一种浏览器页面数据采集方法、终端设备及存储介质
文献发布时间:2023-06-19 10:58:46
技术领域
本发明涉及数据采集领域,尤其涉及一种浏览器页面数据采集方法、终端设备及存储介质。
背景技术
在现有的网页数据爬虫技术和方案中,主要的技术难点有几类,一类是反爬策略,如频繁抓取IP侦测被禁止访问,一类是模板不定期变动,一类是URL抓取失败。针对上述技术难点有多种应对策略,针对反爬策略可以使用浏览器的形式访问;对于模板定期变动可以设定多套模板规则和策略;对于IP侦测被禁用,可以购买代理IP库,或者部署多个应用分别抓取,降低单个节点访问频率,设定页面访问间隔时间。但上述策略实现的方式复杂,且效果不佳。
随着浏览器技术和JS(JavaScript,一种应用广泛的即时编译型的高级编程语言)的发展,各种反爬技术层出不穷,其中前端反爬就是第一道门槛。网络爬虫的一般作法:基于Socket通讯编写爬虫;基于HttpURLConnection类编写爬虫;基于apache的HttpClient包编写爬虫;基于phantomjs之类的无头(无界面)浏览器;基于Selenium之类的有头(有界面)浏览器。上述方法如果被对方侦测并阻挡时,都无法百分百模拟浏览器的行为特征。
发明内容
为了解决上述问题,本发明提出了一种浏览器页面数据采集方法、终端设备及存储介质。
具体方案如下:
一种浏览器页面数据采集方法,包括以下步骤:
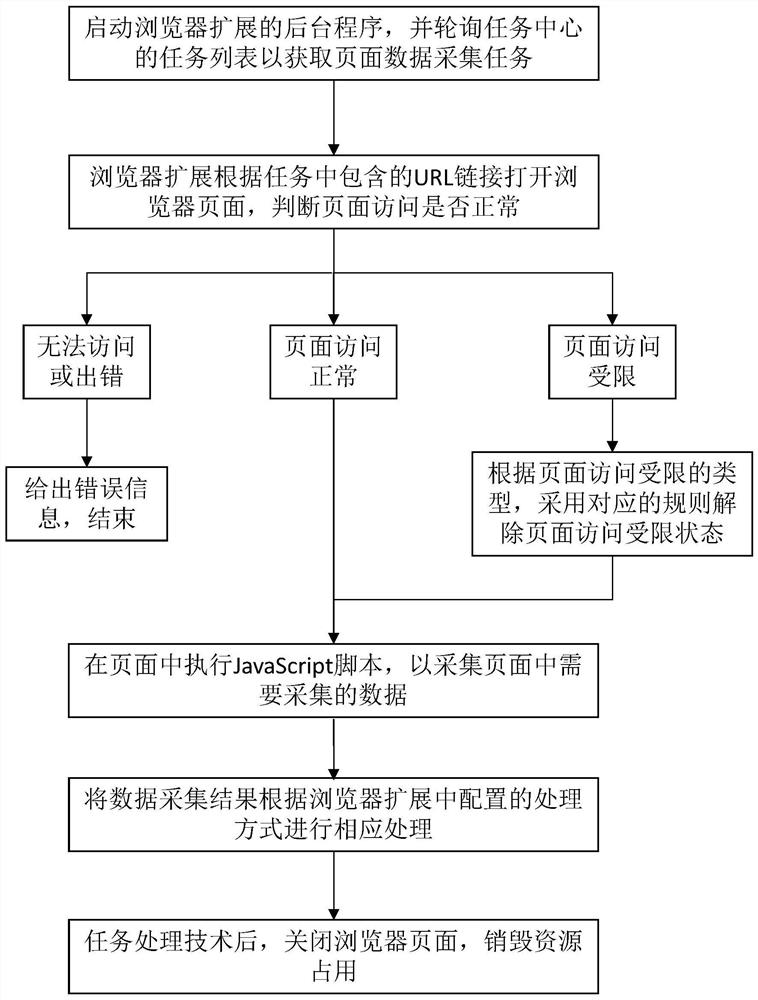
S1:启动浏览器扩展的后台程序,并轮询任务中心的任务列表以获取页面数据采集任务;
S2:浏览器扩展根据任务中包含的URL链接打开浏览器页面,判断页面访问是否正常,当页面访问正常时,进入S4;当页面无法访问或访问出错时,给出错误信息,结束;当页面访问受限时,进入S3;
S3:根据页面访问受限的类型,采用对应的规则解除页面访问受限状态后,正常访问页面,进入S4;
S4:在页面中执行JavaScript脚本,以采集页面中需要采集的数据;
S5:将数据采集结果根据浏览器扩展中配置的处理方式进行相应处理。
进一步的,步骤S1在打开浏览器扩展的后台程序后,还包括对浏览器扩展进行配置,包括:
(1)配置每台服务器上同时打开的标签页小于1000个;
(2)配置自动识别并去掉页面中的干扰信息;
(3)配置利用浏览器API控制浏览器开启和关闭目标网页;
(4)配置利用浏览器API和JavaScript脚本,进行页面操作;
(5)配置数据采集结果的处理方式。
进一步的,步骤S3中解除页面访问受限状态的规则包括:
当页面访问受限类型为IP被限定时,降低网页的访问频率,或构建IP代理池,更换IP进行访问;
当页面访问受限类型为需要验证码时,采用绕过验证码、验证码图像自动识别或手动输入的方式;
当页面访问受限类型为需要登陆Cookie时,预先注册页面需要的账号,并在浏览器扩展中进行配置,在需要登陆Cookie时,根据配置自动模拟登陆或手动输入账号登陆。
进一步的,步骤S4中还包括将采集的文本、表格数据、图片链接和视频链接保存为JSON格式的文本数据,将采集的图片和视频保存为图片和视频的原始格式。
进一步的,步骤S4采集页面中需要采集的数据的过程包括:自动识别页面的分页方式,根据识别到的分页方式自动点击并打开下一页页面;通过模拟鼠标滚动以获取每一页中更多数据。
进一步的,步骤S4中当采集的数据中包括链接时,提取链接生成新的任务后,发送到任务中心,任务中心对接收到任务进行排重后,将其添加至任务列表内。
进一步的,步骤S5中数据采集结果的处理方式包括:发送至服务器并保存、导出和打印。
进一步的,还包括S6:任务处理技术后,关闭浏览器页面,销毁资源占用。
一种浏览器页面数据采集终端设备,包括处理器、存储器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现本发明实施例上述的方法的步骤。
一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现本发明实施例上述的方法的步骤。
本发明采用如上技术方案,通过浏览器扩展来采集互联网数据,在先天上克服了各类爬虫工具的弊端,百分百模拟浏览器请求。
附图说明
图1所示为本发明实施例一的流程图。
具体实施方式
为进一步说明各实施例,本发明提供有附图。这些附图为本发明揭露内容的一部分,其主要用以说明实施例,并可配合说明书的相关描述来解释实施例的运作原理。配合参考这些内容,本领域普通技术人员应能理解其他可能的实施方式以及本发明的优点。
现结合附图和具体实施方式对本发明进一步说明。
实施例一:
本发明实施例提供了一种浏览器页面数据采集方法,如图1所示,所述方法包括以下步骤:
S1:启动浏览器扩展的后台程序,并轮询后台服务器以获取页面数据采集任务。
任务的数据格式如下:
浏览器扩展具有多种配置选项,在打开浏览器扩展的后台程序后,还包括对浏览器扩展进行配置,包括:
(1)配置每台服务器上同时打开的标签页小于1000个。
浏览器扩展可以同时打开和关闭多个标签页,为了保证系统稳定运行在单台服务器上,该实施例限制同时打开标签页小于1000个。
(2)配置自动识别并去掉页面中的干扰信息。
干扰信息包括广告,推广等,通过去掉干扰信息,可以避免采集到异常数据。
(3)配置利用浏览器API控制浏览器开启和关闭目标网页。
(4)配置利用浏览器API和JavaScript脚本,进行页面操作。
页面操作包括点击、滚动等。
(5)配置数据采集结果的处理方式。
数据采集结果的处理方式包括发送至服务器并保存、导出和打印等。
S2:浏览器扩展根据任务中包含的URL链接打开浏览器页面,判断页面访问是否正常,当页面访问正常时,进入S4;当页面无法访问或访问出错时,给出错误信息,结束;当页面访问受限时,进入S3。
页面访问受限的类型包括IP被限定、需要验证码、需要登陆Cookie等。
S3:根据页面访问受限的类型,采用对应的规则解除页面访问受限状态后,正常访问页面,进入S4。
该实施例中解除页面访问受限状态的规则包括:
(1)当页面访问受限类型为IP被限定时,降低网页的访问频率,或构建IP代理池,更换IP进行访问.
(2)当页面访问受限类型为需要验证码时,采用绕过验证码、验证码图像自动识别或手动输入的方式。
(3)当页面访问受限类型为需要登陆Cookie时,预先注册页面需要的账号,并在浏览器扩展中进行配置,在需要登陆Cookie时,根据配置自动模拟登陆或手动输入账号登陆。
S4:在页面中执行JavaScript脚本,以采集页面中需要采集的数据。
JavaScript脚本有两种来源,一种是用户自定义,存储于任务中的match-format字段中;一种是智能识别,如列表数据识别
- 一种浏览器页面数据采集方法、终端设备及存储介质
- 一种页面数据采集方法、系统、终端及存储介质