云平台下基于粗糙超立方体的大规模特征选择方法
文献发布时间:2023-06-19 10:41:48
技术领域
本发明涉及大规模数据特征选择技术领域,具体涉及一种云平台下基于粗糙超立方体的大规模特征选择方法。
背景技术
由于计算机与互联网技术的快速发展,在军事、金融、通讯等行业,数据量的生成速度和存储规模正以前所未有的态势不断增长。与此同时,数据的形式也不再局限于离散特征,更多的是连续型特征,特别是能源、气象、遥感等领域的数据。高维度的数据不仅会增加计算的复杂度,还很容易造成机器学习算法出现过拟合的现象,从而影响其学习性能。而特征选择能够在保证学习模型性能稳定的同时,为数据分析确定相关特征并尽可能多地剔除冗余特征,这也是其在模式识别、机器学习等领域广受欢迎的主要原因。
云计算作为分布式计算的一种,突破了单台计算机资源不足的限制,通过构建计算机集群为大规模数据计算提供了良好的解决方案。所以目前处理连续型大规模特征选择问题的常用方法有:1)先对数据集中连续型特征离散化,离散方法有等距离散、等频离散和优化离散等,再结合云平台,运用分布式计算技术和Pawlak粗糙集模型对离散后的数据进行特征选择。虽然Pawlak粗糙集模型中的等价关系非常适用于分布式计算,但是数据离散化的过程会造成信息丢失,从而影响选择特征的质量。2)选择适用于连续型特征的粗糙集模型,主要有邻域粗糙集和模糊粗糙集,再通过哈希方法等将其并行化实现,以适用云计算范例。这种方法虽然避免了离散化数据造成的信息丢失,但因为模型本身的限制,即邻域关系和相似矩阵的计算涉及全局交流的问题,仍然无法高效地处理连续型大数据特征选择问题。
发明内容
针对现有技术中的上述不足,本发明提供的一种云平台下基于粗糙超立方体的大规模特征选择方法解决了云平台下处理连续型大数据特征选择的问题。
为了达到上述发明目的,本发明采用的技术方案为:一种云平台下基于粗糙超立方体的大规模特征选择方法,包括以下步骤:
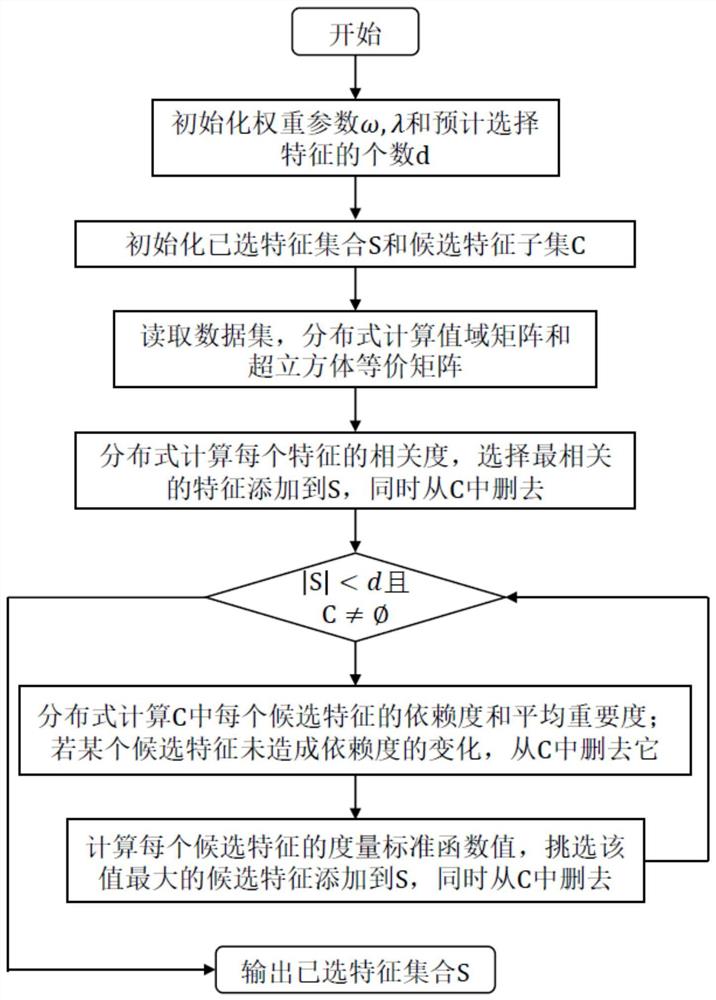
S1、初始化权重参数ω、λ和预计选择特征的个数d;
S2、初始化已选特征集合S和候选特征子集C;
S3、读取数据集,通过云平台以数据并行地方式分布式计算值域矩阵,再根据值域矩阵分布式计算由特征的超立方等价划分矩阵分解、重构后得到的超立方体等价划分矩阵;
S4、基于分解重构的超立方体等价划分矩阵再以数据并行的方式分布式计算每一个特征与决策属性之间的相关度,选择最相关的特征添加到已选特征集合S中,并从候选特征子集C中删去该特征;
S5、当|S| S6、通过云平台上数据并行地方式,基于分解重构的超立方体等价划分矩阵,并结合缓存-更新-过滤机制的加速方法,分布式计算每一个候选特征对于已选特征集合S的依赖度和平均重要度,若添加某个候选特征到已选特征集合S后,依赖度没有变化,则从候选特征子集C中删除该候选特征; S7、根据权重参数ω、λ计算每个候选特征的度量标准函数值,挑选该值最大的候选特征添加到已选特征集合S,并从候选特征子集C中删去该特征。 进一步地:所述步骤S3中的值域矩阵计算方法为:给定一个决策表 进一步地:所述步骤S3中分解重构的超立方体等价划分矩阵为:
上式中,H(A 进一步地:所述步骤S4中相关度J
上式中,混淆向量值 进一步地:所述步骤S6中依赖度J
上式中, 所述平均重要度J
上式中, 进一步地:所述步骤S6中依赖度的缓存-更新-过滤方法为:把第s次特征选择过程中计算得到的H(S-{A 其中,子集U H(S∪{A 特征集合S∪{A
所述平均重要度的缓存-更新-过滤方法为:在第s次特征选择过程中,将特征A 其中,特征A
进一步地:所述步骤S7中每个候选特征的度量标准函数值J(A J(A (1-ω)(1-λ)J 本发明的有益效果为:本发明结合云平台分布式计算的特点和粗糙超立方体在处理连续型数据上的优势,从而解决了海量连续性数据,例如能源、气候等大型数据集的特征选择问题,可应用到模式识别和机器学习相关领域中。本发明主要提出了面向云平台的超立方体等价划分矩阵的表示方法和特征度量标准,设计一种缓存-更新-过滤的加速机制以及提出了一种云平台下基于粗糙超立方体的大数据特征选择方法。本发明所公开的大数据特征选择方法在保证特征选择质量,剔除冗余特征的同时,不仅能够高效地处理海量连续性数据,而且面对不同规模的集群和数据量,均表现出良好的可扩展性和可伸缩性。 附图说明 图1为本发明流程图。 具体实施方式 下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。 本发明是在对粗糙超立方体模型基本原理与运用的研究基础上,结合云平台分布式计算的特点,重点研究了粗糙超立方体模型适用于分布式环境的表示方法,基于该表示方法的特征度量标准,提出了缓存-更新-过滤机制的加速方法以及基于粗糙超立方体的大数据特征选择方法,旨在提供一种云平台下处理连续型大数据特征选择问题的解决方法。本发明主要体现在以下四个方面: 1、面向云平台的粗糙超立方体模型的表示方法 粗糙超立方体模型充分利用样本的类别信息,以监督学习的方式进行造粒,粒度信息由特征的超立方体等价划分矩阵表示。这种造粒机制和等价矩阵的表示方法使得粗糙超立方体模型无论在特征选择的质量上还是效率上都要优于Pawlak粗糙集、邻域粗糙集和模糊粗糙集模型。但是特征的超立方体等价划分矩阵的表示形式仍然涉及到样本空间中全局交流的问题,并不适合在云平台下直接构建。本发明针对这一问题,对特征的表示矩阵进行分解和重构,提出了新的基于对象或样本子集的超立方体等价划分矩阵的表示方法。新的表示方法的创新点在于避免了全局交流问题,允许样本或子集的超立方体等价划分矩阵在云平台各节点或各数据分块上并行独立地计算,完美地契合了云平台“分而治之”的思想,从而有效地提高了云平台下处理大数据的效率。 2、基于分解重构的超立方体等价划分矩阵的特征度量标准 特征的度量标准是决定特征选择质量的关键。粗糙超立方体模型在特征的超立方体等价划分矩阵的基础上,提出了特征与决策属性之间的相关度,特征子集与决策属性之间的依赖度以及已选特征之间的属性重要度三种概念,通过赋予不同的权重综合考虑作为特征的度量标准。众所周知,云环境下要处理的大数据不仅样本数量较多而且样本维度也较高。而特征的超立方体等价划分矩阵不适用云平台,在这种情况下,本发明选择以分解重构后的超立方体等价划分矩阵作为基础,进而提出了分布式环境下特征度量标准(相关度、依赖度和属性重要度)的并行化计算方法,该方法降低了大数据特征评估过程的复杂度。 3、提出了一种缓存-更新-过滤机制的加速方法 大数据环境下,针对迭代式的计算过程,云平台提供了数据持久化方法,可以将中间数据缓存到集群的内存或磁盘中,如Spark范例中的persist算子,以减少重复计算提高大数据处理速度。本发明深入剖析了迭代式特征选择过程中依赖度和属性重要度的计算过程,结合云平台提供的持久化方法,提出了一种缓存-更新-过滤的加速机制,从而加快了大数据特征选择的过程,并且随着特征选择的进行,每次选择特征的速度会越来越快。 4、基于粗糙超立方体的大数据特征选择方法 上述云平台下大数据选择方法,提出面向云平台的粗糙超立方体表示方法具体包括:本发明结合云平台分布式计算的特点,对特征的超立方体等价划分矩阵进行了分解和重构,提出了两种基于样本或子集的超立方体等价划分矩阵的表示方法。该步骤有以下分步骤: 如图1所示,一种云平台下基于粗糙超立方体的大规模特征选择方法,包括以下步骤: S1、初始化权重参数ω、λ和预计选择特征的个数d; S2、初始化已选特征集合S和候选特征子集C; S3、读取数据集,并通过云平台上数据并行地方式计算值域矩阵,根据值域矩阵对特征的粗糙超立方矩阵进行分解、重构,得到超立方体等价划分矩阵; 值域矩阵计算方法为:给定一个决策表 本实施例假设大数据集保存在Hadoop平台上的分布式文件系统HDFS。首先读取数据集的HDFS文件到Spark集群上,再聚合每种决策类别下的样本在每个特征下面的所有特征值,比较得出最小值和最大值,即值域矩阵。最后将值域矩阵数据收集到Driver节点转化成二维数组并广播到集群的每一个计算节点。这个过程依次是flatMap、reduceByKey、collect和broadcast。 超立方体等价划分矩阵为:
上式中,H(A S4、基于超立方体等价划分矩阵以数据并行的方式计算每一个特征与决策属性之间的相关度,选择最相关的特征添加到已选特征集合S中,并从候选特征子集C中删去该特征; 基于超立方体等价划分矩阵H(A 其中, 相关度J
上式中,混淆向量值 分析可知,特征A S5、当|S| S6、通过云平台上数据并行地方式,基于超立方体等价划分矩阵,并结合缓存-更新-过滤机制的加速方法,计算每一个候选特征对于已选特征集合S的依赖度和平均重要度,若添加某个候选特征到已选特征集合S后,依赖度没有变化,则从候选特征子集C中删除该候选特征; 依赖度J
上式中, 所述平均重要度J
上式中, 依赖度的缓存-更新-过滤方法为:把第s次特征选择过程中计算得到的H(S-{A 给定已选特征集合S,A H(S∪{A 特征集合S∪{A
所述平均重要度的缓存-更新-过滤方法为:在第s次特征选择过程中,将特征A 给定已选特征集合S,A
基于以上缓存数据,计算每个候选特征相对于已选特征集合S的依赖度和平均重要度,再收集到Driver节点保存下来。这个过程依次是mapPartitions、persist、reduceByKey和collect。 S7、根据权重参数ω、λ计算每个候选特征的度量标准函数值,挑选该值最大的候选特征添加到已选特征集合S,并从候选特征子集C中删去该特征。 每个候选特征的度量标准函数值J(A J(A (1-ω)(1-λ)J 本发明公开了一种云平台下基于粗糙超立方体的大数据特征选择方法,结合云平台分布式计算的特点和粗糙超立方体在处理连续型数据上的优势,从而解决了海量连续性数据,例如能源、气候等大型数据集的特征选择问题,可应用到模式识别和机器学习相关领域中。本发明主要提出了面向云平台的超立方体等价划分矩阵的表示方法和特征度量标准,设计一种缓存-更新-过滤的加速机制以及提出了一种云平台下基于粗糙超立方体的大数据特征选择方法。本发明所公开的大数据特征选择方法在保证特征选择质量,剔除冗余特征的同时,不仅能够高效地处理海量连续性数据,而且面对不同规模的集群和数据量,均表现出良好的可扩展性和可伸缩性。
- 云平台下基于粗糙超立方体的大规模特征选择方法
- 一种基于粗糙集和群智能的特征选择方法