树形结构自增数据节点ID及其路径链二进制编码方法
文献发布时间:2023-06-19 09:44:49
技术领域
本发明涉及信息系统编码技术领域,涉及分级的数据域内数据对象的自增标示统一编码,即树形结构自增数据节点ID及其路径链二进制编码方法。
背景技术
在分布式系统、数据库与大数据管理系统中,树形数据结构是一种基本的数据表达和存储方式,一般系统在扩展数据节点的时候,为了保证节点的唯一标志,往往采用自增ID的形式,实际的分布式或大数据生态系统中,在树形结构的各个层次上,均有可能不断进行节点的增添。自增ID为信息系统内部和/或分布式系统之间的数据对象调用提供唯一标识,同时为实现软件信息系统之间广域的“数据耦合”提供一种数据资源的标识方法。“松耦合,高内聚”是现代软件架构的基本设计原则,“数据耦合”是实现“松耦合”软件架构的主要方法。传统的软件系统之间的信息交换一般采用“接口”方式,当前XML、JSON均为成为普遍应用的数据交换技术,为了满足良好的可读性,XML、JSON一般直接采用ASCII码文件形式,其数据调用和访问均涉及文件操作,并且一般系统的XML或JSON文件的语义理解是在系统内自行解析的,即为相对“封闭”的系统,其互联互通均须通过对XML或JSON文件的操作来实现。
传统的自增ID编码方式位固定字长编码,一般将其前驱节点的ID作为索引路径的编码前缀,往往需要开销大量的存储空间,若采用文件压缩方案,则调取某一个节点ID需要解码整个压缩文件,其操控性和可读性更弱。结合申请号为CN201810455972.8的专利申请“一种表驱动的云模式软件自动构造方法及系统”和申请号为CN201410180915.5的专利申请“一种轻量级应用开发云服务平台及其资源的访问方法”所记载的可伸缩软件系统中可扩展的数据资源应用场景,构建一种即时动态编码的方案具有重要的应用价值。
发明内容
树形数据结构可以高效精简地表达复杂的大数据结构,但为分层检索带来了复杂性,对索引路径进行组合编码能够提高检索效率,但是传统的索引编码方案占用相当大的存储空间,也影响到其检索性能。为了克服现有技术存在的缺陷与不足,结合可伸缩软件系统中可扩展的数据资源应用场景,为信息系统内部和/或分布式系统提供更为具体的数据资源唯一标示方法,也为其它开放系统的互联互通、系统认证、业务集成提供一套基于统一编码规则的数据资源定位和识别方案,本发明提供一种树形结构自增数据节点ID二进制编码方法和基于此方法嵌入的数据节点访问路径链二进制编码方法,本发明旨在为泛在的数据对象提供精简的二进制唯一标示方法,在保证目标数据对象被唯一标定的前提下,比采用XML或JSON方式能够节省大量的存储空间,本发明的包含索引路径的树形结构自增ID编码方案对于树形数据结构自增节点,采用分层简约表达的方法实现了树形结构任意数据节点的唯一访问路径标示,且达到了大大缩减树形结构数据节点的索引路径所占用的空间的效果。在实现唯一标识、唯一解码、压缩存储空间、直接逐条解码方面具有显著优势,实现开放软件生态中异构数据对象的唯一标示,以满足数据对象访问、调用和复用的业务需求,对于实现数据驱动的软件构造具有重要的现实意义。
为了达到上述目的,本发明内容包括下述技术要点:
本发明提供一种树形结构自增数据节点ID二进制编码方法,包括下述步骤:
所述树形结构是指任意子层中一个数据节点有且仅有一个父层数据节点的树形拓扑数据组织结构,节点ID的十进制自增编号生成顺序为自根节点至叶节点,自左至右,对于该树形结构中第i层的一个数据节点ID自增编号值j
1.1 计算第i层中的一个数据节点ID自增编号值j
1.2 计算二进制码长度bj
1.3 预设固定参数LJM,表示该树形结构中各分层节点二进制编码长度bbj
作为优选的技术方案,采用
bj
所述计算二进制码长度bj
bbj
所述计算二进制码长度bbj
bbbj
所述预设固定参数LJM,具体表示为:
LJM=Max(bbbj
采用向上取整的表示形式
采用以上两套方法计算的结果一致。
本发明提供树形结构自增数据节点ID路径链二进制编码方法,包括下述步骤:
2.1 设置系统预设值SYSTEM内容,作为路径链数据结构的编码头信息;
2.2 采用逆序编码、顺序编码或继承编码中的任意一种编码方式对于目标节点j
2.2.1所述逆序编码是指从目标节点逆向朝其各级父节点直至根节点RootNode的方式完成其二进制路径链编码,对于该路径上的每个数据节点,依次先将二进制码长度bbj
2.2.2所述顺序编码是指从根节点RootNode出发向其各级子节点直至目标节点的方式完成其二进制路径链编码,对于该路径上的每个数据节点,依次先将二进制码长度bbj
2.2.3所述继承编码是指从根节点RootNode出发向其各级子节点直至目标节点的方式完成其二进制路径链编码,对于该路径上的当前目标数据节点,先将二进制码长度bbj
2.3判断当前层是否还有新增数据节点,若还有新增数据节点,则ID自增编号值j
作为优选的技术方案,所述逆序编码步骤具体包括:
针对新的自增数据节点,对其尾部的LJM个比特位置0,编码为LJM个0,表示该自增节点编码的结束符;
将ID自增编号值j
将二进制码长度bj
计算二进制码长度bbj
若i>1,则以上一层父节点FN的序列号置换,遍历树形结构的各个层级,直至i=1,则结束编码,在其头部把系统预设值SYSTEM的内容写入sPrefix个比特位置。
作为优选的技术方案,所述顺序编码步骤具体包括:
在头部把系统预设值SYSTEM内容写入sPrefix个比特位置;
计算第i=1层中的ID自增编号值j
计算二进制码长度bj
计算bbj
依次将Bbbj
若该数据节点没有后续节点,则在尾部写入LJM个0,表示编码结束;
若存在后续节点,遍历所有层级进行编码,直至新增节点的末尾。
作为优选的技术方案,所述继承编码步骤中,当前节点编码的主体表示为:
FNSH
其中,(.)内的值表示比特位的宽度,+表示比特位的拼接,*表示前面位置补填0;
当前节点最终编码为:
SYSTEM(sPrefix)+ FNSH
其中,sPrefix表示用户自定义的固定比特系统前缀SYSTEM。
本发明还提供一种树形结构自增数据节点ID路径链二进制编码方法,包括上述树形结构自增数据节点ID路径链二进制编码方法,将树形结构当前自增节点ID路径链的二进制编码值作为当前自增节点ID的二进制编码值,即以路径值替代节点值。
本发明提供一种树形结构自增数据节点ID路径链二进制解码方法,对应上述树形结构自增数据节点ID路径链二进制编码方法的逆过程,具体步骤包括:
获取系统预设值SYSTEM内容;
首先,i=1,取出第i=1个间隔位LJM的值,若LJM≠0,则获得该数据对象第1级前缀的字长的字长值bbj
根据所得的bj
随后,i=i+1,取出第i+1个间隔位LJM的值,若LJM=0,解码结束;
若LJM≠0,则提取该LJM位二进制的值赋给bbj
根据所得的bj
本发明提供一种树形结构自增数据节点ID路径链二进制编码系统,包括:树形结构层级及编号选取模块、二进制码计算模块、固定参数预设模块、预设值设置模块、编码模块和迭代判断模块;
所述树形结构层级及编号选取模块用于选取树形结构第i层,以及数据节点在第i层中的ID自增编号值j
所述二进制码计算模块用于计算第i层中的ID自增编号值j
所述固定参数预设模块用于预设固定参数LJM,表示树形结构中分层节点二进制编码的固定比特间隔;
所述预设值设置模块用于设置系统预设值SYSTEM内容;
所述编码模块用于采用逆序编码、顺序编码或继承编码中的任意一种编码方式进行编码;
所述逆序编码按当前编码节点所在层逆序至根节点,分别将二进制码长度bbj
所述顺序编码从根节点顺序至当前编码节点,分别将二进制码长度bbj
所述继承编码是指从根节点RootNode出发向其各级子节点直至目标节点的方式完成其二进制路径链编码,对于该路径上的当前目标数据节点,先将二进制码长度bbj
所述迭代判断模块用于判断当前层是否还有新增数据节点,若还有新增数据节点,则ID自增编号值j
本发明提供一种树形结构自增数据节点ID路径链二进制解码系统,与上述树形结构自增数据节点ID二进制编码系统相对应,包括:系统预设值获取模块、间隔位内容提取模块和判断遍历模块;
所述系统预设值获取模块用于获取系统预设值SYSTEM内容;
所述间隔位内容提取模块用于取出第i=1个间隔位LJM的值,若LJM≠0,则获得该数据对象第1级前缀字长的字长值bbj
根据所得的bj
取出第i+1个间隔位LJM的值;
所述判断遍历模块用于判断LJM是否为0,若LJM=0,解码结束;
若LJM≠0,则提取该LJM位二进制的值赋给bbj
根据所得的bj
本发明与现有技术相比,具有如下优点和有益效果:
(1)本发明为树形数据结构中的节点数据对象的索引定位路径提供精简的二进制唯一编码标示方法,在保证目标数据对象被唯一标定的前提下,比采用XML或JSON方式能够节省大量的存储空间,本发明的自增ID编码方案对于树形数据结构自增节点,在实现唯一标识、唯一解码、压缩存储空间、直接逐条解码方面具有显著优势,实现开放软件生态中异构数据对象的唯一标示,以满足数据对象访问、调用和复用的业务需求,对于实现数据驱动的软件构造具有重要的现实意义。
(2)本发明对于非标准化分层数据结构的索引定位路径标示的精简表达具有借鉴意义。
(3)传统的实现方案往往需要开销大量的索引存储空间来换取检索效率,本发明为多级树形数据的深度检索提供了一种扁平化的索引路径编码方案,在保证同等高效的检索效率的基础上,大幅度地缩减了树形结构索引路径的ID存储空间,对于巨型、超大型数据结构的表达和索引具有基础意义,其主要价值在于其低冗余与高效率,对于大规模数据存储和数据检索具有实际意义,对于大数据的分布式存取与快速检索调用具有现实意义。
附图说明
图1为本发明的树形结构数据节点自增ID编码比特分配示意图;
图2为本发明数据节点自增ID逆序编码方案步骤SI3.1示意图;
图3为本发明数据节点自增ID逆序编码方案步骤SI3.2示意图;
图4为本发明数据节点自增ID逆序编码方案步骤SI3.3示意图;
图5为本发明数据节点自增ID逆序编码方案步骤SI3.4示意图;
图6为本发明数据节点自增ID逆序编码方案步骤SI3.5示意图;
图7为本发明数据节点自增ID逆序编码方案步骤SI3.6示意图;
图8为本发明数据节点自增ID顺序编码方案步骤SS3.1示意图;
图9为本发明数据节点自增ID顺序编码方案步骤SS3.2示意图;
图10为本发明数据节点自增ID顺序编码方案步骤SS3.3示意图;
图11为本发明的树形数据节点自增ID的顺序编码流程示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例
本实施例提供一种树形结构自增数据节点ID二进制编码方法,为了实现开放软件生态系统GWDI(通用Web数据集成系统)中异构数据对象唯一标示,以满足数据对象访问、调用和复用的业务需求,采用本发明设计一套数据对象唯一标示符编码,并通过该编码码字的全球化统一注册,实现数据对象资源的全球化分布式访问调用。
本实施例的“自增节点”是指自然增长的数据节点,默认生成方式为当前ID+1,树形数据结构是一种具有广泛应用的数据结构,本实施例的面向树形结构(包括但不限于二叉树)进行自增数据节点的编码,该编码方法是可变长编码、唯一可译码、非前缀码、即时码。
本实施例的树形结构是一种层次化的嵌套结构,可以递归表示。本实施例所针对的树形结构是指在该树形结构中,树根结点没有前驱结点,其余每个结点有且只有一个前驱结点,叶子结点没有后续结点,其余每个结点的后续节点数可以是一个也可以是多个。在该树形结构中,一个自增节点是指当前最新的节点(当前没有后续节点),是其前驱节点(FN:FatherNode)之下的一个新增节点(CN:CurNode),取当前FN的顺序号为i-1代,当前CN在i代的值为j
(1)当前自增节点CN索引路径标记可变长二进制编码:当前第i代数据节点CN的顺序号为该序号j
bj
表示该序号所占字长bj
bbj
表示该序号所占字长的字长bbj
bbbj
同理,其父数据节点j
设所有层中的数据节点的预计的最大可能个数为JM:
JM = Predict(MAX(j
这里Predict( .)表示一个预测函数,取该树分层节点二进制编码的固定间隔位为LJM:
LJM=Max(bbbj
LJM存储当前节点CN及其各级FN的顺序号的字长数的字长的值,即bbj
如果采用向上取整的表示形式,公式(1)表示为:
如果采用向上取整的表示形式,公式(2)表示为:
如果采用向上取整的表示形式,公式(3)表示为:
如图1所示,进行当前可变长自增节点ID二进制编码比特分配,图中sPrefix为用户可以自定义的固定比特系统前缀SYSTEM,该前缀部分的设计不受约束。为了方便可读,该二进制编码可转换为十进制或者其它进制表示。
基于以上涉及的编码方法,对于该树中的一个自增数据节点所需编码码长为L
L
其中,bbj
若采用固定字长,则该树形结构的数据节点ID的固定字长设计为
(2)本发明方法(1)中所述的自增ID间隔默认为+1,即
树的同层新增节点编号 =树的同层前一节点编号 + 1公式(8)
同时,本发明方法(1)中的所述方法支持自增ID为
树的同层新增节点编号 =树的同层前一节点编号 +n公式(9)
公式9为n>1的情况表述,其它ID编码方法与n=1的情况一致。为了进一步节省编码空间,n的取值可以预先在system头字段中进行设计,则编码方案与n=1完全一致,解码时候从SYSTEM头字段中读取n的值,即可进行解码操作。
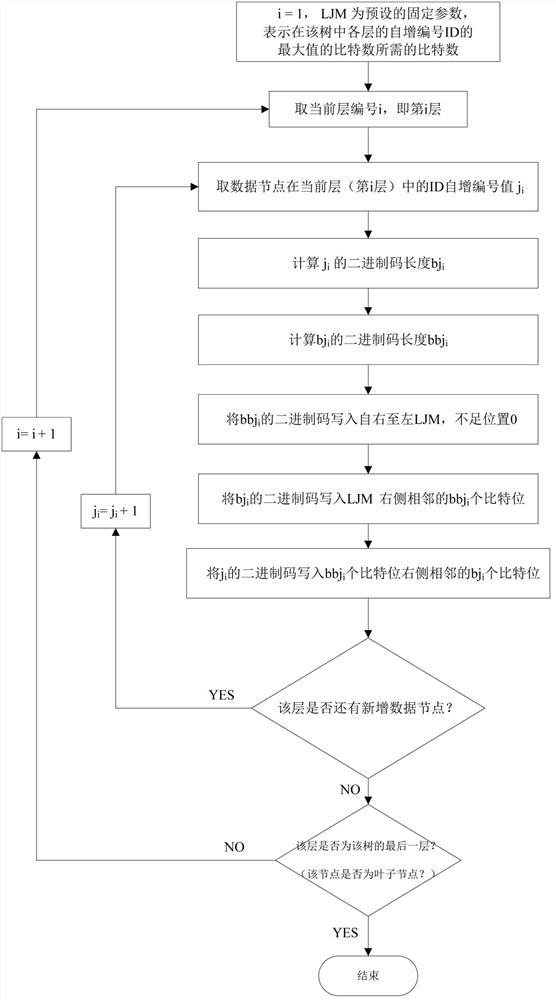
(3)基于本发明所述编码方法(1),首先根据公式(4)和公式(5)首先根据估计的JM值,确定LJM的值,如图1所示,以SI为例,本发明提供三种具体的编码方案,其步骤的编号前缀别为SI、SS、SH,分别逆序编码SI、顺序编码SS和继承编码SH,具体实施采用其中的一种即可。
逆序编码方案SI:如图1所示,表示编码步骤从尾至头依次编码,其步骤为:
SI3.1 对于一个新的自增数据节点,对其尾部的LJM个比特位,置0,即编码为LJM个0,表示该自增节点编码的结束符;如图2所示,这里*表示前面位置补填足够的0。
SI3.2 对于该新的自增数据节点,根据该新增数据节点所在父节点内的自增序列号j
SI3.3 对于该新的自增数据节点,根据SI3.2和公式(2)计算bj
SI3.4 对于该新的自增数据节点,根据SI3.3和公式(3)计算bbbj
基于公式(4)和公式(5)的定义,不出现bbbj
SI3.5如图6所示,如果i>1,则以上一层父节点FN的序列号置换,对于该新的自增数据节点,即i=i-1,转到SI3.2~SI3.5;
SI3.6如果i=1,则结束,如图7所示,在其头部把系统预设值SYSTEM的内容写入sPrefix个比特位置。
(二)顺序编码方案SS:表示编码步骤从头至尾依次编码,类似SI方案,其不同在于SI比特分配顺序是从尾至头,SS是从头至尾;其步骤为:
SS3.1如图8所示,首先,在头部把系统预设值SYSTEM内容写入sPrefix个比特位置;然后,对于该新的自增数据节点,根据该新增数据节点所在树的根节点(即i=1)驱动的数据节点的自增序列号j
(1)根据公式(1)计算其序列号的二进制字长bj
(2)根据公式(2)计算bj
(3)根据公式(3)计算bbj
如图9所示,依次将Bbbj
SS3.2如图10所示,取i=i+1,循环迭代执行SS3.1的相关计算过程,直到该新增节点的末尾。
(三)继承编码方案SH:表示其编码的当前节点的所有父节点全部已经采用该继承编码方案进行其ID二进制编码生成,故所有节点只需要编码当前叶子节点的码字即可,其父编码的传递序列直接从其前驱节点继承,其分步编码的步骤为SS方案的特例。即设前驱节点编码为FNSH
FNSH
这里(.)内的值表示比特位的宽度,‘+’表示比特位的拼接,当前节点最终编码为:SYSTEM(sPrefix)+ FNSH
如图11所示,本实施例给出树形数据节点自增ID的逆序编码工作流程,相应的解码工作流为其逆过程。
(4)基于本发明步骤(3)的编码方案的解码步骤为:
S4.1对于一个分布式分层树形结构大数据集所包含的数据节点对象,本实施例分布式分层树形结构大数据集可用于大型图片库的树形多级分类索引标签构造,根据本发明(1)分配其头部固定比特数分别取出sPrefix比特位获取SYSTEM的值;
S4.2首先,i=1,取出第i=1个间隔位LJM的值,若LJM≠0,则获得该数据对象第1级前缀的字长的字长值bbj
S4.3随后,i=i+1,取出第i+1个间隔位LJM的值,若LJM=0,解码结束;若LJM≠0,则提取该LJM位二进制的值赋给bbj
本实施例的一种树形结构自增数据节点ID路径链二进制编码方法,包括上述树形结构自增数据节点ID路径链二进制编码方法,将树形结构当前自增节点ID路径链的二进制编码值作为当前自增节点ID的二进制编码值,即以路径值替代节点值。
本实施例还提供一种树形结构自增数据节点ID路径链二进制编码系统,包括:树形结构层级及编号选取模块、二进制码计算模块、固定参数预设模块、预设值设置模块、编码模块和迭代判断模块;
所述树形结构层级及编号选取模块用于选取树形结构第i层,以及数据节点在第i层中的ID自增编号值j
所述二进制码计算模块用于计算第i层中的ID自增编号值j
所述固定参数预设模块用于预设固定参数LJM,表示树形结构中分层节点二进制编码的固定比特间隔;
所述预设值设置模块用于设置系统预设值SYSTEM内容;
所述编码模块用于采用逆序编码、顺序编码或继承编码中的任意一种编码方式进行编码;
所述逆序编码按当前编码节点所在层逆序至根节点,分别将二进制码长度bbj
所述顺序编码从根节点顺序至当前编码节点,分别将二进制码长度bbj
所述继承编码是指从根节点RootNode出发向其各级子节点直至目标节点的方式完成其二进制路径链编码,对于该路径上的当前目标数据节点,先将二进制码长度bbj
所述迭代判断模块用于判断当前层是否还有新增数据节点,若还有新增数据节点,则ID自增编号值j
本实施例还提供一种树形结构自增数据节点ID路径链二进制解码系统,与上述树形结构自增数据节点ID二进制编码系统相对应,包括:系统预设值获取模块、间隔位内容提取模块和判断遍历模块;
所述系统预设值获取模块用于获取系统预设值SYSTEM内容;
所述间隔位内容提取模块用于取出第i=1个间隔位LJM的值,若LJM≠0,则获得该数据对象第1级前缀字长的字长值bbj
根据所得的bj
取出第i+1个间隔位LJM的值;
所述判断遍历模块用于判断LJM是否为0,若LJM=0,解码结束;
若LJM≠0,则提取该LJM位二进制的值赋给bbj
根据所得的bj
在本实施例中,树形数据结构的层次n=4层,每层数据对象的最大值分别为j
所以取LJM=
本实施例对前缀部分的这个固定比特宽度不做重点阐述。
例如,本实施例中第2层的第5个数据对象,如下表1所示,可以编码为:
表1 第2层的第5个数据对象编码表
即该数据对象的码字的可变长部分为:0011101011101,共13比特,若采用固定比特率,需要16*2=32比特。
例如,本实施例中第3层的第11个数据对象,且该数据的父数据对象为第2层的第5个数据对象,如下表2所示,则该数据对象可以编码为二进制数:
表2 第3层的第11个数据对象编码表
即该数据对象的码字的可变长部分为:00111010111010111001011,共23比特,若采用固定比特率,需要16*3=48比特。
例如,本实施例中第4层的第31个数据对象,且该数据的父数据对象为第3层第11个数据对象,如下表3所示,该数据对象可以编码为二进制数:
表3 第4层的第31个数据对象编码表
即该数据对象的码字的可变长部分为:0011101011101011100101101110111111000,共34比特,若采用固定比特率,需要16*4=64比特。
例如,本实施例中第4层的第1024个数据对象,且该数据的父数据对象为第3层第11个数据对象,如下表4所示,该数据对象可以编码为二进制数:
表4 第4层的第1024个数据对象编码表
即该数据对象的码字的可变长部分为:0011101011100011100101110010101111111111000,共43比特,若采用固定比特率,需要16*4=64比特。
例如,本实施例中第4层的第65536个数据对象,且该数据的父数据对象为第3层第11个数据对象,如下表5所示,该数据对象可以编码为二进制数:
表5 第4层的第65536个数据对象
即该数据对象的码字的可变长部分为:001110101110001110010111001111111111111111111000,共48比特,若采用固定比特率,需要16*4=64比特。
因此,该树形数据结构节点的唯一编码方式,随着自增序列从小到大,其所占码字的长度能够自适应的逐步增长,以适应大的序列号的需要,可以节省码字空间。即自增码小的时候会自动采用较短的编码字长,自增码大的时候会自适应地采用相对较长的编码字长,从而达到缩小码字空间的目的。本发明采用自适应设计自增字段三级动态编码方案,即LJM+bj
本发明不但为可伸缩软件系统中可扩展的数据资源应用场景提供了更为具体的数据资源唯一标示方法,同时本发明也为其它开放系统的互联互通、系统认证、业务集成提供了一套基于统一编码规则的数据资源定位和识别方案,在大型数据资源管理与维护、通用Web 数据集成GWDI、命名数据网络NDN、RMI远程方法调用等方面具有重要应用价值。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 树形结构自增数据节点ID及其路径链二进制编码方法
- 树形结构自增数据节点ID及其路径链二进制编码方法