结构注释
文献发布时间:2023-06-19 10:44:55
技术领域
本公开涉及结构注释,诸如创建带注释的道路图像,可用于(尤其用于)训练机器学习对象的检测组件。
背景技术
一种快速发展的技术是自主驾驶车辆(AV),可在城市和其他道路上自行导航。这类车辆不仅须在人与其他车辆之间执行复杂的操纵,而且还须在频繁这样操纵的同时保证严格约束发生不良事件的概率(例如与环境中其他这些媒介发生碰撞)。为了允许AV安全地进行计划,至关重要的是,它能够准确可靠地观察其环境。这包括需要准确可靠地检测车辆附近的道路结构。
因此,在自主驾驶领域中,一种普遍的需求是具有结构检测组件(又称为机器视觉组件),当给定视觉输入时,该结构检测组件可确定现实世界的结构,诸如道路或车道结构,例如图像的哪一部分是路面,图像的哪一部分组成道路的车道,等等。
这通常通过使用卷积神经网络的机器学习来实现。这样的网络需要大量的训练图像。这些训练图像就像从自主驾驶车辆的相机中看到的图像一样,但它们已经注释有需要学习神经网络的信息。例如,这些图像将具有注释,该注释标记图像上的哪些像素是路面和/或图像上的哪些像素属于车道。在训练时,向网络呈现成数千或优选数十万个这样带注释的图像,并自行学习图像的哪些特征指示像素是路面还是车道部分。然后,在运行时,网络可使用先前从未见过的图像(即在训练过程中未曾见过的图像)自行进行此确定。
创建带注释的训练图像的常规技术是人工手动对图像进行注释。每个图像可能要花费数十分钟(因此需要耗费大量时间才能获得所需的大量图像)。使用这种手动过程创建数十万的训练图像需要大量的人工成本,这又导致其成为一项高成本的训练。实践中,它会限制实际提供训练图像的数量,这又可能不利于经训练的结构检测组件的性能。
自主驾驶车辆(又称为自动驾驶车辆)是指具有用于监视其外部环境的传感器系统以及能够使用这些传感器自动做出和实施驾驶决策的控制系统的车辆。这特别是包括基于来自传感器系统的输入来自动调适车辆的速度和行驶方向的能力。全自主驾驶或“无人驾驶”的车辆具有足够的决策能力,无需驾驶员的任何输入即可运行。然而,本文所用的术语“自主驾驶车辆”也适用于半自主驾驶车辆,其具有更强的自主决策能力,因此仍然要求驾驶员一定程度上的监督。
发明内容
本发明要解决的核心问题在于快速有效但仍然准确地注释道路图像,其中注释表示视觉道路结构。这样的图像例如可用于准备超大型带注释的道路图像的训练集,该训练集适合于训练卷积神经网络(CNN)或其他最新的机器学习(ML)结构检测组件。
本公开一方面涉及允许以半自动化的方式快速注释大量道路图像的技术。
该技术通过消除或至少大幅减少人工需求,允许比这样手动注释更有效又更快速地生成大量训练图像。
这种经训练的结构检测组件的性能强烈依赖于训练集的质量和大小。能够生成使用传统注释无法实际生成的大型准确注释的道路图像的训练集,这又意味着能够提高训练的结构检测组件应用于训练中未曾遇到的图像时(运行时)的准确度。
本发明第一方面提供一种对由至少一个行驶车辆捕捉的帧时间序列中的帧进行注释的方法,该方法包括在帧处理系统中:确定在帧时间序列中捕捉的区域的三维(3D)道路模型;接收表示帧时间序列的第一帧的移动对象的已知3D位置的第一注释数据;以及通过假设移动对象沿着根据已知3D位置和3D道路模型确定的预期路径移动,自动生成第二注释数据,用于在帧时间序列的至少第二帧中标记预期移动对象位置。
术语“帧”和“其他帧”可以分别与术语“第一帧”和“第二帧”互换使用。类似地,术语“注释数据”和“另外的注释数据”可以与“第一注释数据”和“第二注释数据”互换使用。术语“图像”和“帧”可以互换使用,并且在广义上用于涵盖任何2D或3D结构表示(包括点云、RGBD图像等)。术语“2D图像”可以用于具体指代例如RGB图像等。
本发明第二方面提供一种注释道路图像的方法,该方法包括以下在图像处理系统中实施的步骤:
接收由行驶车辆的图像捕捉装置捕捉的图像时间序列;
确定在图像时间序列中捕捉的区域的三维(3D)道路模型;
接收表示图像时间序列的至少一个图像中的移动对象的已知位置的注释数据;
通过假设移动对象沿着根据已知位置和3D道路模型确定的预期路径移动,自动生成另外的注释数据,用于在图像时间序列的至少另一个图像中标记预期移动对象位置。
本发明在基于3D道路模型注释2D图像的上下文中具备特殊优势。在此上下文中的高效性源于在3D空间中使用对象注释要素(例如长方体或其他3D体),然后将其几何投影回2D图像的各个图像平面中,以生成用于移动对象的2D注释数据。只要准确捕捉到对象注释要素的位置和移动,即可大幅减轻手动注释的负担。
为了考虑对象在图像之间的移动,在对象注释要素遵循3D道路模型的道路形状的假设下(即,使得预期路径与道路形状相匹配),可以在3D空间中移动对象注释要素。为此,针对至少一个图像,需要获知3D对象注释要素在3D空间中的位置。这可通过手动注释来建立(即,可以手动生成表示已知位置的注释数据),但在此情况下的问题在于,注释者只能使用单个2D视图,它对应于相关图像的2D图像平面。在此情况下的问题还在于,将3D注释要素置于3D空间中的自由度过高:3D注释要素可能置于3D空间中的多个位置,当投影回2D图像的图像平面时,所有这些位置都会看似正确,但由于尚未正确建立对象在3D空间中的实际起点,当对象注释要素在帧之间移动时会得到错误的结果。
这一问题可通过并入关于对象注释要素相对于道路模型路面的高程(可以在垂直于路面的方向上定义)的几何限制来克服。例如,针对移动的车辆,可以假设该移动的车辆在沿路径移动时始终坐落于路面上,例如,对象注释要素的一个或多个预定参考点(例如,长方体的四个底角)与路面之间的垂直隔距为零或基本为零。
以此方式,即使在2D图像的上下文中,注释者也可定义第一(3D)注释数据,该第一注释数据表示移动对象的已知3D位置(在3D空间中)。换而言之,基于3D道路模型施加的几何限制的优势在于,允许注释者相对于2D图像准确定位3D注释,这又允许针对另外的图像自动确定3D和2D注释。例如,可以通过将自动确定的3D注释投影到另外图像的各自图像平面中而确定2D注释。
换而言之,在本发明实施例中,通过假设移动对象沿着3D道路模型的路面中的预定高程(可以为零)处的预定路径移动,可以自动生成另外的注释数据。
下面阐述第一方面和第二方面更进一步的示例实施例。
可以针对其他图像生成另外的注释数据,这是通过将对象注释要素(例如长方体或其他3D体)从3D空间中的已知位置沿着预期路径移动到3D空间中的预期位置,并且将预期位置处的对象注释要素几何投影到其他图像的2D图像平面中。
已知位置和预期位置可以使得这两个位置处都保持距路面的预定高程。
响应于在图像处理系统的用户界面处接收到的注释输入,可以生成表示移动对象的已知位置的注释数据,其中,注释输入可以促使对象注释要素在保持距路面的预定高程的同时移动。换而言之,可以施加几何约束(限制),使得只能由注释者在道路平面中移动注释对象,从而始终保持预定高程。
通过将对象注释要素几何投影到图像的2D图像平面中,可以响应于注释输入而生成注释数据。注释数据可以随图像显示(例如,覆盖在图像上),并随着接收到注释输入进行更新,以便注释者能够基于2D投影而看到对象注释要素何时已正确定位,即,他能够看到何时已相对于图像准确建立已知位置(以及何处适用大小和形状正确的注释要素,等等)。内置的几何约束允许注释者仅使用2D投影到相关图像的图像平面中即可在3D空间中准确建立正确的已知位置。
优选地,预期道路模型是通过在捕捉图像时间序列的同时重构车辆行驶的路径而确定。亦即,3D道路模型可以展现出与重构的车辆路径的形状相对应的道路形状(即,预期道路形状可以是重构的车辆路径的形状)。
下面阐述更进一步的示例实施例。这些实施例是在第一方面的上下文中构架,但那些相同的特征也能应用于本文阐述的任何其他方面,除非另作注明。
帧可以为2D图像。
基于对已知3D位置相对于3D道路模型的路面的高程施加的几何限制,可以针对第一帧确定移动对象的3D位置。
几何限制可以将已知3D位置限制为相对于3D道路模型的路面预定的零高程或非零高程。
3D注释要素可以位于初始3D位置,可以将3D注释要素几何投影到第一帧的图像平面中,并且可以在保持所述几何限制的同时调整3D位置,以将3D注释要素的投影与第一帧中的移动对象相匹配,由此确定移动对象的已知3D位置。
可以在保持所述几何约束的同时手动调整3D位置,以手动将投影与图像平面中的移动对象相匹配。
第二注释数据可以是通过转换3D注释要素以使其沿着预期路径移动到3D空间中的预期移动对象位置而确定。
第二注释数据可以包括用于在第二帧的图像平面中标记预期移动对象位置的2D注释数据,该2D注释数据是通过将预期移动对象位置处的3D注释要素投影到第二帧的图像平面中而确定。
通过将已知3D位置处的3D注释要素投影到第一帧的图像平面中,可以针对第一帧确定第一2D注释数据。
预期路径可以是基于移动对象的速度以及第一帧与第二帧之间的时间间隔而确定。
可以假设该速度与行驶车辆的速度相匹配。
可以针对三分之一帧来确定移动对象的附加已知3D位置,并且基于第一帧与第三帧之间的时间间隔,可以使用已知3D位置和附加已知3D位置来估计速度。
预期道路模型可以是通过在捕捉图像时间序列的同时重构车辆行驶的路径而确定,3D道路模型展现出与重构的车辆路径的形状相对应的道路形状。
路径可以是通过处理帧时间序列而重构。
替选地或附加地,路径可以是根据与帧同时捕捉的卫星定位数据或其他传感器数据而确定。
移动对象的预期路径可以定义为在路面法线方向上相对于重构的车辆路径具有零垂直偏移。
移动车辆的预期路径可以定义为相对于重构的车辆路径具有固定横向偏移。
可以基于移动对象相对于3D道路模型的道路结构的位置来推断移动对象的移动方向-例如,可以使用其位置来推断它是否属于同一交通流(在同方向上移动)或即将来临的交通流(在反方向上移动)。
所述方法可以进一步包括:生成分类数据,用于基于帧中移动对象相对于3D道路模型的道路结构的位置来对帧进行分类。
分类帧可以用于验证机器学习模型。
替选地或附加地,带注释的帧可以用于在监督训练过程中训练机器学习模型。
与帧时间序列相关联地捕捉的位置数据可以用于将帧时间序列与地图区域相匹配,以便确定3D道路模型的道路形状。
第二注释数据可以采取位于3D空间中预期移动对象位置的3D注释要素的形式。
作为2D图像的替选,帧可以为3D帧。所有上述公开皆等同适用于这样的帧,除非另作注明。本文对2D图像的全部描述皆等同适用于其他类型的帧,除非上下文另作要求。
每个3D帧可以包括深度图和点云中的至少一个。
3D注释要素可以为3D边界框。替选地,3D注释要素可以为3D模型。
3D模型可以是从一个或多个3D帧导出。
下面阐述在第二方面的上下文中架构的更进一步的示例实施例。然而,该教导等同适用于本文阐述的任何其他方面或实施例。
第二注释可以包括2D注释数据,该2D注释数据是通过将对象注释要素从3D空间中的已知位置沿着预期路径移动到3D空间中的预期位置并且将预期位置处的对象注释要素几何投影到第二帧的二维图像平面而生成。
已知位置和预期位置可以使得这两个位置处都保持距路面的预定零高程或非零高程。
响应于在图像处理系统的用户界面处接收到的注释输入,可以生成表示移动对象的已知位置的注释数据,其中,注释输入可以促使对象注释要素在保持距路面的预定高程的同时移动。
通过将对象注释要素几何投影到图像的2D图像平面中,可以响应于注释输入生成注释数据。
注释数据可以叠加在图像上或以其他方式随图像显示,并在接收到注释输入时进行更新,以便注释者能够基于随图像显示的2D注释要素的投影而看到何时正确定位对象注释要素。
注释数据可以是响应于在图像处理系统的用户界面处接收到的注释输入而生成。
另外的注释数据可以是根据移动对象沿着预期路径的预期速度而生成。
可以假设移动对象的预期速度与行驶车辆的速度相匹配。
注释数据可以表示移动对象在至少两个图像中的各自已知位置,并且移动对象的预期速度可以是基于其而确定。
针对序列中两个图像之间的图像,可以基于预期速度沿着预期路径内插移动对象位置,以针对这些图像生成另外的注释数据。
上述内容等同适用于2D图像以外的帧,除非上下文另作要求。
路径可以是通过处理图像时间系列(序列)而重构。
移动对象的预期路径可以定义为在路面法线方向上相对于重构的车辆路径具有零垂直偏移。
路面法线可以通过处理图像时间序列而确定。
移动车辆的预期路径可以定义为相对于重构的车辆路径具有固定横向偏移。
注释数据可以是响应于在图像处理系统的用户界面处接收到的注释输入而生成。
另外的注释数据可以是根据移动对象沿着预期路径的预期速度而生成。
可以假设移动对象的预期速度与行驶车辆的速度相匹配。
替选地,注释数据可以表示移动对象在至少两个图像中的各自已知位置,并且移动对象的预期速度可以是基于其而确定。在此情形下,至少两个图像可各自如上所述那样手动注释。
针对序列中两个图像之间的图像,可以基于预期速度沿着预期路径内插移动对象位置,以针对这些图像生成另外的注释数据。
可以基于移动对象相对于3D道路模型的道路结构的位置来推断移动对象的移动方向。
所述方法可以进一步包括:生成分类数据,用于基于图像中移动对象相对于3D道路模型的道路结构的位置来对图像进行分类。如稍后所述,分类图像可以例如用作M1验证的基础。
还应指出,尽管可使用重构的车辆路径来推断预期道路形状,但预期道路形状的知识可来自任何来源。例如,与图像时间序列相关联地捕捉的位置数据可以用于将图像时间系列与地图(诸如HD地图)的区域相匹配,以便从地图中确定预期道路形状。一般而言,可假设移动对象的预期路径与预期道路形状相匹配,但可获得该知识。
对象检测可采取各种形式,诸如边界框检测、有关对象类别的图像分割等。应当领会,在ML训练的上下文中,要学习的对象检测的形式决定了要为训练图像生成的注释数据的形式。
本发明另一方面提供一种注释道路图像的方法,该方法包括以下在图像处理系统中实施的步骤:
接收由行驶车辆的图像捕捉装置捕捉的图像时间序列;
处理图像以在三维空间中重构车辆行驶的路径;
接收表示图像时间序列的至少一个图像中的移动对象的已知位置的注释数据;
通过假设移动对象沿着根据已知路径和重构的车辆路径来确定的预期路径移动,使用已知位置和重构的车辆路径来自动生成另外的注释数据,用于在图像时间序列的至少另一个图像中标记移动对象的预期位置。
道路图像可以为街景图像。
本发明又一方面提供一种对由至少一个行驶车辆捕捉的帧时间序列中的帧进行注释的方法,该方法包括在帧处理系统中:确定在帧时间序列中捕捉的区域的三维(3D)道路模型;以及生成用于在帧时间序列的至少一帧中标记3D对象位置的注释数据,该注释数据是基于在帧处理系统的用户界面处接收到的用户输入而生成,用于将3D空间中的对象位置经受施加的几何限制而移动到3D对象位置相对于3D道路模型的路面的高程。
几何限制可以将已知3D位置限制为相对于3D道路模型的路面预定的零高程或非零高程。
3D注释要素可以位于初始3D位置,将3D注释要素几何投影到第一帧的图像平面中,并且可以在保持所述几何限制的同时调整3D位置,以将3D注释要素的投影与第一帧中的移动对象相匹配,由此确定移动对象的已知3D位置。
注释数据可以包括通过将确定的3D对象位置处的3D注释要素投影到帧的图像平面中而生成的2D注释数据。
预期道路模型可以是通过在捕捉图像时间序列的同时重构车辆行驶的路径而确定,3D道路模型展现出与重构的车辆路径的形状相对应的道路形状。
本发明还一方面提供一种图像处理计算机系统,其包括配置为执行上述步骤的一个或多个处理器,以及一种包括可执行指令的计算机程序,这些指令在图像处理计算机系统的一个或多个处理器上执行时促使该计算机系统执行上述步骤。
本发明提供一种计算机程序产品,其包括存储在计算机可读存储介质上的代码,并配置为在一个或多个处理器上执行时实施任何前述权利要求所述的方法或系统。
本发明再一方面提供一种处理计算机系统,其包括配置为执行任何上述步骤的一个或多个处理器。
本发明再一方面一种包括可执行指令的计算机程序,这些指令在处理计算机系统的一个或多个处理器上执行时促使该计算机系统执行任何上述步骤。
附图说明
通过非限制性示例的方式结合以下附图,更清楚地理解本发明并表明实现本发明实施例的方式,图中:
图1示出用于训练结构检测组件的训练系统的高度示意性功能框图;
图2示出自主驾驶车辆的高度示意性框图;
图3示出用于捕捉待注释的道路图像的车辆的高度示意性框图;
图3A示出车辆的示意性正视图;
图4示出图像处理系统的示意性框图;
图4A示出图4中系统的扩展图;
图5左侧示出自动图像注释过程的流程图,右侧示出所述方法的相应步骤的示例图;
图6示出表示图像系统有助于在人工定影(fixer)阶段进行调整的功能的示意性框图;
图7、图7A和图7B示出用于重构车辆路径的同步定位与建图技术(SLAM)的原理;
图8示出车辆的示意性透视图;
图9示出配备有至少一个图像捕捉装置的车辆的示意性透视图;
图10示出基于图像测量图像捕捉装置的角定向的某些原理;
图11示出基于图像测量道路宽度的某些原理;
图12示出人工定影阶段的手动调整的示例;
图13示出带注释的道路图像的示例;
图14示出SLAM输出的示例;
图15示出基于图像测量前进方向的某些原理;
图16示出基于图像测量道路法线的某些原理;
图17示出移动通过点云世界的相机位置的SLAM重构的示例图像;
图18至图24示出用于基于本公开的技术注释图像的注释工具用户界面的示例;
图25示出应用于道路图像的连续注释;
图26示出相对于车辆的图像捕捉装置定义的参考点;
图27示出道路法线估计过程的更多细节;
图28示出自身(ego)车道估计的俯视图;
图29示出注释移动对象的方法的流程图;
图30示出图29中的方法的步骤应用于实践的可行方式的示意图;
图31示出用于注释3D帧的注释界面的示例;
图32A至图32E示出使用中的扩展注释界面的示例;以及
图33示出图29中的方法的步骤应用于3D注释要素以生成2D和/或3D注释数据的方式。
具体实施方式
举例而言,参照名称为“Image Annotation(图像注释)”、申请号为PCT/EP2019/056356的PCT国际专利申请,其全部内容通过引用归并本文。本发明公开了一种图像处理系统,其中,为了进行图像注释,使用同步定位与建图(SLAM)处理来重构行驶车辆(自身车辆)的3D路径(VP)。SLAM处理应用于由车辆的图像捕捉装置(相机)捕捉的图像。在处理图像时,确定捕捉每个图像时自身(ego)车辆在自身车辆路径VP上的相应位置(称为该图像的捕捉位置)。
现将描述图像处理系统的更多细节,提供在下文标题“注释对象”下描述的本发明实施例的相关上下文。本发明使用3D道路模型作为注释静态对象或帧间移动对象的基础。在下文描述的本发明实施例中,使用前文概述并说明的技术,从自身车辆在3D空间中的路径推断出3D道路模型。然而,本发明并不局限于这方面,可以使用其他方法(稍后给出一些示例)而确定3D道路模型。
自主驾驶车辆需要获知周围道路布局,这可通过最新的CNN来进行预测。这项工作解决了目前缺乏用于确定各种驾驶操纵所需的车道实例的数据。主要问题是耗时的通常逐图像应用的手动标注过程。
本公开认识到驾驶汽车本身是一种注释形式。这在半自动方法中得以利用,该方法允许通过利用3D的估计道路平面并将标注从该平面投影到序列的全部图像而对图像序列加以有效标注。每图像的平均标注时间减少到5秒,并且数据捕捉仅需低成本的行车记录仪即可。
自主驾驶车辆有可能彻底变革城市交通。移动性将更加安全,始终可用,更加可靠,成本更低。
一个重要问题是向自主驾驶系统给予有关周围空间的知识:自动驾驶汽车需要获知其周围的道路布局,以便做出明智的驾驶决策。本公开解决了从安装在车辆上的相机检测驾驶车道实例的问题。需要空间有限的单独车道实例区域来执行各种挑战性的驾驶操纵,包括换道、超车和十字路口。
典型的最新CNN模型需要大量标注数据才能可靠地检测车道实例。然而,公开的标注数据集不多,主要是因为耗时的注释过程;每图像完全注释图像以完成语义分割任务的时间从几分钟到一小时以上不等。相比之下,本发明的半自动注释过程将每图像的平均时间减少到几秒。这可通过以下方式加速获得:(1)注意到驾驶车辆本身就是一种注释形式,并且汽车多数情况下沿着车道行驶;(2)将手动标注调整从单个视图传播到序列的全部图像;以及(3)在不明确的情况下接受未标注的部分。
一些先前的工作旨在在自主驾驶场景中创建半自动对象检测。提出检测和投影图像中未来的驾驶路径,但未解决车道注释的问题。这意味着该路径不适合车道宽度,而是横穿车道和路口。此外,它需要高成本的传感器套件,其中包括经校准的相机和激光雷达。相比之下,本方法适用于来自启用GPS的行车记录仪的数据。本公开的贡献包括:
-一种用于3D车道实例的半自动注释方法,仅需低成本的行车记录仪设备;
-在交通拥堵的场景下,尽管有遮挡也能进行路面注释;
-使用CNN获得道路、自身车道和车道实例分割的实验结果。
下面描述一种方法,提供了一种全自动的生成训练数据的方法,其质量仅略低于常规的手动处理。
本文还描述了对此引入手动校正(“人工定影”)阶段的扩展。利用这一扩展,该方法成为一种半自动方法,生成的质量与常规的手动方法同样高,但人工工作量却减少百倍(以每图像的注释时间来衡量)。这是基于以下观察:典型的注释时间(使用目前使用的当前类型的全手动注释)可达每图像7分钟到90分钟之间的任何时间;然而,使用下文描述的方法,可实现每图像约12秒的注释时间。
在下文描述的方法中,训练图像为视频图像的帧。显而易见的是,本文描述的方法特别适于对移动的训练车辆所捕捉到的视频帧进行批量注释。对于典型的训练视频(由一系列静态2D图像组成,即由帧组成),每个典型的训练视频序列的注释时间达7分钟,相当于每图像约12秒,同时仍可获得高质量的结果。
图1示出用于基于一组带注释的感知输入108(即,感知输入连同相关联的注释数据)来训练感知组件102的监督训练系统的高度示意性功能框图。在下文的描述中,感知组件102可以同义地称为结构检测器、结构检测组件或简称为结构检测器。用于训练目的的感知输入在本文中可以称为训练示例或训练输入。
感知输入可以为2D图像,并且用2D注释数据(例如2D边界框、2D分割图等)注释的2D图像可用于训练2D感知组件,诸如2D对象检测器、2D实例分割组件等。然而,感知输入也可为3D,即包括3D结构数据,并且可以使用3D注释数据(诸如3D边界框)训练3D结构检测器(例如3D边界框检测器、3D姿态估计器、3D对象检测器等)。
在图1中,训练示例标有附图标记104,与之关联的一组注释数据标有附图标记106。注释数据106为与之关联的训练示例104提供地面实况。例如,对于图像形式的训练示例,注释数据106可以标记图像104内某些结构组件(诸如道路、车道、路口、不可驾驶区域等)和/或图像内对象(诸如其他车辆、行人、街道标牌或其他基础设施等)的位置。
带注释的感知输入108可以分为训练集、测试集和验证集,分别标有108a、108b和108c。带注释的训练示例因用于测试或验证而无需形成训练集108a的一部分就可用于训练感知组件102。
感知组件102从训练集108a、测试集108b和验证集108c之一接收感知输入,表示为x,并处理感知输入x,以便提供相对应的感知输出,表示为
y=f(x;w)
在上文中,w表示感知组件102的一组模型参数(权重),f表示由权重w和感知组件102的架构定义的函数。例如,在2D或3D边界框检测的情形下,感知输出y可以包括一个或多个检测到的从感知输入x导出的2D或3D边界框;在实例分割的情形下,y可以包括一个或多个从感知输入导出的分割图。一般而言,感知输出y的格式和内容取决于感知组件102的选择及其选择的体系结构,并且这些选择又是根据要对其进行训练的一个或多个期望的感知模态而作出。
基于训练集108a的感知输入来训练检测组件102,以将其输出y=f(x)与关联的注释数据所提供的地面实况相匹配。针对感知输入x提供的地面实况在此表示为y
这是一种递归过程,其中训练系统110的输入组件112系统地将训练集108b的感知输入提供给感知组件102,并且训练系统110的训练组件114调适模型参数w,以试图优化误差(成本)函数,补偿每个感知输出y=f(x;w)与相对应的地面实况y
测试数据108b用于尽量减少过度拟合,这是指以下事实:超出某一点,提高检测组件102对训练数据集108a的准确度不利于其将泛化到训练中尚未遇到的感知输入的能力。过度拟合可能被识别为提高感知组件102对训练数据108的准确度会降低(或不提高)其对测试数据的准确度的一点,其中准确度是根据误差函数而测得。训练的目的在于将训练集108a的总误差减至最低,以至能够在不过度拟合的情况下使其最小化。
必要时,验证数据集108c可用于提供对检测组件性能的最终估计。
该描述最初集中于2D感知输入,其形式为带注释的街景图像(本文中又称为道路图像),即,具有关联图像2D注释数据的街景图像。稍后描述3D感知输入和3D注释数据。
下述方法可用于自动或半自动地生成这样的注释数据106,用于训练、测试和/或验证检测组件102。
图2示出自主驾驶车辆200的高度示意性框图,该自主驾驶车辆示为包括经训练的检测组件102的实例,其输入端连接至车辆200的图像捕捉装置202且其输出端连接至自主驾驶车辆控制器204。在使用中,自主驾驶车辆200的经训练的结构检测组件102根据其训练实时检测由图像捕捉装置102捕捉的图像内的结构,并且在无任何人工输入或有限人工输入的情况下,自主驾驶车辆控制器204基于结果来控制车辆的速度和方向。
虽图2中仅示出一个图像捕捉装置202,但自主驾驶车辆可包括多个这样的装置。例如,可以布置一对图像捕捉装置以提供立体视图,并且道路结构检测方法可应用于从每个图像捕捉装置捕捉到的图像。
应当领会,这是对某些自主驾驶车辆功能的高度简化描述。自主驾驶车辆的一般原理已为公知,因此不再赘述。
2视频收集
为了稍后详细的实验,使用标准的Nextbase 402G专业行车记录仪以每秒30帧1920x1080的分辨率记录视频和相关联的GPS数据,并用H.264标准进行压缩(但也可使用任何合适的低成本图像捕捉装置来实现相同的优势)。相机近似沿着车辆的中心线安装在汽车挡风玻璃内部,并与运动轴近似对准。
图26(左上方)示出来自所收集数据的示例图像。为了消除汽车移动极慢或静止不动的部分(这在城市环境中十分常见),仅包括根据GPS相距至少1米的帧。最后,将记录的数据拆分为长度为200m的序列。
图25示出示例道路图像(左上方),包括道路(右上方)、自身车道(左下方)和车道实例(右下方)的注释。尽管受到遮挡,车辆下方的道路和车道仍带注释。未着色的部分未带注释,即类别未知。
图3示出车辆300的简化框图,该车辆300可用于捕捉待注释的道路图像,即,上文参照图1描述的那类道路图像。优选地,这些图像被捕捉为车辆300沿道路驾驶时记录的短视频片段的帧,其方式是允许车辆在每个视频片段的记录过程中行驶的路径根据该视频片段的帧来重构。车辆300可以称为训练车辆,便于简写其与图2中的自主驾驶车辆200的区别。训练车辆300示为包括图像捕捉装置302,其可为前向或后向图像捕捉装置,并耦合到处理器304。处理器304从图像捕捉装置302接收所捕捉的图像,并将它们存储在存储器306中,可以从存储器306中检索出这些图像以供采用下述方式使用。
在本例中,车辆300是汽车,但它可为任何形式的交通工具。
本发明的基础是这样一个假设:即由人驾驶的训练车辆300行驶的路径沿道路延伸,因此可从训练车辆300采取的任何路径推断出道路的位置。当要注释所捕捉的训练图像序列中的特定图像时,训练车辆300在捕捉到该图像之后随后采取的路径的后见之名允许进行自动注释。换而言之,利用捕捉到该图像之后车辆行为的后见之明,可推断出图像中道路的位置。带注释的道路位置就是鉴于训练车辆300随后行驶的路径以及关于其与道路位置的相关性的基础假设来预期的道路位置。
如下进一步详述,通过处理捕捉的图像本身来确定路径。据此,当用预期道路位置注释特定图像时,对于前向(后向)的图像捕捉装置302,该图像中预期道路位置是根据车辆在捕捉到该图像之后(之前)行驶的路径而确定,如使用捕捉图像序列中的至少一个后续(先前)的捕捉图像来重构。亦即,使用从正注释的图像之后(之前)捕捉的一个或多个图像导出的路径信息来注释每个受注释的图像。
3视频注释
图27示出帧i的车道边界点
初始注释步骤呈自动化,并提供3D空间中路面的估计以及自身车道的估计(请参阅第3.1节)。然后,手动校正估计,并在路面空间中添加另外的注释。然后将标注投影到2D相机视图中,从而允许即刻注释序列中的全部图像(请参阅第3.2节)。
3.1自动3D自身车道估计
给定来自具有未知内部参数和外部参数的相机的N帧视频序列,目标是确定3D路面并将自身车道的估计投影到该路面上。为此,首先应用OpenSfM[28]-一种“运动恢复结构(structure-from-motion)”算法,获取3D相机位置ci,并在全局坐标系中为每帧i∈{1,...,N}设R
假设道路为嵌入3D世界中的2D流形。此外,道路的局部曲率很低,因此车轮的定向提供了对局部路面坡度的良好估计。相机固定在车辆内,相对于当前道路平面静态平移和旋转(即,假设车身遵循道路平面而忽略悬架运动)。因此,帧i的相机下方道路上的地面点g
g
其中h为相机在道路上方的高度,n为道路相对于相机的路面法线(请参见图26左侧)。于是,自身车道左右边界可推导为:
其中r为道路平面内垂直于行驶方向的矢量,
给定帧i,全部未来的车道边界
可通过以下方式投影到局部坐标系中:
然后可将车道注释绘制为相邻未来帧的多边形,即带有拐角点
这就隐含了这样一个假设,即在捕捉的图像之间,车道为分段的直线且平坦。下述各部分描述如何测量或以其他方式获得下量:
应当指出,对于具有相同相机位置的全部序列,仅需估计一次h、n和r。
道路上方的相机高度ft易于手动测量。然而,在无法完成此操作的情形下(例如,对于从Web下载的行车记录仪视频),也可使用根据OpenSfM获得的估计路面网格来获得相机高度。h的粗略估计便足矣,因为它可经由手动注释进行校正,请参见下段。
图27示出在单帧i处估计道路法线n和前进方向f
道路法线n的估计是基于以下事实:当汽车转弯移动时,代表其运动的矢量m将全部位于道路平面中,因此取这些矢量的叉积将得出道路法线,请参见图27。令m
帧i(在相机坐标中)的估计道路法线为:
其中
可以仅在转弯时估计法线,因此此加权方案强调转弯时的偏斜,而忽略行程的直线部分。
r垂直于前进方向f并在道路平面内,结果:
剩下的唯一量为f,可通过使用以下事实导出:
m
如果转弯速率低,则近似平行于c
至于法线,可以在整个行程中对f
在此情形下,将根据内积对移动进行加权,以便在低转弯速率时增加这些部分的权重,同时最大程度上确保前向移动。
量
为了估计这些量,可以假设自身车道具有固定的宽度w,
并且汽车已经刚好在中心位置行驶,即:
对于全部帧皆为恒定。在扩展中(请参阅下段),将此假设放宽到通过手动注释获得改进的估计。
实践中,选择在道路平面内具有多个转弯的序列来估计n,并选择直线序列来估计f。然后,对于具有相同静态相机位置的全部序列,重复使用相同的值。仅注释序列的第一部分,直至距末尾100m,否则将无法投影足够的未来车道边界点。附件A(算法1)中提供了自动行车道注释程序的摘要,图28中示出自动边界点估计的可视化效果(请参阅下文)并照此加以标注。
更多细节请参阅下述内容。
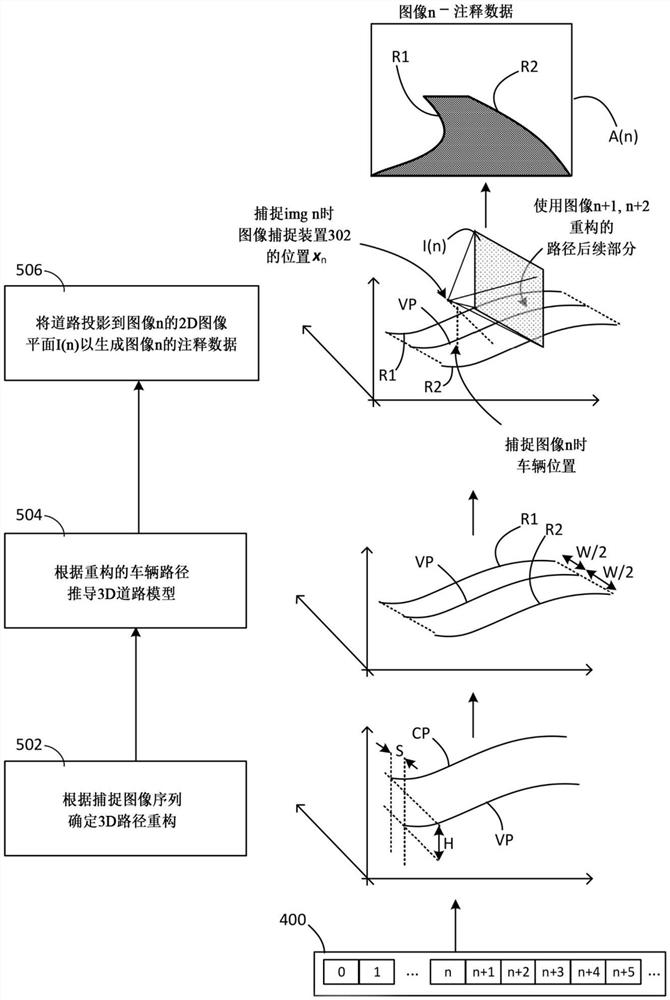
图4示出根据本发明运行以自动生成用于训练以上文参照图3描述的方式捕捉的图像的注释数据的图像处理系统的示意性框图。注释数据标记图像内的预期道路位置,其中使用上述假设来推断这些位置。图4A示出该系统的扩展,如下所述。图4A中的系统包括图4中的全部组件,并且关于图4的全部描述等同适用于图4A。
图5左侧示出由图像捕捉系统实施的自动图像注释过程的流程图,图5右侧示出相应步骤的示例说明。
现将并行描述图4和图4A中的图像系统和图5中的过程。
图4中的图像处理系统示为包括路径重构组件402、道路建模组件404和图像注释组件406。
路径重构组件402接收一序列捕捉的二维(2D)图像400,并对其进行处理,以根据捕捉的图像序列对车辆行驶的路径进行三维(3D)重构(图5,步骤502)。
在步骤502右侧,图5示出三维空间中的两条重构路径。
标注为CP(相机路径)的第一路径为训练车辆300的图像捕捉装置(相机)302行驶的路径的3D重构。用于根据相机在移动时捕捉的图像序列来重构移动相机行驶的路径的技术在本领域中已为公知,因此本文不再赘述。
可根据其他数据(加速计、高精度GPS等)重建路径,而仅从视频进行重构能够有利地降低捕捉数据的成本,因为基本的行车记录仪即可用于数据收集,而非包含高成本加速计、高成本精密GPS等的高价汽车。
标注为VP(车辆路径)的第二路径为训练车辆300行驶的路径的重构,其定义为某一点所行驶的路径,该点位于横跨训练车辆300宽度的近似二分之一,即距训练车辆的左右两侧等距,并在图像捕捉装置300下方近似位于道路水平面(在图3和图3A中标注为P)。亦即,在道路高度处沿着车辆300的中心线C(图3A),该中心线C垂直延伸并位于沿车辆300宽度的中间点处。
应当指出,这些点不必完全等距-即使这些点不等距,所述方法也能给出准确的结果。
如果已知相机302在路面上方的高度(在图3、图3A和图5中标注为H)、相机302相对于中心线C的水平偏移(在图3A和图5中标注为S)以及相机相对于车辆的定向,则根据相机路径CP可直接确定地平面上的车辆路径VP。相机的相对定向可捕捉为“前向点”和“视平线”,定义如下。
应当指出,图5右侧所示的示例仅为说明而非穷举,仅旨在举例说明可使用少量参考参数根据3D相机路径CP推断道路结构位置的一般原理。
根据3D路径重构,道路建模组件404创建(图5中的步骤504)假设车辆途经道路的3D模型602(图6)。
在步骤504右侧所示的示例中,道路模型由对应于假设车道边界位置的两条几何曲线R1、R2形成,它们定义为与车辆路径VP平行,与车辆路径VP处于相同的高度,位于车辆路径VP的任一侧,且距车辆VP的距离均为W/2,其中W为假设的道路或车道宽度。
这是基于以下假设:训练车辆300沿道路车道行驶,训练车辆300的行驶方向近似平行于该车道的实际车道边界,并且近似在车道中心驾驶该车辆。
预期道路位置可例如对应于道路本身的边缘(以便标记道路或道路旁的不可驾驶区域)或者对应于道路内车道的车道位置。
一般而言,自动注释技术可用于标记本文中称为“平行结构”的位置,该结构即预期至少近似平行于车辆驾驶的路径的结构,或更一般地预期相对于车辆路径具有特定定向的结构。这可为道路结构,诸如道路、车道、假设平行于车辆路径的不可驾驶区域、假设垂直于车辆路径延伸的路口或者除汽车之外的交通工具可能遇到的现实平行结构,诸如跑道(在自主无人机、飞机等情形下)等。据此,对3D道路模型的全部描述等同适用于车辆行驶环境的任何其他形式的3D结构模型,对于该3D结构模型而言,可使用本文所述的方法自动确定预期的平行结构。
除了它们平行于训练车辆300实际行驶的路径的基础假设,还可使用不同的假设来适应不同类型的平行结构。
在此,该描述可以具体参考道路或车道以及诸如道路或车道宽度的相关参数。但应领会,该描述适用于任何平行道路结构,并且对道路或车道宽度(等)的任何引用一般适用于针对预期平行结构确定的宽度参数。
图像注释组件406使用3D道路模型来生成2D注释数据,以用预期道路位置单独标记各个2D训练图像(图5,步骤506)。
如图5中步骤506右侧所示,生成序列中第n个2D图像(图像n,其可为捕捉的训练图像序列中的任何图像)的注释数据A(n),这是通过执行将3D道路模型几何投影到该图像平面上,该图像平面标注为I(n)。在本例中,这意味着将3D道路边界R1、R2投影到图像平面I(n)上,以使这些边界在图像中的投影标记为假设道路边界位于图像n中。
图像平面I(n)为与相机302捕捉图像n时的视场相对应的平面,因此定位于与捕捉图像n时的车辆位置相对应的一点。
参数计算组件408计算各种“参考参数”,这些“参考参数”用于根据重构的车辆路径构建3D模型并执行几何投影。这些参考参数包括以下图像捕捉参数,有关训练车辆300的图像捕捉装置302的位置和定向:
1)相机302在道路上方的高度H;
2)相机相对于中心线C的水平偏移量S;
3)相机302相对于车辆的定向,其可捕捉为:
a.相机302的“前向点”(定义如下);以及
b.相机的“视平线”(定义如下);
以及附加地:
4)道路/车道的宽度W。
这些参数以上文简述的方式使用,下面将描述如何使用它们的更多详细信息。现足以说明,这些参数是根据捕捉的训练图像400本身计算得出,这具有各种优势,如稍后所述。
注释数据存储在电子存储414中,从中可对其进行访问或检索,以用于上文参照图1所述的训练过程。在此过程中,最终,自动结构检测组件102正根据驾驶员的能力进行学习,以大多数时间在捕捉训练图像的同时使车辆300近似保持在道路中心。
3.2手动校正及附加注释
注释界面为人工注释者提供个人以批处理方式查看帧的能力,并且当前渲染的车道已投影到图像中。注释者可在最近便的帧中加宽、缩窄和移动这些车道,并且车道结构的这些更改将投影到批处理中的全部其他帧中,这与单独注释全部图像相比,提供了明显的优势。
图28示出自身车道估计可视化的俯视图。自动估计和手动校正分别标注为:
w
w
最初,全部
图18至图24示出注释者使用的注释界面的示例。在图18中,在图像中心,可看出自身路径投影到该帧中。在左下方,注释者提供有用于操纵当前渲染的车道的控件(缩窄、加宽、左右移动、移动车道边界等)并添加新车道。在图19中,注释者提供有调整相机高度以使重构与路面相匹配以及裁切高度以排除车辆仪表板或引擎盖的的机构。全部注释皆在估计的3D道路平面中执行,但通过2D相机视图中的投影可提供即时反馈。注释者可轻松地在序列中向前和向后跳过以确定标注是否与图像对准,并视需要进行校正。校正序列的示例可参阅图27(请参见上文)。
除道路上的车道之外,沿道路侧面的地带用附图标记NR1注释为“非道路”。另外,每个图像的整个上部(上方地带NR2)注释为非道路,其中由注释者手动调整大小。图25示出所呈现的注释的示例。
上述过程是在图4A中的扩展中实施,其中提供了呈现组件416,该呈现组件416可经由用户界面(UI)412呈现标记有为此图像确定的预期道路注释的单个训练图像(img n)。因此,用户可检查预期道路结构与图像中可见的实际道路结构的对应程度,并在必要时进行校正。
UI 412的输出端示为经由连接器418连接到图像注释组件的输入端,以表示以下事实:用户可经由UI 412修改单个图像的注释数据A(n),以便更好地将假设的车道边界R1、R2(仅)与该图像中的实际车道边界对准。这可有用于解决“一次性”差异,例如,由异常的局部道路结构引起的差异。
还提供了模型适配组件410,以允许经由UI 412同时跨多个图像有效地手动调适注释数据。实现这一目的是通过允许用户参考单图像及其呈现的注释数据来调适3D道路模型,以便更好地对准该图像中的道路边界。然而,由于正在调适3D道路模型(而不仅是单个图像的注释数据A(n)),这些调适也可应用于其他图像的注释数据,而无需用户手动调适这些其他图像的注释数据。例如,用户可调整假设的车道宽度W以更好地拟合一个图像,由于道路模型正在适应新的车道宽度,可基于具有新车道宽度W的适配模型来自动调适其他图像的注释数据。下面将参照图6对此予以详述。
图4和图4A中的图像处理系统的上述组件为由图像处理系统执行的图像处理系统表示功能的功能组件。这些功能以软件实施,即通过存储在存储器中并由图像处理系统(未示出)的一个或多个处理器执行的可执行指令(代码)来实施,该处理器可由一个或多个通用处理单元(诸如CPU)、专用处理单元(诸如GPU)或其任何组合形成。应当领会,这些组件代表可使用各种代码结构实施的高级功能。图4中的箭头大体上表示这些高级功能之间的高级相互关系,并不必对应于物理或逻辑连接的任何特定布置。图5中的步骤为计算机实施的步骤,所述指令在一个或多个处理器上执行时促使图像处理系统执行这些步骤。
示例实施方案的详情:
图13中示出注释图像的示例。在图13中标记两个可驾驶车道:朝向图像中间的自身车道,以及位于图像左侧的另一个可驾驶车道。这些车道的两侧标记有两个不可驾驶区域,一条最右侧沿另一方向交通的车道与自身车道之间被其中一个不可驾驶区域隔开。
如上所述,该方法利用到以下观察和假设:
1)当人驾驶汽车时,他们通常遵循保持靠近道路上车道中心的路径。因此,如果将视频相机向前(或向后)放置在人驾汽车中,则当相机向下投向地面并扩展到车道宽度时,该相机追踪的路径将(主要)勾勒出车道所在的轮廓。
2)找到车道所在的轮廓后,对于视频中的每个图像,可再将汽车下方车道的轮廓投影回该图像中,并(几乎)准确地提供标记车道位置所需的注释。
如稍后所述,本发明的优选实施例可利用低成本设备来实现。
确定路径和参考参数:
为了生成车道位置并将其投影回每个图像,如上所述,需要获知或推论下列量:
·相机302在3D空间中遵循的路径CP(图5);
·相机302在车辆300内的定向,其可使用下列参数表示:
о前向点,其定义为汽车在直线行驶时看似朝向的像素;
о视平线,定义为图像上看似与道路平行的线;
·相机在路面上方的高度H(图3、图3A和图5);
·相机在汽车内的左/右位置(在图3A和图5中捕捉为间隔S);以及
·车道宽度W(图3A和图5)。
下文描述的图像处理技术允许使用低成本且未校准的设备(诸如售价几百磅的移动电话或行车记录仪或者其他低成本的消费类设备)而确定全部上述量。这是因为可使用下述图像处理技术根据训练车辆300捕捉的图像计算出这些量。
3)相机CP的3D路径可通过使用现有的可视SLAM(同步定位与建图)技术对未校准相机捕捉的视频进行后期处理而推导得出。诸如OpenSFM和ORB-SLAM等软件包可用于生成准确的相机路径信息。
这类技术可用于构建训练车辆300行驶的环境的3D地图,同时跟踪该车辆在该环境内的位置。
参照图7举例简要说明基于图像的SLAM的一些基础原理。图7上部示出在不同时间、不同但相近位置捕捉的三个现实环境的图像img(n-1)、img(n)和img(n+1)。通过识别图像中出现的独特参考特征(诸如标注为F1和F2的那些特征)并将它们在整个图像中进行匹配,然后可使用三角剖分来构建这些特征的3D模型,如图7下部所示。对于每个捕捉的图像img(n-1)、img(n)、img(n+1),估计在捕捉图像时相机302的3D位置,其标注为x
应当指出,构建为一部分SLAM过程的3D模型不同于建模组件404构建的3D模型。前者是基于图像三角剖分构建的路面图的形式,而后者则是基于车辆路径推断的预期结构,该车辆路径又是根据执行SLAM过程时导出的图像捕捉装置位置而确定。
参照图7A和图7B,可使用俯仰角(P’)、侧倾角(R’)和旋角(Y’)来表示相机302的3D定向。纵轴a
实际上,这类SLAM技术确实会生成环境的表面重构。尽管理论上可使用这种表面重构直接确定道路/车道位置,但实践中该表面重构的质量不足以做到这一点。然而,相机在3D场景中的运动质量良好,因此可为相机路径CP提供足够准确的重构(这是因为相机位置是基于数百个特征点,而表面位置仅基于少数特征点),这又允许使用本技术以足够的准确度推断出道路/车道位置。
应当指出,这些技术中的某一些还可自动推断出相机的特性,诸如焦距,甚至镜头畸变参数。可以使用这样的参数来优化本技术,但它们并非必要条件。
图14示出移动通过点云世界的相机位置的SLAM重构的示例图像。标注为1400的金字塔结构序列代表拍摄不同图像时图像捕捉装置的位置和定向,如通过SLAM过程来估计。它们共同定义了相机路径CP。标注为1402的区块构成3D路面图,作为一部分SLAM过程而生成。稍后将就这两个方面予以详述。
由参数计算组件408经由图像处理来计算其余的参考参数,如下所述。首先简要介绍一些基本注意事项。
参照图8,可采用与相机相同的方式定义训练车辆300的3D定向。这里,车辆的俯仰角、侧倾角和旋角分别标注为P、R和Y,而训练车辆的横轴、纵轴和竖轴(车辆轴线)分别由单位矢量a
应当指出,本文中的术语“绝对”用于指代车辆正行驶的环境内的定向和位置,除非另作注明,即,如相对于车辆移动的环境的全局参考帧的(任意)全局坐标系定义的定向和位置。这可定义为SLAM过程的固有部分。这是定义了重构的车辆路径、图像捕捉装置在环境内的定向(绝对定向)和表面重构的坐标系。
术语“相对”用于指代相对于车辆的位置和定向,即相对于车辆的坐标系(诸如由车辆轴线定义的坐标系a
参照图9,该方法不要求相机302的定向与训练车辆300的定向完全对准。相机轴线相对于车辆轴线的角度失准是可接受的,因为可使用如下所述的技术来检测并解决这种失准。
4)利用汽车直行时汽车的运动矢量将与车身平行的事实,可自动推导出相机在汽车内的角定向,即相机纵轴a
不可能依赖视频中车辆完美直行的那些部分。为了克服车辆可能永远不会完美直行的问题,采用以下方法。
选取路径上的三个等距点,连结外侧的两个等距点,并将该矢量用作中心点处正方向的近似值。该方法由中心点与两个外侧点之间矢量的点积连续平均加权。因此,汽车近乎直行的时间比汽车转弯的时间具有更高的权重。使用该方法可产生亚像素精度。
在图15中对此予以说明。
换而言之,这利用了观察到当车辆300沿(近似)直线行驶时,矢量差x
应当指出,严格而言,只要转弯速率近似恒定(实际上不要求车辆沿直线行驶),矢量差x
该计算执行为矢量平均,其中矢量代表相机坐标系中表达的汽车平均前进运动。前向投影时,该矢量将在特定像素(前向点像素)处切分图像平面。该像素为汽车在笔直平坦的道路上驾驶时看似驶向的像素(此处使用术语“前向点”)。
举例而言,可根据等式1将车辆的前进方向计算为分别在相机与车辆的纵轴之间的矢量差的加权平均值:
其中w
假设车辆纵轴a
应当指出,就此需要在图像捕捉装置302的参考帧中估计x
SLAM过程将推导出x
点积v
如上所述,严格而言,只要转弯速率近似恒定(实际上不要求车辆沿直线行驶),矢量差x
当然,通常随着车辆移动,车辆轴线的定向在图像捕捉装置的参考帧中保持固定,这是因为预期相机302相对于车辆300保持在基本固定的定向上-上述时间依赖性源于对车辆和相机轴线的估计不准确。
时间t对应于相机路径CP上的某一点,并可为捕捉图像之一的时间或捕捉的图像之间的时间,可通过对不同图像的相机姿态进行内插而将相机姿态分配给该时间。
在一种替代实施方案中,a
参照图10,一旦已经以此方式计算出相机302相对于车辆300的角定向,便可确定车辆纵轴a
5)因为注意到大多数道路局部平坦,从而当汽车转弯时,垂直于相机路径所描述的表面的矢量将从相机直接指向路面,可自动推断出相机在车辆内的旋转定向-即,相机竖轴a
在图16中对此予以说明。
换而言之,这利用了观察到:当车辆表现出角加速度以使车辆路径在3D空间中呈现局部曲率时,车辆路径的弯曲部分所在的平面至少近似平行于正常驾驶条件下的路面平面;或等同地,路径的局部弯曲部分的法线至少近似平行于车辆300的竖轴a
在相机坐标中表达路径的平均法线矢量。垂直于该路面法线矢量的平面可与图像平面相截,如果汽车沿着笔直的水平道路行驶,将在图像上提供一条与地平线相匹配的线(本文使用术语“视平线”)。
举例而言,可根据等式(2)将相机在车辆内的旋转定向计算为相机竖轴与车辆竖轴之间的偏移角的加权平均值:
其中:
·w
·v
·v
假设车辆竖轴a
如上所述,就此需要在图像捕捉装置302的参考帧中估计v
叉积的量值|v
应当领会,上文关于角定向测量所作的许多观察也适用于旋转定向测量。
6)可通过根据SLAM过程生成路面网格(即使这是低准确度)来计算相机在道路上方的高度(H),然后对该网格上方的相机路径上全部点的高度取平均值。整个路径上取平均值抵消了SLAM过程生成的网格准确度差的影响。
相机路径CP上给定点的高度H定义为相机路径CP上一点与在该点沿车辆竖轴a
7)可通过使用各种计算机视觉技术检测车道边界来估计车道内相机的左右位置(S)以及车道的宽度(W)。
检测车道边缘显然是个难题(生成此车道训练数据的整体目的是训练神经网络来解决该问题)。然而,由于具有两段附加信息,在此特定情形下检测车道边缘会变得非常容易。首先,在进行任何车道边界检测之前,可使用已知的相机路径(以及车道形状)来创建变换,以有效地整直道路。其次,根据相机路径(几乎)获知车道的中心线,并且车道的宽度相对固定,因此搜索车道边界的位置大幅缩减。
例如,可将图像投影到俯视图中,进行变换以使道路整直(使用相机路径信息),然后可使用霍夫(Hough)变换来检测具有正确的近似位置和方向的主导线。
相机路径CP上每个点处的道路宽度定义为在该点沿车辆横轴a
通过利用以上各项,仅使用从低成本且未校准的图像捕捉装置捕捉的图像,即可在视频的全部图像中全自动生成汽车驾驶车道的注释。
还期望扩展这些技术来标注多个车道。一种方式如下:
8)通过沿每个车道驾驶并创建包含每个车道路径的单个3D SLAM重构,可自动注释多个车道(以及整个路面)。为了获得车道和整个路面的相对定位,有必要将沿每条路线驾驶的单独视频合并到单个重构中。
图17示出移动通过点云世界的相机位置的SLAM重构的图像,其中有两组相机图像。
9)除非相机图像都面向相同的方向,否则难以将多个视频中的图像合并到单个3D重构中;即,将沿道路反向行驶的汽车的视频合并到单个3D重构中并不切实际。一种解决此问题的方式是使前向相机在一个方向上行驶,而使后向相机在另一方向上(在另一车道上)行驶。这样就能给出一组全部沿道路指向同一方向的图像。
扩展-人工定影阶段:
本文描述的全自动注释系统产生可用的注释,但它仍会存在许多错误,人工注释者毫不费力即可修复这些错误。举例而言:
·计算出的相机高度可能不完全正确;
·车道内的左/右位置可能不完全正确;
·车道宽度可能不完全正确;
除了这些关于不完善自动计算的修复工作之外,还有一些可人工添加的附加注释,这些注释的添加工作量极少,但若它们存在于训练数据中,则可提供显著的优势。举例而言:
·可添加相邻车道(不必行驶在这些车道上)。很容易添加这些相邻车道,因为它们一般与汽车驾驶的车道具有平行的边界。
·可添加不可驾驶的平行道路特征。可简单地添加保留给自行车或公交车/出租车的道路区域(同样,它们一般只是地面上遵循驾驶车道的平行区域)。
·可添加与道路相邻的人行道区域。
10)已经开发了具有简单用户界面的工具,该工具允许人工注释者进行这些“修复”并添加这些附加注释。该工具的主要优势在于,可在视频的一帧中进行修复和附加注释,并且该系统可自动将这些更改传播到视频中的全部帧中。
这种有效节省源于以下事实:用户可使用一帧及其注释数据作为参考来调适3D道路模型(经由模型适配组件410),并又可将适配后的3D道路模型应用于多个图像。
还应指出,该技术不限于手动调整自动生成的道路/车道模型。可标记世上任何静止的对象,并可计算该对象在视频的每个图像中的位置(因为已知相机的运动)。
以此方式,可以将已经预先填充有近乎正确注释的一帧视频提供给人员,并且仅需最少的修复即可生成约50至100个注释好的图像。如果使用更长的视频片段,则可能生成更多的图像,但根据经验,便于3D重构并在构建上也相当相似的视频长度足以包含50至100个图像。
11)应当指出,用作训练数据的图像是采样自整个视频,因此它们在空间上(而非时间上)相隔合理的间距,从而为网络提供一些多样化的训练数据。从视频中获取每个图像无甚裨益,因为它们中的大多数彼此极度相似。
图6示出可在人工定影阶段执行的调整类型示例的示意性框图。呈现组件可在用户界面412的显示上呈现任何捕捉图像的数据,并覆盖有其相关联的注释数据A(n)。还呈现一个或多个可选的选项600,用户可选择这些选项600以使模型适配组件410以快速直观的方式适配于3D道路模型602。如图6所示,随着道路模型602的更新,不仅根据适配模型602修改当前正呈现的注释数据A(n),而且适配模型602也可用于针对相同视频序列中的其他图像更新注释数据604。举例而言,图6上部示出图像内标记的道路或车道。尽管右侧边界R2与图像中可见的现实右侧边界准确重合,但左侧边界R1略微偏离。用户可通过移置3D模型中左侧边界的位置来快速修复此问题,其中使用当前图像和当前图像上呈现的注释数据作为参考,以手动调适左侧边界R2的位置,直至它对应于图像中可见的现实左侧边界。这一更改将应用于序列中的多个图像上,这意味着只要道路/车道保持相同的宽度,便会将左侧道路边界准确放置在这些图像中。
利用了许多与车辆路径平行的目标道路结构,可提供一系列极快的手动注释选项:
-可轻松地更改(“轻推”)自动确定的道路结构的宽度或位置;
-可轻松地创建平行于车辆路径/自动确定的道路的附加道路结构,并可以相同的方式轻松地轻推其宽度和位置。附加道路结构的定向自动平行于车辆路径/现有道路结构。例如,自动确定的道路结构可为“自身车道”,即车辆驾驶的车道。很轻松就能在多个图像上添加附加结构,诸如:
о其他车道(例如非自身车道、公交车道、自行车道)、中央道路标志或左右道路标志或者任何其他平行道路标志、不可驾驶区域,诸如人行道、草坪、障碍物、路边植物(树木、树篱等)。
-也可非常轻松地添加垂直的道路结构,即,垂直于自动确定的道路结构/车辆路径延伸的道路结构,并且可用相同的方式轻推其宽度和位置。示例包括路口、让行标线或其他垂直道路标志等,或与路径成假设角度的其他结构(例如,道路中的分岔点)。
-可通过允许用户在他/她选取的一点“拆分”视频序列来适应道路宽度的变化,例如由于车道数目变化而引起的变化。在视频拆分点之后,用户的调适将仅应用于拆分点之后一些点处的3D道路模型-拆分点之前的模型部分将保持不变,这又意味着拆分点之前的图像注释数据保持不变。
举例而言,考虑以下工作流程。用户从训练序列的始端开始。已使用上述技术自动确定了3D自身车道。此外,通过假设它们具有一定的宽度并位于自身车道的中心和最右边/最左边,已确定中心车道标记和左/右车道标记的位置。此时,用户可调适自身车道的宽度和位置,必要时还可调适道路标志的宽度和位置,以使它们与图像中可见的实际自身车道/道路标志对准。用户还可在此时添加附加平行结构,诸如非自身车道、不可驾驶区域等。
图18中示出预先修复的自动注释图像的示例,其中仅标记自身车道(及其假设的中心线和车道边界)。可以看出,标记与实际车道边界不完全一致。图19示出修复后的图像,其中已调整自身车道的宽度和位置,并已标记其他车道和不可驾驶区域。
这些更改将应用于基础3D模型,因此也将应用于序列中的后续图像。然后,用户可循环浏览后续图像,以快速验证是否全部匹配。
当用户到达视频中某一图像内路口清晰可见的一点时,他/她可在该点添加路口结构,并在必要时轻推其位置/宽度。同样,这将应用于3D模型,因此将应用于路口可见的全部图像。道路边缘处的不可驾驶式道路结构将自动适配于并行路口(即,不可驾驶式道路结构中与新路口重叠的任何部分皆将被自动消除)。
图22示出刚添加路口时的UI示例。用户已将路口定义为垂直于车道切分左右车道。
参照图12,当用户到达视频中道路/车道宽度变化的一点(例如车道缩窄/加宽、车道数目变化或减少等)时,他/他可在这一点拆分视频,并使用该帧作为参考来修改基础模型(图12,步骤1)。将当前视频帧的位置映射到车辆路径上的一点,该点又用于将3D模型的适配性限制到仅在该点之后的部分-在此之前的点(用户已验证过注释与图像相匹配)不受影响。此时,用户可更改道路宽度、添加车道等。该系统能够自动在拆分点周围内插平行结构,例如线性内插。例如,添加车道时,道路通常会逐渐加宽,直至能够容纳新车道为止,用户可继续视频直至新车道达到其全宽的那一点,然后在该点添加车道(图12,步骤2)。该系统自动在中间区域之间进行内插,在该中间区域中,假设新车道的宽度线性增大,直至达到其最终宽度(例如图12,步骤3)。
图23和图24示出其示例。在图23中,用户已选择在图22中的路口之后不久拆分视频的选项,以适应以下事实:此时在右侧具有较宽的不可驾驶道路区域,在图24中,用户已对此加以注释。
作为扩展,用户还可在图像中标记天空区域。这可能是用户定义天际线的简单情形,在该天际线上方,全部图像肯定皆为天空。即使这不会标注图像中的全部天空,但仍可用于防止经训练的神经网络将天空识别为道路结构。更复杂的技术可使用3D道路结构来推断每个图像中的天际线,例如,基于3D空间中道路的最高点。
超越车道训练数据的扩展:
视频中与所遵循的路径平行的任何特征皆可得益于人工注释者同样加速注释和单击添加。
12)例如,可以此方式注释道路标志。位置和类型均如此,包括中心虚线或实线、道路边线、双黄线等。例如,可以此方式添加自行车道,也可添加人行道。
图20左侧示出标记自行车道的图像示例。
简要回顾图4A,除上述组件之外,还示出对象注释组件420。这代表图像处理系统的对象注释功能,该功能允许有效地注释不属于道路的对象,这是基于这样的对象与3D道路模型之间关系的确定性。
图中示出对象注释组件420,其输入端分别连接至3D道路建模组件404和UI 412,其输出端用于提供对象注释数据,该对象注释数据既由呈现组件416呈现又存储在电子存储414中。
现将描述对象注释组件420的功能性。
视频中世上静止的任何特征都能得益于某种程度上的加速。即使这些特征可能因形状与驾驶路径平行而无法直接创建,它们仍可得益于以下事实:人们可在视频的一帧中对其进行标记,并自动将其传播到视频的全部帧中。
13)例如,可以此方式注释路标。可人工在一帧中专门标记出该路标(带有或不带低质量检测提供的任何初始提示),然后将其自动传播到视频中的整个图像集。
静止车辆的注释可采用相同的方式生成。尽管该技术不会自动允许以相同的方式加快对移动对象的注释,但该技术可用于驻停的车辆。因此,允许以最少的工作量对场景中的车辆子集进行注释。可通过在多个(至少两个)图像中标记同一个对象并假设注释之间保持恒定的速度来对移动的车辆进行注释。然后,可将标注传播到带注释图像之间的全部图像。
14)应当指出,静止的车辆看似与正移动的车辆相同,因此可在运行时使用对静止车辆的带注释图像训练的神经网络来检测移动的车辆。
图21示出正添加车辆的3D边界框的图像。
该技术的另一优势在于,当相机靠近视频图像中的对象时(例如,当对象较大时),人们可选择对该对象进行注释。然后将这种准确注释传播到全部图像,即使是对象在图像内很小。
15)由于3D模型是以视频中的整个图像序列为基础,当对象更远离相机时自动生成的注释将会具有在对象较大并由人注释时的注释准确度。这通常会比由人尝试注释较小对象图像所能达到的准确度更高。
图21考虑静态对象。现将描述该技术对移动对象(即,相对于道路移动)的扩展。
现将描述将上述技术扩展到移动对象(即相对于道路移动,从而有别于静态对象,移动对象不会相对于道路保持固定位置)。
使用3D车辆路径以及可以从图像本身导出的某些参考参数,确定3D道路模型。道路建模为嵌入3D空间中的2D流形。通过将道路模型几何投影到捕捉的图像的图像平面中,可用2D道路结构注释有效地注释那些图像。
快速数据注释软件允许重构自身车辆路径的3D模型,从中可推断出道路的路径。基本构思在于,相机与车辆几乎始终遵循车道,因此车辆轨迹暗示3D空间中可能的车道路径。可自动生成已遵循道路形状的车道结构,因此允许非常有效地注释道路的一组平行车道。
在一些实施方案中,针对少数的2D图像,经由用户界面(UI)提供一定程度的手动注释输入。它们与3D道路模型共同用于将这些输入自动外推到其他图像。
还对道路(诸如各个车道)的结构进行建模。假设车道与自身车辆路径VP平行延伸,则可有效地经由UI将车道添加到模型中。
假设重构的车辆路径的形状对应于车辆行驶的道路和/或车道的形状(统称为道路形状),则使用重构的车辆路径VP来确定3D道路模型。
可在当前上下文中扩展上述图像处理系统的功能性,以提供对同一道路上移动的其他车辆的有效注释。然后,这些图像可用于例如训练对象检测器。该过程不限于车辆,并可应用于假设以遵循道路形状的方式移动的任何对象,诸如沿着自身道路旁的人行道行走的行人。
除了了解道路车道外,自主驾驶车辆还需要识别其他道路使用者,以免发生碰撞。可通过注释从汽车拍摄的视频中的其他车辆、骑行者和行人而生成用于此任务的训练数据。
如图21所示,对静态对象(诸如驻停的汽车)进行注释相对简单,因为一旦在3D模型中建立正确的位置、定向和范围(通过针对一帧注释对象),该注释便对于对象可见的全部帧均有效。然而,沿着道路前进的车辆在每个帧中的3D空间位置不同,这将要求在每个帧中手动注释每个车辆。
在认识到自身车辆路径暗示道路路径的基础上,现在将其颠倒方向,以建立推断的道路路径为其他车辆的可能路径的良好预测的假设。一旦注释者已在单个时间点对移动的车辆进行注释,他们便可将其标记为“即未来临”或“驶向前方”,然后系统会对其以恒定速度沿道路轨迹进行动画处理。为了校正速度,动画将移至更早或更晚的一帧,然后重新定位注释框,使其与目标车辆在该时间点的位置相一致。然后得出两点之间的平均速度;目标车辆在视野内明显加速或减速时,可标记另外的位置。类似地,可通过稍微重新定位注释来注释较小的横向偏差,例如目标车辆驾驶员在一段道路上采取一条略微不同的路线时,并且系统将在沿道路路线的不同给定偏移量之间进行内插。
对于许多通行和往来交通的常见情况,该系统能够快速轻松地准确注释其他车辆。
图29示出在上述图像处理系统中实施的针对移动对象自动生成注释数据的方法的流程图。图30示出如何应用图29中的步骤的图形说明。在图30中使用带数字的圆圈表示与图29中步骤的对应关系。
在步骤1,使用上述图像处理方法针对捕捉图像的时间序列S确定3D道路结构模型。如图所示,道路建模为3D空间中的2D流形(曲面)。这是基于自身车辆路径VP的3D重构。该处理还估计前进方向f(自身车辆在此时行驶的方向)以及沿着重构的车辆路径VP的不同点处的路面法线n(垂直于路面-此处为垂直方向)。它们定义了垂直于前进方向f的方向r=f×n和路面法线n(横向)。
图30示出时间序列S的三个图像IMG1、IMG2和IMG3,但时间序列可以包含任意数目的图像。时间序列S可以例如由自身车辆的相机捕捉的短视频序列的帧形成。
在步骤2,手动注释至少一个图像以标记移动对象在图像中的位置。
在图30的示例中,经由UI手动注释IMG1,以定义围绕IMG1中可见的移动对象(这是另一车辆)的2D边界框B1。
在移动对象沿着平行于重构的自身车辆路径VP的路径OP行驶的假设下,有可能仅根据手动注释的边界框B1和重构的自身车辆路径VP来估计移动对象路径OP(步骤3)。
这可公式化为假设移动对象的路径OP保持固定的横向偏移量(即,在r方向上)并且距自身车辆路径VP(距路面的高程)保持固定的垂直偏移量(即,在路面法线n方向上)。
在图30的示例中,针对其他车辆确定两条3D路径OP1和OP2,它们为由边界框B1底部边缘上的参考点C1、C2跟踪的路径-在本例中,位于边界框B1的两个下角处。假设参考点C1和C2位于道路平面中,即与自身车辆路径VP的垂直偏移量为零。因此,对象路径OP1和OP2可唯一定义为3D空间中的路径,这些路径相对于自身车辆路径VP具有固定的横向偏移量和零垂直偏移量,当它们几何投影回IMG1的图像平面时与手动注释的边界框B1的参考点C1、C2相交。C1和C2在3D空间中的初始位置又称为3D空间中与IMG1的2D图像平面中C1和C2分别与OP1和OP2相交的那些点相对应的点。
应当领会,边界框的下角只是道路高度处的适当参考点的一个示例,并且可以替代地使用其他适当的参考点。例如,可以假设IMG1的边界框B1的上角位置垂直位于C1和C2上方。一般而言,通过利用3D道路模型的几何图形,可将手动注释的边界框B1从IMG1的2D图像平面映射到3D空间中任何适当的表示。
另举一例,在3D空间中建立初始位置的另一种方式如下所述。动画从2D注释开始,将其投影到3D空间中以创建表示移动对象的3D注释要素,在本例中,该要素为3D空间中的长方体(3D边界框),但可采用不同的几何形状。在图33中对此予以说明,其中3D注释要素标为附图标记800。
替选地,可将3D注释要素放置在3D空间中的多个位置,并投影回第一帧的图像平面中。
在3D要素处于距路面预定高程的假设下,长方体800位于3D空间中的初始位置。例如,可以假设长方体的四个最低角在路面法线n方向上与定义的路面间距为零。路面定义为在沿着重构的车辆路径VP的每个点横向平置(r)(但并非假设其总体上平置-在前进方向f上,它定义为遵循车辆路径VP的形状)。然后,注释者经由UI 412提供手动注释输入,响应于此,可以将长方体重新定位,但保持这个距路面的固定高程(距车辆路径VP固定的垂直高程)。将长方体投影回当前图像IMG1的平面中,从而注释者可以看到何时正确放置该长方体。通过施加距路面固定高程的几何限制,仅使用2D视图即可在3D空间中准确放置注释要素。注释者还能在3D空间中编辑注释要素的大小、形状等,以手动将其与2D图像相匹配。
例如,针对移动的车辆,可以假设该移动的车辆在沿路径移动时始终坐落于路面上,例如,对象注释要素的一个或多个预定参考点(例如,长方体的四个底角)与路面之间的垂直隔距为零或基本为零。
确定了IMG1在3D空间中的边界框表示后,可利用关于移动对象的3D路径的假设知识,对3D空间中另外的图像(例如,图33中的IMG2)进行“动画处理”。通过将边界框(例如长方体)800的3D表示移动到其相对于另外的图像IMG2的捕捉位置的假设位置,可通过将移动的表示800几何投影到其图像平面中而自动为该图像IMG2生成注释数据。
在步骤4,使用在步骤3确定的路径信息来自动注释序列中另外的图像。为了注释另外的图像(例如,IMG2或IMG3),假设参考点C1和C2分别相对于从IMG1的手动注释中已知的初始位置沿路径OP1和OP2移动一定距离。这会提供那些参考点C2、C3相对于另外的图像的捕捉位置的位置,这又允许通过将参考点C1、C2几何投影回另外的图像(例如,IMG2、IMG3)的图像平面来自动生成边界框(例如,图30中的IMG2和IMG3的B2或B3)。
按照图30中的示例,假设参考点C1、C2分别保留在对象路径OP1和OP2上,唯一未知的是沿这些路径行驶的距离。
在上述替选示例中,假设将长方体在3D空间中放置在距路面的固定高程上,则可在3D空间中以完全相同的方式相对于长方体的路径参考点(例如中心点、拐角等)定义长方体的单一预期路径。该路径参考点以相同的方式沿着预期3D路径移动,以确定长方体的新位置。确定预期路径是基于以下假设:(i)遵循道路的预期形状(如从车辆路径VP导出),以及(ii)保持距路面的预定高程(例如,四个最低角始终保持在道路高度上,或者适用的参考点保持距路面的预定高程)。应当领会,这基于相同的基本原理运行,并且本文关于OP1和OP2上的C1或C2的全部描述均等同适用于参考点,如针对3D注释要素(诸如建立的长方体)及3D其路径定义的参考点。在那种情况下,一旦使用上述假设将长方体移动到相关的预期位置,便通过将长方体几何投影到例如IMG2或IMG3的图像平面中而自动生成另外的注释数据。
在仅手动注释单个图像的情况下,假设其他车辆正以与自身车辆相同的速度移动。因此,在此情形下,当注释另外的图像(例如,IMG2或IMG3)时,如果自身车辆已沿着自身车辆路径VP相对于IMG1的捕捉位置移动一段距离D
当手动注释序列S中的至少两个图像时,这就允许经由对象注释组件420的速度估计组件422估计其他车辆的速度。这可以是简单的线性外推法,其中如果确定其他车辆在两个间隔的图像捕捉时间T的两个手动注释的图像之间已移动一段距离D
可经由UI 412对此进行细化。例如,当使用者首先用对象边界框注释图像时,系统最初将估计其他辆车的速度与自身车辆的速度相匹配。
当用户移动到序列中的下一个(或后一个)图像时,该图像将在假设其他车辆正以与该车辆相同的速度行驶的前提下自动加以注释。如果看似正确,则用户可简单地继续浏览序列。然而,如果注释错误,则用户可手动对其进行调整。如此一来,,用户此时已经准确注释两个图像,这又允许系统细化其他车辆的速度估计。当用户再次移动时,下一个图像将自动使用细化的速度估计来加以注释,因此将具有可接受的准确度(除非其他车辆的速度发生了显着变化)。
无论如何,可使用根据3D道路模型获知的道路布局知识来推断行驶方向。例如,确定其他车辆处于标记为车辆迎面而来的车道上时,可假设该车辆正在与自身车辆相反的方向上行驶。
另举一例,3D注释要素可为移动对象的3D模型(非立方体,比3D边界框更准确)。3D模型的优势在于,当投影回图像位置时,它可提供更准确的2D注释数据,诸如更严格拟合的3D边界框。3D模型也可用于生成分割掩码形式的2D注释数据,其目的是实质上跟踪图像平面中对象的轮廓。这譬如可用于实例分割训练。
对上述方式的另一种扩展源自以下认识:针对周围道路结构定位对象提供有用的信息层,用于验证经训练的对象检测器。验证是一种经训练的模型能够以可接受的准确度对训练期间未遇到的图像执行测试的过程,因此是对模型概括能力的结构化测试。
在自主驾驶的背景下,在某些特殊情况下,准确的对象检测至关重要,而在某些情况下,对象检测虽然可能有用却并不重要。一个简单示例是,对于AV而言,能够准确检测和定位道路上的其他车辆至关重要,而对其而言不甚重要的是单独检测路边驻停的车辆。
如上所述,作为上述图像处理系统的一部分,创建具有详细道路结构的道路模型,其可以例如包括单独的车道、路边的停车区、不可驾驶区(人行道、公交车道等)。如上所述,当使用该模型作为基础执行对象注释时,结果是对于任何给定的图像,均可直接推断出带注释的对象与道路结构相关的位置,例如,推断其是否在自身车道(自身车辆正行驶的车道)中,或在不同的车道中,或在停车区中,等等。
这又允许用此类信息对图像进行标志或以其他方式进行分类,即,可将标签或其他分类数据与图像相关联,以提供有关其中包含哪些对象的信息,重要的是,提供这些对象与周围道路结构的关系。这又允许出于验证目的而定位特定类型的图像。特别是,由于其他车辆相对于周围道路结构的定位方式,在捕捉背景的图像中,精确的对象检测至关重要,可识别这些图像并用于验证目的,以确保对象检测模型能够在此类关键图像上获得可接受的结果。
还提供了数个用户界面特征,以促进快速注释静态对象和动态对象。现将对此予以描述。
上述图像处理仅考虑了2D图像,而使用3D道路模型进行注释,但本技术可扩展到3D结构数据。例如,3D结构数据可以得自立体图像对、LiDAR、RADAR等或多个这类传感器模态的组合。
在上述图像处理示例的上下文中,帧采取2D图像的形式。通过扩展3D结构数据,术语“帧”也包含3D帧,并且图29中的步骤也可应用于3D帧。
在此3D上下文中,3D帧可为任何捕捉的3D结构表示,即包括定义3D空间结构的捕捉点(3D结构点),并提供在该帧中捕捉的3D结构的静态“快照”(即静态3D场景)。可以说该帧与单个时刻相对应,但未必暗示需要立即捕捉该帧或派生该帧的基础传感器数据-例如,可以由移动对象(mobile object)在LiDAR扫描中以“解扭(untwisted)”方式在短时间内(例如,约100ms)捕获LiDAR测量值,以说明移动对象的任何运动,从而形成单点云。在那种情况下,尽管采用了捕获基础传感器数据的方式,但由于这种解扭,从提供有用静态快照的意义上,单点云仍可以说与单个时刻相对应。在帧时间序列的上下文中,每个帧对应的时刻是该帧在时间序列内的时间索引(时间戳)(并且时间序列中的每个帧对应于一个不同的时刻)。
在下例中,每个帧均采用在特定时刻捕捉的RGBD(Red Green Blue Depth)图像的形式。RGBD图像具有四个通道,其中三个通道(RGB)是对“常规”图像进行编码的色彩通道(色彩分量),而第四个通道则是对图像的至少一些像素的深度值进行编码的深度通道(深度分量)。举例说明RGB,但该描述更普遍适用于具有色彩分量和深度分量的任何图像(或实际上仅具有深度分量的图像)。一般而言,可使用一个或多个色彩通道(包括灰度/单色)在任何适当的色彩空间中对图像的色彩分量进行编码。点云计算组件302将每个帧转换为点云形式,以允许在3D空间中注释该帧。更一般而言,一帧对应于一个特定时刻,并且可以引用已针对该时刻捕捉到静态“快照”结构(即静态3D场景)的任何数据集(诸如多个RGBD图像、一个或多个点云等)。因此,下文关于RGBD图像的全部描述等同适用于其他形式的帧。在注释系统300处以点云形式接收帧的情况下,不需要点云转换。尽管下例是参照从RGBD图像派生的点云来描述,但注释系统可应用于任何形态的点云,诸如单眼深度、立体深度、LiDAR、雷达等。通过合并不同传感器的输出,也可从两个或多个这样的感测模态和/或从相同或不同模态的多个传感器组件派生点云。因此,术语“帧的点云”可指代与特定时刻相对应的任何形式的点云,包括在注释计算机系统300处以点云形式接收的帧、由点云计算组件302从帧派生的点云(例如,呈一个或多个RGBD图像的形式)或合并的点云。
如上所述,尽管帧对应于特定时刻,但可以在(通常较短的)时间间隔内捕捉用于派生帧的基础数据,并在必要时进行变换以考虑时间变迁。因此,帧对应于特定时刻(例如,由时间戳表示)未必暗示基础数据已全部被同时捕获。因此,术语“帧”包含在与帧不同的时间戳接收的点云,例如,在特定的时刻(诸如捕捉图像的时间)将在100ms内捕获的激光雷达扫描“解扭”为单个点云。帧301的时间序列又可称为视频片段(应当指出,视频片段的帧不必是图像,并可以例如是点云)。
图31和图32A至图32E示出可用于在图29的方法的步骤3中有效地放置初始3D边界框的示例注释界面300的示意图。亦即,根据围绕移动对象放置的初始两个边界框可以基于以下假设外推出其他帧的边界框:例如(i)恒定(或以其他方式已知的,例如假设或测得的)速度,以及(ii)移动对象遵循道路形状(如上所述,如果可假设外部车辆的速度与自身车辆的速度相匹配,则足以手动放置单个3D边界框)。
图31示出可以经由UI 412呈现的注释界面700的示意图。
在注释界面700内,在左侧显示RGBD图像702(当前帧)的色彩分量。在右侧显示该帧的点云400的俯视图704。
此外,将3D道路模型到RGBD图像的图像平面的投影706a叠加在显示的图像702上。同样,将3D道路模型到俯视图中的投影706b显示为叠加在点云400的俯视图上。
提供可选择的选项708,用于为当前帧创建新的3D边界框。一旦完成创建,便提供可选的选项710和712,分别用于移动边界框和重新调整边界框大小。
用于移动边界框的选项710包括用于在任一方向上沿道路纵向移动边界框的选项(±R,如俯视图右侧所示),以及跨道路横向移动边界框的选项(±L)。
用于重新调整边界框大小的选项712包括用于更改边界框的宽度(w)、高度(h)和长度(1)的选项。
尽管描绘为显示的UI要素,但可替选地使用键盘快捷键、手势等提供相关联的输入。
现将描述用于放置3D注释对象的示例工作流程。应当领会,这只是注释者可利用注释界面700的注释功能的一种示例方式。
图32A示出一旦创建新的边界框800后的注释界面。边界框800放置在3D注释空间中道路高度处的初始位置,并定向为平行于该位置处的道路方向(如在3D道路模型中捕捉的方向)。为了辅助注释者,将3D边界框800投影到显示图像702的图像平面和俯视图704中。
如图32B所示,当注释者将边界框800在+R方向上沿道路移动时,边界框800会自动重新定向,以使其与道路方向保持平行。在本例中,注释者的目的是将边界框800手动拟合到图像右半部分中可见并面向图像平面的车辆。
如图32C所示,一旦注释者将边界框800沿道路移动到所需的位置后,便再将其横向(即垂直于道路方向)移动到所需的横向位置-在本例中,沿+L方向移动。
如图32D和图32E所示,注释者再适当地调整边界框800的宽度(在此情形下,以“-w”表示减小)和高度(以“+h”表示增大)。碰巧在本例中不需要长度调整,但可视需要以相同的方式调整边界框的长度。边界框800的宽度尺寸在边界框800的位置处保持与道路方向平行,而高度尺寸在边界框800的位置处保持与路面垂直。
上例假设边界框800在进行调整时仍与3D道路模型保持绑定。虽未示出,但注释界面也可以允许不受3D道路模型约束地“自由”调整,即注释者也能视需要自由移动或旋转边界框800。例如,这可能有益于注释行为有时偏离假设行为的车辆时(例如在转弯或换道期间)的情况。
以此方式针对至少一个移动对象放置3D边界框之后,图29的方法的步骤3至4可采用与上述基本相同的方式应用。假设其他车辆遵循3D道路模型的形状,则可采用相同的方式外推出3D边界框800的位置和定向。进行图32A至图32E所示类型的手动调整时,恰好在3D边界框800处可“对齐(snapped)”到3D道路模型,当在帧之间自动外推时,3D边界框800可保持对齐到3D道路模型。系统将3D边界框在帧之间沿道路纵向移动,其方式与用户手动选择可选选项710的±R选项的方式相同,但此时可通过根据车辆的速度和帧间的时间间隔确定的自动确定自动量而自动这样进行。
应当指出,就此而言,期望的3D注释数据可以是3D注释数据。亦即,就此而言,3D注释数据不仅用于确定移动对象的2D注释数据以便训练2D机器学习感知组件,而且作为替选或附加,可以使用3D注释数据来训练机器学习组件以解译3D结构数据。
如上所述,3D注释要素800可以替选地采取3D模型的形式。通过3D帧,可根据一个或多个3D帧本身导出3D模型,例如通过从属于3D模型的3D帧中选择性提取点。
举例而言,参阅英国专利申请GB 1910382.9、GB 1910395.1、GB 1910390.2和GB1910392.8,它们的全部内容通过引用归并本文。这些文献公开了在此背景下可应用的基于3D帧的对象建模技术。可在一个或多个3D帧中(例如手动地)将3D边界框放置在对象周围,然后可在该帧/每帧中从3D边界框提取点子集,以建立对象的3D模型,然后可将其应用于其他帧。基于对象沿道路的假设运动,可将该3D模型放置在其他帧中。
在上文中,道路建模组件404应用“运动恢复结构(SfM)”处理,将其应用于一系列2D图像,以便重构捕捉图像的车辆VP的3D路径(自身路径)。又将其用作外推车辆行驶经过的道路的3D表面的基础。可假设移动对象至少近似遵循相同的路面。这是基于视频序列(片段)的图像之间的2D特征匹配。
道路模型也可以采用替选方式而确定,例如点云拟合,例如自身路径可基于应用于深度图或点云的3D结构匹配和/或使用高精度卫星定位(例如GPS)。替选地,可以加载现有道路模型,并且可以视需要在现有道路模型内部对帧进行定位。
更一般而言,可用于重构自身车辆路径VP的技术示例包括加速计/IMU(内部测量单位-可以根据内部传感器数据重构路径)、视觉测距法、LIDAR测距法、RADAR测距法、车轮编码器等。
前述参考文献使用从车辆本身路径外推出的3D道路模型来有效地生成2D注释数据,以在原始图像中注释道路结构。在当前上下文中,将该技术扩展到,通过假设其他道路使用者总体上随时间推移遵循道路形状,允许跨视频片段中的多个帧将3D边界框有效地围绕道路上的其他对象放置,诸如其他车辆、骑行者等。
参考文献
5.G·J·Brostow,J·Fauqueur,R·Cipolla:《Semantic object classes invideo:A high-definition ground truth database》Pattern Recognition Letters,30(2)(2009)88-97
6.M·Cordts,M·Omran,S·Ramos,T·Rehfeld,M·Enzweiler,R·Benenson,U·Pranke,S·Roth,B·Schiele:《The cityscapes dataset for semantic urban sceneunderstanding》CVPR(2016)
7.G·Neuhold,T·Ollmann,S·R·Bulo,P·Kontschieder:《The mapillaryvistas dataset for semantic understanding of street scenes》Proceedings of theInternational Conference on Computer Vision(ICCV),意大利威尼斯(2017)22-29
14.G·J·Brostow,J·Shotton,J·Fauqueur,R·Cipolla:《Segmentation andrecognition using structure from motion point clouds》European conference oncomputer vision,Springer,施普林格出版社(2008)44-57
15.S·Sengupta,P·Sturgess,P·H·S·Torr,等人:《Automatic dense visualsemantic mapping from street-1evel imagery》Intelligent Robots and Systems(IROS),2012年IEEE/RSJ国际会议,IEEE(2012)857-862
16.T·Scharwachter,M·Enzweiler,U·Franke,S·Roth:《Efficient multi-cue scene segmentation》German Conference on Pattern Recognition,施普林格出版社(2013)
17.J·Fritsch,T·Kuehnl,A·Geiger:《A new performance measure andevaluation benchmark for road detection algorithms》16th International IEEEConference on Intelligent Transportation Systems(ITSC2013),IEEE(2013)1693-1700
18.M·Aly:《Real time detection of lane markers in urban streets》IEEEIntelligent 675 676,Vehicles Symposium,Proceedings,IEEE(2008)7-12
19.TuSimple:《Lane Detection Challenge(Dataset)》http://benchmark.tusimple.ai(2017)
27.D·Barnes,W·Maddern,I·Posner:《Find Your Own Way:Weakly-Supervised Segmentation of Path Proposals for Urban Autonomy》ICRA(2017)
28.Mapillary:《OpenSfM(Software)》https://github.com/mapillary/OpenSfM(2014)
29.V·Badrinarayanan,A·Kendall,R·Cipolla:Segnet:《A deep convolu-f)″tional encoder-decoder architecture for image segmentation》arXiv预印本,arXiv:1511.00561(2015)
32.K·He,G·Gkioxari,P·Dollar,R·B·Girshick:MaskR-CNN,CoRR abs/1703.06870(2017)
33.B·D·Brabandere,D·Neven,L·V·Gool:《Semantic instancesegmentation with a aki discriminative loss function》CoRR abs/1708.02551(2017)
34.S·Li,B·Seybold,A·Vorobyov,A·Fathi,Q·Huang,C·C·J·Kuo:《Instance embedding transfer to unsupervised video object segmentation》(2018)
35.A·Fathi,Z·Wojma,V·Rathod,P·Wang,H·O·Song,S·Guadarrama,K·P·Murphy:《Semantic instance segmentation via deep metric learning》CoRR713abs/1703.10277(2017)
36.S·Kong,O·Fowlkes:《Recurrent pixel embedding for instancegrouping》(2017)
37.D·Comaniciu,P·Meer:《Mean shift:A robust approach toward featurespace analysis》IEEE Trams.Pattern Amal.Mach.Intell.24(5)(2002年5月)603-61
附件A
- 注释数据库索引结构、快速注释遗传变异的方法及系统
- 注释方法、注释装置、注释程序以及识别系统