一种数据处理方法及装置
文献发布时间:2023-06-19 09:46:20
技术领域
本说明书实施例涉及多核处理器领域,尤其涉及一种数据处理方法及装置。
背景技术
目前,多核处理器具有每个核心的私有缓存。某个核心可以使用独占方式读取数据,具体是先读取数据到自身的私有缓存中,将该数据置于独占状态,表示该数据当前仅被该核心读取到私有缓存中。该核心可以进一步将该数据从自身的私有缓存中取出进行修改,然后将修改后的该数据写回到自身的私有缓存中。
考虑到在该核心将修改后的该数据写回到自身的私有缓存之前,可能出现一个或多个其他核心也读取该数据到各自的私有缓存的情况。在这种情况下,该数据的独占状态会改变,同时为了满足数据一致性(即同一数据的版本在所有核心间都是一致的),该核心需要先针对其他核心的私有缓存中的该数据进行无效化,再将修改后的数据写回自身的私有缓存中。
然而,该核心对其他核心的私有缓存中的该数据进行无效化的过程涉及较为频繁的核心间通信,因此无效化的过程会拖延该核心将修改后的该数据写回到自身私有缓存的时间。
发明内容
为了解决上述问题,本说明书提供了一种数据处理方法及装置。技术方案如下所示。
一种数据处理方法,应用于多核处理器的指定核心,所述多核处理器的每个核心具有私有缓存,所述方法包括:
确定需要以独占方式读取目标数据之后,查询所述目标数据的状态;所述目标数据置于锁定状态或非锁定状态,在所述目标数据置于锁定状态的情况下,任一核心不能将所述目标数据读取到自身的私有缓存中;
确定查询结果为非锁定状态之后,将所述目标数据读取到自身的私有缓存中,并设置所述目标数据为锁定状态;
确定需要修改自身私有缓存中的所述目标数据之后,在完成修改的情况下,设置所述目标数据为非锁定状态。
一种数据处理装置,应用于多核处理器的指定核心,所述多核处理器的每个核心具有私有缓存,所述装置包括:
查询单元:用于确定需要以独占方式读取目标数据之后,查询所述目标数据的状态;所述目标数据置于锁定状态或非锁定状态,在所述目标数据置于锁定状态的情况下,任一核心不能将所述目标数据读取到自身的私有缓存中;
读取单元:用于确定查询结果为非锁定状态之后,将所述目标数据读取到自身的私有缓存中,并设置所述目标数据为锁定状态;
修改单元:用于确定需要修改自身私有缓存中的所述目标数据之后,在完成修改的情况下,设置所述目标数据为非锁定状态。
通过上述技术方案,为待处理的目标数据配置可切换的锁定状态和非锁定状态,使得目标数据在并未被任一核心以独占方式读取的情况下,置于非锁定状态,而一旦被某个核心以独占方式读取,则将对应的状态切换为锁定状态。置于锁定状态的目标数据不能再被其他核心以任何方式读取到其他核心的私有缓存中。如此,不会存在其他核心在目标数据置于锁定状态的期间(具体可以包括指定核心以独占方式读取、以及修改目标数据的期间)将目标数据读取到自身私有缓存的情况,这意味着指定核心在将修改后的目标数据写回到自身的私有缓存之前,不会面对“存在至少一个其他核心在目标数据置于锁定状态的期间(具体可以包括指定核心以独占方式读取、以及修改目标数据的期间)、将目标数据读取到自身私有缓存中”的情况,也就不必对这至少一个其他核心的私有缓存中的目标数据进行无效化,加快指定核心将修改后的目标数据写回到自身私有缓存的时间。
附图说明
为了更清楚地说明本说明书实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书实施例中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
图1是本说明书实施例提供的一种多核处理器的结构示意图;
图2是本说明书实施例提供的一种数据处理方法的流程示意图;
图3是本说明书实施例提供的一种数据处理方法的原理示意图;
图4是本说明书实施例提供的一种数据处理装置的结构示意图。
具体实施方式
为了使本领域技术人员更好地理解本说明书实施例中的技术方案,下面将结合本说明书实施例中的附图,对本说明书实施例中的技术方案进行详细地描述,显然,所描述的实施例仅仅是本说明书的一部分实施例,而不是全部的实施例。基于本说明书中的实施例,本领域普通技术人员所获得的所有其他实施例,都应当属于保护的范围。
多核处理器是一种集成了两个以上计算引擎的处理器,其中每个计算引擎可以视为一个核心,不同核心之间可以并行进行独立计算,提高了处理器的计算性能。
目前,多核处理器不仅具有多个核心间的公共缓存,还具有每个核心的私有缓存。
如图1所示,为本说明书提供的一种多核处理器的结构示意图,其中包括3个核心、1个公共缓存以及3个核心各自的私有缓存。
在多核处理器中,任一核心(为了描述的方便,后文将任一核心称为指定核心,将指定核心之外的核心称为其他核心)可以将数据读取到指定核心的私有缓存中。在需要修改数据的情况下,指定核心可以将该数据从自身的私有缓存中取出进行修改,再将修改后的该数据写回到自身的私有缓存中。
数据可以存储在公共缓存或私有缓存中,指定核心可以从这些缓存中读取数据。指定核心具体读取时,需要读取数据的最新版本。公共缓存中的数据可以对应于表征数据最新版本的存储位置的标识,任一核心可以根据该标识确定数据最新版本的存储位置。因此,指定核心可以根据数据在公共缓存中对应的标识,确定数据最新版本的存储位置,进而读取数据的最新版本到私有缓存中。
而指定核心针对数据的读取,存在两种读取方式,包括独占方式读取和非独占方式读取。
其中,独占方式读取具体是指定核心将数据读取到指定核心的私有缓存,并将数据置于独占状态。独占状态可以表示该数据正在被指定核心以独占方式读取。而非独占方式读取并不会将数据置于独占状态,具体可以是普通的读取操作。
但是独占状态并不意味着数据不会被其他核心读写,其他核心仍然可以读取或修改置于独占状态的数据。而一旦任一其他核心读取或修改置于独占状态的数据,其他核心会将数据从独占状态切换到其他状态。因此,独占状态的设置可以方便指定核心确定不存在其他核心读取该数据。
也就是说,在指定核心以独占方式读取数据之后,一个或多个其他核心可以将同一数据读取到各自的私有缓存中。
而指定核心在以独占方式读取数据之后,在指定核心需要修改该数据的情况下,指定核心可以将该数据从自身的私有缓存中取出进行修改。
考虑到在指定核心将修改后的该数据写回到自身的私有缓存之前,可能出现一个或多个其他核心也读取该数据到各自的私有缓存的情况。在这种情况下,该数据的独占状态会被切换为其他状态,同时为了满足数据一致性(即同一数据的版本在所有核心间都是一致的),该核心需要先针对其他核心的私有缓存中的该数据进行无效化,再将修改后的数据写回自身的私有缓存中。
在指定核心将修改后的该数据写回到自身的私有缓存之前,可能存在至少一个其他核心也会将同一数据读取到自身的私有缓存中。也就是说,对于同一数据(假设为版本A)而言,在该数据被指定核心修改成下一版本B之前,可能存在多个核心(至少一个其他核心)也会将版本A的数据读取到各自的私有缓存中,可能进行修改,也可能并不修改,得到A版本的数据、A1版本的数据、A2版本的数据……。
在多个核心都将同一数据读取到私有缓存的情况下,需要满足数据一致性的要求(各个缓存之间只能有一个版本的数据是唯一有效的)。
因此,在指定核心将版本B的数据写回到私有缓存之前,需要将其他核心的私有缓存中的全部版本的同一数据(A版本的数据、A1版本的数据、A2版本的数据……)都进行无效化。只保留指定核心所修改的版本B的数据作为唯一有效的数据。
此外,如果其他核心在指定核心将版本B的数据写回到私有缓存之前,也对版本A的数据进行了修改,得到版本C的数据写回到自身的私有缓存中,则指定核心本次修改失败,指定核心的私有缓存中的版本A的数据(未将版本B写回到私有缓存)被该其他核心无效化,将版本C的数据作为唯一有效的数据。
为了便于理解,下面给出一种具体的示例用于说明。
针对核心1-3,核心1以独占方式读取数据,核心2和核心3将同一数据读取到各自的私有缓存中。在核心1最先完成数据修改后,确定核心1具有本次修改权限,因此,针对核心2和核心3,核心1可以将全部其他核心(包括核心2和核心3)的私有缓存中的同一数据都无效化,再将修改后的数据写回到自身的私有缓存中,使得全部核心中只有核心1的私有缓存中具有有效的该数据。
一般而言,修改后得到的数据最新版本可以存储在执行本次修改的指定核心的私有缓存中。对应地,该数据在公共缓存中对应于表征指定核心的私有缓存的标记。也可以将修改后得到的数据最新版本存储在公共缓存中。对应地,该数据在公共缓存中可以对应于表征公共缓存的标记。以便于在下一次处理时,可以根据该标记确定数据最新版本的存储位置。
然而,指定核心对其他核心的私有缓存中同一数据进行无效化的过程涉及较为频繁的核心间通信,即,指定核心需要对这些其他核心的私有缓存中的该数据进行无效化,并需要等待接收这些其他核心分别返回的无效化成功通知。等到其他核心全部无效化成功后,再将修改后的数据写回到自身的私有缓存中。
可见,对这些其他核心的私有缓存中的该数据完成无效化的过程比较耗时,会拖延指定核心将修改后的该数据写回到自身私有缓存的时间。
为了解决上述问题,在本说明书的一个或多个实施例中,为待处理的目标数据配置可切换的锁定状态和非锁定状态,使得目标数据在并未被任一核心以独占方式读取的情况下,置于非锁定状态,而一旦被某个核心以独占方式读取,则将对应的状态切换为锁定状态。置于锁定状态的目标数据不能再被其他核心以任何方式读取到其他核心的私有缓存中。如此,不会存在其他核心在目标数据置于锁定状态的期间(具体可以包括指定核心以独占方式读取、以及修改目标数据的期间)将目标数据读取到自身私有缓存的情况,这意味着指定核心在将修改后的目标数据写回到自身的私有缓存之前,不会面对“存在至少一个其他核心在目标数据置于锁定状态的期间(具体可以包括指定核心以独占方式读取、以及修改目标数据的期间)、将目标数据读取到自身私有缓存中”的情况,也就不必对这至少一个其他核心的私有缓存中的目标数据进行无效化,加快指定核心将修改后的目标数据写回到自身私有缓存的时间。
为了便于理解上述技术效果,下面提供一个具体示例进行说明。
例如,在指定核心将修改后的目标数据写回到自身的私有缓存之前,存在38个其他核心也需要将目标数据读取到各自的私有缓存中。基于现有方式,38个其他核心可以将目标数据读取到各自的私有缓存中,因此,在指定核心将修改后的目标数据写回到自身的私有缓存之前,需要针对38个其他核心的私有缓存中的目标数据进行无效化,并等待38个其他核心的私有缓存中的目标数据完成无效化,才能继续将修改后的目标数据写回到指定核心的私有缓存中。而基于本说明书提供的实施例,指定核心以独占方式读取目标数据之后,将目标数据对应的状态切换为锁定状态。由于目标数据对应的状态为锁定状态,不会存在“38个其他核心在目标数据对应的状态为锁定状态的期间(具体可以包括指定核心以独占方式读取、以及修改目标数据的期间),将目标数据读取到自身的私有缓存”的情况,因此,不需要针对38个其他核心的私有缓存中的目标数据进行无效化,也就不需要等待38个其他核心的私有缓存中的目标数据完成无效化,加快指定核心将修改后的目标数据写回到自身私有缓存的时间。
下面针对锁定状态和非锁定状态进行解释。
某个数据对应的状态为锁定状态,可以表示该数据已经被某一核心以独占方式读取到私有缓存中。
某个数据对应的状态为非锁定状态,可以表示该数据没有被任一核心以独占方式读取,可以被任一核心读取到私有缓存中。
在有些实施例中,可以基于为该数据添加标记的方式为数据配置对应的状态。具体而言,针对目标数据,目标数据具有第一标记,可以表明目标数据置于锁定状态,目标数据具有第二标记,可以表明目标数据置于非锁定状态。其中,第一标记和第二标记可以是数字形式,也可以是其他字符形式。相对应地,为数据切换锁定状态或者非锁定状态,可以是切换数据的标记。
例如,可以为目标数据配置一个状态标记位,当状态标记位的值为1时,可以表示目标数据对应的状态为锁定状态;当状态标记位的值为0时,可以表示目标数据对应的状态为锁定状态;而将状态标记位从0切换到1,可以表示将目标数据对应的状态从锁定状态切换为非锁定状态;将状态标记位从1切换到0,可以表示将目标数据对应的状态从非锁定状态切换为锁定状态。
锁定状态和非锁定状态可以为目标数据配置,而目标数据可以是待处理的任一数据。因此,可以理解的是,针对待处理的每个数据都可以配置锁定状态和非锁定状态。
而具体存储数据对应的状态的存储区域可以是全部核心可以查询访问的存储区域。例如,多核处理器的公共缓存。
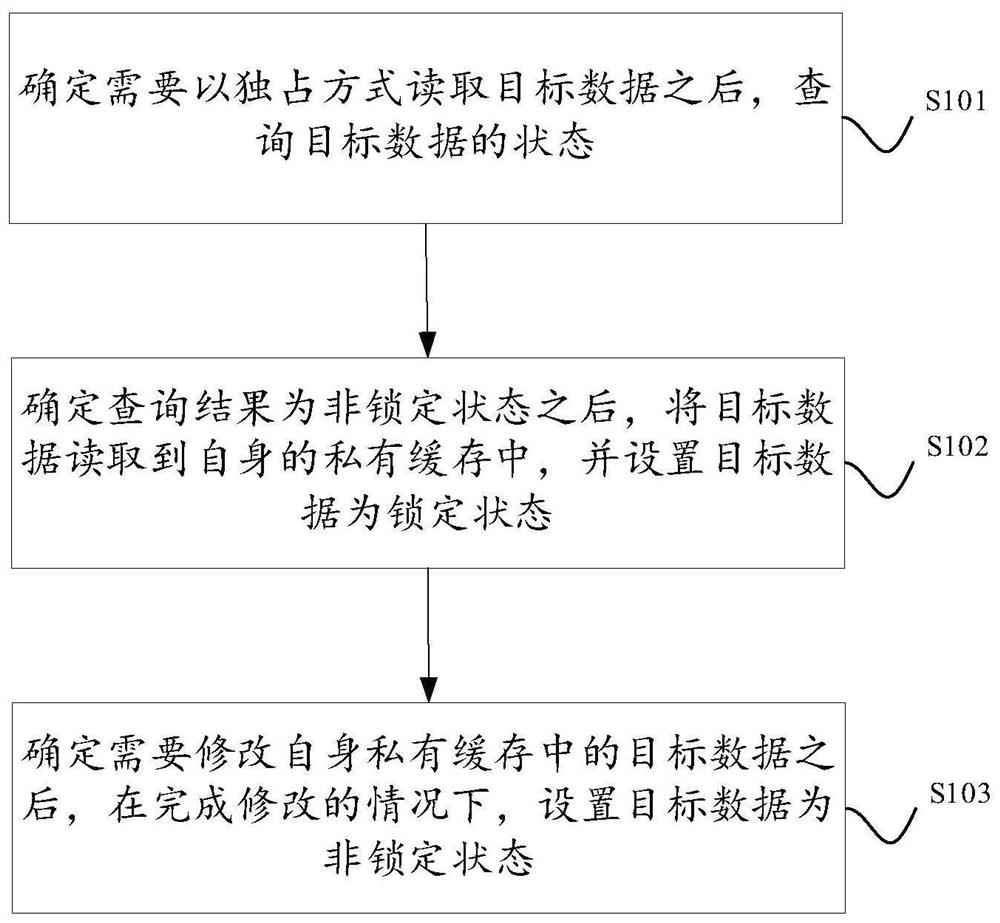
如图2所示,为本说明书提供的一种数据处理方法的流程示意图。该方法的执行主体可以是多核处理器中的任一核心。为了方便描述,将该方法的执行主体称为指定核心。多核处理器可以具有多个核心间的公共缓存以及每个核心的私有缓存。图2所示的方法可以至少包括以下步骤。
S101:确定需要以独占方式读取目标数据之后,查询目标数据的状态。
目标数据可以是指定核心需要处理的任一数据,可以存储在指定核心可以读取的存储区域中,具体可以是公共缓存、内存或者某一核心的私有缓存中。指定核心的处理具体可以包括读取或者读写。
目标数据可以对应有状态,具体可以置于锁定状态或非锁定状态。该状态可以是预先为目标数据额外配置的。
在目标数据置于锁定状态的情况下,任一核心不能将目标数据读取到自身的私有缓存中。也就是说,在目标数据置于锁定状态的情况下,任一核心不能将目标数据以任何方式读取到自身的私有缓存中。
下面针对非独占方式读取和独占方式读取,分别提供两种具体的实施例。
1)在目标数据置于锁定状态的情况下,任一核心在确定需要以非独占方式读取目标数据之后,可以查询目标数据的状态;确定查询结果为锁定状态之后,可以将目标数据读取到自身的处理队列中。
处理队列具体可以是多核处理器中的流水线结构,其一般包含核心正在使用或将要使用的数据。对于处理队列中的数据,可以在使用之后直接丢弃,并不会写回到私有缓存中,因此并不会破坏数据一致性,也就不需要针对处理队列中的数据进行无效化。
2)在目标数据置于锁定状态的情况下,任一核心在确定需要以非独占方式读取目标数据之后,可以查询目标数据的状态;确定查询结果为锁定状态之后,可以监测目标数据的状态;待监测到目标数据置于非锁定状态之后,可以将目标数据读取到自身的私有缓存中,并可以设置目标数据为锁定状态。
也就是说,核心可以不断监测目标数据的状态,具体可以是周期性检测目标数据的状态,从而避免核心将目标数据读取到自身的私有缓存中。
当然,在目标数据置于锁定状态的情况下,还存在其他方式使得任一核心不能将目标数据以任何方式读取到自身的私有缓存中,例如,在目标数据置于锁定状态的情况下,任一核心停止对目标数据的任何处理。以上两个实施例仅仅用于示例性说明。
相对应地,在确定查询结果为锁定状态之后,表示目标数据正在被某一其他核心以独占方式读取,指定核心不能以独占方式读取目标数据。
根据上述实施例,指定核心可以监测目标数据的状态;待监测到目标数据置于非锁定状态之后,可以将目标数据读取到自身的私有缓存中,并可以设置目标数据为锁定状态。
指定核心也可以周期性查询目标数据的状态,具体可以是在本次周期内停止对目标数据的处理之后,等待下一周期再开始执行S101中的查询操作。
S102:确定查询结果为非锁定状态之后,将目标数据读取到自身的私有缓存中,并设置目标数据为锁定状态。
目标数据置于非锁定状态的情况下,由于非锁定状态表示目标数据没有被其他核心以独占方式读取,因此,指定核心可以利用独占方式将目标数据读取到自身的私有缓存中。
而为了防止其他核心将目标数据读取到各自的私有缓存中,指定核心可以将设置目标数据为锁定状态,具体可以是将目标数据对应的状态切换为锁定状态。
S102中“将目标数据读取到自身的私有缓存中的操作”与“设置目标数据为锁定状态的操作”可以同时执行,也可以先后执行(执行顺序并不限定)。
在指定核心将目标数据的状态切换为锁定状态后,其他核心在基于图2所示的方法以独占方式读取目标数据时,会查询到目标数据的状态为锁定状态,则可以基于上述S101中所列的实施例,不能将目标数据读取到其他核心的私有缓存中。
S103:确定需要修改自身私有缓存中的目标数据之后,在完成修改的情况下,设置目标数据为非锁定状态。
由于在指定核心将目标数据的状态切换为锁定状态后,其他核心不能将目标数据读取到其他核心的私有缓存中,因此,指定核心在将修改后的目标数据写回到自身的私有缓存之前,无需针对这些其他核心的私有缓存中的目标数据执行无效化操作,加快指定核心将修改后的目标数据写回到自身私有缓存的时间。
而在指定核心将修改后的目标数据写回到自身私有缓存之后,指定核心可以设置目标数据为非锁定状态,具体可以是将目标数据对应的状态切换为非锁定状态,便于后续任一核心针对目标数据的处理(针对目标数据的读取、读写或修改)。
此外,在指定核心将修改后的目标数据保留在自身的私有缓存中的情况下,S103中,还可以为目标数据添加用于表征指定核心的标识。该标识可以用于表示最新版本的目标数据存储在指定核心的私有缓存中,以便于执行目标数据的下一次处理的核心可以确定最新版本的目标数据的存储位置。该标识也可以用于表示目标数据的最近一次修改是由指定核心执行的。
对应地,在指定核心将修改后的目标数据保留在公共缓存中的情况下,S103中,还可以为目标数据添加用于表征公共缓存的标识,表示最新版本的目标数据存储在公共缓存中。标识的存储区域可以是全部核心能够查询访问的存储区域,例如,公共缓存。
需要注意的是,指定核心也可能在以独占方式读取目标数据后,并不对目标数据进行修改。则目标数据的状态可以通过其他方式切换为非锁定状态,便于任一核心继续进行处理。
在一种可选的实施例中,在任一其他核心完成对目标数据的修改的情况下,目标数据可以被该其他核心设置为非锁定状态。具体可以是其他核心在不将目标数据读取到自身的私有缓存的情况下,直接对目标数据(具体可以是公共缓存汇总的目标数据)进行修改,在完成对目标数据的修改之后,可以将目标数据的状态切换为非锁定状态。
通过上述图2所示的方法流程,为待处理的目标数据配置可切换的锁定状态和非锁定状态,使得目标数据在并未被任一核心以独占方式读取的情况下,置于非锁定状态,而一旦被某个核心以独占方式读取,则将对应的状态切换为锁定状态。置于锁定状态的目标数据不能再被其他核心以任何方式读取到其他核心的私有缓存中。如此,不会存在其他核心在目标数据置于锁定状态的期间(具体可以包括指定核心以独占方式读取、以及修改目标数据的期间)将目标数据读取到自身私有缓存的情况,这意味着指定核心在将修改后的目标数据写回到自身的私有缓存之前,不会面对“存在至少一个其他核心在目标数据置于锁定状态的期间(具体可以包括指定核心以独占方式读取、以及修改目标数据的期间)、将目标数据读取到自身私有缓存中”的情况,也就不必对这至少一个其他核心的私有缓存中的目标数据进行无效化,加快指定核心将修改后的目标数据写回到自身私有缓存的时间。
需要注意的是,上述图2所示的方法流程是针对指定核心而言的,可以理解的是,多核处理器中任一核心都可以执行上述图2所示的方法流程。
基于上述图2所示的方法流程,在目标数据置于锁定状态的期间,不会存在其他核心将目标数据读取到私有缓存中的情况。但在指定核心以独占方式读取数据、设置数据为锁定状态之前,同一数据可能已经存在于其他核心的私有缓存中。
下面介绍两种具体“在指定核心以独占方式读取数据、设置数据为锁定状态之前,该数据存在于其他核心的私有缓存中”情况。
情况一:在有些实施例中,指定核心在完成修改之后,可以在自身的私有缓存中保留修改后的目标数据。
针对S103,在完成修改之后,S103中可以将修改后的目标数据保留在自身的私有缓存。
在这种情况下,对于执行目标数据下一次处理的核心而言,在以独占方式读取目标数据之前,目标数据已经保留在指定核心的私有缓存中。换言之,指定核心在以独占方式读取目标数据之前,目标数据可以保留在执行目标数据的以往处理的核心的私有缓存中。
通常情况下,指定核心在私有缓存中保留修改后的目标数据,可以是为了便于指定核心继续执行目标数据的下一次处理,可以直接在私有缓存中进行处理,无需将目标数据读取到私有缓存中。因此,如果指定核心预测目标数据的下一次处理还是指定核心执行,可以将目标数据保留在自身的私有缓存中。
作为一种可选的实施例,基于核心读取数据的一个规律,针对连续两次修改同一数据的核心,该核心存在较大可能还需要处理同一数据。因此,针对执行目标数据当前修改的核心,可以基于执行目标数据的上一次修改的核心,确定是否在私有缓存中保留目标数据。
例如,针对执行完目标数据当前修改的指定核心,若确定目标数据的上一次修改也是由指定核心执行的,则可以将修改后的目标数据保留在自身的私有缓存,从而便于指定核心在下一次目标数据的处理中,直接在私有缓存中处理最新版本的目标数据,无需再将最新版本的目标数据读取到私有缓存中,提高数据处理速度。相对应地,若确定目标数据的上一次修改是由其他核心执行的,则可以不保留目标数据,将私有缓存中修改后的目标数据无效化,并将修改后的目标数据写入公共缓存,以便于执行下一次目标数据的处理的核心可以直接将目标数据从公共缓存中读取到自身的私有缓存中,无需再从指定核心的私有缓存中读取。
而具体确定“执行目标数据的上一次修改的核心”,可以是任一核心在完成对目标数据的修改后,为目标数据对应添加该核心的标识,该标识可以表示目标数据的最近一次修改是该核心执行的,以便于执行目标数据的下一次处理的核心,可以根据该标识确定“执行目标数据的上一次修改的核心”。标识的存储区域可以是全部核心能够查询访问的存储区域,例如,公共缓存。
情况二:核心基于非独占方式读取数据时,往往也会将数据读取到私有缓存中。而在上述图2所示的方法流程中,只限定了“在目标数据置于锁定状态的情况下,任一核心不能将目标数据以任何方式读取到自身的私有缓存中”,其中,核心基于非独占方式读取数据时,可以将数据读取到处理队列中,而不是私有缓存中。但并没有限定“目标数据置于非锁定状态”的情况。
因此,在有些实施例中,目标数据置于非锁定状态的情况下,任一核心可以基于非独占方式,将目标数据读取到自身的私有缓存中。也就是说,在指定核心以独占方式读取目标数据之前,其他核心可以在“目标数据置于非锁定状态”的情况下,将目标数据读取到私有缓存中。
综合上述两种情况,结合上述图2所示的方法流程,尽管指定核心不会面对“存在至少一个其他核心在目标数据置于锁定状态的期间、将目标数据读取到自身私有缓存中”的情况,但还可能需要面对“存在至少一个其他核心在目标数据置于非锁定状态的期间、将目标数据读取到自身私有缓存中”的情况。
例如,执行目标数据的以往处理的核心在自身的私有缓存中保留目标数据;或者目标数据置于非锁定状态的情况下,存在至少一个核心基于非独占方式,将目标数据读取到自身的私有缓存中。
因此,尽管指定核心不必对“在目标数据置于锁定状态的期间、将目标数据读取到自身私有缓存中”的其他核心的私有缓存中的目标数据进行无效化,但仍然需要对“在指定核心以独占方式读取目标数据之前将目标数据保留在自身私有缓存中”的其他核心的私有缓存中的目标数据进行无效化。
在一种可选的实施例中,针对“在指定核心以独占方式读取目标数据之前将目标数据保留在自身私有缓存中”的其他核心的私有缓存中的目标数据所进行的无效化,可以在指定核心完成对自身私有缓存中目标数据的修改之前完成。
具体可以是指定核心在将修改后的目标数据写回到自身的私有缓存之前,将其他核心的私有缓存中的目标数据无效化。无效化的执行顺序并不限定,也可以与指定核心针对目标数据的其他操作并行执行,例如,修改目标数据、将目标数据读取到自身的私有缓存。只要在将目标数据读取到自身的私有缓存之前完成即可。进一步加快指定核心将修改后的目标数据写回到自身私有缓存的时间。
因此,S103可以包括:判断是否存在至少一个其他核心的私有缓存中有目标数据;确定判断结果为存在之后,将这至少一个其他核心的私有缓存中的目标数据在完成修改之前无效化。
具体可以是:在将目标数据读取到自身的私有缓存之前,将这至少一个其他核心的私有缓存中的目标数据无效化。
无效化操作可以是将私有缓存中原本有效的数据失效。具体可以是核心将处理目标数据的操作(例如读取目标数据的操作、修改目标数据的操作)回滚,恢复到未处理目标数据的状态;也可以是将私有缓存中的目标数据打上标记,表示目标数据在私有缓存中无效;也可以是直接将私有缓存中的目标数据删除。
为了便于理解上述实施例的技术效果,下面提供一个具体示例进行说明。
例如,在指定核心以独占方式读取目标数据之前,存在2个其他核心以非独占方式将目标数据读取到各自的私有缓存中。在指定核心将修改后的目标数据写回到自身的私有缓存之前,存在38个其他核心也需要将目标数据读取到各自的私有缓存中。基于现有方式,38个其他核心可以将目标数据读取到各自的私有缓存中,使得目标数据保留在40个其他核心的私有缓存中。因此,在指定核心将修改后的目标数据写回到自身的私有缓存之前,需要针对40个其他核心的私有缓存中的目标数据进行无效化,并等待40个其他核心的私有缓存中的目标数据完成无效化,才能继续将修改后的目标数据写回到指定核心的私有缓存中。而基于本说明书提供的实施例,指定核心以独占方式读取目标数据之后,将目标数据对应的状态切换为锁定状态。由于目标数据对应的状态为锁定状态,不会存在“38个其他核心在目标数据置于锁定状态的期间(具体可以包括指定核心以独占方式读取、以及修改目标数据的期间),将目标数据读取到自身的私有缓存”的情况,因此,只需要针对2个其他核心的私有缓存中的目标数据进行无效化,不需要针对38个其他核心的私有缓存中的目标数据进行无效化,也就不需要等待38个其他核心的私有缓存中的目标数据完成无效化,加快指定核心将修改后的目标数据写回到自身私有缓存的时间。
为了便于进一步理解,本说明书还提供了一种应用实施例。
如图3所示,为本说明书提供的一种数据处理方法的原理示意图。其中,数据处理方法可以应用于多核处理器,包括针对同一目标数据的3次修改。3次修改分别是核心0、核心0以及核心1执行的。同时为了区分3次修改中的目标数据版本,将3次修改中的目标数据版本称为目标数据0、目标数据1、目标数据2以及目标数据3。
为了便于理解,核心0针对目标数据0所执行的修改是目标数据0的第一次修改。在第一次修改之前,多核处理器中的每个核心都没有将目标数据0读取到私有缓存。
S201:核心0确定需要以独占方式读取目标数据0之后,确定公共缓存中目标数据0的状态置于非锁定状态,将目标数据0读取到自身的私有缓存中,并将目标数据0在公共缓存中的状态设置为锁定状态,使得其他核心不能将目标数据0读取到各自的私有缓存中。
目标数据的状态可以存储在公共缓存中。
S202:核心0确定需要修改目标数据0之后,对目标数据0进行修改得到目标数据1,写回到自身的私有缓存中。
S203:核心0将修改后得到的目标数据1写入公共缓存,替换原有的目标数据0,再将目标数据1在公共缓存中的状态设置为非锁定状态。
显然,由于第一次修改之前,目标数据0预先没有被读取到其他核心的私有缓存中,并且在目标数据置于锁定状态的过程中,其他核心不能将目标数据0读取到私有缓存,因此,目标数据1在S203中仅存在于核心0的私有缓存中,核心0无需在完成修改数据之后针对其他核心的私有缓存执行无效化操作,加快了目标数据写回到私有缓存的时间。
S204:核心0删除自身的私有缓存中修改后得到的目标数据1。
由于目标数据0并不存在上次修改,因此核心0并不会保留目标数据1在私有缓存中,并且可以将修改后得到的目标数据1写入公共缓存。
S205:核心0确定需要以独占方式读取目标数据1之后,确定公共缓存中目标数据1的状态置于非锁定状态,将目标数据1读取到自身的私有缓存中,并将目标数据1在公共缓存中的状态设置为锁定状态,使得其他核心不能将目标数据1读取到各自的私有缓存中。
S206:核心0确定需要修改目标数据1之后,对目标数据1进行修改得到目标数据2,写回到自身的私有缓存中。
S207:核心0将目标数据1在公共缓存中的状态设置为非锁定状态,在自身的私有缓存中保留目标数据2。
由于目标数据1的修改也是由核心0执行的,针对目标数据的两次修改都是核心0执行的,因此,核心0可以保留目标数据2在私有缓存中,以便于之后直接处理目标数据。
S208:核心1确定需要以独占方式读取目标数据1之后,并确定公共缓存中目标数据1的状态置于非锁定状态,则确定最新版本的目标数据2的存储位置是核心0的私有缓存,将目标数据2读取到自身的私有缓存中。
S209:核心1将核心0的私有缓存中的目标数据2无效化,并将目标数据1在公共缓存中的状态设置为锁定状态,使得其他核心不能将目标数据2或者目标数据1读取到各自的私有缓存中。
针对在以独占方式读取目标数据之前,将目标数据读取到私有缓存、或者在以往处理中将目标数据保留在私有缓存的情况,需要进行无效化。
S210:核心1确定需要修改目标数据2之后,对目标数据2进行修改得到目标数据3。
S211:由于目标数据上次修改是核心0执行的,因此,核心1将修改后得到的目标数据3写入公共缓存,替换原有的目标数据1,再将目标数据3在公共缓存中的状态设置为非锁定状态,删除自身的私有缓存中修改后的目标数据3。
除了上述方法实施例,本说明书还提供了一种对应的装置实施例。
如图4所示,为本说明书提供的一种数据处理装置的结构示意图,该装置可以应用于多核处理器的任一核心(指定核心),多核处理器可以具有多个核心间的公共缓存以及每个核心的私有缓存,该装置可以至少包括以下单元。
查询单元301:可以用于确定需要以独占方式读取目标数据之后,查询目标数据的状态;目标数据置于锁定状态或非锁定状态,在目标数据置于锁定状态的情况下,任一核心不能将目标数据读取到自身的私有缓存中。
读取单元302:可以用于确定查询结果为非锁定状态之后,将目标数据读取到自身的私有缓存中,并设置目标数据为锁定状态。
修改单元303:可以用于确定需要修改指定核心的私有缓存中的目标数据之后,在完成修改的情况下,设置目标数据为非锁定状态。
查询单元301还可以英语确定需要以非独占方式读取目标数据之后,查询目标数据的状态;确定查询结果为锁定状态之后,将目标数据读取到自身的处理队列中。
读取单元302还可以用于:确定查询结果为非锁定状态之后,判断是否存在至少一个其他核心的私有缓存中有目标数据;确定判断结果为存在之后,将至少一个其他核心的私有缓存中的目标数据在完成修改之前无效化。读取单元302具体可以用于:在将目标数据读取到自身的私有缓存之前,将至少一个其他核心的私有缓存中的目标数据无效化。
修改单元303还可以用于:在完成修改的情况下,将修改后的目标数据保留在自身的私有缓存。修改单元303具体可以用于:确定目标数据的上一次修改是由指定核心执行之后,将修改后的目标数据保留在自身的私有缓存。
查询单元301还可以用于:确定查询结果为锁定状态之后,监测目标数据的状态;待监测到目标数据置于非锁定状态之后,将目标数据读取到自身的私有缓存中,并设置目标数据为锁定状态。
本装置实施例的解释可以参见上述方法实施例。
除了上述装置实施例,本说明书还提供了一种设备实施例。一种多核处理器,具有多个核心间的公共缓存以及每个核心的私有缓存,多核处理器中任一核心可以执行本说明书中任一方法实施例。
具体可以是:确定需要以独占方式读取目标数据之后,查询目标数据的状态;目标数据置于锁定状态或非锁定状态,在目标数据置于锁定状态的情况下,任一核心不能将目标数据读取到自身的私有缓存中;确定查询结果为非锁定状态之后,将目标数据读取到自身的私有缓存中,并设置目标数据为锁定状态;确定需要修改私有缓存中的目标数据之后,在完成修改的情况下,设置目标数据为非锁定状态。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中作为分离部件说明的模块可以是或者也可以不是物理上分开的,在实施本说明书实施例方案时可以把各模块的功能在同一个或多个软件和/或硬件中实现。也可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
以上所述仅是本说明书实施例的具体实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本说明书实施例原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本说明书实施例的保护。
- 图像数据处理方法、用于图像数据处理方法的程序、记录有用于图像数据处理方法的程序的记录介质和图像数据处理装置
- 药箱的数据处理方法、装置、数据处理方法和装置