一种新型知识图谱实体画像方法
文献发布时间:2023-06-19 09:52:39
技术领域
本发明属于计算机技术领域,涉及一种新型知识图谱实体画像方法。
背景技术
近年来,知识图谱发展迅速,它以“实体-关系-实体”和“实体-属性-属性值”的形式来存储事实信息,被广泛应用于实体搜索、数据集成等任务中。理解一个实体有两类方法:一类是将实体识别为对应的现实对象;另一类方法是将一个实体与其他实体进行比较,以了解其独特性。然而,知识图谱的容量和结构复杂性大大降低了识别和比较实体的效率。为了解决实体理解中的实体识别问题,近年来实体摘要领域得到了广泛关注。实体摘要的方法通过提取一个简明的摘要来缩短冗长的实体描述,并在摘要中保留重要的信息内容。
虽然实体摘要能够帮助用户快速理解实体,但是仅仅依靠摘要来理解实体仍很困难,区分实体的问题仍然没有解决。由于实体摘要只包含了实体本身的“局部”信息,而缺少了体现实体相对于其他实体的唯一性的“全局”信息,实体的区分性无法在摘要中表现出来。
发明内容
为解决上述问题,本发明提出一种基于知识图谱的实体画像方法,提供一种可扩展的表示学习模型——HAS模型,用于生成多模式实体嵌入,能够高效地查找出知识图谱中最具区分性的实体标签,从而能够体现知识图谱中实体的独特特征。
为了达到上述目的,本发明提供如下技术方案:
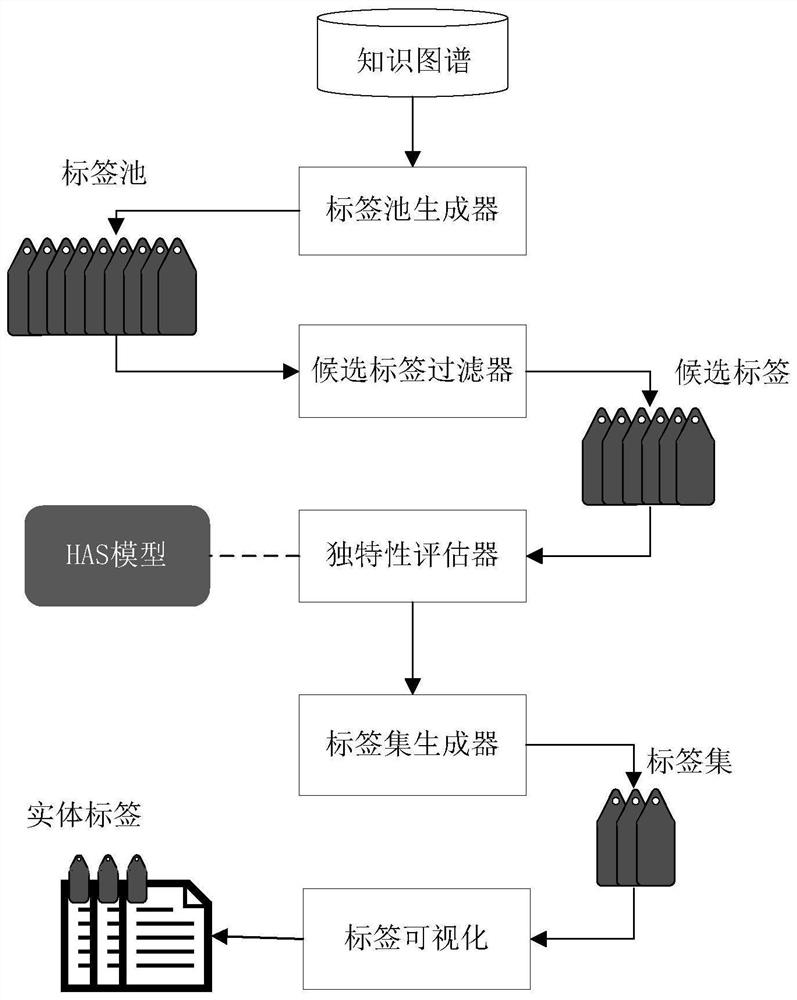
一种新型知识图谱实体画像方法,包括如下步骤:
步骤1:构建候选标签池
给定一个知识图谱作为输入,为每个实体类型自动枚举所有可能的标签,放入标签池中;
步骤2:过滤候选标签
通过过滤器滤除低质量标签,得到候选标签集;
步骤3:评估候选标签区分性
通过独特性评估器衡量标签的区分性,计算匹配该标签的正例实体间和正例与不匹配该标签的负例实体之间的相似性,评估标签的区分性;
步骤4:重排序
通过重排序的方法选择具有区分性标签,生成最终的标签集;
步骤5:可视化生成实体画像结果
遍历所有的实体标签描述,查找某个实体是否与某些标签匹配,得到最终画像结果,并可视化地呈现给用户。
进一步的,所述步骤1中,标签包括属性型标签和关系型标签,所述属性型标签包括属性区间标签和属性值标签,所述关系型标签包括关系-实体标签和关系-属性标签;生成标签的过程为:通过从知识图谱中暴力枚举所有属性和属性值的组合,或关系和实体的组合,自动化生成标签。
进一步的,生成属性区间标签时,将属性的连续值离散化,采用等宽离散化和密度离散化相结合的方法,划分出合适的区间。
进一步的,所述步骤2中,使用启发式规则来过滤低质量的标签,包括不具备代表性的标签和不具有区分性的标签。
进一步的,启发式规则具体包括:
对于一个实体类型t和与t相关候选标签l,将ε
进一步的,所述步骤3采用多模式实体表示模型来衡量实体之间的相似度,同时考虑了同质性模式、属性等价模式和结构等价模式,生成3种随机游走路径;然后,按照一定比例将3种路径混合,遵循DeepWalk的skip-gram学习过程,得到实体的嵌入表示;最终,利用余弦相似度进行实体的相似性度量。
进一步的,所述步骤4中的重排序方法,优先选择与已有标签不同的标签和与已有标签互补的标签,生成最终的标签集。
进一步的,重排序时,计算
与现有技术相比,本发明具有如下优点和有益效果:
本发明提供的基于知识图谱的实体画像方法,侧重于发现具有区分性的标签,充分体现实体间的区分性;通过HAS模型和重排序的方法来深入研究实体标签的区分性,减少了标签空间中的冗余,使得实体相似性度量更加全面,提高标签区分能力。本发明首次提出了知识图谱中实体画像的研究,这会是对实体摘要研究的一个很好的补充,有利于实体链接、实体推荐等下游任务的实现。
附图说明
图1为本发明实体画像流程图。
图2为本发明HAS三种路径查找策略图。
图3为本发明实体画像示例图。
具体实施方式
以下将结合具体实施例对本发明提供的技术方案进行详细说明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
为了方便理解,下面对本申请实施例中涉及的名词进行解释:
知识图谱(Knowledge Graph):给定一个知识图谱
标签与标签集(Label and Label Set):给定
本发明核心为每个实体类型构造一个包含区分性标签的集合。具体地说,本申请实施例提供的基于知识图谱的实体画像方法的流程示意图,如图1所示,包括如下步骤:
步骤1:构建候选标签池
实体类别包括:航空公司、乐队、棒球运动员、湖泊、大学、哲学家、歌曲、政党、电视节目、喜剧演员、学术期刊、演员、书籍、山、广播台和电影,每个实体类别包含若干个实体。实体的特征在结构上是异构的,为了帮助用户充分理解实体的区分性,本发明根据实体特征结构的不同,将标签分为属性型标签和关系型标签,其中属性型标签包括属性区间标签和属性值标签,关系型标签包括关系-实体标签和关系-属性标签。在没有先验知识的情况下,通过自动化生成标签的方式,从知识图谱中暴力枚举出所有标签。通过枚举所有属性和属性值的组合,或关系和实体的组合,可以直接生成候选属性值标签和关系-实体标签,而候选属性区间标签和关系-属性标签的生成会比较复杂。将属性的连续值生成为包含该值的一个更广泛的区间,比如
为标签找到一个合适的区间是生成属性区间标签至关重要的一步,它实质上是标签的连续数值离散化问题。设置一些简单的离散化规则来找到一些特定值的合适区间,例如,采用等宽离散化方法,使用五年的周期作为各种年份的间隔。对于其他类型的数值,采用了一种基于局部密度的离散化算法,其主要思想是找出属性值的密度区间,确保区间中间的密度高,边界附近的密度低。属性值排序后,密度值呈现多峰现象,密度分布的每个峰值表示两个区间之间的边界。
步骤2:过滤候选标签
将步骤1中的标签进行初步的筛选,候选池中可能会包含许多低质量标签,这些标签提供的信息非常有限,甚至是误导性的。将这些低质量的候选标签分为两类,一类是不具备代表性的标签,举个例子,在Drugbank中有候选标签
使用一个简单的启发式规则来过滤掉这两类低质量的标签。给定一个实体类型t和与t相关候选标签l,我们将ε
步骤3:评估候选标签区分性
在生成候选之后,所有的标签需要进一步的评估,确保实体最终的标签结果具有区分性,在正例和负例之间有明显的界限。使用
提出一种多模式实体表示模型来衡量实体的相似度,称为HAS模型。每个实体的嵌入表示由HAS学习,如果它们共享一个或多个结构模式,则保持实体在连续的低维空间中是封闭的。HAS考虑了三种结构模型:同质性模式(Homophily)、属性等价模式(Attributiveequivalency)和结构等价模式(Structural equivalency),该模型简化了实体表示的操作,对于在大规模知识图谱中评估区分性,是一种高效的实体表示方法。
将知识图谱作为输入,对每个实体进行路径查找操作,得到从该实体开始的一组路径。基于HAS三种策略,会得到三种类型的路径:(1)H策略用来找到代表同质性模式的H路径;(2)A策略用来找到代表属性等价的A路径;(3)S策略用来找到代表结构等价的S路径。每种类型的路径反映了结构模式的某些方面,路径查找之后,这些路径将按比例混合作为实体的特征。最后,我们使用随机游走模型学习特征表示。图2展示了三种路径查找策略。图的上半部分表示输入的KG部分,其中节点是实体,白色矩形是文本信息,边是连接实体和文本的关系或属性。根据类型的不同,实体被标注为不同样式的节点。图的下半部分展示了从实体x出发的三种路径查找策略。对每种策略的阐述如下:
H策略:简单的随机游走策略,用于寻找反映同质性模式的H路径,即实体之间的直接连接。在图2(a)中,从x出发,利用深度优先搜索(Deep First Search,DFS)生成多条路径。
A策略:用于寻找反映属性等价性的A路径。从x开始,A策略尝试查找知识图谱中与x属性值最相似的同类型类型的后续实体。在图2中,实体x与y、z都是相同的类型。可以看出,z与y相比,和x更相似,因为z的性别与x相同,并且和y相比,z的年龄更接近x。所以,基于属性等价的策略,选择z作为从x出发的路径的后续节点。
图2(b)展示了查找A路径的随机游走模型,我们首先将相同类型的实体嵌入到一个属性空间。对于每个类型t,其属性空间有
S策略:结构等价性通常嵌入在实体的局部结构中。例如,如果两位教授在他们的社交网络中扮演相似的角色,那么他们在结构上就具有很高的相似性,例如他们每个人都与许多学生有联系。与A策略相似,S策略通过在结构空间中嵌入实体来查找S路径。给定一个类型t,它的结构空间有
路径混合:最后,HAS模型为每个实体生成3种随机游走路径集合:P
对于一个具有区分性的标签,正例之间是相似的,而跟负例之间是不同的。通过计算正例之间的相似度和正负例之间的相似度,评估标签的区分性。正例之间越相似,正负例之间差异越大,则该标签区分性越强。本步骤用HAS模型来衡量正例和负例之间的差异性,保留具有区分性标签。
步骤4:重排序
利用重排序的方法来最终评估候选标签,要求(1)给标签集带来的冗余少;(2)提高了标签集的完整性。第一个要求是优先处理与已有标签不同的标签,第二个要求倾向于与已有标签互补的标签。
如公式
步骤5:可视化生成实体画像结果
所有的实体描述都将被遍历,以查找某个实体是否与某些标签匹配。最终,实体标签的可视化结果将被呈现给用户,以帮助快速理解实体的唯一性。在图3中给出了本申请实施例的两个实体画像结果图。(a)图中的实体是定义在电影知识图谱LinkedMDB中的电影实体Léon;(b)图中的实体是定义在DBpedia中的一个乐队实体BeastieBoys。每个实体都有五个标签,每个标签从KG中提取,并用深灰色标注,其中“≠80%”表示该实体在该特征上与其他80%的电影或乐队不同;“>60%”或“<95%”表示该实体在该特征上与其他电影或乐队相比,具有较大或较小的值。
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 一种新型知识图谱实体画像方法
- 一种基于知识图谱建立实体统一模型及实体统一方法