一种基于注意力模块的图像质量评价方法
文献发布时间:2023-06-19 10:32:14
技术领域
本发明涉及图像质量处理技术领域,尤其涉及一种基于注意力模块的图像质量评价方法。
背景技术
随着捕获图像设备数量和图像数据量的增长,现实中随处可见各类图像处理和传输的应用。然而,数字图像在传输、压缩过程中会遭受各种各样的噪声影响而失真,这些失真会使得图像的质量下降;在实际应用场景中,我们可能只需要特定质量范围的图片,因此,如何评估图像的质量便成为了一个关键的问题。图像质量评价不仅可以在快速传输的图像流中发挥作用,也可以在监视器等场景中使用。同时,图像质量评价(Image QualityAssessment,IQA)可以为图像的超分辨率重建、去噪、去雾以及压缩等领域提供可靠依据。利用人力评估图像质量不仅耗时耗力而且会带有主观随意性,于是预测一幅图像的客观评估分数便是图像质量评价的主要任务。
根据参考图像是否存在,图像质量评价可以分为全参考(Full reference,FR)评价、半参考(Reduced reference,RR)评价和无参考(No reference,NR)评价,其中以全参考图像质量评价方法最为成熟,也得到了广泛的应用。但是,在实际应用中,参考图像的信息往往难以获取,全参考和半参考图像质量评价有较大局限性。与此相对的是,无参考图像质量评价由于不需要参考图像,因此有着最广泛的应用前景和最大的实用价值。
近年来,随着深度学习和神经网络的再一次兴起,NR-IQA的方法也取得一定突破和进展。简单迁移传统的分类网络使其适应于NR-IQA任务的方法最先得到应用;同时加深网络深度以提高其性能的方法也得到了学者的重视;基于排序的方法在NR-IQA任务中取得了突破性的进展,与IQA任务联系最紧密,并且取得了比较好的效果。如今,比较流行的无参考图像质量评估算法有BRISQUEP、CNN、SOM、BIECON等,然而在多数NR-IQA算法中,网络深度太深,提取了很多冗余信息,由于使用的IQA数据库样本量不足,很容易产生过拟合,并且,很容易将图片的部分特征的信息赋予过多的权重,导致图像质量评价不够准确。
因此,本发明引入空间和通道混合注意力模块,对特定特征进行注意力增强;并利用两个网络提取多尺度的图像特征,采用两种融合方式对网络的输出做混合处理,在保留关键特征的基础上,减少了参数的冗余,使得在网络层数不加深的情况下,也能达到深层网络的效果;同时我们采用多个数据库来对网络参数进行训练,以进一步提高客观评价与主观评价的一致性,提高图像质量评价的准确度。
发明内容
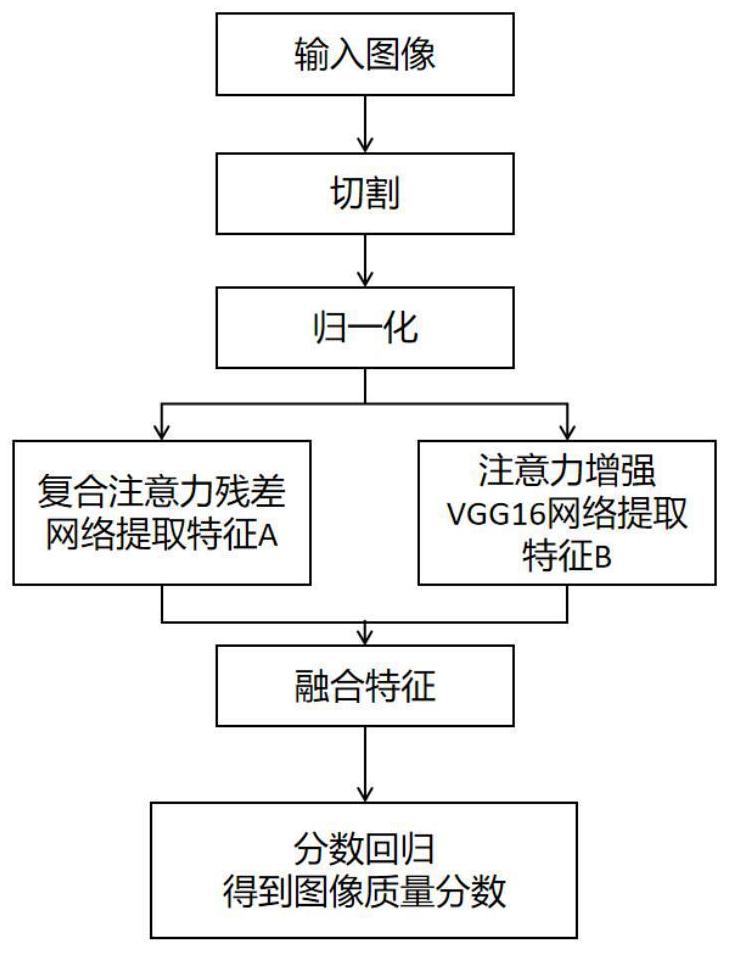
本发明提出了一种基于注意力模块的图像质量评价方法,属于图像质量处理技术领域。该方法利用双分支卷积神经网络建立回归网络模型,通过复合注意力残差网络(compound Attention Model-Based ResNet)和注意力增强VGG16网络(Attention Model-Based VGG16)提取特征。采用特征融合网络将两个网络提取的特征进行融合,利用全连接层结合激活函数ReLU将融合特征回归到分数指标。将待评价图像输入训练好的回归网络模型中,得到最终的图像质量评分。
本发明的上述技术问题主要是通过下述技术方案得以解决的:
一种基于注意力模块的图像质量评价方法,具体步骤如下:
步骤1:将训练集中每张原始图像裁剪成多个n×n大小的子图像,并对每一张子图像依次进行归一化处理得到归一化之后的子图像,通过人工评分得到原始图像的质量分数目标值;
步骤2:利用双分支卷积神经网络建立回归网络模型,将步骤1归一化之后的每一张子图像依次输入回归网络模型中,得到原始图像的质量分数预测值,通过原始图像的质量分数预测值与原始图像的质量分数目标值构建损失函数,利用损失函数对双分支卷积神经网络建立回归网络模型进行优化训练,得到训练后的双分支卷积神经网络,建立回归网络模型;
步骤3:将待评价图像经过步骤1处理后得到待评价图像的多张子图像,将待评价图像的多张子图像依次输入训练后的双分支卷积神经网络建立的回归网络模型中,最终得到待评价图像的质量评分。
作为优选,步骤1所述将原始图像裁剪为n×n个子图像,具体为:
以训练集中的第k张原始图像p
第k张原始图像中第i行第j列的子图像定义为:p
从原点开始,连续不重叠截取n×n像素大小的区域作为子图像,p
(i·n,j·n),((i+1)·n,j·n),((i+1)·n,(j+1)·n),(i·n,(j+1)·n);
其中,
若原始图像有剩余未裁剪部分,则让裁剪区域与图像边界线齐平,向图像内侧取n×n大小区域;
若
(X
若
(i·n,Y
若
(X
所述步骤S1中子图像经归一化具体为:
用1/9[111;111;111]对p
对子图像p
用1/9[111;111;111]对p
对p
计算第k张原始图像中第i行第j列的子图像的方差三阶张量为:
p
找出方差三阶张量p
得到第k张原始图像中第i行第j列的归一化之后的子图像为:
步骤1所述第k张图像的质量分数目标值为:y
作为优选,步骤2所述的双分支卷积神经网络由注意力残差网络、注意力增强VGG16网络、特征融合网络、全连接层组成。
所述注意力残差网络与所述注意力增强VGG16网络并行连接,进一步与特征融合网络、全连接层依次串行连接;
所述复合注意力残差网络由多个残差单元串联组成;
复合注意力残差网络的输入为第k张原始图像中第i行第j列的归一化之后的子图像p
第k张原始图像中第i行第j列的子图像的第l个残差单元的操作为:
第k张原始图像中第i行第j列的子图像的第l个残差单元的输入的三阶张量I
利用CBAM算法获得的通道和空间权重对特征f
利用PSA算法生成的注意力权重对第k张原始图像中第i行第j列的子图像的第l个残差单元的输入的三阶张量I
将F
其中,复合注意力残差网络第l个残差单元中每层卷积层的卷积核权重为待寻优参数,l∈[1,NUMA];NUMA为复合注意力残差网络中残差单元的数量;
所述注意力增强VGG16网络由一层卷积核大小为3×3的浅层卷积层与多个注意力增强单元串联组成;
注意力增强VGG16网络的输入为第k张原始图像中第i行第j列的归一化之后的子图像即p
p
第k张原始图像中第i行第j列的子图像的第r个注意力增强单元的定义为:
第k张原始图像中第i行第j列的子图像的第r个注意力增强单元输入的三阶张量即I
将特征f′
利用CBAM算法获得的通道和空间权重对特征f′
其中,注意力增强VGG16网络第r个注意力增强单元中每层卷积层的卷积核权重为待寻优参数,r∈[1,NUMB];NUMB为注意力增强VGG16网络中注意力增强单元的数量;。
所述特征融合网络,对复合注意力残差网络提取的第k张原始图像中第i行第j列的子图像的图像特征
注意力增强VGG16网络提取的第k张原始图像中第i行第j列的子图像的图像特征f
利用Softmax函数对f
将f
b
将f
将x
将矩阵c
对向量x
对向量y
将z
其中,M为复合注意力残差网络提取的图像特征的尺寸,N为注意力增强VGG16网络提取的图像特征的尺寸,T为图像特征的通道数。
其中,将第k张原始图像中第i行第j列的子图像经融合后的最终的特征向量z
其中,全连接层的卷积核的权重需经过学习不断更新迭代以达到最优值;
步骤2所述的损失函数为:
在这其中,f(x
步骤2所述利用损失函数对双分支卷积神经网络建立回归网络模型进行优化训练为:使用Adam算法作为优化函数来更新网络参数;
其中,θ
其中,本发明中复合注意力残差网络和注意力增强VGG16网络的每一层的每一个卷积核的权重,以及全连接层的卷积核的权重均为需要更新的网络参数。
本发明的有益效果为:
本发明提出了一种基于注意力模块的图像质量评价方法。该方法利用双分支卷积神经网络建立回归网络模型,通过复合注意力残差网络和注意力增强VGG16网络提取特征,使得经典网络在层数不加深的情况下就能够取得深层网络才能达到的结果,甚至超越一些深层网络的方法,网络的泛化能力也有所提高。引入混合的注意力模块嵌入方式,使得网络在空间和通道上的抗噪声干扰能力得到提高,保证了网络结构的稳定性。利用两个网络提取多尺度的图像特征,利用两个网络做同一任务,可以有效地提取多种特征,并且通过实验验证了我们方法的有效性。采用不同的融合方式,对于网络的输出做混合处理,在保留关键特征的基础上,减少了参数的冗余。
附图说明
图1是本发明方法事宜图
图2是基于注意力模块的残差块模块
图3是注意力增强VGG16网络
图4是融合方式示意图
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
如图1所示,本发明提出的基于注意力模块的图像评价,包含以下步骤:
本实施例使用一块NVIDIA Tesla V100作为GPU加速器进行训练。对于原始的图片切分为224x224的子块后作为网络的输入,并且设置步幅为224,批量数为32,使用Adam算法(adaptive moment estimation optimizer)作为优化函数,设置β=0.9,初始学习率为1e
本发明方法示意图,如图1所示,首先,利用双分支卷积神经网络建立回归网络模型,通过复合注意力残差网络和注意力增强VGG16网络提取特征。其次,利用特征融合网络将两个网络提取的特征进行融合。然后,利用全连接层结合激活函数ReLU将融合特征回归到分数指标。最后,将待评价图像输入训练好的回归网络模型中,得到最终的图像质量评分。
一种基于注意力模块的图像质量评价方法,具体步骤如下:
步骤1:将训练集中每张原始图像裁剪成多个n×n大小的子图像,并对每一张子图像依次进行归一化处理得到归一化之后的子图像,通过人工评分得到原始图像的质量分数目标值;
所述步骤1中将原始图像裁剪为n×n个子图像,具体为:
以训练集中的第k张原始图像p
第k张原始图像中第i行第j列的子图像定义为:p
从原点开始,连续不重叠截取n×n像素大小的区域作为子图像,p
(i·n,j·n),((i+1)·n,j·n),((i+1)·n,(j+1)·n),(i·n,(j+1)·n);
其中,
若原始图像有剩余未裁剪部分,则让裁剪区域与图像边界线齐平,向图像内侧取n×n大小区域;
若
(X
若
(i·n,Y
若
(X
所述步骤S1中子图像经归一化具体为:
用1/9[1 1 1;1 1 1;1 1 1]对p
对子图像p
用1/9[1 1 1;1 1 1;1 1 1]对p
对p
计算第k张原始图像中第i行第j列的子图像的方差三阶张量为:
p
找出方差三阶张量p
得到第k张原始图像中第i行第j列的归一化之后的子图像为:
步骤1所述第k张图像的质量分数目标值为:y
步骤2:利用双分支卷积神经网络建立回归网络模型,将步骤1归一化之后的每一张子图像依次输入回归网络模型中,得到原始图像的质量分数预测值,通过原始图像的质量分数预测值与原始图像的质量分数目标值构建损失函数,利用损失函数对双分支卷积神经网络建立回归网络模型进行优化训练,得到训练后的双分支卷积神经网络,建立回归网络模型;
步骤2所述的双分支卷积神经网络由注意力残差网络、注意力增强VGG16网络、特征融合网络、全连接层组成。
所述注意力残差网络与所述注意力增强VGG16网络并行连接,进一步与特征融合网络、全连接层依次串行连接;
所述复合注意力残差网络由多个残差单元串联组成;如图2所示,本实施例中所述复合注意力残差网络由多个个残差单元串联组成;
复合注意力残差网络的输入为第k张原始图像中第i行第j列的归一化之后的子图像p
第k张原始图像中第i行第j列的子图像的第l个残差单元的操作为:
第k张原始图像中第i行第j列的子图像的第l个残差单元的输入的三阶张量I
利用CBAM算法获得的通道和空间权重对特征f
利用PSA算法生成的注意力权重对第k张原始图像中第i行第j列的子图像的第l个残差单元的输入的三阶张量I
将F
其中,复合注意力残差网络第l个残差单元中每层卷积层的卷积核权重为待寻优参数,l∈[1,NUMA];NUMA为复合注意力残差网络中残差单元的数量;
其中,
所述注意力增强VGG16网络由一层卷积核大小为3×3的浅层卷积层与多个注意力增强单元串联组成;
如图3所示,本实施例中注意力增强VGG16网络由一层卷积核大小为3×3的浅层卷积层与多个注意力增强单元串联组成;
注意力增强VGG16网络的输入为第k张原始图像中第i行第j列的归一化之后的子图像即p
p
第k张原始图像中第i行第j列的子图像的第r个注意力增强单元的定义为:
第k张原始图像中第i行第j列的子图像的第r个注意力增强单元输入的三阶张量即I
将特征f′
利用CBAM算法获得的通道和空间权重对特征f′
其中,注意力增强VGG16网络第r个注意力增强单元中每层卷积层的卷积核权重为待寻优参数,r∈[1,NUMB];NUMB为注意力增强VGG16网络中注意力增强单元的数量;
其中,
如图4所示,所述特征融合网络,对复合注意力残差网络提取的第k张原始图像中第i行第j列的子图像的图像特征
注意力增强VGG16网络提取的第k张原始图像中第i行第j列的子图像的图像特征f
利用Softmax函数对f
将f
b
将f
将x
将矩阵c
对向量x
对向量y
将z
其中,M为复合注意力残差网络提取的图像特征的尺寸,N为注意力增强VGG16网络提取的图像特征的尺寸,T为图像特征的通道数。
其中,将第k张原始图像中第i行第j列的子图像经融合后的最终的特征向量z
其中,全连接层的卷积核的权重需经过学习不断更新迭代以达到最优值;
步骤2所述的损失函数为:
在这其中,f(x
步骤2所述利用损失函数对双分支卷积神经网络建立回归网络模型进行优化训练为:使用Adam算法作为优化函数来更新网络参数;
其中,θ
其中,本发明中复合注意力残差网络和注意力增强VGG16网络的每一层的每一个卷积核的权重,以及全连接层的卷积核的权重均为需要更新的网络参数。
步骤3:将待评价图像经过步骤1处理后得到待评价图像的多张子图像,将待评价图像的多张子图像依次输入训练后的双分支卷积神经网络建立的回归网络模型中,最终得到待评价图像的质量评分。
性能比较如下:
实验数据库包括LIVE,CSIQ,TID2013以及LIVE Challenge数据库。其中LIVEChallenge数据库有982张失真图片包括五种类型的失真:白高斯噪声,高斯模糊,JPEG,JPEG2000以及快衰落失真。每张图片都和DMOS相关联,DMOS的取值在[0-100]。CSIQ数据库包括30张原始图片和866张失真图片,包括6种失真类型,每一种失真类行都有4-5个等级的失真程度。CSIQ的DMOS的范围在归一化后在[0,1]之间。TID2013有25张参考图片,24种失真类型,每个失真类型包括5个不同的失真等级,TID2013的MOS分布在[0,9]之间。由于TID2013的数据库的复杂度和失真类型的多样性,目前已经成为最具挑战性的数据库之一。LIVE Challenge数据库不包含参考图片,是针对无参考任务所推出的数据库,不同于上述数据库中图片失真是人为添加的,LIVE Challenge中的图片是自然情况下的失真图片,因此在该数据库上取得良好的指标更有益于对于现实任务的指导。
为了评估模型性能,实验中采用几种常用的相关参数。这几种标准包括皮尔逊相关系数(Pearson Linear Correlation Coefficient,PLCC),斯皮尔曼等级相关系数(Spearman Rank Order Correlation Coefficient,SRCC)以及肯德尔等级相关系数(Kendall rank-order correlation coefficient,KROCC)。对于每一种相关参数,分数越高表明模型的效果越好。在实际应用过程中,将TID2013中的MOS,CISQ和LIVE数据库中DMOS归一化到[0,1]进行评估。
表1模型在五个数据库上训练的性能指标
表2在LIVE数据库上的训练测试对的实验和不同方法进行对比
从表2中可以看出,在实际测试中,本算法的表现优于BRISQUE、CNN等算法,充分说明了本算法的优异性能。
在跨数据库的测试中,训练集仍然为被作为训练集的80%的图片,测试集则是被选为测试集的全部图片,其中TID2013(部分)表示TID2013中和LIVE以及CSIQ中存在相同失真类型的图片。
表3在LIVE2016数据库上的训练
表4在CSIQ数据库上的训练
表5在TID2013数据库上的训练
应当理解的是,本说明书未详细阐述的部分均属于现有技术。
应当理解的是,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 一种基于注意力模块的图像质量评价方法
- 一种基于三维视觉注意力的立体图像质量客观评价方法