信息处理装置和方法以及程序
文献发布时间:2023-06-19 10:00:31
技术领域
本技术涉及一种信息处理装置和方法以及一种程序,更具体地,涉及一种信息处理装置和方法以及一种程序,其能够从带有声音的运动图像中提取期望对象。
背景技术
如果可以从带有声音的运动图像(其是伴随声音的运动图像)中提取发出声音的对象,则提取结果可以用于各种处理,这是方便的。
例如,在再现带有声音的运动图像时,可以摄像将焦点集中在运动图像上的某个对象(物体),或者放大或修剪作为中心的对象。在这种情况下,需要强调从已经经历了诸如聚焦、放大和修剪等图像处理的对象发出的声音,或者对于带有声音的运动图像的声音仅提取和播放该声音。
此外,例如,作为用于强调期望声音的技术,已经提出了使用麦克风阵列来强调对象(物体)的特定方向上的声音的技术(例如,参见专利文献1)。
引文列表
专利文献
专利文献1:日本专利申请公开号2014-50005
发明内容
本发明要解决的问题
然而,通过上述技术难以从带有声音的运动图像中提取期望对象的图像区域和声音。
例如,在专利文献1中描述的技术中,在存在在空间中沿相同方向发出声音的多个物体的情况下,不可能聚焦在期望物体上的声音。即,不可能从同一方向的多个物体(对象)中仅提取期望物体的声音。
此外,因为专利文献1中描述的技术通过选择运动图像上的位置来近似选择物体,所以不可能基于诸如人A、汽车或吉他等概念来选择对象。例如,即使用户希望在语音识别界面中给出“聚焦于穿红色衬衫的女孩”等的指令,除非穿红色衬衫的女孩被定义为对象并且定义对应于该对象的图像区域和声音,否则难以响应这样的命令。
因此,不可能聚焦于发出特定声音的对象,例如,基于该对象的声音聚焦于对象。
鉴于这种情况而构成本技术,并且使得有可能从带有声音的运动图像中提取期望的对象。
问题的解决方案
本技术的一个方面的信息处理装置包括:图像对象检测单元,基于带有声音的运动图像来检测图像对象;声音对象检测单元,基于带有声音的运动图像来检测声音对象;以及声像对象检测单元,基于图像对象的检测结果和声音对象的检测结果来检测声像对象。
本技术的一个方面的信息处理方法或程序包括以下步骤:基于带有声音的运动图像来检测图像对象;基于带有声音的运动图像来检测声音对象;并且基于图像对象的检测结果和声音对象的检测结果来检测声像对象。
在本技术的一个方面,基于带有声音的运动图像来检测图像对象;基于带有声音的运动图像来检测声音对象;并且基于图像对象的检测结果和声音对象的检测结果来检测声像对象。
本发明的效果
根据本技术的一个方面,可以从带有声音的运动图像中提取期望的对象。
注意,此处描述的效果不一定受到限制,并且可以是本公开中描述的任何效果。
附图说明
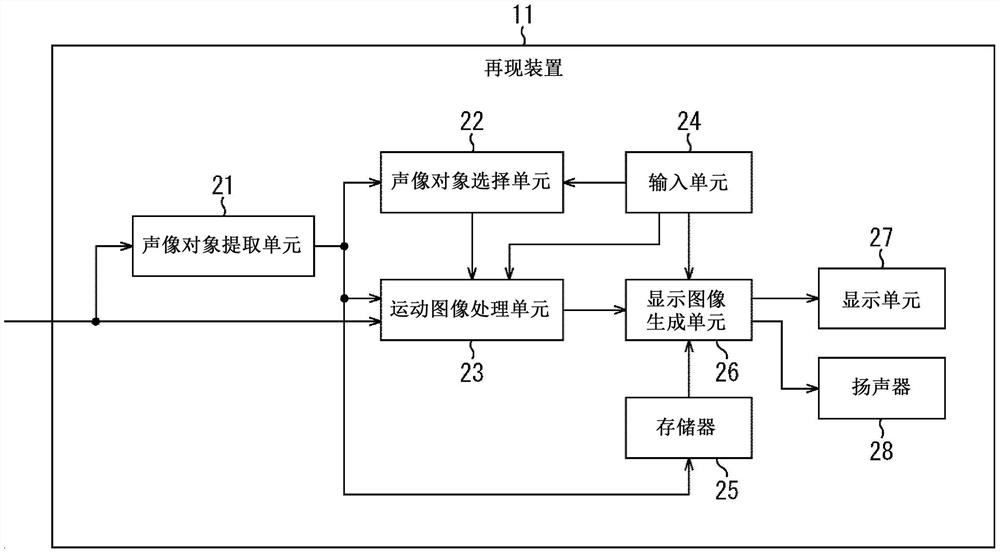
图1是示出再现装置的配置示例的示图。
图2是示出声像对象提取单元的配置示例的示图。
图3是示出声音对象检测器的配置示例的示图。
图4是描述声像对象的选择的示图。
图5是描述再现处理的流程图。
图6是描述本技术的使用实例的示图。
图7是描述本技术的使用实例的示图。
图8是描述本技术的使用实例的示图。
图9是描述本技术的使用实例的示图。
图10是描述本技术的使用实例的示图。
图11是描述本技术的使用实例的示图。
图12是示出计算机的主要配置示例的框图。
具体实施方式
在下文中,将参考附图描述应用本技术的实施例。
<第一实施例>
<关于本技术>
本技术从带有声音的运动图像中检测声音对象和图像对象,并且基于其检测结果来检测声像对象,从而能够从带有声音的运动图像中提取期望对象(即,声像对象)的图像区域和声音。
在此处,带有声音的运动图像包括运动图像和伴随运动图像的声音。在下文中,构成带有声音的运动图像的运动图像将被简单地称为带有声音的运动图像。此外,声音对象是诸如成为带有声音的运动图像的声音的声源的物体等对象,并且图像对象是诸如作为带有声音的运动图像上的被摄体而存在的物体等对象。此外,声像对象是既是带有声音的运动图像的声音对象又是图像对象的对象。
在本技术中,当检测到声像对象时,首先单独检测图像对象和声音对象。
此时,为了检测图像对象,可以适当地使用带有声音的运动图像的声音信息,例如,声音对象的检测结果和声学事件的检测结果。以这种方式,即使在构成带有声音的运动图像的运动图像是暗的、亮度不足的、被摄体不清晰的或者被摄体大部分被隐藏等情况下,也可以检测到图像对象。
此外,声源分离用于检测声音对象。因此,即使在一个方向上有多个声源,也可以根据声源的类型来分离声源的各个声音。即,可以更可靠地检测和提取声音对象。
注意,尽管此处将描述使用声源分离来检测声音对象的示例,但是例如可以组合用于检测声源方向的技术,例如,使用麦克风阵列的指向性控制。
然而,指向性控制不能简单地代替声源分离。这是因为声源分离需要关于要分离和提取的声音的声源类型及其声源的模型的先验知识,并且为了建立模型,还需要比音量差、相位差和声学特征量更多的信息,即,更多的信息。
此外,当检测到声音对象时,可以使用诸如图像对象的检测结果等图像信息。例如,通过使用图像对象的检测结果,当检测声音对象时,可以缩减声源(声音对象)所处的方向和声源的类型等。
此外,图像对象和声音对象的同现概率可以用于检测图像对象和声音对象。在这种情况下,例如,当存在预定的图像对象时,预先学习同时监测多个相应声音对象的概率,即,用于估计同现概率的模型,并且同现概率用于缩减作为检测目标的声音对象。
如果检测到图像对象和声音对象,则基于其检测结果来检测声像对象。
具体地,在本技术中,通过将检测到的图像对象和声音对象相关联来检测声像对象。
在图像对象和声音对象的关联中,例如,通过使用图像对象和声音对象的先验知识以及空间中的位置信息等,每个位置处的图像对象和声音对象可以根据位置信息正确地彼此关联。此外,在图像对象与声音对象的关联中,可以单独地将相同方向的声源变成对象。
具体地,例如,可以预先准备通过学习获得的神经网络等,并且可以通过神经网络等将声音对象和图像对象彼此关联。
此时,例如,从声音对象的先验知识(初步信息)来标记(关联)与声音对象的位置相对应的图像对象,或者相反,从图像对象的先验知识来标记(关联)与图像对象的位置相对应的声音对象。
另外,可以预先学习图像对象和声音对象的同现概率,并且该同现概率可以用于检测声像对象。
如果如上所述检测到一个或多个声像对象,则可以选择任何一个声像对象,并基于所选择的声像对象执行控制,以执行处理。
选择声像对象的方法可以由用户指定,或者可以由装置侧自动选择。
例如,在用户选择(指定)声像对象的情况下,用户可以通过使用诸如鼠标等输入操作装置的输入操作或使用语音识别的语音输入,以声像对象为单位选择期望的声像对象。
此外,在虚拟现实(VR)、增强现实(AR)、混合现实(MR)等中,可以选择预先登记的预定声像对象。在这种情况下,例如,选择对应于人声、特定声学事件、特定物体(对象)等的声像对象。
另外,在VR、AR、MR等中,可以检测用户的注视位置,并且可以选择注视位置处的声像对象,或者可以选择通过相机等中的自动聚焦(AF)聚焦的声像对象。
此外,基于所选择的声像对象的处理可以是任何处理,并且可以想到的是聚焦处理、移除处理、通知处理、快门操作控制处理等。
例如,在聚焦处理中,可以执行强调处理、图像合成等,使得所选择的声像对象的图像区域聚焦在AR或光场相机中,同时,可以强调所选择的声像对象的声音。
此外,例如,在移除处理中,可以从带有声音的运动图像中移除所选择的声像对象,例如,在AR中擦除特定的人,并且也可以移除声像对象的声音。
此外,在通知处理中,例如,在AR中,可以通知用户所选择的声像对象是值得注意的对象。此外,在快门操作控制处理中,当所选择的声像对象发出特征声音时,可以控制相机执行快门操作,以捕捉图像。
<再现装置的配置示例>
现在,下面将更详细地描述上述本技术。
图1是示出应用本技术的再现装置的一个实施例的配置示例的示图。
图1所示的再现装置11由例如能够处理带有声音的运动图像的信息处理装置形成,例如,个人计算机、头戴式显示器、游戏装置、智能手机、相机、智能扬声器和机器人。
再现装置11具有声像对象提取单元21、声像对象选择单元22、运动图像处理单元23、输入单元24、存储器25、显示图像生成单元26、显示单元27和扬声器28。
声像对象提取单元21通过从所提供的带有声音的运动图像中检测声像对象来从带有声音的运动图像中提取声像对象,并且将其提取结果提供给声像对象选择单元22、运动图像处理单元23和存储器25。
在此处,作为声像对象的提取结果,例如,对于带有声音的运动图像的每一帧,输出每个声像对象的声像对象信息。该声像对象信息包括例如图像区域信息、分离的声音、类型信息等。
图像区域信息是声像对象在带有声音的运动图像上的图像区域,即声像对象的图像,并且分离的声音是声像对象的声音,更具体地,是声像对象的声音的声音信号。此外,类型信息是指示声像对象的类型(种类)的信息。
通常,从多个声源(对象)发出的声音与带有声音的运动图像的声音混合并监测,但是在声像对象提取单元21中,仅分离(提取)作为目标的声像对象的声音,并作为分离的声音输出。
声像对象选择单元22根据从输入单元24提供的信号,基于从声像对象提取单元21提供的声像对象的提取结果,从一个或多个提取的声像对象中选择一个或多个期望的声像对象,并且将其选择结果提供给运动图像处理单元23。
运动图像处理单元23根据从输入单元24提供的信号、从声像对象选择单元22提供的选择结果以及从声像对象提取单元21提供的提取结果,基于从外部提供的带有声音的运动图像上的声像对象执行处理。
在执行图像处理,作为基于声像对象的处理的情况下,运动图像处理单元23将图像处理之后的带有声音的运动图像提供给显示图像生成单元26。
此外,例如,在再现装置11是诸如相机等具有成像功能的装置的情况下,运动图像处理单元23可以执行上述快门操作控制处理等,作为基于声像对象的处理。
输入单元24包括例如各种输入装置,例如,按钮和开关、叠设在显示单元27上的触摸面板以及用于语音识别的麦克风。输入单元24根据用户操作、语音输入等向声像对象选择单元22、运动图像处理单元23和显示图像生成单元26提供信号。
存储器25暂时保存从声像对象提取单元21提供的提取结果,并且适当地将保存的提取结果提供给显示图像生成单元26。
显示图像生成单元26根据从输入单元24提供的信号生成显示图像和再现声音,显示图像和再现声音是基于保持在存储器25中的提取结果和从运动图像处理单元23提供的经历了图像处理的带有声音的运动图像的用于再现的图像和声音。
显示图像生成单元26将生成的显示图像(更具体地,显示图像的图像数据)提供给显示单元27以显示显示图像,同时,将生成的再现声音(更具体地,再现声音的声音数据)提供给扬声器28,以再现(输出)再现声音。
显示单元27包括例如液晶显示面板等,并且显示从显示图像生成单元26提供的显示图像。扬声器28输出从显示图像生成单元26提供的再现声音。
<声像对象提取单元的配置示例>
此外,例如,再现装置11中的声像对象提取单元21被配置为如图2所示。
在图2所示的示例中,声像对象提取单元21具有图像对象检测器51、声音对象检测器52和声像对象检测器53。
图像对象检测器51通过适当地使用从声音对象检测器52提供的声学事件或声音对象的检测结果,从外部提供的带有声音的运动图像中检测图像对象。即,图像对象检测器51从构成带有声音的运动图像的运动图像中检测图像对象的图像区域。
图像对象检测器51将图像对象的检测结果提供给声音对象检测器52和声像对象检测器53。注意,在图像对象检测器51对图像对象的检测中,不仅可以使用构成带有声音的运动图像的运动图像,还可以使用构成带有声音的运动图像的声音。
声音对象检测器52适当地使用从图像对象检测器51提供的图像对象的检测结果来从外部提供的带有声音的运动图像中检测声音对象,并将检测结果提供给声像对象检测器53。对于声音对象的检测,不仅使用带有声音的运动图像的声音,而且适当地使用构成带有声音的运动图像的运动图像。
此外,声音对象检测器52还从带有声音的运动图像中检测声学事件。声音对象检测器52适当地将声音对象和声学事件的检测结果提供给图像对象检测器51。
注意,更具体地,在声音对象检测器52中,通过检测声音对象,从带有声音的运动图像的声音中提取检测到的声音对象的声音(分离的声音)。
声像对象检测器53基于从图像对象检测器51提供的检测结果和从声音对象检测器52提供的检测结果来检测声像对象。此处,通过将图像对象与声音对象相关联来检测声像对象。
此外,声像对象检测器53根据图像对象的检测结果和声音对象的检测结果生成检测到的声像对象的声像对象信息,从而从带有声音的运动图像中提取声像对象。声像对象检测器53将作为提取声像对象的结果而获得的声像对象信息提供给声像对象选择单元22、运动图像处理单元23和存储器25。
注意,声像对象是既是图像对象又是声音对象的对象。然而,在预定帧中是图像对象而不是声音对象的对象可以被假设为无声声像对象。
即,而且,在当前帧中对于在过去帧中被视为声像对象的图像对象没有对应的声音对象的情况下,图像对象可以被视为当前帧中的无声声像对象。
这是因为例如在预定帧中没有检测到对应的声音对象但是在过去帧中检测到对应的声音对象的图像对象也需要被视为声像对象。注意,可以通过跟踪等来识别多个帧中哪些图像对象彼此对应。
类似地,在具有声像对象的帧中,可能被某种屏蔽等隐藏并消失。因此,关于在过去帧中被假设为声像对象的声音对象,即使在当前帧中没有对应的图像对象的情况下,声音对象也可以被视为当前帧中的声像对象。
此外,没有对应的声音对象的图像对象或没有对应的图像对象的声音对象可以被分类为背景图像或背景声音对象,即背景对象。
此外,已经在图2中描述了声像对象检测器53基于图像对象的检测结果和声音对象的检测结果来检测声像对象的示例,但是也可以配置声像对象检测器53,以使用带有声音的运动图像作为输入来检测声像对象。
然而,不是通过输入带有声音的运动图像来用声像对象检测器53检测声像对象,而是可以通过在声像对象检测器53之前设置图像对象检测器51和声音对象检测器52来高精度地检测声像对象,如图2的示例所示。
<声音对象检测器的配置示例>
此外,例如,声音对象检测器52被配置为如图3所示。
在图3所示的示例中,声音对象检测器52具有声源分离单元81和声学事件检测单元82。
声源分离单元81通过适当地使用从图像对象检测器51提供的检测结果和从声学事件检测单元82提供的声学事件的检测结果,基于从外部提供的带有声音的运动图像的声音,通过声源分离来检测声音对象。声源分离单元81将声音对象的检测结果提供给声学事件检测单元82和声像对象检测器53。注意,声音对象的检测结果也可以被提供给图像对象检测器51。
声学事件检测单元82通过适当地使用从声源分离单元81提供的检测结果,从外部提供的带有声音的运动图像的声音中检测特定的声学事件,并且将其检测结果提供给声源分离单元81和图像对象检测器51。
<关于再现装置的各个单元的操作>
接下来,将更详细地描述上述再现装置11的各个单元的操作。
首先,将描述声源分离单元81和声学事件检测单元82。
例如,声源分离单元81可以由神经网络构成。
通常,由麦克风记录的声音是从多个声源发出的声音的混合。即,在来自多个声源的声音混合的状态下,麦克风监测来自各个声源的声音。因此,为了提取声音对象,需要用于从混合声音中仅分离目标声音对象的声音的声源分离技术。
因此,在声源分离单元81中,通过使用如在“Multi-scale Multi-band DenseNetsfor Audio Source Separation,WASPAA 2017”(以下称为“技术文件1”)等中描述的技术来执行声源分离,以便检测和提取声音对象的声音。
即,在声源分离单元81由神经网络配置的情况下,最终要检测的期望对象是作为声源分离中的检测目标(提取目标)的声音对象。此外,预先准备包括作为检测目标的声音对象的声音和可以同时被监测的其他语音的声音数据,作为用于通过神经网络进行学习的数据。
然后,使用这种声音数据用于学习,执行通过神经网络的学习,以便从混合声音中估计目标对象的声音,作为声音对象的声音。特别是在学习期间,神经网络进行学习,以便最小化频域中幅度谱的估计平方误差。
在神经网络中,可以想象,随着作为检测目标的对象的类型增加,分离性能降低。这是因为在具有相似声学特性的对象之间出现混淆,并且输出目的地是分散的。
为了防止这种混淆的发生,图像信息可以用于用作声源分离单元81的神经网络中的声源分离。在此处,图像信息可以是带有声音的运动图像本身,或者可以是带有声音的运动图像的图像物体识别的结果、图像对象的检测结果等。
例如,通过使用构成带有声音的运动图像的运动图像的图像物体识别结果作为图像信息,可以预先缩减候选声音对象的类型,并且可以以更高的精度执行声源分离。
此外,例如,在存在多个麦克风并且带有声音的运动图像的声音变成多个声道的声音的情况下,可以验证通过声音的声源位置估计结果和通过图像的图像物体位置估计结果,以便缩减在每个方向上的声音对象。
具体地,例如,指示作为检测目标的对象(声音对象)的类型的指数由i表示(其中,i=1,...,N),并且由图像物体识别器的作为对象的检测结果获得的第i个对象的存在概率由p
在这种情况下,在构成声源分离单元81的神经网络中,仅需要通过仅限制存在概率p
因此,在这种情况下,声音对象检测器52设置有未示出的图像物体识别器,该图像物体识别器使用带有声音的运动图像,作为输入,并且从带有声音的运动图像中检测N个对象中的每一个的图像区域。
然后,声源分离单元81使用作为图像物体识别器的输出的存在概率p
在这种情况下,当检测声音对象时,声源分离单元81基于声音对象的类型来执行对象的缩减,使得只有作为带有声音的运动图像上的对象而存在的对象被视为检测目标。
注意,也可以使用图像对象检测器51的输出来代替作为图像物体识别器的输出的存在概率p
另外,在图像对象检测器51的输出用于检测声音对象的情况下,例如,在构成声源分离单元81的神经网络中,可以增加与图像对象检测器51检测到的图像对象相对应的声音对象的存在概率。此外,在这种情况下,对应于未检测到的图像对象的声音对象的存在概率可以显著降低。
此外,在带有声音的运动图像的声音具有多个声道的情况下,可以缩减在每个方向上声音对象的候选。
在这种情况下,作为由图像对象识别器或图像对象检测器51的检测结果而获得的图像对象(物体)的位置,即,图像对象存在的方向、图像对象在该位置的存在概率p
在声源分离单元81中,可以通过从输入的带有声音的运动图像的声音进行估计来获得作为声音对象的候选的声源的位置(即声源的方向)。因此,在声源分离单元81中,对于声源的每个方向,只有属于关于图像对象在声源方向上的存在概率p
在这种情况下,基于构成带有声音的运动图像的运动图像上的图像对象的位置,即,通过图像物体识别等的图像物体位置以及作为声音对象的声源的位置,缩减作为检测目标的声音对象。
此外,存在这样的可能性,即,在带有声音的运动图像的声音中收集并包括从不作为带有声音的运动图像上的被摄体存在的物体发出的声音。
在这种情况下,对于图像对象识别器或图像对象检测器51的输出,即,检测到的图像对象(物体),只需要预先学习用于估计当存在图像对象时同时监测的多个声音对象的同现概率q
然后,声源分离单元81还可以使用同现概率q
在这种情况下,在声音对象检测器52中提供由例如神经网络等构成的未示出的用于估计同现概率q
声源分离单元81使用作为图像对象检测器51的检测结果的存在概率p
此时,当检测到声音对象时,具有高同现概率q
此外,在存在多个相同类型的声音对象并且这些声音对象同时发出声音的情况下,如上述技术文件1中那样仅根据对象的类型来执行声源分离的方法不能分离多个相同类型的声音对象的声音。
因此,例如,声源分离单元81可以通过使用指示声像的定位位置、声源独立性、频域中的稀疏性等的定位信息、独立分量分析、基于聚类的方法、通过无排列学习获得的神经网络等进行波束成形来配置。注意,图像信息可以用作定位信息。
此外,声学事件检测单元82包括例如神经网络等,从所提供的带有声音的运动图像的声音中检测特定的声学事件,并将作为其检测结果的声学事件信息提供给图像对象检测器51和声源分离单元81。
在此处,例如,人类的声音、动物(例如,狗)的叫声或预定的音乐被检测为特定的声学事件,并且输出包括声学事件发生的后验概率的信息,作为声学事件信息。注意,声学事件信息可以包括指示已经发生声学事件的方向的方向信息等。
如上所述,声源分离单元81和声学事件检测单元82可以相互使用检测结果。
例如,在声源分离单元81中,包括在声学事件信息中的后验概率也用作声源分离的神经网络的输入,并且执行声源分离,使得可以容易地检测与输入后验概率高的声学事件相对应的声音对象。在这种情况下,可以说,声源分离单元81通过检测声学事件来检测声音对象。
另一方面,在声学事件检测单元82中,从声源分离单元81提供的声音对象的检测结果和带有声音的运动图像的声音用作输入,并且检测声学事件,使得对应于检测到的声音对象的声学事件的后验概率高。
随后,将描述图像对象检测器51。
图像对象检测器51可以通过例如神经网络来构造,并且可以使用物体检测技术、分割技术等来构造图像对象检测器51。
注意,在例如“You Only Look Once:Unified,Real-Time Object Detection,CVPR 2016”(以下称为技术文件2)中,详细描述物体检测技术。此外,在例如“One-ShotVideo Object Segmentation,CVPR 2017”(以下称为“技术文件3”)中,详细描述分割技术。
此外,在图像对象检测器51中,带有声音的运动图像的声音、从声学事件检测单元82提供的声学事件信息以及由声源分离单元81获得的声音对象的检测结果可以用作输入,使得即使带有声音的运动图像上的被摄体不清楚时,也可以高性能地检测图像对象。
例如,存在这样的情况,其中,期望从带有声音的运动图像中检测狗作为图像对象,但是狗剧烈运动,并且带有声音的运动图像上的狗图像不清晰。
然而,即使在这种情况下,也可以从声音对象的检测结果和作为声学事件信息提供的狗叫的信息中,大概率获得狗作为被摄体被包括在带有声音的运动图像中的信息。然后,通过使用这样的信息,可以提高作为图像对象的狗的检测精度。
当构成图像对象检测器51的神经网络学习时,通过将带有声音的运动图像的声音、声音对象的检测结果、声学事件信息等作为输入,并使神经网络学习,可以实现这种信息的使用。
在这种情况下,在检测图像对象时,不仅带有声音的运动图像的运动图像,而且带有声音的运动图像的声音和声音对象的检测结果、声学事件信息等也被输入到构成图像对象检测器51的神经网络。
在图像对象检测器51中,如在声源分离单元81的情况下,可以通过使用声音对象的检测结果、声学事件信息等,基于对象类型、声源位置、图像物体位置、同现概率等来缩减作为检测目标的图像对象。
此外,声像对象检测器53基于图像对象的检测结果和声音对象的检测结果来检测声像对象。
在此处,声像对象的检测等同于将图像对象检测器51检测到的图像对象与声音对象检测器52检测到的声音对象相关联的处理。
例如,图像对象检测器51输出图像对象信息,作为图像对象的检测结果,即图像对象的提取结果。图像对象信息包括例如图像区域信息和图像类型信息。
在此处,图像区域信息是带有声音的运动图像中的图像对象的图像(视频),即,存在图像对象的图像区域的图像。此外,图像类型信息是指示图像区域信息的信息,即,存在于图像区域中的图像对象的类型,并且例如,图像类型信息是在图像区域中具有指数i的图像对象的存在概率p
此外,例如,声源分离单元81输出声音对象信息,作为声音对象的检测结果,即声音对象的提取结果。该声音对象信息包括从带有声音的运动图像中提取的声音对象的声音(分离的声音)以及指示分离的声音的声音对象的类型的声音类型信息。例如,声音类型信息是分离的声音是具有指数i等的声音对象的声音的概率(识别概率)p
例如,声像对象检测器53是神经网络,其以图像对象信息和声音对象信息作为输入并且基于图像对象信息和声音对象信息输出检测到的图像对象和声音对象是同一对象(物体)的概率。在此处,图像对象和声音对象是同一对象的概率是图像对象和声音对象的同现概率。
即,在构成声像对象检测器53的神经网络中,例如,使用图像类型信息、声音类型信息、图像对象位置信息、声音对象方向信息、从时间序列图像对象位置信息获得的关于图像对象的运动的信息等来确定检测到的图像对象和声音对象是否匹配。
构成这种声像对象检测器53的神经网络可以使用带有声音的运动图像的数据集来学习,在该数据集中,图像对象和声音对象由人预先彼此关联。此外,构成声像对象检测器53的神经网络可以使用由学习装置等自动标记的数据来学习,即,带有声音的运动图像的数据集,在该数据集中,图像对象和声音对象通过学习装置等彼此关联。
声像对象检测器53获得对于图像对象和声音对象的所有组合或部分组合的图像对象和声音对象匹配的同现概率。
然后,声像对象检测器53以获得的同现概率的降序将图像对象与声音对象相关联,并且相关联的图像对象和声音对象被假设为同一声像对象。
此外,声像对象检测器53基于相关联的图像对象的存在概率p
在此处,假设图像对象、声音对象和声像对象的定义相同。注意,定义相同意味着,例如,指示图像对象类型的指数i和指示声音对象类型的指数i都指示相同类型的对象。
具体地,例如,假设图像对象的类型是“人”,声音对象的类型是“人拍手的声音”、“人的说话声音”等。在这种情况下,图像对象类型“人”和声音对象类型“人拍手的声音”的定义是不同的。
例如,在图像对象、声音对象和声像对象的定义相同的情况下,声像对象检测器53可以将图像对象的存在概率p
注意,在图像对象和声音对象的定义不同的情况下,仅需要在通过使用转换表将图像对象和声音对象中的一个的类型转换为另一个的类型之后确定声像对象的类型。
具体地,例如,当图像对象的类型是“人”并且声音对象的类型是“人拍手的声音”时,例如,声音对象的类型“人拍手的声音”被改变为“人”。
注意,转换表可以根据预期用途预先手动确定,或者可以通过基于用于使图像对象和声音对象的类型关联的数据对同现概率进行聚类来自动生成,诸如此类。
一旦通过上述处理检测到声像对象并且确定了声像对象的类型,声像对象检测器53输出声像对象信息,作为声像对象的检测结果,即声像对象的提取结果。
如上所述,声像对象信息包括例如指示声像对象的类型的类型信息、声像对象的图像区域信息以及声像对象的分离声音。注意,图像区域信息还可以包括例如指示图像区域的位置的信息,即声像对象在带有声音的运动图像上的位置。
随后,将描述声像对象选择单元22对声像对象的选择以及运动图像处理单元23基于声像对象的处理。
声像对象选择单元22基于从声像对象检测器53提供的声像对象信息,选择声像对象作为针对声像对象的缩放处理、聚焦处理、通知处理等的目标。注意,声像对象的选择可以由用户手动执行,或者可以由声像对象选择单元22自动执行。
例如,在用户手动选择声像对象的情况下,用户在观看在显示单元27上显示的显示图像的同时操作输入单元24,并且从显示图像中选择(指定)期望的声像对象。
具体地,例如,假设在显示单元27上显示图4所示的显示图像。在该示例中,在显示图像上显示具有声音的运动图像P11,并且在具有声音的运动图像P11上显示指示作为声像对象的儿童、汽车和小提琴的相应位置的矩形框W11至W13。
此外,在显示图像中具有声音的运动图像P11的示图中,在左侧,指示帧W11至W13的相应位置处显示的声像对象的字符“小孩”、“汽车”和“小提琴”。即,指示这些声像对象的字符形成对象列表,在该列表中可以基于对象选择声像对象。
在这种情况下,用户操作输入单元24,以从对象列表中选择期望的声像对象。然后,声像对象选择单元22响应于用户的操作,基于从输入单元24提供的信号,从声像对象信息指示的声像对象中选择用户选择的声像对象。
此外,例如,用户可以输入声像对象和指定对声像对象的处理的声音,例如,“放大小提琴”作为向作为输入单元24的麦克风的声音。在这种情况下,例如,输入单元24对麦克风拾取的语音执行语音识别,并将语音识别结果提供给声像对象选择单元22。然后,声像对象选择单元22基于从输入单元24提供的识别结果选择“小提琴”,作为声像对象。
此外,在用户在声像对象选择单元22侧自动选择而不执行选择操作的情况下,例如,输入单元24等检测用户的视线,并且其检测结果被提供给声像对象选择单元22。然后,声像对象选择单元22基于所提供的视线检测结果来选择用户正在注视的声像对象。此外,例如,可以被配置为基于声像对象信息选择预先登记的声像对象。
运动图像处理单元23基于从声像对象选择单元22提供的声像对象的选择结果,对例如带有声音的运动图像执行各种处理。
例如,在执行缩放处理的情况下,基于由声像对象选择单元22选择的声像对象的声像对象信息,运动图像处理单元23从所提供的带有声音的运动图像中剪出并放大以所选择的声像对象为中心的图像区域,从而生成放大的图像。此时,图像区域信息可以用于生成放大图像。
此外,基于由声像对象选择单元22选择的声像对象的声像对象信息,运动图像处理单元23使得所选择的声像对象的音量相对增加,或者使得仅所选择的声像对象的声音再现。此外,所选择的声像对象的声音的声像可以根据放大的图像定位在适当的位置。
例如,在所选择的声像对象的音量增加的情况下,只需要适当地放大(调整增益)所选择的声像对象的分离的声音,并将放大后的分离声音添加到带有声音的运动图像的声音中。此外,在仅再现所选择的声像对象的声音的情况下,分离的声音用作再现声音。
此外,例如,在重新排列声像的定位位置的情况下,根据声像对象的位置,通过使用强度立体声、使用头部相关传递函数的双耳再现、波场合成等来调整声像的定位。
此外,在执行聚焦处理的情况下,当带有声音的运动图像是由光场相机拍摄的运动图像时,运动图像处理单元23基于作为带有声音的运动图像的图像组来执行图像合成,从而生成聚焦在所选择的声像对象上的运动图像,作为聚焦处理之后的带有声音的运动图像。
另外,在带有声音的运动图像是不由光场相机拍摄的正常运动图像的情况下,运动图像处理单元23可以对带有声音的运动图像上的声像对象中除了所选择的声像对象之外的一个对象执行模糊处理等,使得聚焦所选择的声像对象。
此外,在执行聚焦处理的情况下,所选择的声像对象的音量可以相对增加,或者除了所选择的声像对象的声音之外的声音可以经历语音模糊处理,如在缩放处理的情况下。
此外,在执行与声像对象相关的通知处理的情况下,例如,运动图像处理单元23基于声像对象信息对带有声音的运动图像执行强调处理,使得在所选择的声像对象的区域中显示边界框(帧)等,以强调声像对象。因此,可以通知(呈现)用户选择了哪个声像对象。
此外,例如,在显示VR图像作为显示图像的情况下,当所选择的声像对象在用户的视野之外时,即,当所选择的声像对象在显示图像之外时,可以执行处理带有声音的运动图像以使得在显示图像上显示指示存在所选择的声像对象的方向的箭头等的处理,作为通知处理。此外,在这种情况下,运动图像处理单元23可以对带有声音的运动图像的声音执行信号处理,使得在双耳再现中强调和再现所选择的声像对象的分离声音。通过这些处理,可以通知用户该用户可能感兴趣的声像对象的存在。
此外,在正常运动图像或AR图像被显示为显示图像的情况下,可以执行从用于生成显示图像的带有声音的运动图像中移除所选择的声像对象以便移除(删除)所选择的声像对象的声音的处理,作为移除处理。
具体地,例如,假设人们期望从作为带有声音的运动图像上的被摄体的城市风景中擦除作为所选择的声像对象的人,以便获得没有人的城市风景的图像。在这种情况下,运动图像处理单元23移除(擦除)从带有声音的运动图像中选择的声像对象,并且使用诸如修复等技术来执行补充处理,以便将城市风景的图像添加到移除的声像对象的区域。
注意,在例如“A study on effect of automatic perspective correction onexemplar-based image inpainting”,ITE Trans.on Media Technology andApplications,第4卷,第1期,2016年1月等中,具体描述修复。
此外,关于声音,运动图像处理单元23可以处理声音,使得通过基于所选择的声像对象的分离声音和带有声音的运动图像的声音,仅从带有声音的运动图像的声音中移除分离的声音,来输出除了分离的声音之外的任何声音。在这种情况下,例如,通过将反相的分离声音添加到带有声音的运动图像的声音中,从带有声音的运动图像的声音中仅移除分离声音。因此,例如,可以仅移除人的声音,而留下风景的声音,例如,鸟的啁啾声、河流的潺潺声和风声。
此外,例如,根据对声像对象的检测和选择,可以执行控制,以执行除了用于带有声音的运动图像及其声音的处理之外的特定处理(动作)。
例如,在再现装置11具有成像功能的情况下,当声像对象选择单元22检测并选择特定声像对象时,运动图像处理单元23可以被配置为指示未示出的成像单元捕捉静止图像,即,快门操作的执行。另外,例如,运动图像处理单元23可以执行对所选择的声像对象的搜索处理的执行的控制等。
<再现处理说明>
随后,将描述由再现装置11执行的处理的流程。即,下面将参考图5的流程图描述由再现装置11执行的再现处理。
在步骤S11中,声学事件检测单元82通过适当地使用从声源分离单元81提供的声音对象的检测结果,基于从外部提供的带有声音的运动图像的声音来检测声学事件。
例如,在步骤S11中,声音对象的检测结果和带有声音的运动图像的声音被输入到构成声学事件检测单元82的神经网络,并且执行算术处理,以便检测声学事件。声学事件检测单元82将作为声学事件的检测结果获得的声学事件信息提供给声源分离单元81和图像对象检测器51。注意,检测到的声学事件可以原样用作声音对象。
在步骤S12中,声源分离单元81通过适当地使用从声学事件检测单元82提供的声学事件信息、从图像对象检测器51提供的检测结果等,基于外部提供的带有声音的运动图像的声音来检测声音对象,并且将其检测结果提供给声学事件检测单元82和声像对象检测器53。注意,声音对象的检测结果可以提供给图像对象检测器51。
例如,在步骤S12中,声学事件信息、图像对象的检测结果、图像对象识别器的图像对象识别结果、以及带有声音的运动图像的声音被输入到构成声源分离单元81的神经网络,并且执行算术处理,以便检测声音对象。此时,可以基于上述对象类型、声源位置、通过图像物体识别等的图像物体位置、同现概率等来缩减声音对象的候选。
在步骤S13中,图像对象检测器51通过适当地使用从声学事件检测单元82提供的声学事件信息和从声源分离单元81提供的声音对象的检测结果,基于从外部提供的带有声音的运动图像来检测图像对象。
例如,在步骤S13中,声学事件信息、声音对象的检测结果和带有声音的运动图像被输入到构成图像对象检测器51的神经网络,并且执行算术处理,以便检测图像对象。图像对象检测器51将图像对象的检测结果提供给声源分离单元81和声像对象检测器53。
注意,更具体地,同时执行上述步骤S11至S13。
在步骤S14中,声像对象检测器53基于作为从图像对象检测器51提供的图像对象的检测结果的图像对象信息和作为从声源分离单元81提供的声音对象的检测结果的声音对象信息来检测声像对象。
例如,在步骤S14中,图像对象信息和声音对象信息被输入到构成声像对象检测器53的神经网络,并且执行算术处理。在算术处理中,例如,执行基于同现概率的图像对象与声音对象彼此的关联,并且确定通过关联检测到的声像对象的类型。
声像对象检测器53将作为声像对象的检测结果获得的声像对象信息提供给声像对象选择单元22、运动图像处理单元23和存储器25。
在步骤S15中,声像对象选择单元22根据从输入单元24提供的信号等,基于从声像对象检测器53提供的声像对象信息选择一个或多个声像对象,然后将其选择结果提供给运动图像处理单元23。
在步骤S16中,运动图像处理单元23根据从输入单元24提供的信号和从声像对象选择单元22提供的选择结果,基于从声像对象检测器53提供的声像对象信息和从外部提供的带有声音的运动图像,执行基于声像对象的处理。
例如,在步骤S16中,作为基于声像对象的处理,对带有声音的运动图像和带有声音的运动图像的声音执行上述缩放处理、聚焦处理、通知处理、移除处理等,并且将作为处理结果获得的带有声音的运动图像提供给显示图像生成单元26。另外,可以执行快门操作控制处理等,作为基于声像对象的处理。
在步骤S17中,显示图像生成单元26根据从输入单元24提供的信号,基于从运动图像处理单元23提供的带有声音的运动图像来生成显示图像和再现声音。此时,显示图像生成单元26通过适当地使用记录在存储器25中的声像对象信息来生成显示图像。
例如,在显示图像是VR图像的情况下,显示图像生成单元26在基于声像对象的处理之后剪出带有声音的运动图像中用户视野内的区域,其从运动图像处理单元23提供,以便使用剪出的区域作为显示图像,并且在基于声像对象的处理之后带有声音的运动图像的声音原样用作再现声音。
在步骤S18中,显示图像生成单元26将生成的显示图像提供给显示单元27用于显示,将再现声音提供给扬声器28以输出再现声音,并结束再现处理。
如上所述,再现装置11从带有声音的运动图像中检测图像对象,并且检测声音对象,并且基于其检测结果来检测声像对象。以这种方式,可以更可靠地从带有声音的运动图像中提取期望的声像对象。
<使用实例1>
在此处,将描述本技术的使用实例。
例如,本技术可以用于执行基于对象的缩放处理的情况。
即,在本技术中,可以通过选择声像对象来基于对象执行聚焦和缩放,而不是指定带有声音的运动图像的一部分区域并基于位置执行缩放处理。
例如,假设如图6中的箭头Q11所示,在没有对由监视相机等捕捉的带有声音的运动图像进行任何特殊处理的情况下,带有声音的运动图像及其声音被显示单元27和扬声器28分别原样再现为显示图像和再现声音。
在图6所示的示例中,在显示单元27上显示的显示图像在箭头Q11所示的部分中示出,并且显示图像包括作为声像对象OB11的拥有个人计算机的女性。
在这种状态下,假设如箭头Q12所示,观看显示图像的用户U11向作为输入单元24的麦克风输入语音“放大带个人计算机的女人并让我听她的对话”。在这种情况下,输入单元24向声像对象选择单元22和运动图像处理单元23提供指示对于输入语音的语音识别结果等的信号。
然后,2响应于来自输入单元24的信号,声像对象选择单元2从带有声音的运动图像中检测到的声像对象中选择由用户U11指定的声像对象OB11,即“带个人计算机的女人”。
然后,在运动图像处理单元23中,带有声音的运动图像中的所选择的声像对象OB11周围的区域的图像被提供给显示图像生成单元26,并且在显示单元27上显示声像对象OB11周围的区域的图像,作为显示图像,如箭头Q13所示。
在此处,由运动图像处理单元23执行生成声像对象OB11周围区域的图像的处理,作为缩放处理。注意,声像对象OB11周围的区域的图像可以是声像对象OB11的声像对象信息中包括的图像区域信息本身,或者可以是基于图像区域信息等从带有声音的运动图像中剪切出的图像。
此外,在运动图像处理单元23中,例如,作为声音的缩放处理,执行仅提取声像对象OB11的声音并将该声音提供给显示图像生成单元26的处理。在此处,例如,包括在声像对象OB11的声像对象信息中的分离声音被原样提供给显示图像生成单元26,并且输出该分离声音,作为再现声音。在这个示例中,“9点钟在品川码头交货”被再现为再现声音,作为声像对象OB11的声音。
如上所述,在本技术中,可以通过语音输入(语音命令)以对象为单位指定声像对象,作为目标,并执行图像和声音的缩放处理。
<使用实例2>
此外,本技术还可以用于再现360度全方位运动图像并且再现诸如VR等图像。
具体地,例如,用户在VR图像中凝视的对象可以被聚焦,并且可以强调对象的声音,如图7所示。
在图7所示的示例中,例如,如箭头Q21所示,在头戴式显示器的显示单元27上原样显示带有声音的运动图像,作为显示图像。
在此处,显示图像(带有声音的运动图像)包括作为用户正在注视的小女孩的声像对象OB21、作为汽车的声像对象OB22和作为狗的声像对象OB23,作为声像对象。此外,再现了声像对象OB21的声音“爸爸,快看”,但是该声音淹没在作为汽车的声像对象OB22的声音“嗡嗡”和作为狗的声像对象OB23的吠叫“哇呜”中。
在这种情况下,假设从输入单元24向声像对象选择单元22提供指示用户注视方向的信号,并且声像对象选择单元22选择作为小女孩的声像对象OB21。然后,运动图像处理单元23对女孩执行聚焦处理。
即,例如,运动图像处理单元23基于从声像对象检测器53提供的声像对象信息,对带有声音的运动图像中的汽车和狗的区域,即声像对象OB22和声像对象OB23的区域,执行模糊处理,从而执行聚焦处理,以相对聚焦在声像对象OB21上。
此外,对于带有声音的运动图像的声音,运动图像处理单元23通过在后续阶段中仅向显示图像生成单元26输出声像对象OB21的分离的声音,仅提取声像对象OB21的声音,即,执行聚焦处理,以聚焦女孩的声音。
因此,在显示单元27上,例如,作为汽车的声像对象OB22和作为狗的声像对象OB23模糊,如箭头Q22所示,并且聚焦在作为用户正在注视的女孩的声像对象OB21上。此外,在这种情况下,仅仅再现声像对象OB21的声音“爸爸,快看”,作为声音的再现声音。
此外,除了图7所示的示例之外,例如,显示图像生成单元26可以基于保持在存储器25中的声像对象的检测结果,生成从带有声音的运动图像中检测到的声像对象的列表,并且执行控制,以在显示单元27上显示该列表。在这种情况下,用户可以操作输入单元24,从显示的列表中选择期望的声像对象。
然后,例如,在运动图像处理单元23中,通过基于作为由光场相机拍摄的带有声音的运动图像的图像组执行图像合成,可以生成聚焦在所选择的声像对象上的运动图像,作为聚焦处理之后的带有声音的运动图像。在这个示例中,用户可以用更直观的操作来选择和聚焦期望的声像对象。
<使用实例3>
此外,本技术还可以用于例如具有成像功能的家庭代理、机器人、动作相机等中的运动图像搜索。
即,例如,从用户在没有特别注意的情况下拍摄和存储的运动图像中,可以搜索满足针对运动图像(视频)和声音的预定条件的运动图像或场景,例如,“A先生弹吉他的视频”和“狗与其主人一起唱歌的视频”。
作为具体示例,例如,如图8中的箭头Q31所示,假设显示单元27显示在记录单元(未示出)中记录的带有声音的运动图像的列表。在此处,文本“你想看什么运动图像?”与列表一起显示,以提示搜索带有声音的运动图像。
例如,假设看到这种列表的用户U31向作为输入单元24的麦克风输入语音“给我看Billy弹吉他的运动图像”,如箭头Q32所示。在这种情况下,输入单元24向声像对象选择单元22和运动图像处理单元23提供指示针对输入语音的语音识别结果等的信号。
然后,声像对象提取单元21通过以记录在记录单元中的带有声音的运动图像为目标来执行声像对象的检测。然后,声像对象选择单元22基于从输入单元24提供的信号,选择具有指定人“Billy”的图像区域信息和分离声音的声像对象以及具有作为指定乐器的吉他的图像区域信息和分离声音的声像对象,并且将其选择结果提供给运动图像处理单元23。
运动图像处理单元23基于从声像对象选择单元22提供的选择结果,从带有声音的运动图像中选择满足用户U31指定的条件的带有声音的运动图像,即,“Billy”和“吉他”被检测为声像对象的带有声音的运动图像,并将选择的带有声音的运动图像提供给显示图像生成单元26。此时,仅“Billy”和“吉他”中的一个被检测为声像对象的带有声音的运动图像可以作为带有声音的运动图像(作为另一候选)提供给显示图像生成单元26。
因此,显示单元27显示例如显示带有声音的运动图像的缩略图SM11(“Billy”和“吉他”被检测为声像对象)以及作为其他候选的带有声音的运动图像的缩略图的屏幕,作为搜索结果,如箭头Q33所示。
<使用实例4>
此外,例如,当在VR等中观看360度全方位运动图像时,本技术还可以用于通知用户在用户的视野之外存在值得注意的对象的情况。这使得可以例如防止用户忽略用户可能感兴趣的场景等。
具体地,例如,假设在头戴式显示器的显示单元27上显示在带有声音的运动图像中的预定视野区域,作为显示图像,如图9中的箭头Q41所示。此外,此时,假设从带有声音的运动图像中检测到用户可能感兴趣的鸟,作为声像对象OB41,但是声像对象OB41此时在视野之外。
在这种情况下,例如,如果在声像对象选择单元22中选择了声像对象OB41,则运动图像处理单元23执行叠加处理,用于将表示声像对象OB41的标记MK11和指示声像对象OB41相对于带有声音的运动图像的当前视野的区域位于带有声音的运动图像上的方向的箭头标记MK12叠加。在此处,执行这样的叠加处理,作为通知处理,用于通知用户声像对象OB41的存在和声像对象OB41的方向。
此后,例如,如果用户在视觉上识别标记MK11和箭头标记MK12,并将视线指向由箭头标记MK12指示的方向,则显示单元27的显示如箭头Q42所示改变,在显示图像上显示作为鸟的声像对象OB41,并且再现声像对象OB41的分离声音“啁啾”,作为再现声音。
<使用实例5>
此外,本技术还可以用于执行移除处理的情况,例如,可以从诸如自然或城市等风景的运动图像中移除任意对象的图像和声音,从而生成好像该对象不存在的运动图像。
具体地,例如,如图10中的箭头Q51所示,假设显示单元27包括分别是行走的人和狗的声像对象OB51和声像对象OB52。此外,还假设作为狗的声像对象OB52的吠叫“哇呜”也被再现为再现声音。
此时,假设例如用户操作输入单元24,来移动在显示图像上显示的指针PT11并选择声像对象OB51和声像对象OB52,然后给出删除这些声像对象的指令。在这种情况下,声像对象选择单元22根据从输入单元24提供的信号选择声像对象OB51和声像对象OB52,并且将其选择结果提供给运动图像处理单元23。
然后,运动图像处理单元23从带有声音的运动图像中移除声像对象OB51和声像对象OB52的区域,并且使用诸如对这些区域进行修复等技术来执行图像互补处理。此外,运动图像处理单元23将声像对象OB52的分离声音的相反相位的声音添加到带有声音的运动图像的声音,从而从带有声音的运动图像的声音中移除声像对象OB52的声音。
因此,例如,从具有声音的原始运动图像中移除声像对象OB51和声像对象OB52的图像被显示为显示图像,如箭头Q52所示,并且不再能够听到已经再现的声像对象OB52的声音。即,显示该显示图像,好像没有在散步的人和狗。
<使用实例6>
此外,本技术还可以用于控制快门操作的执行。
例如,如果使用本技术来控制快门操作的执行,则可以在不依赖于环境噪声或无意对象的声音的情况下,例如,当特定的人发出特定的声音或特定的狗吠叫时,在不错过决定性时刻的情况下释放快门。
具体地,例如,假设具有成像功能的相机等的显示图像生成单元26使得在显示单元27上显示由图11中的箭头Q61指示的显示图像。
在此处,由箭头Q61指示的显示图像包括:显示作为带有声音的运动图像的直通图像MV11的区域,在该区域中,作为人的声像对象OB61和作为狗的声像对象OB62作为被摄体存在;以及显示从直通图像MV11检测到的声像对象的列表的区域。
例如,显示图像生成单元26基于保存在存储器25中的声像对象信息来生成声像对象的列表,并且在此处,该列表描述被检测为声像对象的“狗”和“人”。
在这种状态下,假设用户操作输入单元24,来移动显示图像上的指针PT21,并从声像对象列表中选择“狗”。因此,从直通图像MV11上的声像对象中选择要为快门操作跟踪的声像对象OB62。
然后,显示图像生成单元26生成操作列表,以作为用户选择的要跟踪的声像对象OB62的快门操作的触发,以便允许选择用于执行快门操作的时间,并且执行控制,以在显示图像上显示该列表,如箭头Q62所示。在此处,“跑”、“吠叫”和“自动”被显示为作为触发的动作。
例如,如果选择“跑”,作为触发,则运动图像处理单元23使得快门或未示出的成像元件在基于作为狗的声像对象OB62的时间序列声像对象信息检测到作为狗的声像对象OB62的跑的定时进行操作,从而允许捕捉静止图像。
此外,例如,如果选择“吠叫”,作为触发,则运动图像处理单元23使得快门或未示出的成像元件在基于作为狗的声像对象OB62的声像对象信息检测到作为狗的声像对象OB62的吠叫的定时进行操作,从而允许捕捉静止图像。注意,例如,对于分离的声音,可以通过语音识别等来检测狗是否吠叫,或者可以从作为声学事件检测单元82中的声学事件的狗吠叫的检测结果或者作为声源分离单元81中的声音对象的狗吠叫的检测结果来识别狗是否吠叫。
此外,例如,如果选择“自动”,作为触发,则运动图像处理单元23使得快门或未示出的成像元件在基于作为狗的声像对象OB62的声像对象信息,满足预先确定的条件的适当定时(例如,狗静止时的定时)进行操作,从而允许捕捉静止图像。
在箭头Q62所示的示例中,如箭头Q63所示,选择“吠叫”,作为触发,在狗吠叫“哇哇”被检测为作为狗的声像对象OB62的分离声音的时刻,捕捉静止图像。
例如,如果检测到声像对象,则可以在特定对象发出特定声音(例如,狗叫)时执行快门操作。特别地,即使在相同方向上存在多个声源的情况下,或者存在多个相同类型的声源的情况下,也可以准确地识别特定对象发出特定声音的定时。
(计算机的配置示例)
顺便提及,上述一系列处理可以由硬件执行,也可以由软件执行。在一系列处理由软件执行的情况下,构成软件的程序安装在计算机中。在此处,计算机包括包含在专用硬件中的计算机、例如能够通过安装各种程序来执行各种功能的通用个人计算机等。
图12是示出通过程序执行上述一系列处理的计算机的硬件的配置示例的框图。
在计算机中,中央处理器(CPU)501、只读存储器(ROM)502和随机存取存储器(RAM)503经由总线504互连。
输入-输出接口505进一步连接到总线504。输入单元506、输出单元507、记录单元508、通信单元509和驱动器510连接到输入-输出接口505。
输入单元506包括键盘、鼠标、麦克风、成像元件等。输出单元507包括显示器、扬声器等。记录单元508包括硬盘、非易失性存储器等。通信单元509包括网络接口等。驱动器510驱动可移动记录介质511,例如,磁盘、光盘、磁光盘或半导体存储器。
在如上所述配置的计算机中,CPU 501经由输入-输出接口505和总线504将例如记录在记录单元508中的程序加载到RAM 503中,并执行该程序,以便执行上述一系列处理。
可以通过记录在例如作为封装介质等的可移动记录介质511上来提供由计算机(CPU 501)执行的程序。此外,可以经由有线或无线传输介质,例如,局域网、互联网或数字卫星广播,来提供程序。
在计算机中,通过将可移动记录介质511安装到驱动器510,程序可以经由输入-输出接口505安装在记录单元508中。此外,程序可以由通信单元509经由有线或无线传输介质接收,并安装在记录单元508中。另外,程序可以预先安装在ROM 502或记录单元508中。
注意,由计算机执行的程序可以是用于以本说明书中描述的顺序按时间序列进行处理的程序,或者是用于并行处理或者在必要时间(例如,进行调用时)进行处理的程序。
此外,本技术的实施例不限于上述实施例,并且在不脱离本技术的范围的情况下,各种修改是可能的。
例如,本技术可以采用云计算的配置,其中,一个功能由多个装置经由网络共享并共同处理。
此外,上述流程图中描述的每个步骤可以由一个装置执行,或者可以由多个装置以共享方式执行。
此外,在一个步骤中包括多个处理的情况下,除了由一个装置执行之外,还可以由多个装置以共享方式执行一个步骤中包括的多个处理。
此外,本技术还可以具有以下配置。
(1)一种信息处理装置,包括:
图像对象检测单元,基于带有声音的运动图像来检测图像对象;
声音对象检测单元,基于所述带有声音的运动图像来检测声音对象;以及
声像对象检测单元,基于所述图像对象的检测结果和所述声音对象的检测结果来检测声像对象。
(2)根据(1)所述的信息处理装置,其中,
所述声像对象检测单元输出被检测的所述声像对象的图像区域信息和包括分离的声音的声像对象信息。
(3)根据(1)或(2)所述的信息处理装置,其中,
所述声像对象检测单元通过将所述图像对象与所述声音对象相关联来检测所述声像对象。
(4)根据(1)至(3)中任一项所述的信息处理装置,其中,
所述声像对象检测单元基于所述图像对象和所述声音对象的同现概率来检测所述声像对象。
(5)根据(1)至(4)中任一项所述的信息处理装置,其中,
所述声像对象检测单元基于所述图像对象的位置信息和所述声音对象的位置信息来检测所述声像对象。
(6)根据(1)至(5)中任一项所述的信息处理装置,其中,
所述图像对象检测单元基于构成所述带有声音的运动图像的运动图像和以下各项中的至少一项来检测所述图像对象:构成所述带有声音的运动图像的声音、来自构成所述带有声音的运动图像的声音的声学事件的检测结果、所述声音对象的检测结果。
(7)根据(1)至(6)中任一项所述的信息处理装置,其中,
所述声音对象检测单元基于构成所述带有声音的运动图像的声音和以下各项中的至少一项来检测所述声音对象:构成所述带有声音的运动图像的运动图像、对所述构成所述带有声音的运动图像的运动图像的图像物体识别结果、所述图像对象的检测结果。
(8)根据(1)至(7)中任一项所述的信息处理装置,其中,
基于多个所述声音对象的同现概率、声源位置、图像物体位置以及所述声音对象的类型中的至少一者,所述声音对象检测单元缩减作为检测目标的所述声音对象。
(9)根据(1)至(8)中任一项所述的信息处理装置,其中,
所述声音对象检测单元通过检测声学事件来检测所述声音对象。
(10)根据(1)至(9)中任一项所述的信息处理装置,其中,
所述声音对象检测单元通过声源分离来检测所述声音对象。
(11)根据(1)至(10)中任一项所述的信息处理装置,还包括
声像对象选择单元,从检测到的多个所述声像对象中选择一个或多个所述声像对象。
(12)根据(11)所述的信息处理装置,还包括
处理单元,根据所述声像对象选择单元对所述声像对象的选择结果来执行处理。
(13)根据(12)所述的信息处理装置,其中,
作为根据所述选择结果的处理,所述处理单元执行:
对从所述带有声音的运动图像中选择的所述声像对象的缩放处理,
对从所述带有声音的运动图像中选择的所述声像对象的聚焦处理,
对从所述带有声音的运动图像中选择的所述声像对象的移除处理,
对所选择的所述声像对象的通知处理,
对所选择的所述声像对象的搜索处理,或
基于所选择的所述声像对象的快门操作控制处理。
(14)一种信息处理方法,包括通过信息处理装置:
基于带有声音的运动图像来检测图像对象;
基于所述带有声音的运动图像来检测声音对象;并且
基于所述图像对象的检测结果和所述声音对象的检测结果来检测声像对象。
(15)一种使计算机执行处理的程序,所述处理包括以下步骤:
基于带有声音的运动图像来检测图像对象;
基于所述带有声音的运动图像来检测声音对象;并且
基于所述图像对象的检测结果和所述声音对象的检测结果来检测声像对象。
附图标记列表
11 再现装置
21 声像对象提取单元
22 声像对象选择单元
23 运动图像处理单元
24 输入单元
26 显示图像生成单元
51 图像对象检测器
52 声音对象检测器
53 声像对象检测器。
- 信息处理装置、信息处理装置控制方法、信息处理装置控制程序以及记录了信息处理装置控制程序的计算机可读取的记录介质
- 信息处理装置、信息处理装置控制方法、信息处理装置控制程序和记录有信息处理装置控制程序的记录介质