一种批生产的时序数据特征提取方法
文献发布时间:2023-06-19 09:36:59
技术领域
本发明属于数据挖掘技术领域,尤其是涉及一种批生产的时序数据特征提取方法。
背景技术
数据挖掘(Data Mining)是指从大量含有噪声的、不完全的、模糊的数据中提取事先未知的又有潜在价值的信息的过程。工业生产数据具有大量(volume)、高速(velocity)、多样性(variety)、真实性(veracity)、可见性(visibility)和价值(value)的特征。大量(volume)即数据的规模大,高速(velocity)即数据的产生和采集非常频繁,多样性(variety)即数据的异构多样,真实性(veracity)即避免数据收集和提炼过程中发生的数据质量污染所导致的“虚假”信息,可见性(visibility)即通过分析使以往不可见的信息可见,价值(value)即分析获得的信息应被转换成价值。工业数据的产生主体是人和机器,即由人工输入的数据和通过相应传感器、仪器仪表、智能终端从设备上采集的数据,其中来自机器的数据在体量上占主要地位。这些数据中含有生产过程的宝贵信息,通过对生产数据进行挖掘,能进一步揭示生产规律,为生产优化提供助力。
当前批生产方式广泛应用于制药、食品、化工等行业。批生产数据存在以下特点:生产过程数据为时序数据,能反映生产过程随时间的变化趋势;每个批次的时间长度通常不相等,故每批次的过程变量样本数不同;生产过程数据采集频率高,变量数多,导致单批次的数据量大。针对某对象进行研究时,往往需要分析多个批次的生产数据,变量多、批次间样本数不等、数据量大,都对分析工作的推进提出了挑战。
发明内容
本发明所要解决的技术问题是提供一种压缩数据量、保留过程特征、可减少后续分析工作的运算压力的批生产的时序数据特征提取方法。为此,本发明采用以下技术方案:
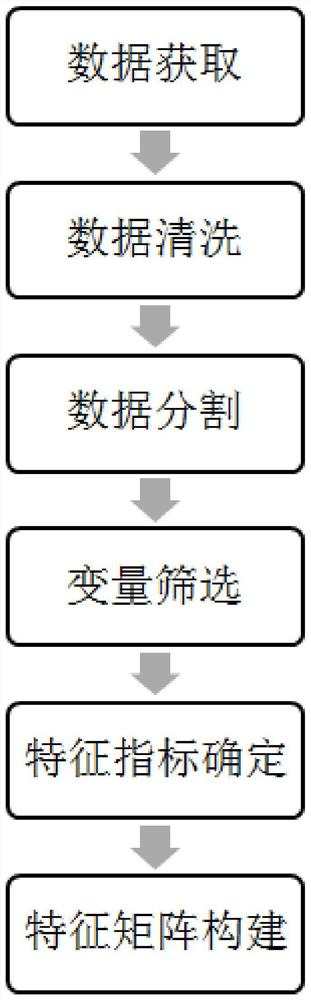
一种批生产的时序数据特征提取方法,包括以下步骤:
S1、数据获取,从数据源获取目标批次的过程数据X:
其中,n为样本数,n≥1;m为变量数,m>7;
S2、数据清洗,遍历各个变量并定位质量差的数据点,将定位到的质量差数据的变量剔除;
S3、数据分割,根据目标对象的实际意义和分析需求并利用现有变量,将过程数据分割为k部分,k≥2,每部分的样本数为n
S4、变量筛选,根据目标对象的实际意义和分析需求进行分析变量的筛选,获得:
其中,筛选后变量数为d,1≤d≤n,i=1,2,…k;
S5、特征指标确定,根据目标对象的实际意义和分析需求确定描述单个变量特征的指标,该指标数计为t,1≤t≤7;
S6、特征矩阵构建,基于数据矩阵A
其中,步骤S6中的指标为统计指标(如均值、标准差等);此处的运算过程是对每个变量求取统计指标,再构成行向量。
在采用上述技术方案的基础上,本发明还可采用以下进一步的技术方案:
所述步骤S1中的过程数据X为时序数据,所述样本数为批次的时长。
所述步骤S2中的质量差数据为变量包含的信息过少、或变量包含错误信息、或变量包含无效信息中的一种或多种;
所述变量包含的信息过少,包括变量取值较长时间保持不变,如变量为设定值;
所述变量包含错误信息,包括数据采集系统故障时收集到的数据;
所述变量包含无效信息,包括变量存在缺失值,如取值显示为NAN、NA或0时。
所述步骤S3中所述过程数据的分割在矩阵X的行方向上进行。分割标准为时间,包括但不限于以固定的时间周期进行分割,如时间周期为10min;或以实际工序单元操作对应的时间为标准,如操作1对应生产的第0min至30min、操作2对应生产的第31min至90min等。
所述步骤S4中所述分析变量为含有充足信息的模拟量。
所述步骤S5中所述描述单个变量特征的指标包括均值、中位数、四分位点、标准差、相关系数、偏度和峰度,采用的指标需根据分析需求和数据特征在上述范围内选取。
所述步骤S6中所述矩阵A
其中,过程数据均为时序数据,样本数反映了批次的时长。均值、四分位数描述了数据的分布情况,标准差描述数据的分散程度,偏度衡量数据分布偏斜的方向和程度,峰度衡量实数随机变量概率分布的峰态。分割后的片段要求样本数不少于3,是为了避免出现上述指标无意义、无法运算的情况。
与现有技术相比,本发明具有以下有益效果:
本发明提出的方法可将拥有大量数据点的变量用若干个指标来表示,且尽可能保留了变量的信息。通过构造特征矩阵,有效压缩数据,并且避免了由于样本数不等而导致的需要进行对齐的问题,进一步能够减小后续运算压力。获得的特征矩阵能代表该批次的信息,可以直接参与主成分分析、聚类分析和回归分类等,提高了分析效率。
附图说明
图1为本发明一种批生产的时序数据特征提取方法的特征提取过程的步骤示意图。
图2为本发明一种批生产的时序数据特征提取方法的实施例中变量V1和V2的均值、标准差的散点图。
图3为本发明一种批生产的时序数据特征提取方法的实施例的得分图。
具体实施方式
为了进一步理解本发明,下面结合具体实施方式对本发明提供的一种批生产的时序数据特征提取方法进行具体描述,但本发明并不限于此,该领域技术人员在本发明核心指导思想下做出的非本质改进和调整,仍然属于本发明的保护范围。
实施例一,如图1所示,目标过程为流化床制粒过程,共10个批次,其中批次2为异常批次。
S1、数据获取:从数据库读取获取批次1的过程数据,变量数为320,样本数为1921。
S2、数据清洗:遍历各个变量,发现数据缺失或数据错误的点,以及包含大量重复值的变量。剔除上述对应变量,不进入下一步处理。至此变量数为120,获得数据矩阵X
S3、数据分割:基于目标产品制粒工艺和流化床设备原理,利用现有的120个变量,将该过程按时间顺序分割为4个部分,每个部分的样本数为m
S4、变量筛选:基于目标产品制粒工艺及分析需求,确定用于后续运算的分析变量16个,均为模拟量。至此,获得4个数据矩阵A
S5、特征指标确定:基于目标产品制粒工艺及分析需求,确定能描述单个变量特征的指标,包括均值、标准差、偏度、峰度。
如图2所示,横坐标为分割序号,其中1-10对应阶段一,11-20对应阶段二,21-30对应阶段三,31-40对应阶段四;纵坐标为变量V1、V2各自的均值和标准差,数值均经过平移。
S6、特征矩阵构建:对4个数据矩阵A
本发明对批生产的历史数据进行特征提取,使单个批次的数据量由1921×320压缩至4×64,数据量明显减小。均值表征过程数据的平均水平,标准差表征过程数据的分散程度,偏度衡量数据分布偏斜的方向和程度,峰度衡量实数随机变量概率分布的峰态。
如图2所示,变量V1在四个阶段的分布明显不同;变量V2在阶段一、二、三的状态较为相似且稳定,在阶段四出现了显著的变化。提示不同工艺阶段,不同变量的分布表现有其特征性,可以指导生产状况的判断。
图3为本实施例的10批数据的特征信息进行主成分分析的得分图。可以看出异常批次2被很好的和其他正常批次区分开,说明特征提取保留的信息是可靠且充足的。所选取的指标能体现过程特征,特征矩阵即可代表整个批次,可以直接参与主成分分析、聚类运算等。
以上所述为本发明的一个较优实施例的具体实施方式,但本发明的保护范围不局限于此。凡是依据本发明的技术框架、无需创造性劳动的,均属于本发明技术方案的范围内。
- 一种批生产的时序数据特征提取方法
- 一种基于工艺规则的带钢生产过程数据特征值提取方法