样量直方图。
图5为重采样后的设备状态数据监测曲线。
图6是8月7日状态监测数据分布直方图。
图7是8月8日状态监测数据分布直方图。
图8是8月7日数据分布拟合图。
图9是8月8日数据分布拟合图。
图10是状态监测数据的自相关系数图。
图11是训练数据集平滑前后的对比。
图12是状态监测数据分解各部分图。
图13是预测结果与置信区间分布图。
具体实施方式。
下面结合附图对本发明作进一步详细阐明。
如图1所示,一种电力设备状态监测数据的完整样本集的构建方法,其特征步骤如下:
S1、状态数据集与设备编码匹配:将数据集与设备编码匹配,以获取状态监测意外的相关基本信息;
S2、数据采样频率归一化:根据筛选出的状态监测数据集中存在的数据采样频率不一的情况,归一化数据集样本的采样时间尺度;
S3、具有分析意义的状态数据集筛选:获取设备采样频率均化后的数据集,计算数据集中非零元素占比、数据方差以及序列数据的周期性参数,从其中筛选出可供后续数据分析的设备状态监测数据;
S4、数据频率分布拟合:分析数据集整体数据的分布特征,根据其频率分布图,使用高斯拟合函数将其拟合为概率密度分布函数,为下一步异常值检测做好数据准备;
S5、完整训练样本的构建:根据拟合的密度函数不同,分别选取拉伊达法则或箱形图检测训练集的异常值并删去,再使用多项式插补法初步得到完整的训练数据集;
S6、数据集的周期性检验:根据完整的训练数据集,将训练数据集进行加性时序数据分集,得等数据的趋势、周期、残差部分;
S7、基于训练样本的状态数据集回归预测及整体异常值检测:对趋势部分进行预测,与周期部分组合得等预测数据,再将预测数据与残差部分组合,构成异常值检查的置信区间,检测并删去异常值;
S8、以经过数据预处理之后的第一日数据集作为训练集样本,构建状态转移矩阵
具体地,步骤S1中,基于设备的基本台账信息,对状态监测数据集进行设备关键编码匹配,生成带有主变设备相关基本信息的状态监测数据集(主要为设备电压等级、生产厂家、设备所在地等基本信息),以便获取设备除监测状态值以外的特征变量数据。
具体地,步骤S2、数据采样频率归一化:鉴于外界因素的影响,状态监测设备可能 存在受到干扰而出现状态数据集中数据采样频率不一的情况(同一时间段内采样的数据量 不同),以
具体地,步骤S3、具有分析意义的数据集筛选:基于采样频率归一化之后的状态数 据集
具体地,步骤S4、数据频率分布拟合:划分状态数据集的训练集与预测集,以前两 日作为训练集,后一日作为预测集,提取所有设备的前两日的状态监测数据,按不同设备的 状态编码,逐一绘制各设备的状态数据频率分布直方图,首先简单将直方图拟合为曲线,筛 选出符合正态分布直方图曲线,使用K-S方法根据对应曲线频率直方图拟合的曲线计算P 值,筛选得到符合正态分布的设备状态数据集
具体地,步骤S5、完整训练样本的构建:对于状态数据集
具体地,步骤S6、数据集
如图2所示,步骤S6中数据周期性检测的具体过程是:
S6-1.通过傅里叶变换将状态序列数据集转化为频域数据,即功率谱密度图和选取候选周期,在分解出的所有正弦函数多项式中,傅里叶系数越大的三角函数的周期越有可能为该数据集的周期;
S6-2.计算序列数据集的自相关系数,绘制自相关系数图。通过度量同一事件不同时间的相关程度,使用Pearson相关系数计算不同相位差序列间的自相关系数,若序列存在周期性,遍历足够多的相位差,则可以找到一个足够大的自相关系数,其对应的相位差即为周期;通过使用该相位差去校验步骤S6-1中检测出可能存在的周期,可辨别出真实周期以及伪周期,候选周期在自相关系数图的波峰则为真实周期,候选周期在自相关系数图的波谷则为伪周期。
具体地,步骤S7、基于训练样本的数据集回归预测及整体异常值检测:对数据进行 周期性分解,结果原始数据分解趋势部分、周期部分以及残差部分,以两日数据作为训练集
具体地,步骤S8、以经过数据预处理之后的第一日数据集作为训练集样本,构建状 态转移矩阵
具体地,步骤S8中的基于Markov状态转移模型进行空值点补全的具体过程为:
S8-1.数据空间划分:马尔科夫过程是依照一定概率分布在离散状态之间转移的过程, 对与变压器铁芯接地电流的时间序列数据,需要将每个采样时间点转化为对应的状态,构 成一个马尔科夫链;取单日铁芯接地电流状态数据中最大值
S8-2.状态转移矩阵的生成:在马尔科夫过程中,从状态
其中
根据上式计算两两状态之间的转移概率,各个状态之间的转移概率共同构成变压器铁 芯接地电流状态转移矩阵,将状态时间序列倒序排列,按相同原理计算反向状态转移矩阵
S8-3.权重分配:对于含有缺失数据的铁芯接地电流状态监测数据,设在第
经正向、反向生成的补全值原理相同,因此两个补全值的初始权重相同,都为0.5,当某 一状态在训练集中出现的次数越多,则说明在生成状态转移矩阵时对该状态的下一状态考 虑的越充分,以此状态作为初始状态的状态转移可信度就越高;因此,
则两个补全值的权重值分别为
式中,t
实施例
以部分江西省主变设备状态监测数据集作为数据分析对象,完整数据集样本构建案例如下:
状态数据集与设备编码匹配:以主变设备的历史监测数据作为研究对象,通过不同设备的编码将状态数据集与主变设备的台帐信建立对应关系;在此基础上使用统计计算不同编码的设备状态数据监测集的非零元素占比、方差、均值等参数,通过分析这些参数初步筛选出原始数据集中具有分析意义的设备状态数据集;以部分江西省主变设备状态监测数据集作为数据分析对象,其基本情况信息汇总表如表1所示。
数据采样频率归一化:通过上表可知,编码为18M00000086658507、18M00000086658511、18M00000086659708、18M00000086659889的设备数据集规模过小,不足以支撑后续数据集分析,因此筛除这些数据集;编码为18M00000086658205、18M00000086659742、18M00000086660016、18M00001061027161、18M00001061027453、18M00000086660011的设备状态采集的数据中空值的占比分别为100%、93.61%、100%、100%、100%、30.1%,数据集中残缺情况较为严重,不具备数据分析价值,舍去;编码为18M00001054120410、18M00001054116401、18M00000008307576的设备虽然特征参数达到要求,但其方差与均值相比相差过大,可推断出其状态监测数据很可能是在一个很小的范围内持续来回跳变,没有分析价值,故删去;编码为18M00000007905515、18M00000086659826的设备虽然数据采集规模较大,且不存在零值的情况,但其整体方差为零,传回的数据为一段不变的常数值,数据集不具备分析的意义,删去。以上这些数据集的问题,大部分还是由于外界环境因素导致状态监测设备运行故障造成的,需根据设备编码进行一一排查。
经过以上初步的状态数据集筛除,仅余下编码为18M00000086659828、18M00000086660044、18M00000086660046、18M00001054120379四台设备状态监测数据集可供后续数据分析;本实施例以编码为18M00000086659828设备状态数据集作为对象,对数据分析操作进行实例分析。首先将数据集数据进行可视化,得到图3所示的状态监测曲线。图3中不难看出,该数据集监测的为8月4日至8月12日的状态变量,4、5、6、12日数据存在残缺,以设置的标准采样频率计算(一日240个数据点为采样频率),其4、5、6、12日数据采样比率分别为23.1%、0%、51.2%、73.6%,故4、5、6日采集数据残缺较为严重,将其删去;12日数据采集比率较大,可通过前几日的数据集训练模型进行回归预测,以填充缺失的部分,故保留。
数据集的重采样:提取设备8月7日至8月11日数据,绘制如图4所示的数据集日数据采样量直方图。不难看出数据集中每日的采样频率不一,7日至11日的数据采样频率分别为:216、230、245、239、234,采样频率未归一化的时间序列数据不利于模型训练,因此,需要对数据集进行重采样,标准日采样频率设置为240个数据点一日,可知7、8、10、11日的采样频率小于标准频率,应执行上采样,上采样过程本质可以归为数据的放回抽样,不断的从少类样本中抽取样本,与原始样本组成训练集训练模型;因此最终的数据集中是存在一定重复数据的,容易造成模型的过拟合,为解决此问题,本方法在采样的数据中添加了部分“随机性”:
假设抽取的数据样本为
式中
9日的数据采集量为245,大于标准的采样频率,需对数据进行下采样,下采样本质为降低日数据采样量,为了更加有目的的选取丢弃样本,使用最大最小值的抽样法,根据下采样需丢弃的样本数量,依次选取数据集中最大最小值作为丢弃样本,直至采样频率达到标准值;该方法在下采样过程中,优先丢弃异常值可能性大的样本,可有效减小后续异常值监测过程的复杂程度。按上述方法将编号为18M00000086659828设备状态监测数据采样频率归一化的数据曲线如图5所示。
不难看出,经过数据集9日的状态数据的经过下采样后,其中存在的一些极端异常值已被删去,7、8、10、11日的数据经过上采样,也已经达到标准采样频率,其中7日补全的数据最多,数据曲线的密度得到了很好的平滑化。
数据集频率分布的拟合:在得到以上一条状态数据监测曲线的基础上,以7、8两日 的监测数据作为训练集,绘制训训练数据的频率分布直方图,如下图6和图7所示,对以上两 直方图进行拟合,以便观察数据与正态分布函数的近似度,拟合图如图8和图9所示,初步观 察两组数据的拟合图,发现两组数据的分布皆较为接近正态分布函数曲线,使用单样本的 K-S方法检验监测数据样本与正态分布的近似程度,比较一个频率分布
当实际观测值
可见经过K-S方法检验,训练集数据的P值皆小于0.05,表示两组数据皆不满足正态分布。
设备状态监测数据的时序分析:观察到设备的状态监测数据接近时间序列数据,而平稳性是进行时序分析的基础,当数据不满足平稳性时许多结论都是不可靠的,因此,首先对数据的平稳性检验,以宽平稳作为判定条件,分别使用自相关系数与单位根检验法检验序列的稳定性,自相关系数检验结果如图10所示。
可见监测数据的自相关系数快速衰减,且单位根检验结果中P-value值远远小于0.99,说明状态监测数据是一个具有很强平稳的时间序列,不需要使用进一步手段对其进行平稳性处理。序列数据中存在的异常点会严重干扰基于建模技术对时序数据的分析,不利于挖掘序列数据中潜在的趋势规律,因此在对时间序列进行建模分析之前,需要对序列中存在的异常值筛除,本实施例使用一种滑动窗口与箱型图组合的方式筛除序列中存在的一些异常值以达到原始序列数据平滑的目的。经过本实施例提出方法平滑后的时序数据与滑动平均效果的对比如图11所示。不难看出,与一般的滑动平均对比,经过异常值的筛除以及筛除点数据的补全后,训练数据中的一些阶跃较大的数据点得到了更好的平滑效果,数据整体曲线也更加平缓,有效筛除了数据集中存在的一些过大或者过小的异常值。
得到平滑后的序列数据集之后,需要对其进行分解以挖掘其蕴含的规律,本专利 使用加法模型对时序数据进行分解;对于一个时间序列
其中
使用时序数据的趋势部分单独对ARMA进行训练,预测出趋势数据之后将其与周期部分组合得到预测的结果,以11日状态数据为例,其预测结果如图13所示。
- 一种电力设备状态监测数据的完整样本集的构建方法
- 一种基于不完整状态监测数据学习的系统可靠性模型构建与评估方法