含有三维存储阵列的处理器
文献发布时间:2023-06-19 09:47:53
本申请是申请号为201710241669.3,申请日为2017年4月13日的中国专利申请的分案申请。
技术领域
本发明涉及集成电路领域,更确切地说,涉及处理器。
背景技术
传统处理器采用基于逻辑的计算(logic-based computation,简称为LBC),它主要通过逻辑电路(如与非门等)来计算。逻辑电路适合实现算术运算(如加法、减法和乘法),但对于非算术函数(如初等函数、特殊函数等)无能为力。非算术函数的高速高效实现面临巨大的挑战。
在传统处理器中,仅少量基本非算术函数(如基本代数函数、基本超越函数)能通过硬件直接实现,这些函数被称为内置函数(built-in functions)。内置函数一般通过逻辑电路和查找表(LUT)的组合来实现。实现内置函数的例子很多,例如:美国专利US 5,954,787(发明人:Eun;授权日:1999年9月21日)披露了一种利用LUT实现正弦/余弦(sin/cosine)函数的方法;美国专利US 9,207,910(发明人:Azadet;授权日:2015年12月8日)披露了一种利用LUT实现幂函数的方法。
图1A具体描述了内置函数的实现方法。传统处理器300通常含有逻辑电路380和存储电路370。逻辑电路380含有算术逻辑单元(ALU),它用于实现算术运算。存储电路370含有LUT。为了达到预定精度,需将代表内置函数的多项式展开到足够高的阶数。LUT 370存储多项式系数,ALU 380计算相应的多项式。由于ALU 380和LUT 370并肩排列在同一平面上(均形成在衬底0中),这种平面集成是一种二维集成。
计算目前正向更高的计算密度和更大的计算复杂度发展。计算密度是指单位芯片面积上的计算能力(如每秒的浮点数运算次数),它是平行计算的一个重要指标。计算复杂度是指芯片支持的内置函数数量,它是科学计算的一个重要指标。二维集成限制了计算密度和计算复杂度的进一步发展。
由于采用二维集成,LUT 370将增加处理器300的芯片面积,降低其计算密度,这对平行计算不利。此外,ALU 380是处理器300的核心部件,它占用了大部分芯片面积,故LUT370能利用的芯片面积有限,它只能支持少量的内置函数。图1B列出英特尔公司的Itanium处理器(IA-64)能实现的所有内置超越函数(参考Harrison等所著《The Computation ofTranscendental Functions on the IA-64 Architecture》, Intel Technical Journal,Q4, 1999年)。IA-64处理器总共支持7种超越函数,每种超越函数使用了相对较小的LUT(从0到24kb),并需要进行相对较多的泰勒级数(5阶到22阶)计算。
该内置函数组(含有~10种内置函数,包括算术运算)就是科学计算的基础。科学计算需要强大的计算能力来增进人类对自然和社会的认识、或解决工程问题,它在计算数学、计算物理、计算化学、计算生物、工程计算、计算经济、计算金融等计算领域有广泛应用。传统的科学计算框架含三个层次:基础层、函数层和模型层。基础层包含各种硬件能直接实现的内置函数;函数层包含各种硬件不能直接实现的数学函数(如非基本非算术函数);模型层包含各种用于描述系统构件性能(如输入-输出特性)的数学模型。
函数层中的数学函数以及模型层中的数学模型需由软件实现。函数层需要做一次软件分解:数学函数由软件分解成内置函数的组合,再由硬件实现内置函数并进行算术运算。模型层需要做两次软件分解:数学模型首先被分解为数学函数,然后数学函数再被分解成内置函数。很明显,软件实现(如数学函数、数学模型)要比硬件实现(如内置函数)慢且低效。而且,软件分解次数越多(如数学模型),延时和能耗将更为恶化。
数学模型的计算复杂度非常惊人。图2A-图2B披露了一个简单例子—放大电路20的仿真。放大电路20含有一晶体管24和一电阻22(图2A)。所有的晶体管模型(如图2B中的MOS3、BSIM3 V3.2、BSIM4 V3.0、PSP等)均建立于传统处理器300支持的内置函数组上。由于内置函数种类有限,即使是计算晶体管24的一个电流点也需要很大计算量(图2B)。举例说,BSIM4 V3.0晶体管模型需要做222次加法、286次乘法、85次除法、16次平方根运算、24次指数运算和19次对数运算。如此大的计算量使仿真慢且低效。
发明内容
本发明的主要目的是推动科学计算的变革。
本发明的另一目的是提供一种能实现更高计算复杂度的处理器。
本发明的另一目的是提供一种具有更多内置函数的处理器。
本发明的另一目的是高速高效地计算非算术函数。
本发明的另一目的是实现高速高效的仿真和模拟。
本发明的另一目的是提供一种能实现更高计算密度的处理器。
为了实现这些以及别的目的,本发明提出一种含有三维存储(three-dimensionalmemory,简称为3D-M)阵列的处理器(简称为“三维处理器”)。它含有多个位于半导体衬底上的计算单元,每个计算单元含有一算术逻辑电路(arithmetic logic circuit,简称为ALC)和一基于3D-M的查找表(3DM-LUT)。ALC形成在半导体衬底中,它对3DM-LUT数据进行算术运算。3DM-LUT 存储在至少一3D-M阵列中。该3D-M阵列堆叠在ALC上方,并覆盖至少部分ALC。3D-M阵列通过接触通道孔与ALC电耦合,这些接触通道孔被统称为三维互连。
本发明还提出一种基于存储的计算(memory-based computation,简称为MBC),它主要通过查找3DM-LUT来计算。与传统的LBC相比,MBC使用的3DM-LUT的存储容量远高于传统LUT。虽然对于大多数MBC来说,它们仍需要进行算术运算。但是,通过使用较大的3DM-LUT作为出发点,MBC仅需使用较少的多项式展开。在MBC中,3DM-LUT的计算成分大于ALC。
由于3DM-LUT堆叠在ALC之上,这种垂直集成被称为三维集成。三维集成能提高计算密度。由于3D-M阵列不占衬底面积,计算单元的面积与ALC的面积相近。而传统处理器的面积是LUT和ALU之和。通过将LUT从边上移到顶上,计算单元变得更小。三维处理器含有更多计算单元,支持大规模平行计算。
三维集成还能极大地提高计算复杂度。传统处理中所有LUT的容量小于100kb,而三维处理器中所有3DM-LUT的容量可以达到100Gb(例如,单芯3D-XPoint的存储容量为128Gb)。因此,单个三维处理器芯片可以支持多达一万个内置函数,比传统处理器多三个数量级。
内置函数的大量增加将使传统科学计算的框架(包括基础层、函数层和模型层)扁平化。过去仅能在基础层用硬件实现函数;现在,不仅函数层的数学函数能直接被硬件实现,模型层的数学模型也能直接被硬件描述。在函数层,数学函数通过function-by-LUT法实现(即通过LUT查表和多项式插值);在模型层,数学模型通过model-by-LUT法实现(即通过LUT查表加多项式插值)。数学函数和数学模型的高速高效实现将推动科学计算的变革。
相应地,本发明提出一种处理器(100),其特征在于含有:一半导体衬底(0);至少一位于该半导体衬底(0)上的计算单元(110-i),所述计算单元(110-i)含有一算术逻辑电路(ALC)(180)和一基于三维存储器(3D-M)的查找表(3DM-LUT)(170),其中:所述ALC(180)位于该半导体衬底(0)中并对该3DM-LUT(170)的数据进行算术运算;所述3DM-LUT(170)存储在至少一3D-M阵列(170o…)中,该3D-M阵列(170o…)堆叠在该ALC(180)上方;所述3D-M阵列(170o…)和所述ALC(180)通过多个接触通道孔(1av, 3av)实现电耦合。
本发明还提出一种三维处理器(100),其特征在于含有:一半导体衬底(0);至少一位于该半导体衬底(0)上的计算单元(110-i),所述计算单元(110-i)含有一算术逻辑电路(ALC)(180)和一基于三维存储器(3D-M)的查找表(3DM-LUT)(170),其中:所述ALC(180)位于该半导体衬底(0)中并对该3DM-LUT(170)的数据进行算术运算;所述3DM-LUT(170)存储在至少一3D-M阵列(170o…)中,该3D-M阵列(170o…)堆叠在该ALC(180)上方并存储与一数学函数相关的数据;所述3D-M阵列(170o…)和所述ALC(180)通过多个接触通道孔(1av,3av)实现电耦合。
本发明还提出一种三维处理器(100),其特征在于含有:一半导体衬底(0);至少一位于该半导体衬底(0)上的计算单元(110-i),所述计算单元(110-i)含有一算术逻辑电路(ALC)(180)和一基于三维存储器(3D-M)的查找表(3DM-LUT)(170),其中:所述ALC(180)位于该半导体衬底(0)中并对该3DM-LUT(170)的数据进行算术运算;所述3DM-LUT(170)存储在至少一3D-M阵列(170o…)中,该3D-M阵列(170o…)堆叠在该ALC(180)上方并存储与一数学模型相关的数据;所述3D-M阵列(170o…)和所述ALC(180)通过多个接触通道孔(1av,3av)实现电耦合。
附图说明
图1A是一传统处理器的透视图(现有技术);图1B列出英特尔Itanium(IA-64)处理器支持的所有超越函数(现有技术)。
图2A是一放大电路的电路图;图2B列出不同晶体管模型计算一个电流点所需的计算量(现有技术)。
图3A是一种三维处理器的电路框图;图3B是一种计算单元的电路框图。
图4A-图4C是三种ALC的电路框图;
图5A是一种含有三维可写存储器(3D-W)计算单元的截面图;图5B是一种含有三维印录存储器(3D-P)计算单元的截面图;图5C是这些计算单元的透视图。
图6A是一种含有二极管(或似二极管器件)存储元的示意图;图6B是一种含有晶体管(或似晶体管器件)存储元的示意图。
图7A-图7C是三种计算单元的衬底电路布局图。
图8A是第一种计算单元的电路框图;图8B是其衬底电路布局图;图8C是该计算单元一种具体实现的电路图。
图9A是第二种计算单元的电路框图;图9B是其衬底电路布局图。
图10A是第三种计算单元的电路框图;图10B是其衬底电路布局图。
注意到,这些附图仅是概要图,它们不按比例绘图。为了显眼和方便起见,图中的部分尺寸和结构可能做了放大或缩小。在不同实施例中,数字后面的字母后缀表示同一类结构的不同实例;相同的数字前缀表示相同或类似的结构。“/”表示“和” 或“或”的关系。
在本说明书中,“存储器”泛指任何基于半导体的信息存储设备,它可以长久或临时存储信息。“一电路位于衬底中或衬底上”是该电路的至少部分功能器件(如晶体管)形成在衬底中(包括衬底表面上)。“一电路位于衬底上方”是指该电路的所有功能器件(如存储元)形成在衬底上方、不与衬底接触。
具体实施方式
图3A表示一种三维处理器100,它含有N个计算单元110-1, 110-2, … 110-i, …110-N。这些计算单元110-1 … 110-N可以实现相同功能、或不同功能。每个计算单元110-i有一个或多个输入变量150、一个或多个输出值190(图3B)。每个计算单元110-i含有一算术逻辑电路(ALC)180和一基于3D-M的查找表(3DM-LUT)170。该3DM-LUT 170包括所有与ALC180耦合的3D-M阵列所存储的查找表(LUT)。ALC 180对3DM-LUT数据进行算术运算。3DM-LUT170和ALC 180之间通过三维互连160电耦合。由于3DM-LUT 170与ALC 180位于不同物理层(详见图5A-图5C),它用点线表示。
三维处理器100采用基于存储的计算(memory-based computation,简称为MBC),它主要通过查找3DM-LUT 170来计算。与传统的LBC相比,MBC使用的3DM-LUT 170的存储容量远高于传统LUT 370。虽然对于大多数MBC来说,它们仍需要进行算术运算。但是,通过使用较大的3DM-LUT作为出发点,MBC仅需使用较少的多项式展开。在MBC中,3DM-LUT 170完成的计算成分大于ALC 180。
图4A-图4C表示三种ALC 180。图4A的ALC 180是一种加法器180A;图4B中的ALC180是一种乘法器180M;图4C中的ALC 180是一种乘加器(MAC),它含有一加法器180A和一乘法器180M。ALC 180可以实现整数运算、定点数运算或浮点数运算。对于熟悉本专业的人士来说,ALC 180还可以含有存储电路,如寄存器、触发器、缓冲RAM等。
计算单元110-i中3D-M有多种形式。美国专利US 5,835,396(发明人:张国飙;授权日:1998年11月10日)对3D-M做了详细披露。3D-M含有多个垂直堆叠在一半导体衬底上的存储层,每个存储层含有多个3D-M阵列。一个3D-M阵列是在一个存储层中所有共享了至少一条地址线的存储元之集合。
3D-M分为3D-RAM(三维随机访问存储器)和3D-ROM(三维只读存储器)。在本说明书中,RAM泛指任何临时存储信息的半导体存储器,包括但不局限于寄存器、SRAM和DRAM;ROM泛指任何长久存储信息的半导体存储器,它可以电编程或非电编程。大多数3D-M是3D-ROM。3D-ROM还分为三维可写存储器(three-dimensional writable memory,简称为3D-W)和三维印录存储器(three-dimensional printed memory,简称为3D-P)。
3D-W存储的信息通过电编程的方式录入。根据其可编程的次数,3D-W又分为三维一次编程存储器(three-dimensional one-time-programmable memory,简称为3D-OTP)和三维多次编程存储器(three-dimensional multiple-time-programmable memory,简称为3D-MTP)。顾名思义,3D-OTP只能写一次,3D-MTP能写多次(包括重复编程)。一种常见的3D-MTP是3D-XPoint。其它3D-MTP包括memristor、阻变存储器(RRAM)、相变存储器(PCM)、programmable metallization cell(PMC)、conductive bridging random-access memory(CBRAM)等。对于3D-W来说,3DM-LUT可以现场编程。如果3D-W是3D-MTP则更好,它可以实现重复编程。
3D-P存储的信息是在工厂生产过程中采用印刷方式录入的(印录法)。这些信息是永久固定的,出厂后不能改变。印录法可以是光刻(photo-lithography)、纳米压印法(nano-imprint)、电子束扫描曝光(e-beam lithography)、DUV扫描曝光、激光扫描曝光(laser programming)等。常见的3D-P有三维掩膜编程只读存储器(3D-MPROM),它通过光刻法经过掩膜编程录入数据。由于它没有电编程的要求,3D-P存储元在读的时候可以偏置在更高的电压。因此,3D-P的读速度比3D-W快。
图5A表示一种含有3D-W的计算单元110-i。该计算单元110-i含有一形成在衬底0中的衬底电路层0K。ALC 180形成在衬底电路层0K中。存储层16A堆叠在衬底电路0K之上,存储层16B堆叠在存储层16A之上。衬底电路层0K含有存储层16A, 16B的周边电路,它包括晶体管0t及互连线0M。每个存储层(如16A)含有多条第一地址线(如2a,沿y方向)、多条第二地址线(如1a,沿x方向)和多个3D-W存储元(如6aa)。存储层16A, 16B分别通过接触通道孔1av, 3av与ALC 180耦合。存储层16A, 16B中所有与ALC 180耦合的3D-M阵列所存储的LUT统称为3DM-LUT 170。由于接触通道孔1av, 3av将3DM-LUT 170和ALC 180电耦合,它们被统称为三维互连160。
3D-W存储元6aa含有一编程膜12和一二极管膜14。编程膜12可以是反熔丝膜(写一次,用于3D-OTP),也可以是其它多次编程膜(用于3D-MTP)。二极管膜14具有如下的广义特征:在读电压下,其电阻较小;当外加电压小于读电压或者与读电压方向相反时,其电阻较大。二极管膜可以是P-i-N二极管,也可以是金属氧化物(如TiO
图5B表示一种含有3D-P阵列的计算单元110-i。除了存储元不同,它与图5A类似。3D-P含有至少两种存储元5aa, 5ac:存储元5aa是高阻存储元,存储元5ac是低阻存储元。低阻存储元5ac含有一层二极管膜14。高阻存储元5aa则含一高阻膜13,它是一绝缘膜(如氧化硅或氮化硅)。在生产流程中,位于低阻存储元5ac处的高阻膜13被物理移除。
图5C从另一个角度显示计算单元110-i的结构。3DM-LUT 170堆叠在ALC 180上方,ALC 180位于衬底0中,并被3DM-LUT 170至少部分覆盖。它们之间通过大量接触通道孔1av,3av电耦合。三维集成将3DM-LUT 170和ALC 180移得更近。由于接触通道孔1av, 3av数量众多(最少数千个)且长度很短(微米级),三维互连160的带宽远高于传统处理器300。在传统处理器300中,二维集成使ALU 380和LUT 370在衬底0上并肩排列,它们之间的互连数量有限(最多数百个)且较长(百微米级)。
图6A表示一种含有二极管(或似二极管器件)14的存储元5ab。它含有一可变电阻12和一二极管(或似二极管器件)14。可变电阻12由图5A中的可编程膜实现,其电阻可在出厂前或出厂后设置。二极管(或似二极管器件)14由图5A中的二极管膜实现。
图6B表示一种含有晶体管(或似晶体管器件)16的存储元5ab。晶体管(或似晶体管器件)16是具有如下广义特征的三端口(或更多端口)器件:其第一和第二端口之间的电阻可以由第三端口上的电信号调制。在本实施例中,晶体管16还含有一用于存储电荷的悬浮栅18。该电荷代表存储元5ab存储的信息。对于熟悉本专业的人士来说,晶体管16可以组成NOR阵列或NAND阵列。基于晶体管中的电流方向(从第一端口流向第二端口),3D-M可以分为横向3D-M(即电流水平流动,如3D-XPoint)和纵向3D-M(即电流垂直流动,如3D-NAND)。
图7A-图7C披露了三种计算单元110-i。在图7A中,ALC 180只与3D-M阵列170o耦合,它对来自3D-M阵列170o的数据进行算术运算。3DM-LUT 170存储在3D-M阵列170o中。ALC180位于3D-M阵列170o的四个周边电路(包括X解码器15o, 15o`和Y解码器17o, 17o`)之间,并被3D-M阵列170覆盖。在图7A及以后的图中,由于3D-M阵列位于衬底电路0K上方,不在衬底电路0K中,在此仅用点线表示其在衬底0上的投影。
在图7B中,ALC 180与四个3D-M阵列170a-170d耦合,它对来自这四个3D-M阵列170a-170d的数据进行算术运算。3DM-LUT 170存储在四个3D-M阵列170a-170d中。与图7A不同,每个3D-M阵列(如170a)只有两个周边电路(如X解码器15a和Y解码器17a)。ALC 180位于八个周边电路(X解码器15a-15d、Y解码器17a-17d)之间,并被四个3D-M阵列170a-170d覆盖。图7B中的ALC 180可以是图7A的四倍大。
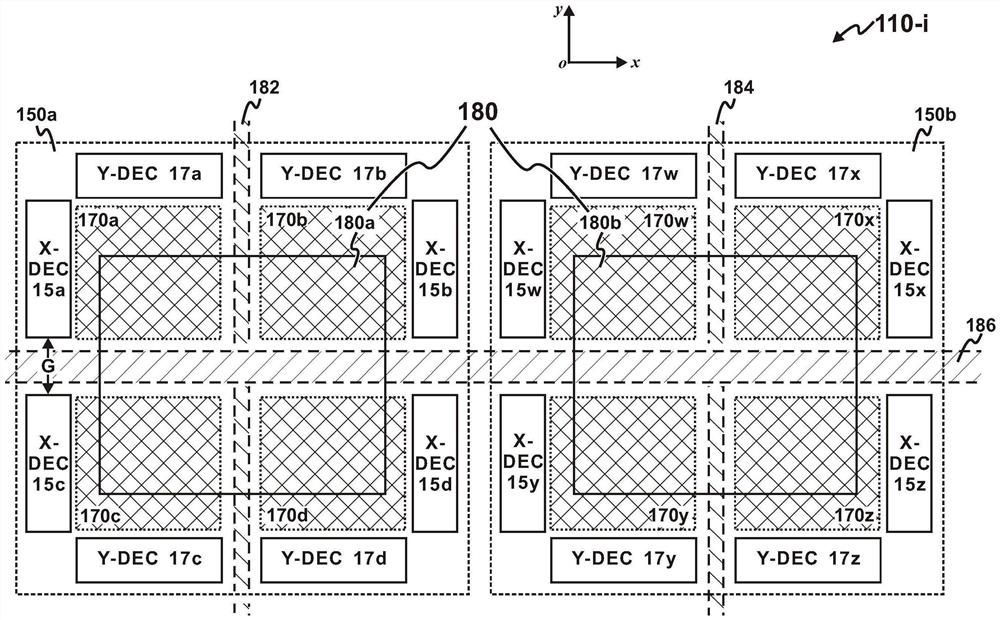
在图7C中,ALC 180与八个3D-M阵列170a-170d、170w-170z耦合,它对来自这八个3D-M阵列170a-170d、170w-170z的数据进行算术运算。3DM-LUT 170存储在八个3D-M阵列170a-170d、170w-170z中。3D-M阵列170a-170d、170w-170z分为两组150a, 150b。每组(如150a)包括四个3D-M阵列(如170a-170d)。在第一组150a的四个3D-M阵列170a-170d下方,形成第一ALC 组件180a。类似地,在第二组150b的四个3D-M阵列170w-170z下方,形成第二ALC组件180b。第一ALC 组件180a和第二ALC 组件180b构成ALC 180。在本实施例中,在相邻周边电路之间(如相邻X解码器15a, 15c之间;在相邻的Y解码器17a, 17b之间;在相邻的Y解码器17c, 17d之间)留有间隙G,以形成布线通道182, 184, 186,供不同ALC 组件之间、或不同ALC 之间实现通讯。图7C的ALC 180可以是图7A的八倍大。
由于3DM-LUT 170堆叠在ALC 180之上,这种垂直集成被称为三维集成。三维集成能提高计算密度。由于3DM-LUT 170不占衬底面积,计算单元110-i的面积与ALC 180的面积相近;而传统处理器300的面积是LUT 370和ALU 380之和。通过将LUT从边上移到顶上,计算单元变得更小。三维处理器100含有更多计算单元110-i,支持大规模平行计算。
三维集成还能极大地提高计算复杂度。传统处理器300中所有LUT 370的容量小于100kb,而三维处理器100中所有3DM-LUT 170的容量可以达到100Gb。因此,单个三维处理器芯片100可以支持多达一万个内置函数,比传统处理器300多三个数量级。
内置函数的大量增加将使传统科学计算的框架(包括基础层、函数层和模型层)扁平化。过去仅能在基础层用硬件实现函数;现在,不仅函数层的数学函数能直接被硬件实现,模型层的数学模型也能直接被硬件描述。在函数层,数学函数通过function-by-LUT法实现(即通过LUT查表和多项式插值,图8A-图9B);在模型层,数学模型通过model-by-LUT法实现(即通过LUT查表加多项式插值,图10A-图10B)。数学函数和数学模型的高速高效实现将推动科学计算的变革。
图8A-图8C表示第一种计算单元110-i。该计算单元110-i用于实现内置函数Y=f(X),它采用function-by-LUT法。图8A是其电路框图。ALC 180含有一预处理电路180R、一3DM-LUT 170P、和一后处理电路180T。预处理电路180R将输入变量(X)150转化为3DM-LUT170P的地址(A)。将3DM-LUT 170P中的地址(A)的数据(D)读出后,后处理电路180T将其转化为函数值(Y)190。为了提高计算精度,输入变量(X)的余量(R)被送到后处理电路180T。
图8B是其衬底电路布局图。3DM-LUT 170P存储在3D-M阵列170p中。3D-M阵列170p还含有X解码器15p和Y解码器17p。3D-M阵列170p覆盖预处理电路180R和后处理电路180T。虽然该实施例只有一个3D-M阵列170p,计算单元110-i可以含有多个3D-M阵列(类似图7B-图7C)。由于3DM-LUT 170P不占用衬底面积,3DM-LUT 170P与预处理电路180R和后处理电路180T之间的三维集成使计算单元110-i具有较小的面积。
图8C是能实现单精度内置函数Y=f(X)的一种计算单元110-i。输入变量X 150为32位(x
在实现内置函数时,将LUT和多项式插值结合起来可以用较小的LUT实现较高的计算精度。假如仅用LUT(无多项式插值)来实现上述的单精度函数(32位输入、32位输出),LUT的容量需要达到2
除了初等函数以外,图8C中的实施例还能实现各种高等函数,如特殊函数等。特殊函数在数学分析、泛函分析、物理研究、工程应用中有着举足轻重的地位。许多特殊函数是微分方程的解或基本函数的积分。特殊函数的例子包括伽玛函数、贝塔函数、贝塞尔函数、勒让德函数、椭圆函数、Lame函数、Mathieu函数、黎曼泽塔函数、菲涅耳积分等。三维处理器的出现将简化特殊函数的计算,助推其在科学计算中的应用。
图9A-图9B表示第二种计算单元110-i。该计算单元110-i用于实现复合函数Y=exp[K*log(X)]=X
图9B是其衬底电路布局图。衬底电路0K含有3D-M阵列170s, 170t的X解码器15s,15t、Y解码器17s, 17t,以及乘法器180M。3D-M阵列170s, 170t覆盖至少部分乘法器180M。注意到,图8C和图9A的实施例均使用了两个3DM-LUT。这些3DM-LUT可以存储在同一3D-M阵列170p中(如图8B),也可以存储在两个并肩排列的3D-M阵列170s, 170t中(如图9B),还可以存储在两个垂直堆叠的3D-M阵列中(如分别形成在图5A-图5C的存储层16A, 16B中)。当然,3DM-LUT还可以形成在更多的3D-M阵列中。
图10A-图10B表示第三种计算单元110-i。该计算单元110-i用于实现放大电路20(图2A)的仿真,它采用model-by-LUT法。图10A是其电路框图。它含有一3DM-LUT 170U、一加法器180A和一乘法器180M。3DM-LUT 170U存储与晶体管24性能(如输入-输出特性)相关的数据。输入电压V
3DM-LUT 170U可以存储多种数学模型。在一种实施例中,3DM-LUT存储的模型数据是原始测量数据,如测量出的输入-输出特性。一个例子是晶体管的漏电流vs. 栅源电压(I
图10B是第三种计算单元110-i的衬底电路布局图。衬底电路0K含有3D-M阵列170u的X解码器15u、Y解码器17u,以及乘法器180M和加法器180A。3D-M阵列170u覆盖乘法器180M和加法器180A。虽然此图仅显示了一个3D-M阵列170u,本实施例可以使用多个3D-M阵列(如图7B-图7C)。
Model-by-LUT带来很多优势。由于不需两次软件分解(从数学模型到数学函数、从数学函数到内置函数),它能节省大量的计算时间和能耗。Model-by-LUT甚至比function-by-LUT需要的LUT还少。由于晶体管模型(如BISM4 V3.0)需要数百个模型参数,如采用function-by-LUT的方法,则计算晶体管模型的中间函数需要大量的LUT。如果我们跳过function-by-LUT(即跳过晶体管模型及相关的中间函数),晶体管性能可以用三个测量参数描述(包括栅源电压V
应该了解,在不远离本发明的精神和范围的前提下,可以对本发明的形式和细节进行改动,这并不妨碍它们应用本发明的精神。例如说,处理器可以是中央处理器(CPU)、数字信号处理器(DSP)、图像处理器(GPU)、网络安全处理器、加密/解密处理器、编码/解码处理器、神经网络处理器、人工智能(AI)处理器等。因此,除了根据附加的权利要求书的精神,本发明不应受到任何限制。
- 含有三维存储阵列的处理器
- 含有三维存储阵列的集成神经网络处理器