III类脱氧核酶突变体及其制备方法与应用
文献发布时间:2023-06-19 09:46:20
技术领域
本发明属于生物化学与分子生物学领域,特别涉及一种能快速水解DNA的III类脱氧核酶突变体及其制备方法与应用。
背景技术
脱氧核酶(Deoxyribozyme),也称为DNA酶,是通过体外筛选策略得到的具有酶活性的人工合成的具有一定三维立体结构的单链DNA分子。其不仅具有较好的结构识别能力,还具有高效的催化活性,能催化DNA的磷酸化、腺苷化、RNA切割、DNA连接等多种化学反应。近年来,已有研究者筛选出了两类感应锌离子并在特定位点水解DNA磷酸二酯键的脱氧核酶。其中,依赖锌离子的I类脱氧核酶,催化核心只有15个保守的核苷酸序列,侧翼带有1或2个双链亚结构,其水解切割DNA的速率常数约1.0min
发明内容
基于此,本发明的目的在于提供一种能快速水解DNA的脱氧核酶突变体及其制备方法与应用。
为实现上述目的,本发明具体技术方案如下:
一种III类脱氧核酶突变体,其结构通式为:P1-(N)
其中(N)
P1与P1′上的核苷酸序列全部或部分互补配对而组成亚结构域1;
P2与P2′上的核苷酸序列全部或部分互补配对而组成亚结构域2。
本发明的另一个目的在于提供一种能快速水解DNA的脱氧核酶的制备方法,具体技术方案如下:
一种脱氧核酶突变体的体外筛选方法,包括以下步骤:
(1)构建两个DNA单链文库,互为引物进行聚合酶链式反应获得线性单链DNA:所述两个单链DNA文库的序列如SEQ ID NO.1和SEQ ID NO.2所示,SEQ ID NO.1和SEQ ID NO.2的末端含有的互补区域;且SEQ ID NO.2末端带有rC修饰;
(2)以所述线性单链DNA为底物进行第一次环化反应;
(3)预筛选、筛选、成环、PCR扩增、二次成环;所述二次成环的引物如SEQ ID NO.3、SEQ ID NO.4所示。
本发明的另一个目的在于提供一种能快速水解DNA的脱氧核酶的应用,具体技术方案如下:
上述脱氧核酶突变体在切割长单链DNA中的应用
基于上述技术方案,本发明具有以下有益效果:
本发明通过引入特殊末端结构,设计了成环效率较高的DNA文库,进行筛选感应锌离子切割的实验,体外筛选到了另外一类III类脱氧核酶。设计相应的退化库,进行退化再筛选,从而获得快速水解切割DNA的III类脱氧核酶的突变体,从而满足不同DNA水解反应的需求,获得了能够感应锌离子并能快速水解DNA磷酸二酯键的III类脱氧核酶。
附图说明
图1为单链DNA文库成环效率检测结果图;
图2为体外筛选流程;
图3为III类脱氧核酶及其突变体的序列比对;
图4为Zn-III-R1序列结构及切割位点示意图;
图5为III类脱氧核酶及其突变体37℃动力学测试;
图6Zn-III-R3观察到的切割速率常数(k
图7为Zn-III-R3的离子特异性测试图;
图8为Zn-III-R3的pH依赖性及锌离子浓度依赖性测试图。
具体实施方式
为了便于理解本发明,下面将参照实施例对本发明进行更全面的描述,以下给出了本发明的较佳实施例。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。应理解,下列实施例中未注明具体条件的实验方法,通常按照常规条件,例如Sambrook等人,分子克隆:实验室手册(New York:Cold Spring Harbor Laboratory Press,1989)中所述的条件,或按照制造厂商所建议的条件。实施例中所用到的各种常用试剂,均为市售产品。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。
一种III类脱氧核酶突变体,其结构通式为:P1-(N)
其中(N)
P1与P1′上的核苷酸序列全部或部分互补配对而组成亚结构域1;
P2与P2′上的核苷酸序列全部或部分互补配对而组成亚结构域2。
优选的,所述(N)
更优选的,所述(N)
优选的,所述(N)
更优选的,所述(N)
在其中一些实施例中,本发明所述的脱氧核酶变体的序列为:序列如SEQ IDNO.15所示的序列或与SEQ ID NO.15同源性大于75%的序列。优选的,所述的脱氧核酶变体的序列与SEQ ID NO.15同源性大于80%。更优选的,所述的脱氧核酶变体的序列与SEQ IDNO.15同源性大于85%。进一步优选地,所述的脱氧核酶变体的序列与SEQ ID NO.15同源性大于90%。例如:同源性大于91%,92%,93%,94%,95%,96%,97%,98%或99%。
优选的,所述P2与P2′上的核苷酸序列全部或部分互补配对而组成亚结构域2中,P2与P2′之间含有长度为4-6nt的loop区域。可选的,所述loop区域长度为4nt、5nt或6nt。
本发明的脱氧核酶突变体的体外筛选方法,包括以下步骤:
(1)构建两个DNA单链文库,互为引物进行聚合酶链式反应获得线性单链DNA:所述两个单链DNA文库的序列如SEQ ID NO.1和SEQ ID NO.2所示,SEQ ID NO.1和SEQ ID NO.2的末端含有的互补区域;且SEQ ID NO.2末端带有rC修饰;
(2)以所述线性单链DNA为底物进行第一次环化反应;
(3)预筛选、筛选、成环、PCR扩增、二次成环;所述二次成环的引物如SEQ ID NO.3、SEQ ID NO.4所示。
优选的,还包括以下步骤:将权利要求15所述的步骤(3)获得产物的碱基进行部分随机化处理后,重复多次进行以下步骤:第一次环化反应、预筛选、筛选、成环、PCR扩增、二次成环。
更优选的,所述预筛选为:环化后的单链DNA文库通过PAGE分离回收,加入哌啶,加热;通过变性PAGE分离回收、常温洗脱;和/或
所述筛选为将预筛选获得的环状DNA在缓冲液1中变性,室温放置后加入预热好的等体积的缓冲液2,孵育,通过变性PAGE回收发生切割的线性DNA片段;所述缓冲液1的组分包括HEPES和LiCl;所述缓冲液2的组分包括HEPES、LiCl、MgCl
本发明中,对于碱基符号的定义:N表示随机碱基,R表示嘌呤和Y表示嘧啶。
不同的DNA分子由于进化上的原因,其核苷酸序列具有相同来源而具有的某些共性,表现在相应的位点具有相同的或相似的核苷酸残基。关于本发明中所述的“同源性”定义为候选序列中含有与特定序列中核苷酸相同的核苷酸的百分比。在比对序列后,将任何保守取代视为序列同一性的一部分。
实施例1重复感应锌离子切割的筛选
1.1构建DNA单链文库
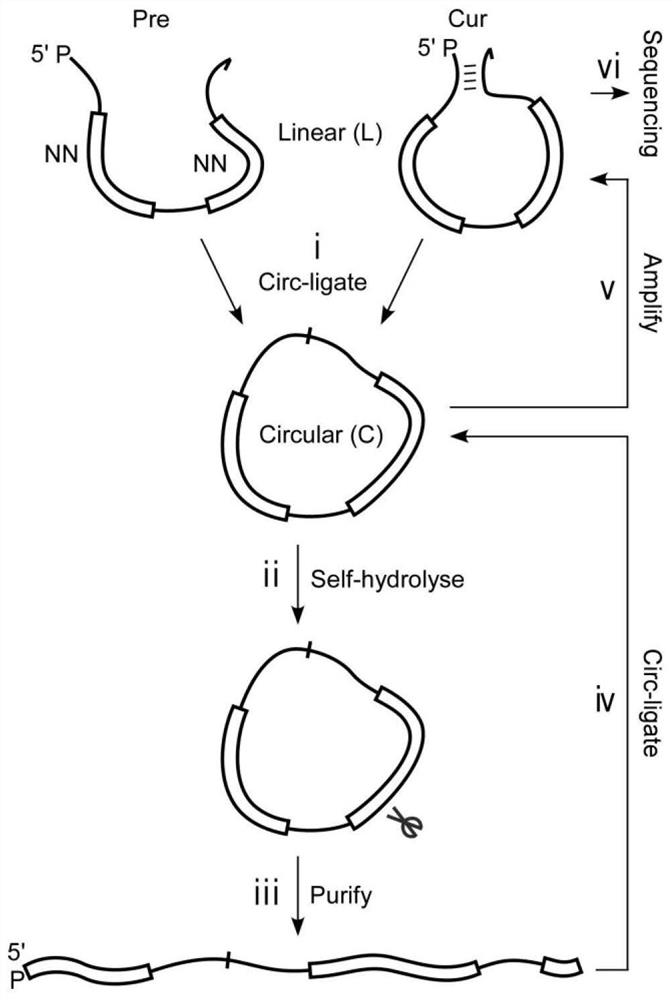
将末端杂交的结构设计到现用的ssDNA文库(Cur)中(即在序列的末端人为设计能够辅助成环的互补配对区域),使线性DNA文库能更有效地被CircLigase连接成环,从而为筛选过程中对水解切割序列的有效富集提供保障(现用文库成环效率达78%,远远高于未人为设计末端杂交结构的ssDNA文库做筛选时的成环效率32%,如图1所示)。由美国Integrated DNA Technologies(IDT)公司合成长度为82nt的单链DNA文库序列,经过10%变性聚丙烯酰胺凝胶电泳(Polyacrylamide Gel Electrophoresis,page)纯化后,用荧光成像仪和割胶仪回收目标条带。由于技术与成本限制,超过100bp的单链DNA在体外合成产率较低,且成本较高,所以本发明借助两个单链DNA文库末端15nt的互补区域(如SEQ IDNO.1和SEQ ID NO.2所示),使其互为引物在聚合酶链式反应(Polymerase ChainReaction,PCR)中延伸,从而建立双链DNA文库(随机碱基用N表示)。由于B文库的末端带有rC修饰,加入终浓度为0.25mM的NaOH 90℃加热5min后,可使含RNA修饰的单链DNA断裂,形成长短不同的两条单链。利用8%变性PAGE分离,即可获得含两段随机序列(50nt)的总长为149nt的单链DNA文库。
PCR反应体系:(50μl×15)
PCR反应条件:95℃预变性15s,之后每个循环95℃变性15s,42℃退火15s,72℃延伸30s,为保证所有引物延伸完成,进行5个循环;最后72℃终延伸2min。
A2文库(SEQ ID NO.1):
5′-pGTCCGTGCGCAGACCAA(N)
B文库(SEQ ID NO.2):
5′-GCTCGTGCGCAGACAGC(N)
其中,A2文库与B文库的下划线序列区域互补配对,即所述的末端杂交的结构。
第一次环化体系:
反应条件:60℃5h
1.2体外筛选
体外筛选,如图2所示。本发明采用指数富集的配基系统进化技术,在体外分为预筛选、筛选、成环、PCR扩增、二次成环等步骤进行。在6轮筛选后进行深度测序。具体筛选步骤如下:
1.2.1预筛选
为去除在筛选过程中形成的脱碱基位点,筛选出结构完整的脱氧核酶,在筛选步骤前加入预筛选过程。将环化后的单链DNA文库通过8%PAGE分离回收,加入50μl 0.1M哌啶,80℃加热30分钟。通过8%变性PAGE分离完好的环状单链DNA分子,切胶回收后常温洗脱3h。
1.2.2筛选
将回收的环状DNA在150μl缓冲液1中70℃变性5min,室温放置5min后加入等体积的缓冲液2,37℃下孵育1h,通过8%变性PAGE回收发生切割的线性DNA片段。(之后的筛选体系为25μl+25μl)
1.2.3二次成环反应
将回收的切割后形成的线性DNA片段进行二次成环反应,回收由线性单链DNA重新成环的DNA分子
二次成环体系:
反应条件:60℃2.5h。
1.2.4 PCR扩增DNA文库
将回收得到的环状单链DNA作为模板,利用PCR反应进行扩增,反应体系如下。
引物序列为:
Primer A2(SEQ ID NO.3):5'-pGTCCGTGCGCAGACCAA
Primer B(SEQ ID NO.4)5′-GCTCGTGCGCAGACAGrC
PCR反应条件:95℃预变性3min,之后每个循环95℃变性20s,54℃退火20s,72℃延伸15s,扩增30个循环;最后72℃终延伸2min。
注:反向引物3′修饰rC,可以通过NaOH处理PCR产物,使得修饰RNA的链在rC处断裂,形成两条长度不同的单链DNA链。随后通过8%变性PAGE分离纯化出目标单链DNA(无RNA修饰的DNA链)。再次构建环状单链DNA文库,重复之前的筛选过程。为筛选到更多种类的脱氧核酶,在筛选过程中并未施加筛选压力(改变筛选条件),最后在G6(第六轮筛选)库分离出DNA片段进行深度测序。得到除I类、II类酶外另外两类(III类和IV类)感应锌离子水解切割的脱氧核酶,命名为Zn-III-R1(SEQ ID NO.5),Zn-IV-R1。
2.退化再筛选过程
2.1构建退化库
在Zn-III-R1的基础上进行“退化”处理:在末端设计有助于成环的二级结构的基础上,将下划线部分的碱基进行部分随机化,其余序列保持不变,即下划线部分的各位点82%还保持原来的碱基,剩余的18%按其余三种碱基类型混合配比,各占6%。即在合成时各个位点82%按照序列所示的碱基合成,就比如:划线部分第一个序列是T,合成时有82%的序列为T,而A、C、G各占6%(即所说的剩余18%按其余三种碱基类型混合配比。合成时要求人工掺杂了四种脱氧核苷酸溶液,第一种是含82%的T,6%的A,6%的C,6%的G;第二种是含82%的A,6%的T,6%的C,6%的G,第三种是含82%的C,6%的T,6%的A,6%的G,第二种是含82%的G,6%的T,6%的C,6%的A。)
III类感应锌离子水解切割脱氧核酶(Zn-III-R1)的序列:
序列由上海捷瑞公司合成,经过10%变性聚丙烯酰胺凝胶电泳(polyacrylamidegel electrophoresis,PAGE)纯化后,用荧光成像仪和割胶仪回收目标序列。
第一次环化体系:
反应条件:60℃5h
2.2体外筛选
同之前体外筛选过程一致,重复预筛选、筛选、成环、PCR扩增、二次成环等步骤进行。对第5轮筛选到的序列进行深度测序,分析筛选过程中序列进化的保守性。如图3所示,图中底部划线、斜体、加粗标记的脱氧核苷酸分别保留至少75%,90%,97%的保守序列,而相对不保守的核苷酸用圆圈表示。阴影部分代表碱基对可以共变,R和Y分别代表嘌呤和嘧啶。碱基互补配的亚结构(P1&P2)也已经标记。在8轮筛选后进行挑克隆测序找出切割活性更高的脱氧核酶突变体。详细序列如表1所示。具体筛选步骤包括:
2.2.1预筛选
为去除在筛选过程中形成的脱碱基位点,筛选出结构完整的脱氧核酶,在筛选步骤前加入预筛选过程。将环化后的单链DNA文库通过10%PAGE分离回收,加入50μl 0.1M哌啶,80℃加热30分钟。通过10%变性PAGE分离完好的环状单链DNA分子,切胶回收后常温洗脱3h。
2.2.2筛选
将回收的环状DNA在150μl缓冲液1中70℃变性5min,室温放置5min后加入37℃预热好的等体积的缓冲液2,37℃下孵育40min,通过10%变性PAGE回收发生切割的线性DNA片段。(之后的筛选体系为25μl+25μl)
2.2.3二次成环反应
将得到的切割形成的线性DNA片段进行二次成环反应,回收由线性单链DNA重新成环的DNA分子
二次成环体系:
反应条件:60℃2.5h
2.2.4 PCR扩增DNA文库
将回收得到的环状单链DNA作为模板,利用PCR反应对富集的文库进行扩增,反应体系如下。
为增加退化库的序列多样性,筛选到活性更高的脱氧核酶,在第6、7轮筛选中引入突变PCR。
突变PCR反应体系如下:
引物序列为:
III类脱氧核酶退化库引物Primer-5′-pGACGTGCTAGCGCAG(SEQ ID NO.6)
III类脱氧核酶退化库引物Primer-3′-AGGTGCCTAGCGCArG(SEQ ID NO.7)
PCR反应条件:95℃预变性3min,之后每个循环95℃变性15s,45℃退火15s,72℃延伸15s,扩增30个循环;最后72℃终延伸2min。
突变PCR反应条件:95℃预变性3min,之后每个循环95℃变性1min,45℃退火1min,68℃延伸1min,扩增30个循环;最后72℃终延伸2min。
注:反向引物3′修饰RNA,可以通过NaOH处理PCR产物,使得修饰RNA的链在RNA处断裂,形成两条DNA链长度不一致。随后通过10%变性PAGE分离纯化出目标单链DNA(无RNA修饰的DNA链)。再次构建环状单链DNA文库,重复之前的筛选过程。在筛选过程中为得到活性更高的脱氧核酶突变体,需要不断的施加筛选压力。从G0到G5,筛选步骤中允许脱氧核酶反应的时间为40分钟;在G6筛选中,降低反应时间至30分钟;在G7和G8的筛选中,最后将反应时间降低至5分钟;最终在G8的筛选库中分离出DNA片段,并进行克隆测序,得到III类脱氧核酶的突变体Zn-III-R2,Zn-III-R3。
表1 Zn-III类脱氧核酶的序列分析总结表
实施例2切割位点测试
将15pmol脱氧核酶切割位点测试序列与200μl缓冲液1(50mM HEPES,100mM LiCl,pH 7.0)混匀,70℃加热5min,室温放置5min,加入等体积37℃预热的缓冲液2(50mM HEPES,100mM LiCl,10mM MgCl
切割位点测试序列:
Zn-III-R1-61nt:GCGCAGACCAACGAATGTTTTCATTCGTTTTTATGGACTGATCATGCCCTGCTGTCTGCGC(SEQ ID NO.18)
参比序列如下:
Zn-III-R1-Marker1-40nt:GCGCAGACCAACGAATGTTTTCATTCGTTTTTATGGACTG(SEQID NO.19)
Zn-III-R1-Marker1-39nt:GCGCAGACCAACGAATGTTTTCATTCGTTTTTATGGACT(SEQ IDNO.20)
Zn-III-R1-Marker1-38nt:GCGCAGACCAACGAATGTTTTCATTCGTTTTTATGGAC(SEQ IDNO.21)
Zn-III-R1-61nt切割后生成的5′端切割片段与参照序列中的SEQ ID NO.20条带位置一致,说明生成的5′端切割片段序列即为SEQ ID NO.20,即可确认Zn-III-R1-61n切割位点为T/G之间。结果如图4显示。
利用精确质谱对切割混合物的分子量进行表征,验证切割位点的同时证明水解切割。为了不超出精确质谱检测分子量的范围,将III类和IV类脱氧核酶沿碱基互补配对区域(P1,P2)分开,分为酶链与底物链,并将碱基互补配对区域缩短至7或8个碱基对。
质谱样品序列如下:
Zn-III-S-39nt:CATTCGTTTTTATGGACTGATCATGCCCTGCTGTCTGCG(SEQ ID NO.22)
Zn-III-E-16nt:CGCAGACCAACGAATG(SEQ ID NO.23)
在400μl反应体系中加入酶链和底物链各40pmol(1:1),37℃反应过夜后,乙醇沉降、烘干,以此作为精确质谱的样品。图中E、S分别对应于每类脱氧核酶的酶链和底物链,5′切割产物(5′clv),3′切割产物(3′clv)的质谱峰对应的分子量与理论计算的分子量基本一致,证明两类脱氧核酶均为水解切割。
实施例3动力学测试
为精确测得脱氧核酶的动力学参数,在脱氧核酶底物的5′端修饰FAM荧光基团,并用荧光检测的方法对脱氧核酶的切割情况进行定量表征。为使酶链与底物链稳定的形成切割所需要的结构,将III类和IV脱氧核酶及其突变体stem区域延长(Zn-III-R1 Zn-IV-R1stem区域延长至15bp,为测试活性更高的突变体在50℃反应的动力学参数,将Zn-III-R2,Zn-III-R3,Zn-IV-R2,Zn-IV-R3stem区域延长至20bp),并在上海捷瑞公司订购相应的酶链与5′荧光修饰的底物链。
动力学测试序列:
Zn-III-R1-E-31nt:CTGACATGCGCAGACCAACGAATGCTGGACC(SEQ ID NO.24)
Zn-III-R1-S-54nt:5'-FAM-GGTCCAGCATTCGTTTTTATGGACTGATCATGCCCTGCTGTCTGCGCATGTCAG(SEQ ID NO.25)
Zn-III-R2-E-41nt:CCGATCTGACCTAGCGCAGACTAACGACCGCTGGACTGGCA(SEQ IDNO.26)
Zn-III-R2-S-63nt:5-FAM-TGCCAGTCCAGCGGTCGTTGCTTTGGACAGATCATGCCTTGCTGCTGCGCTAGGTCAGATCGG(SEQ ID NO.27)
Zn-III-R3-E-42nt:CCGATCTGACCTAGCGCAGATCAACGACTGCCTGGACTGGCA(SEQ IDNO.28)
Zn-III-R3-S-64nt:5-FAM-TGCCAGTCCAGGCAGTCGTTCTTGTGGACGAATCATGCCCTGCTGCTGCGCTAGGTCAGATCGG(SEQ ID NO.29)
在120μl筛选体系中加入30pmol的酶链及10pmol底物链置于37℃反应,在0s,20s,40s,1min,2min,5min,10min,20min,40min,1h一系列时间点吸取8μl反应混合物,与2×上样缓冲溶液混合后,跑15%变性PAGE胶分离底物链与切割产物。
借助多功能荧光分析仪进行成像,并对凝胶条带进行定量分析。通过计算切割后生成的5′底物切割片段和总底物片段(切割后生成的底物切割片段加上未切割的全长底物片段)的比值,从而得出各时间点脱氧核酶的切割效率。反应速率常数kobs可以用下列公式计算:切割百分比=FCmax(1-e
选取切割速率最快的突变体Zn-III-R3和Zn-IV-R3,在30℃,45℃,50℃反应条件下分别进行动力学测试,计算各时间点的切割百分比及速率常数,结果如图6所示。
实施例4离子特异性检测及镁离子依赖性测试
将Zn-III-R3、Zn-IV-R3分别与2mM其他二价离子孵育20min,分析其水解切割的离子特异性。dPAGE结果如图7中A所示。比较其反应体系只有镁离子,只有锌离子及同时含有镁离子和锌离子的切割情况。切割百分比随时间变化的图像如图7中B所示。
实施例5pH依赖性及锌离子浓度依赖性测试
配制一系列pH梯度(pH 6.85,pH 6.95,pH 7.05,pH 7.15,pH 7.25,pH 7.35,pH7.45,pH 7.55)的筛选缓冲buffer1、2,分别与Zn-III-R3、Zn-IV-R3孵育20min。图8中A所示为其水解切割的15%dPAGE胶图及切割百分比随pH变化的图像。
改变筛选缓冲液中锌离子的终浓度(0.1mM,0.2mM,0.5mM,1mM,2mM,5mM,10mM,20mM),分别与Zn-III-R3、Zn-IV-R3孵育20min。图8中B所示为其水解切割的15%dPAGE胶图及切割百分比随锌离子浓度变化的图像。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对以上实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
序列表
<110> 复旦大学附属肿瘤医院
<120> III类脱氧核酶突变体及其制备方法与应用
<160> 29
<170> SIPOSequenceListing 1.0
<210> 1
<211> 82
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 1
gtccgtgcgc agaccaannn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 60
nnnnnnngac tgcatcacga ag 82
<210> 3
<211> 82
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 3
gctcgtgcgc agacagcnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 60
nnnnnnnctt cgtgatgcag tc 82
<210> 3
<211> 17
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 3
gtccgtgcgc agaccaa 17
<210> 4
<211> 17
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 4
gctcgtgcgc agacagc 17
<210> 5
<211> 81
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 5
gacgtgctag cgcagaccaa cgactgcttt tgcagtcgtt tttatggact gatcatgccc 60
tgctgtctgc gctaggcacc t 81
<210> 6
<211> 15
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 6
gacgtgctag cgcag 15
<210> 7
<211> 15
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 7
aggtgcctag cgcag 15
<210> 8
<211> 68
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 8
ctagcgcaga ctaacgactg cttttgcggt cgttgctttg gacagatcat gccttgctgc 60
tgcgctag 68
<210> 9
<211> 3
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 9
act 3
<210> 10
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 10
gctttggaca gatcatgcct tgctg 25
<210> 11
<211> 68
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 11
ctagcgcaga tcaacgactg cttttgcagt cgttcttgtg gacgaatcat gccctgctgc 60
tgcgctag 68
<210> 12
<211> 3
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 12
atc 3
<210> 13
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 13
cttgtggacg aatcatgccc tgctg 25
<210> 14
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 14
nytntggacn ratcrtgccy tg 22
<210> 15
<211> 68
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 15
ctagcgcaga yyaacgactg cttttgcngt cgttnytntg gacrratcat gccctgctgc 60
tgcgctag 68
<210> 16
<211> 3
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 16
ayy 3
<210> 17
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 17
nytntggacr ratcatgccc tgctg 25
<210> 18
<211> 61
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 18
gcgcagacca acgaatgttt tcattcgttt ttatggactg atcatgccct gctgtctgcg 60
c 61
<210> 19
<211> 40
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 19
gcgcagacca acgaatgttt tcattcgttt ttatggactg 40
<210> 20
<211> 39
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 20
gcgcagacca acgaatgttt tcattcgttt ttatggact 39
<210> 21
<211> 38
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 21
gcgcagacca acgaatgttt tcattcgttt ttatggac 38
<210> 22
<211> 39
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 22
cattcgtttt tatggactga tcatgccctg ctgtctgcg 39
<210> 23
<211> 16
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 23
cgcagaccaa cgaatg 16
<210> 24
<211> 31
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 24
ctgacatgcg cagaccaacg aatgctggac c 31
<210> 25
<211> 54
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 25
ggtccagcat tcgtttttat ggactgatca tgccctgctg tctgcgcatg tcag 54
<210> 26
<211> 41
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 26
ccgatctgac ctagcgcaga ctaacgaccg ctggactggc a 41
<210> 27
<211> 63
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 27
tgccagtcca gcggtcgttg ctttggacag atcatgcctt gctgctgcgc taggtcagat 60
cgg 63
<210> 28
<211> 42
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 28
ccgatctgac ctagcgcaga tcaacgactg cctggactgg ca 42
<210> 29
<211> 64
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 29
tgccagtcca ggcagtcgtt cttgtggacg aatcatgccc tgctgctgcg ctaggtcaga 60
tcgg 64
- III类脱氧核酶突变体及其制备方法与应用
- IV类脱氧核酶突变体及其制备方法与应用