一种结合声纹识别和深度学习的回声消除方法
文献发布时间:2023-06-19 09:38:30
技术领域
本发明涉及回声消除技术领域,进一步说,尤其涉及一种结合声纹识别和深度学习的回声消除方法。
背景技术
智能音箱在播放音频节目时,麦克风采集进来的信号既包含了目标说话人的信号(近端信号),也包含了扬声器播放出的音频信号(远端回声),这种情况下语音识别模块几乎无法工作。通常需要引入回声消除的方法把回声消除干净,同时保护近端的语音信号不受损失。目前主流的回声消除方法是借助硬件回路采集到的参考信号,来估计麦克风信号中存在的回声信号,将估计到的回声信号和原始信号做减法得到估计的近端信号,最后通过一个后置的非线性滤波器来抑制回声消除后残留的回声。在实际情况中,远端信号常常包含人声,后置的非线形滤波器根据信号成分很难区分多少成分是近端信号的人声,多少成分是回声信号中的人声。这种混淆严重影响了回声消除的效果。
经过检索,申请号为201810708151.0、名称为一种智能家居设备控制方法、智能音箱及智能家居系统的技术方案,仅仅解决了可以根据用户的行为习惯信息,主动提问用户是否开启相应的受控目标,简化了操作步骤,提升了用户体验等技术问题,其采用的技术方案是:采集用户的身份认证信息;对所述身份认证信息进行识别,获得身份认证结果;调取与所述身份认证结果对应的第一行为习惯信息;根据所述第一行为习惯信息,输出是否开启相应的受控目标的提示信息;其中,所述第一行为习惯信息是预先通过对所述用户的语音信息进行深度学习得到的。接收用户的声纹信息;调取与所述声纹信息对应的第二行为习惯信息;根据所述第二行为习惯信息,对相应的受控目标进行控制;其中,所述第二行为习惯信息为预先对所述用户的不同情感状态下的所述声纹信息进行深度学习得到的。
发明内容
为了解决远端信号包含人声时回声消除的效果不好的技术问题,本公开提供了一种结合声纹识别和深度学习的回声消除方法。
1)从目标说话人的语音片段中提取声学特征,通过预先训练好的包含递归神经网络模型的声纹编码器得到表征说话人信息的嵌入式向量,即声纹向量;
2)从接收的信号中提取声学特征,所述信号包括近端信号和远端信号,通过AEC算法估计出出现的回声信号,即估计回声信号,同时得到线性方式消除后的包含残留回声的近端信号,即线性过滤信号;
3)将估计回声信号、线性过滤信号以及远端信号声学特征合并,通过预先训练的二维卷积网络得到一组新的特征向量,将新的特征向量与声纹向量做特征合并;
4)合并后的特征向量通过预先训练的多层的递归神经网络模型中进行迭代运算,计算所述声学特征的掩膜;
5)采用所述掩膜对所述线性过滤信号的声学特征进行掩蔽;
6)将经过掩蔽后的所述声学特征与所述麦克风信号的相位进行合成,得到经过回声消除后的近端信号。
上述的一种结合声纹识别和深度学习的回声消除方法,其中:2)步中,从接收的麦克风信号中提取声学特征,所述麦克风信号包括近端信号和远端信号。
上述的一种结合声纹识别和深度学习的回声消除方法,其中:1)步中,预先训练好的包含长短期记忆的递归神经网络模型的声纹编码器构建方法为:收集多个说话人的语音信号,并以此建立语音训练集,通过长短期记忆的递归神经网络对所述语音训练集进行训练;步骤包含:根据所述语音信号的提取单句的声学向量,并与相同说话人和不同的说话人做区分训练,得到一个区分表达声学向量的模型。
上述的一种结合声纹识别和深度学习的回声消除方法,其中:3)步中,预先训练的卷积神经网络和长短期记忆的递归神经网络模型的构建方法包括:确定进行训练时的说话人声为近端和远端参考信号;收集远端信号、近端信号,并以此建立语音训练集,其中所述远端信号为回声信号,所述近端信号与所述回声信号形成麦克风信号;获取近端信号中目标说话人的其他音频信号的声纹向量,将通过估计回声信号、线性过滤信号和参考信号合并后通过所述二维卷积网路,在通过具有长短期记忆的递归神经网络模型得到估计的掩膜,将所述掩膜对所述线性过滤信号的声学特征进行掩蔽,目标就是将掩蔽后的声学特征逼近干净的近端信号声学特征,具体损失函数为幂律压缩重建误差:
本发明相对于现有技术具有如下有益效果:
在进行回声消除时,从接收的麦克风信号中提取声学特征,将声学特征通过预先训练的卷积神经网络得到稳定的多项声学特征向量,再与声纹向量合并,通过预先训练好的长短期记忆递归神经网络模型中进行迭代运算,计算声学特征的掩膜后,采用该掩膜对声学特征进行掩蔽。再将经过掩蔽后的声学特征与麦克风信号的相位进行合成,实现回声消除。由于该方案中采用了目标说话人的声纹信息、卷积神经网络获取稳定的多项特征信息,以及预先训练的递归神经网络模型,从而能够在双讲和非现性失真等情况下实现回声消除,即使在远端信号包含人声的情况下,也可以大大地提高回声消除的效果。
附图说明
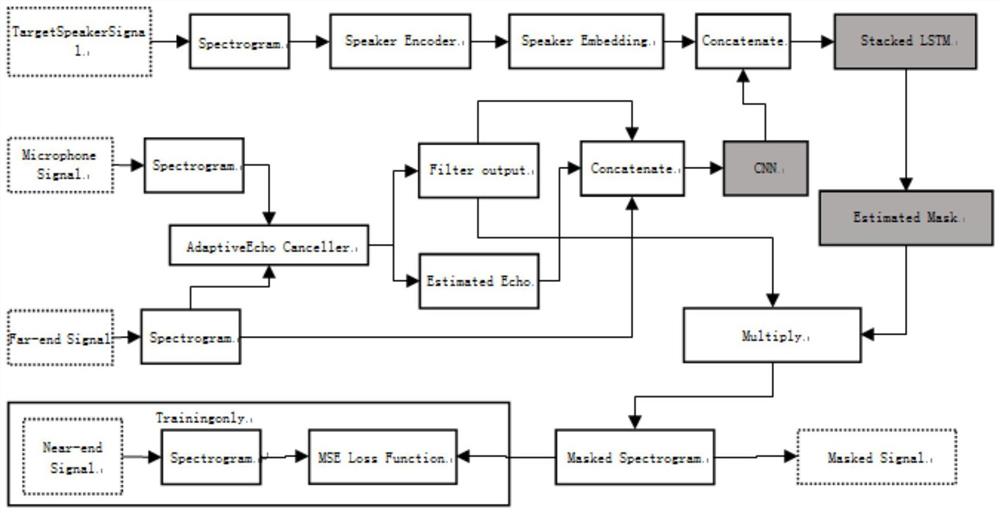
图1为具体实施例示意图,长方形框内的操作表示仅在训练时需要计算,灰色底部分的操作包含可训练参数。
具体实施方式
下面结合附图和实施例对本发明作进一步的描述。
首先,从目标说话人的语音片段中提取声学特征,通过预先训练好的包含递归神经网络模型的声纹编码器,得到表征说话人信息的嵌入式向量,即声纹向量;
在实际工作中,从接收的麦克风信号中提取声学特征,所述麦克风信号包括近端信号和远端信号,通过传统的AEC算法,如通过线性回声消除器,估计出麦克风出现的回声信号,即估计回声信号,同时得到线性方式消除后的包含残留回声的近端信号,即线性过滤信号。
将估计回声信号、线性过滤信号以及远端信号声学特征合并,通过预先训练的二维卷积网络得到一组新的特征向量,将新的特征向量与声纹向量做特征合并;
合并后的特征向量通过预先训练的多层的递归神经网络模型中进行迭代运算,计算所述声学特征的掩膜;
采用所述掩膜对所述线性过滤信号的声学特征进行掩蔽;
将经过掩蔽后的所述声学特征与所述麦克风信号的相位进行合成,得到经过回声消除后的近端信号。
预先训练的包含长短期记忆的递归神经网络模型的声纹编码器构建方法包括:
收集多个说话人的语音信号,并以此建立语音训练集,通过长短期记忆的递归神经网络对所述语音训练集进行训练;
步骤包含:根据所述语音信号的提取单句的声学向量,并与相同说话人和不同的说话人做区分训练,得到一个可以区分表达声学向量的模型;
预先训练的卷积神经网络和长短期记忆的递归神经网络模型的构建方法包括:
确定进行训练时的说话人声为近端和远端(参考)信号;收集远端信号、近端信号,并以此建立语音训练集,其中所述远端信号为回声信号,所述近端信号与所述回声信号形成麦克风信号;获取近端信号中目标说话人的其他音频信号的声纹向量,将通过估计回声信号、线性过滤信号和参考信号合并后通过所述二维卷积网路,在通过具有长短期记忆的递归神经网络模型得到估计的掩膜,将所述掩膜对所述线性过滤信号的声学特征进行掩蔽,目标就是将掩蔽后的声学特征逼近干净的近端信号声学特征,具体损失函数为幂律压缩(power-law compressed)重建误差:
图1为具体实施例示意图,长方形框内的操作表示仅在训练时需要计算,灰色底部分的操作包含可训练参数。
虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发明的保护范围当以权利要求书所界定的为准。
- 一种结合声纹识别和深度学习的回声消除方法
- 一种基于深度学习算法的声纹识别方法