用于在存储器阵列内执行视频处理矩阵运算的方法和设备
文献发布时间:2023-06-19 11:03:41
本申请要求于2019年11月20日申请的题为“用于在存储器阵列内执行视频处理矩阵的方法和设备(METHODS AND APPARATUS FOR PERFORMING VIDEO PROCESSING MATRIXOPERATIONS WITHIN A MEMORY ARRAY)”的第16/689,981号美国专利申请案的优先权,所述申请案的全部内容以引用的方式并入本文中。
本申请案的主题还与以下各者相关:于2018年6月7日申请的题为“形成于存储器单元阵列中的图像处理器(AN IMAGE PROCESSOR FORMED IN AN ARRAY OF MEMORYCELLS)”的共同拥有和共同未决的第16/002,644号美国专利申请案;于2018年12月5日申请的题为“用于激励参与雾网络的方法和设备(METHODS AND APPARATUS FOR INCENTIVIZINGPARTICIPATION IN FOG NETWORKS)”的第16/211,029号美国专利申请案;于2019年1月8日申请的题为“用于基于惯例的雾联网的方法和设备(METHODS AND APPARATUS FOR ROUTINEBASED FOG NETWORKING)”的第16/242,960号申请案;于2019年2月14日申请的题为“用于特征化存储器装置的方法和设备(METHODS AND APPARATUS FOR CHARACTERIZING MEMORYDEVICES)”的第16/276,461号申请案;于2019年2月14日申请的题为“用于检查特征化存储器搜索的结果的方法和设备(METHODS AND APPARATUS FOR CHECKING THE RESULTS OFCHARACTERIZED MEMORY SEARCHES)”的第16/276,471号申请案;于2019年2月14日申请的题为“用于保持特征化存储器装置的方法和设备(Methods and Apparatus for MaintainingCharacterized Memory Devices)”的第16/276,489号申请案,前述申请案中的每一个的全部内容以引用的方式并入本文中。
技术领域
以下一般涉及数据处理和装置架构的领域。具体地,在一个示范性方面,公开了一种处理器-存储器架构,其将存储器阵列转换为矩阵结构以用于矩阵变换并在其中执行视频处理矩阵运算。
背景技术
存储器装置被广泛用来在如计算机、无线通信装置、相机、数字显示器等各种电子装置中存储信息。信息通过对存储器装置的不同状态进行编程来存储。例如,二进制装置具有两个状态,通常由逻辑“1”或逻辑“0”表示。为存取所存储的信息,存储器装置可以读取(或感测)存储器装置中的所存储的状态。为存储信息,存储器装置可以将所述状态写入(或编程)到存储器装置中。所谓的易失性存储器装置可能需要电力来维持此存储的信息,而非易失性存储器装置甚至在存储器装置本身例如已进行电力循环之后仍可持久地存储信息。不同的存储器制造方法和构造实现不同的能力。例如,动态随机存取存储器(DRAM)廉价地提供高密度易失性存储。初期的研究是针对电阻式随机存取存储器(ReRAM),其具有类似于DRAM的非易失性性能。
处理器装置通常结合存储器装置使用以执行无数不同的任务和功能。在操作期间,处理器执行来自存储器的计算机可读指令(通常被称为“软件”)。计算机可读指令定义基本算术、逻辑、控制、输入/输出(I/O)操作等。如计算领域中众所周知的,相对基本的计算机可读指令在按顺序组合时可执行各种复杂行为。处理器倾向于强调不同于存储器装置的电路构造和制造技术。例如,处理性能一般与时钟速率有关,因此大多数处理器制造方法和构造强调非常高速率的晶体管开关结构等。
随着时间的推移,处理器和存储器的速度和功耗都增加了。典型地,这些改进是由于装置尺寸缩小的结果,因为电信令在物理上受到传输媒体的电介质和距离的限制。如前所述,大多数处理器和存储器是用不同的制造材料和技术制造的。因此,即使处理器和存储器继续改进,处理器与存储器之间的物理接口是整个系统性能的“瓶颈”。更直接地,无论处理器或存储器能够独立运行多快,处理器和存储器的组合系统的性能都受限于接口所允许的传输速率。这种现象具有几个常见的名称,例如“处理器-存储器壁”、“冯诺依曼瓶颈效应”等。
视频处理(例如,压缩)方法是已知需要存储器与处理器之间的频繁通信的一类处理应用。因此,传统视频处理的速度特别受到上述处理器-存储器接口限制的影响。因此,明显需要改进的设备和方法以减少这些限制的影响,包含在这种视频处理应用中。
发明内容
本发明尤其提供了用于将存储器阵列转换成矩阵结构以用于矩阵变换并在其中执行矩阵运算的方法和设备。
在本公开的一个方面,公开了一种非暂时性计算机可读媒体。在一个示范性实施例中,所述非暂时性计算机可读媒体包含:存储器单元阵列,其中所述存储器单元阵列的每一存储器单元经配置以将数字值作为模拟值存储在模拟媒体中;存储器感测组件,其中所述存储器感测组件经配置以读取第一存储器单元的模拟值作为第一数字值;以及逻辑。在一个实施例中,存储器单元阵列包含至少两个存储器单元子阵列的堆叠。在一个变体中,至少一些存储单元子阵列经配置以彼此并行运行。
在一个实施方案中,至少一些存储器单元子阵列连接到单个存储器感测组件。
在另一实施方案中,个别存储器单元子阵列连接到个别存储器感测组件。
在另一变体中,存储器单元经配置以将模拟值作为阻抗或电导存储在存储器单元中。
在另一示范性实施例中,所述逻辑进一步经配置以:接收主观操作码;基于所述矩阵变换操作码使所述存储器单元阵列作为矩阵乘法单元(MMU)操作;其中,MMU的每个存储器单元根据矩阵变换操作码和矩阵变换操作数修改模拟媒体中的模拟值;配置所述存储器感测组件以根据所述矩阵变换操作码和所述矩阵变换操作数将所述第一存储器单元的模拟值转换为第二数字值;并且响应于将矩阵变换操作数读取到MMU中,基于第二数字值写入矩阵变换结果。
在一个变体中,矩阵变换操作码指示MMU的大小。在一个这样的变体中,矩阵变换操作码对应于频域变换运算。在一个实施方案中,频域变换运算是DCT(离散余弦变换)运算,并且MMU的大小的至少一些方面对应于DCT运算的大小(例如,MMU的大小可以对应于DC运算的大小,或其倍数或分数)。在一个示范性变体中,频域变换运算跨越至少一个其它MMU。
在又一变体中,矩阵变换操作数包含从像素图像块的像素值导出的向量。在一个实施方案中,像素值对应于红色、绿色、蓝色、亮度(Y)、色度红(Cr)或色度蓝(Cr)像素值。在一个示范性配置中,像素图像块是NxN图像块(例如,8x8像素、16x16像素等)。
在一个变体中,矩阵变换操作码识别对应于一或多个存储器单元的一或多个模拟值。在一个这样的变体中,对应于一或多个存储器单元的一或多个模拟值被存储在查找表(LUT)数据结构中。在一个实施方案中,一或多个模拟值包含DCT变换矩阵值。
在一个变体中,MMU的每个存储器单元包括电阻式随机存取存储器(ReRAM)单元;以及MMU的每个存储器单元根据矩阵变换操作码和矩阵变换操作数使模拟媒体中的模拟值相乘。
在一个变体中,MMU的每个存储器单元进一步将模拟媒体中的模拟值与先前的模拟值进行累加。
在一个变体中,第一数字值由二(2)的第一基数表征;并且第二数字值由大于二(2)的第二基数表征。
在本公开的一个方面,公开了一种装置。在一个实施例中,所述装置包含耦合到非暂时性计算机可读媒体的处理器;其中所述非暂时性计算机可读媒体包含一或多个指令,所述指令在由所述处理器执行时致使所述处理器:将矩阵变换操作码和矩阵变换操作数写入到所述非暂时性计算机可读媒体;其中所述矩阵变换操作码致使所述非暂时性计算机可读媒体将存储器单元阵列作为矩阵结构操作;其中矩阵变换操作数修改矩阵结构的一或多个模拟值;并且从所述矩阵结构中读取矩阵变换结果。
在一个变体中,所述非暂时性计算机可读媒体还包括一或多个指令,所述指令在由所述处理器执行时致使所述处理器:捕获包括一或多个所捕获的颜色值的图像数据;并且其中矩阵变换操作数包括一或多个捕获的颜色值,并且矩阵变换结果包括一或多个移位的颜色值。
在一个变体中,所述非暂时性计算机可读媒体进一步包括一或多个指令,所述指令在由所述处理器执行时致使所述处理器:接收包括一或多个图像块的视频数据;其中矩阵变换操作数包括一或多个图像块,并且矩阵变换结果包括一或多个频域图像系数;并且其中所述矩阵结构的一或多个模拟值随时间累加来自视频数据的一或多个频域图像系数。在一个实施方案中,一或多个频域图像系数包括DCT图像系数。
在一个变体中,矩阵变换操作码使得非暂时性计算机可读媒体将另一存储器单元阵列作为另一矩阵结构操作;并且在逻辑上将与所述矩阵结构相关联的矩阵变换结果和与另一矩阵结构相关联的另一矩阵变换结果进行组合。
在一个变体中,矩阵结构的一或多个模拟值被存储在查找表(LUT)数据结构中。在一个变体中,矩阵结构的至少一些值被存储在未被配置为矩阵结构的存储器单元的一部分中。
在本公开的一个方面,公开了一种执行变换矩阵运算的方法。在一个实施例中,所述方法包含:接收矩阵变换操作码;基于所述矩阵变换操作码将存储器的存储器单元阵列配置成矩阵结构;基于所述矩阵变换操作码配置存储器感测组件;以及响应于将矩阵变换操作数读取到矩阵结构中,写入来自存储器感测组件的矩阵变换结果。在一个变体中,配置矩阵结构包含用DCT变换矩阵的值配置存储器单元阵列,并且矩阵变换结果包含DCT图像系数矩阵。在一个实施方案中,矩阵结构配置有两个矩阵的值:正DCT变换矩阵值的矩阵和负DCT变换矩阵值的矩阵。在一个变体中,多个存储器单元阵列配置有DCT变换矩阵的值。
在一个变体中,配置存储器单元阵列包含连接对应于与矩阵结构相关联的行维度和列维度的多个字线和多个位线。
在一个变体中,所述方法还包含从矩阵变换操作码确定行维度和列维度。
在一个变体中,配置存储器单元阵列包含基于查找表(LUT)数据结构设置矩阵结构的一或多个模拟值。
在一个变体中,所述方法包含基于矩阵变换操作码识别来自LUT数据结构的条目。
在一个变体中,配置存储器感测组件使得矩阵变换结果具有大于二(2)的基数。
在一个方面中,公开了一种经配置以将存储器装置配置成矩阵结构的设备。在一个实施例中,所述设备包含:存储器;处理器,其经配置以存取所述存储器;预处理器逻辑,其经配置以分配一或多个存储器部分以用作矩阵结构。
在本公开的另一方面,公开了一种计算机图像处理装置设备,其经配置以将存储器动态配置成矩阵结构。在一个实施例中,计算机图像处理装置包含:相机接口;与所述相机接口进行数据通信的数字处理器设备;以及存储器,其与所述数字处理器设备进行数据通信并且包含至少一个计算机程序。
在本公开的另一方面,公开了一种计算机视频处理装置设备,其经配置以将存储器动态地配置成矩阵结构。在一个实施例中,计算机视频处理装置包含:相机接口;与所述相机接口进行数据通信的数字处理器设备;以及存储器,其与所述数字处理器设备进行数据通信并且包含至少一个计算机程序。
在本公开的另一方面,公开了一种计算机无线存取节点设备,其经配置以将存储器动态地配置成矩阵结构。在一个实施例中,计算机无线存取节点包含:无线接口,其经配置以传输和接收频谱部分中的RF波形;与所述无线接口进行数据通信的数字处理器设备;以及存储器,其与所述数字处理器设备进行数据通信并且包含至少一个计算机程序。
在本公开的附加方面中,描述了计算机可读设备。在一个实施例中,所述设备包含存储媒体,其经配置以将一或多个计算机程序存储在特征化存储器内或与所述特征化存储器结合。在一个实施例中,所述设备包含在计算机控制器装置上的程序存储器或HDD或SDD。在另一个实施例中,所述设备包含在计算机存取节点上的程序存储器、HDD或SSD。
当根据本文提供的公开内容考虑时,这些和其它方面将变得显而易见。
附图说明
图1A是处理器-存储器架构的图和相关矩阵运算的图形描绘。
图1B是处理器-PIM架构的图和相关矩阵运算的图形描绘。
图2是根据本公开的各种原理的存储器装置的一个示范性实施方案的逻辑框图。
图3是第一存储器装置配置和第二存储器装置配置的示范性并排说明。
图4是根据本公开的原理执行的半矩阵运算的图形描绘。
图5A是根据本发明的各方面的经配置以用于DCT矩阵运算的存储器装置的第一实施例的框图。
图5B是根据本发明的各方面的经配置以用于DCT矩阵运算的存储器装置的第二实施例的框图。
图6A是根据本发明的各方面的经配置以用于DCT矩阵运算的存储器装置的第三实施例的框图。
图6B是根据本发明的各方面的经配置以用于DCT矩阵运算的存储器装置的第四实施例的框图。
图7A是处理器-存储器架构的一个示范性实施方案的逻辑框图。
图7B是示出根据本公开的原理执行一组矩阵运算的一个示范性实施例的梯形图。
图7C是示出根据本公开的原理执行一组矩阵运算的另一示范性实施例的梯形图。
图8是将存储器阵列转换为矩阵结构并在其中执行矩阵运算的一个示范性方法的逻辑流程图。
图8A是使用矩阵结构执行DCT矩阵运算的一个示范性方法的逻辑流程图。
所有图式2019美光科技公司保留全部版权。
具体实施方式
现在参照附图,其中相同数字指代全文中的相似部分。
如在本文中所使用的,术语“应用”(或“app”)通常但不限于实施特定功能或主题的可执行的软件单元。应用的主题在任何数量的规范和功能(如点播内容管理、电子商务交易、经纪交易、家庭娱乐、计算器等)上有很大不同,并且一个应用可以具有多于一个的主题。可执行的软件单元通常在预定环境中运行;例如,所述单元可以包含在操作系统环境中运行的可下载应用程序。
如本文中所使用的,术语“计算机程序”或“软件”意味着包含执行功能的任何序列或人或机器可识别的步骤。这样的程序实际上可以以任何编程语言或环境呈现,包含例如C/C++、Fortran、COBOL、PASCAL、汇编语言、标记语言(例如,HTML、SGML、XML、VoXML)等,以及面向对象的环境,例如公共对象请求代理体系结构(CORBA)、Java
如本文中所使用的,术语“分散的”或“分布式的”不限于能够执行彼此的数据通信的多个计算机装置的配置或网络架构,而不是要求给定装置通过如服务器装置的指定(例如,中央)网络实体进行通信。例如,分散式网络使得能够在组成网络的多个UE(例如,无线用户装置)之间进行直接对等数据通信。
如本文中所使用的,术语“分布式单元”(DU)不限于无线网络基础设施内的分布式逻辑节点。例如,DU可以体现为由上述gNB CU控制的下一代节点B(gNB)DU(gNB-DU)。一个gNB-DU可以支持一或多个小区;给定小区仅由一个gNB-DU支持。
如本文中所使用的,术语“因特网(Internet)”和“因特网(internet)”可互换地用来指包含但不限于因特网的跨网。其它常见的实例包含但不限于:外部服务器的网络、“云”实体(例如对装置而言不是本地的存储器或存储装置,通常经由网络连接在任何时间可存取的存储装置等)、服务节点、存取点、控制器装置、客户端装置等。驻留在回程(backhaul)、前传(fronthaul)、交叉回程(crosshaul)中的5G服务核心网络和网络组件(例如,DU、CU、gNB、小型小区或毫微微小区、具有5G能力的外部节点),或其邻近住宅、企业和其它占用的区域的“边缘”可以包含在“因特网”中。
如本文中所使用的,术语“存储器”包含适于存储数字数据的任何类型的集成电路或其它存储装置,包含但不限于随机存取存储器(RAM)、伪静态RAM(PSRAM)、动态RAM(DRAM)、包含双倍数据速率(DDR)类存储器和图形DDR(GDDR)及其变体的同步动态RAM(SDRAM)、铁电RAM(FeRAM)、磁RAM(MRAM)、电阻式RAM(ReRAM)、只读存储器(ROM)、可编程ROM(PROM)、电可擦除PROM(EEPROM或E
如本文中所使用的,术语“微处理器”和“处理器”或“数字处理器”通常意味着包含所有类型的数字处理装置,所述数字处理装置包含但不限于数字信号处理器(DSP)、精简指令集计算机(RISC)、通用处理器(GPP)、微处理器、门阵列(例如FPGA)、PLD、可重新配置的计算机结构(RCF)、阵列处理器、安全微处理器和专用集成电路(ASIC)。这样的数字处理器可以包含在单个整体IC管芯上,或者分布在多个部件上。
如本文中所使用的,术语“服务器”指的是任何计算机组件、系统或实体,而不管适于向计算机网络上的一或多个其它装置或实体提供数据、文件、应用、内容或其它服务的形式。
如本文中所使用的,术语“存储器”不限于计算机硬盘驱动器(例如,硬盘驱动器(HDD)、固态驱动器(SDD))、闪存驱动器、DVR装置、存储器、RAID装置或阵列、光学介质(例如,CD-ROM、激光盘、蓝光等),或能够存储内容或其它信息的任何其它装置或媒体,包含能够在没有电源的情况下维持数据的半导体装置(例如,本文中描述为存储器的那些装置)。用于存储的存储器装置的常见实例包含但不限于:ReRAM、DRAM(例如,SDRAM、DDR SDRAM、DDR2 SDRAM、DDR3 SDRAM、DDR4 SDRAM、GDDR、RLDRAM、LPDRAM等)、DRAM模块(例如,RDIMM、VLP RDIMM、UDIMM、VLP UDIMM、SODIMM、SORDIMM、Mini-DIMM、VLP Mini-DIMM、LRDIMM、NVDIMM等)、受管理NAND、NAND快闪存储器(例如,SLC NAND、MLC NAND、TLS NAND、串行NAND、3D NAND等)、NOR快闪存储器(例如,并行NOR、串行NOR等)、多芯片封装、混合存储器立方体、存储器卡、固态存储器(SSS),以及任意数量的其它存储器装置。
如本文中所使用的,术语“Wi-Fi”不限于并且当适用时,是指以下各者的任何变体:IEEE标准802.11或包含802.11a/b/g/n/s/v/ac/ad/av或802.11-2012/2013、802.11-2016的相关标准,以及Wi-Fi Direct(尤其包含“Wi-Fi对等(P2P)规范”,通过引用的方式将其全部内容并入本文中)。
如本文中所使用的,术语“无线”意味着任何无线信号、数据、通信或其它接口,包含但不限于Wi-Fi、蓝牙/BLE、3G/4G/4.5G/5G/B5G(3GPP/3GPP2)、HSDPA/HSUPA、TDMA、CBRS、CDMA(例如,IS-95A、WCDMA等)、FHSS、DSSS、GSM、PAN/802.15、WiMAX(802.16)、802.20、
概述
在处理器-存储器架构在大数据集上重复类似操作的情况下,上述“处理器-存储器壁”性能限制可能非常严重。在这种情况下,处理器-存储器架构必须为数据集的每个元素单独地反复传送、操作和存储。例如,4x4(十六(16)个元素)的矩阵乘法需要2x2(四(4)个元素)的矩阵乘法的四(4)倍。换句话说,矩阵运算根据矩阵大小指数地缩放。
矩阵变换通常用于许多不同的应用中,并且可能占用不成比例的处理量和/或存储器带宽。例如,许多图像信号处理(ISP)技术通常将矩阵变换用于例如色彩插值、白平衡、色彩校正、色彩转换等。许多通信技术采用快速傅立叶变换(FFT)和矩阵乘法来进行波束成形和/或大规模多输入多输出(MIMO)信道处理。
特别地,视频、音频和图像压缩通常使用离散余弦变换(DCT)来识别可以以最小保真度损失去除的视频图像数据。例如,在JPEG、MP3、AAC、MPEG、H.264/AVC、H.265/HEVC图像/图像/音频标准以及HDR(高动态范围)应用中使用基于DCT的压缩。基于DCT的图像/视频压缩涉及几个矩阵乘法运算。本公开的各种实施例针对将存储器阵列转换成用于矩阵变换的矩阵结构以及在其中执行视频处理矩阵运算。
本文所描述的示范性实施例在包含矩阵结构和矩阵乘法单元(MMU)的存储器装置内执行矩阵变换。在一个示范性实施例中,矩阵结构使用电阻元件的“纵横”构造。每个电阻元件存储表示相应矩阵系数值的阻抗水平。纵横连接可以用将输入向量表示为模拟电压的电信号来驱动。所得到的信号可以由MMU从模拟电压转换成数字值,以产生向量-矩阵乘积。在某些情况下,MMU还可以在数字域内执行各种其它逻辑运算。
与迭代矩阵的每个元素来计算元素值的现有解决方案不同,以下描述的纵横矩阵结构“以原子方式”(即在单个处理循环中)计算矩阵的多个元素。例如,可以并行计算向量-矩阵乘积的至少一部分。基于矩阵结构的计算的“原子性”相对于迭代替换方案产生显著的处理改进。特别地,当迭代技术随矩阵大小增长时,原子矩阵结构计算与矩阵维度无关。换句话说,NxN向量-矩阵乘积可以在单个原子指令中完成。
本公开的各种实施例在内部导出和/或使用矩阵系数值以进一步最小化接口事务。如本文中更详细描述的,许多有用的矩阵变换可以由“结构上定义的维度”表征并且用“结构上定义的系数”执行。结构定义是指为特定矩阵结构(例如,矩阵的秩和/或大小)定义的矩阵计算的那些方面;换句话说,矩阵系数可以从矩阵结构中推断出来,而不需要通过处理器-存储器接口明确地提供。例如,如下文更详细描述的,DCT变换矩阵值(即,DCT“旋转因子”)是矩阵大小的函数。用于快速傅立叶变换(FFT)的“旋转因子”也是矩阵大小的函数,而ISP滤波和/或大规模MIMO信道编码技术可以使用例如预定义的矩阵和/或具有已知结构和加权的矩阵的码本。
简而言之,组件制造上的实际限制限制了个别存储器装置内的每一元件的能力。例如,大多数存储器阵列仅经设计以辨别两(2)个状态(逻辑“1”、逻辑“0”)。虽然现有的存储器感测组件可以被扩展以辨别更高的精度级别(例如,四(4)个状态、八(8)个状态等),但是增加存储器感测组件的精度对于支持通常在例如视频压缩、数学变换等中使用的大变换所需的精度可能是不切实际的。
为了这些目的,本公开的各种实施例在逻辑上组合一或多个矩阵结构和/或MMU,以提供比其它方式可能更高的精度和/或处理复杂度。在一个这样的实施例中,第一矩阵结构和/或MMU可用于计算正向量-矩阵乘积,而第二矩阵结构和/或MMU可用于计算负向量-矩阵乘积。可以对正负向量-矩阵乘积求和以确定净向量-矩阵乘积。
在另一个这样的实施例中,可以使用多个简单矩阵变换来实现更大的矩阵变换。例如,为了执行DCT运算,可以将两个NxN矩阵的矩阵-矩阵乘法分解为N个单独的矩阵-向量乘法(即,NxN矩阵乘以N个大小的向量)。处理矩阵结构中的DCT运算的各个部分还可以根据许多设计考虑而被排序或并行化。在给定本公开的内容的情况下,可以用等效成功(例如,分解、公共矩阵乘法等)来替换逻辑矩阵运算的其它实例。
某些应用可通过在不使用时关闭系统组件来节省大量功率。例如,视频压缩可受益于视频消隐间隔期间(当没有视频数据活动时)的“休眠”等。然而,休眠程序通常需要处理器和/或存储器来将数据从操作易失性存储器传送到非易失性存储存储器,使得数据在断电时不丢失。还需要唤醒过程来从非易失性存储器中检索存储的信息。在存储器之间来回传送数据是处理器-存储器带宽的低效使用。因此,本文中所公开的各种实施例利用了矩阵结构的“非易失性”特性。在这样的实施例中,即使当存储器没有电源时,矩阵结构也可以保持其矩阵系数值。更直接地,矩阵结构的非易失性特性使得处理器和存储器能够转换到体眠/低功率模式或执行其它任务而不将数据从易失性存储器混编到非易失性存储器,反之亦然。
在给定本公开的内容的情况下,前述内容的各种其它组合和/或变体将容易地被本领域普通技术人员理解。
示范性实施例的详细描述
现在详细描述本公开的设备和方法的示范性实施例。虽然在先前特定的处理器和/或存储器配置的上下文中描述了这些示范性实施例,但是本公开的一般原理和优点可以扩展到其它类型的处理器和/或存储器技术,因此以下本质上仅是示范性的。
还将理解,虽然通常在消费者装置(在相机装置、视频编解码器、蜂窝电话和/或网络基站内)的上下文中描述,但是本公开可以容易地适用于其它类型的装置,包含例如服务器装置、物联网(IoT)装置,和/或用于个人、公司或甚至政府用途,例如在如美国国防部等的被禁止的“现任”用户之外的所述用途。其它应用也是可能的。
参考附图和下面给出的示范性实施例的详细描述,本领域普通技术人员将立即认识到本公开的其它特征和优点。
处理器存储器架构-
图1A示出了用于示出矩阵运算的一个公共处理器-存储器架构100。如图1A所示,处理器102通过接口106与存储器104连接。在说明性实例中,处理器将输入向量a的元素与矩阵M相乘以计算向量-矩阵乘积b。在数学上,输入向量a被视为具有等于矩阵M中的行数的多个元素的单列矩阵。
为了计算向量-矩阵乘积b
在第二次迭代期间,读取输入向量a
虽然未明确示出,但也执行上述迭代过程以生成向量-矩阵乘积b
尽管前述讨论是在向量-矩阵乘积的竞赛中提出的,但是本领域普通技术人员将容易理解,矩阵-矩阵乘积可以作为一系列向量-矩阵乘积来执行。例如,计算对应于输入向量的第一单列矩阵的第一向量-矩阵乘积,计算对应于输入向量的第二单列矩阵的第二向量-矩阵乘积,等等。因此,2x2矩阵-矩阵乘积将需要两个(2)向量-矩阵计算(即总共2x4=8),3x3矩阵-矩阵乘积将需要三个(3)向量-矩阵计算(即总共3x9=27)。
相关领域的普通技术人员将容易理解,图1A中描述的过程的每次迭代成为了接口106(“处理器-存储器壁”)的带宽限制的瓶颈。即使处理器和存储器可以具有带宽极高的内部总线,处理器-存储器系统也只能在接口106能够支持电信令(基于在接口106中使用的材料(典型地为铜)的介电特性和传输距离(~1-2厘米))的速度下通信。此外,接口106还可以包含各种附加的信号调节、放大、噪声校正、纠错、奇偶校验计算和/或进一步减少事务时间的其它基于接口的逻辑。
一种提高矩阵运算性能的常用方法是在本地处理器高速缓存内执行矩阵运算。不幸的是,本地处理器高速缓存占用处理器管芯空间,并且与例如可比较的存储器装置相比具有高得多的每位制造成本。结果,处理器的本地高速缓存大小通常比其存储器(其可以是数千兆字节)小得多(例如,几兆字节)。从实际角度看,较小的本地高速缓存是对可在处理器内本地执行的矩阵运算的最大量的硬限制。作为另一个缺点,大矩阵运算导致较差的高速缓存利用率,因为一次只存取一行和一列(例如,对于1024x1024向量-矩阵乘积,在单个迭代期间只有1/1024的高速缓存处于有效使用中)。因此,虽然处理器高速缓存实施方案对于小矩阵是可接受的,但是随着矩阵运算复杂性的增加,这种技术变得越来越不理想。
另一种常见的方法是所谓的存储器内嵌处理器(PIM)。图1B示出了一个这样的处理器-PIM架构150。如图所示,处理器152通过接口156与存储器154相连。存储器154进一步包含PIM 162和存储器阵列164;PIM 162通过内部接口166与存储器阵列164紧密耦合。
类似于上述图1A中描述的过程,图1B的处理器-PIM结构150将输入向量a的元素与矩阵M相乘以计算向量-矩阵乘积b。然而,PIM 162经由内部接口166对存储器164进行内部读取、乘法-累加和写入。内部接口166比外部接口156短得多;另外,内部接口166可以在没有例如信号调节、放大、噪声校正、纠错、奇偶校验计算等的情况下本地操作。
虽然处理器-PIM架构150在性能上相较于例如处理器-存储器架构100有实质性的改进,但是处理器-PIM架构150可能有其它缺点。例如,制造技术(“硅工艺”)在处理器与存储器装置之间大体上不同,因为每一硅工艺针对不同设计标准进行优化。例如,处理器硅工艺可以使用比存储器硅工艺更薄的晶体管结构;较薄的晶体管结构提供更快的切换(其提高性能),但遭受更大的泄漏(其对于存储器保持来说是不合需要的)。结果,在同一晶片中制造PIM 162和存储器阵列164导致在次优硅工艺中实现其中至少一个。可替代地,PIM 162和存储器阵列164可以在单独的管芯内实现并连接在一起;管芯到管芯通信通常会增加制造成本和复杂性,并且可能遭受各种其它损害(例如,由工艺不连续性等引入)。
此外,相关领域的普通技术人员将容易理解,PIM 162和存储器阵列164是“硬化的”组件;PIM 162不能存储数据,存储器164也不能执行计算。实际上,一旦制造了存储器154,所述存储器就不能被改变以例如存储更多数据和/或增加/降低PIM性能/功耗。此类存储器装置通常专门针对其应用而定制;这对于设计和修改都是昂贵的,在许多情况下所述存储器是“专有的”和/或客户/制造商特定的。此外,由于技术变化非常迅速,这些装置很快被废弃。
由于各种原因,需要用于处理器和/或存储器内的矩阵运算的改进的解决方案。理想地,这种解决方案将以使处理器-存储器壁的性能瓶颈最小化的方式实现存储器装置内的矩阵运算。此外,这种解决方案应该灵活地适应各种不同的矩阵运算和/或矩阵大小。
示范性存储器装置-
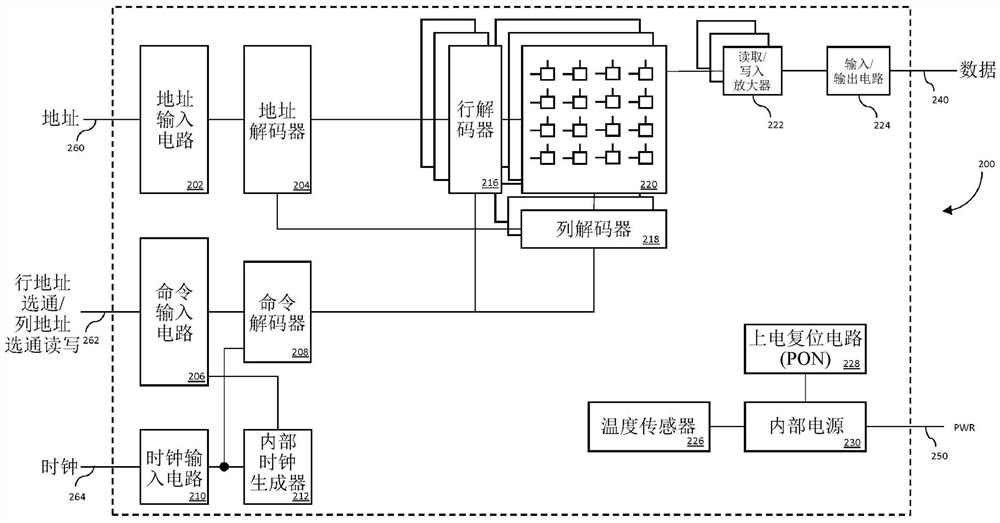
图2是根据本公开的各种原理所制造的存储器装置200的一个示范性实施方案的逻辑框图。存储器装置200可包含多个分区存储器单元阵列220。在一些实施方案中,可在装置制造时分割每一所分割的存储器单元阵列220。在其它实施方案中,可动态地(即,在装置制造之后)分割存储器单元阵列220。存储器单元阵列220可分别包含多个库,其中每一库包含多个字线、多个位线和多个存储器单元,所述多个存储器单元布置在例如所述多个字线和所述多个位线的交点处。字线的选择可由行解码器216执行,而位线的选择可由列解码器218执行。
包含在半导体装置200中的多个外部端子可以包含地址端子260、命令端子262、时钟端子264、数据端子240和电源端子250。可以为地址端子260提供地址信号和库地址信号。提供给地址端子260的地址信号和库地址信号经由地址输入电路202传送到地址解码器204。地址解码器204接收例如地址信号,并将解码的行地址信号提供给行解码器216,并将解码的列地址信号提供给列解码器218。地址解码器204还可接收库地址信号并将所述库地址信号提供给行解码器216和列解码器218。
为命令端子262提供命令信号至命令输入电路206。命令端子262可以包含一或多个单独的信号,例如行地址选通(RAS)、列地址选通(CAS)、读/写(R/W)。通过命令输入电路206将输入到命令端子262的命令信号提供给命令解码器208。命令解码器208可解码所述命令信号262以生成各种控制信号。例如,RAS可被断言为指定数据将被读/写的行,而CAS可被断言为指定数据将被读/写的列。在一些变体中,R/W命令信号确定数据端子240的内容是否被写入存储器单元220或从中读取。
在读取操作期间,可从外部通过读取/写入放大器222和输入/输出电路224从数据端子240输出读取数据。类似地,当发出写入命令并且随写入命令及时提供行地址和列地址时,可以向数据端子240提供写入数据命令。可通过输入/输出电路224和读取/写入放大器222将写入数据命令提供到给定存储器单元阵列220且写入到由行地址和列地址指定的存储器单元中。根据一些实施方案,输入/输出电路224可以包含输入缓冲器。
可以为时钟端子264提供外部时钟信号以用于同步操作。在一个变体中,时钟信号是单端信号;在其它变体中,外部时钟信号可以是彼此互补的(差分信令),并且被提供给时钟输入电路210。时钟输入电路210接收外部时钟信号并调节时钟信号以确保所得内部时钟信号具有足够的幅度和/或频率以用于随后的锁定环路操作。经调节的内部时钟信号被提供给为内部存储器逻辑提供稳定时钟的反馈机构(内部时钟生成器212)。内部时钟产生逻辑212的常见实例包含但不限于:数字或模拟锁相环路(PLL)、延迟锁定环路(DLL)和/或频率锁定环路(FLL)操作。
在替代的变体(未示出)中,存储器200可以依赖于外部计时(即,在没有其自身的内部时钟的情况下)。例如,相位控制时钟信号可以从外部提供给输入/输出(IO)电路224。这个外部时钟可用于时钟输入写入数据,并且时钟输出数据读取。在这种变体中,IO电路224向每个相应的逻辑块(例如,地址输入电路202、地址解码器204、命令输入电路206、命令解码器208等)提供时钟信号。
可以为电源端子250提供电源电势。在一些变体(未示出)中,可以通过输入/输出(I/O)电路224提供这些电源电势。在一些实施例中,电源电势可以与I/O电路224隔离,使得由IO电路224产生的电源噪声不会传播到其它电路块。这些电源电势通过内部电源电路230调节。例如,内部电源电路230可以产生各种内部电势,例如去除噪声和/或寄生活动,以及从电源电势提供的升压或降压电势。内部电势可用于例如地址电路(202,204)、命令电路(206,208)、行和列解码器(216,218)、RW放大器222和/或任何各种其它电路块。
当内部电源电路230能够充分地为上电序列提供内部电压时,上电复位电路(PON)228提供上电信号。温度传感器226可以感测半导体装置200的温度并提供温度信号;半导体装置200的温度可能影响一些存储器操作。
在一个示范性实施例中,可以通过一或多个配置寄存器来控制存储器阵列220。换句话说,这些配置寄存器的使用选择性地将一或多个存储器阵列220配置成一或多个矩阵结构和/或矩阵乘法单元(MMU),这里将更详细地描述。换句话说,配置寄存器可使存储器阵列内的存储器单元架构能够动态地改变例如其结构、操作和功能性。在给定本公开的内容的情况下,这些和其它变化对于本领域普通技术人员是显而易见的。
图3提供存储器阵列和矩阵结构电路配置的更详细的并排图解。图3的存储器阵列和矩阵结构电路配置都使用相同的存储器单元阵列,其中每个存储器单元由电阻元件302组成,其耦合到字线304和位线306。在第一配置300中,存储器阵列电路经配置以作为行解码器316、列解码器318和存储器单元阵列320操作。在第二配置350中,矩阵结构电路经配置以作为行驱动器317、矩阵乘法单元(MMU)319和模拟纵横结构(矩阵结构)321操作。在一个示范性实施例中,查找表(LUT)和相关联的逻辑315可用于存储和配置不同的矩阵乘法单元系数值。
在本公开的一个示范性实施例中,存储器阵列320由电阻式随机存取存储器(ReRAM)组成。ReRAM是非易失性存储器,其改变跨越电介质固态材料的存储器单元的电阻,所述电介质固态材料有时被称为“忆阻器”。当前的ReRAM技术可以在二维(2D)层或三维(3D)层堆叠内实现;然而,在未来的迭代中可以使用更高阶的维度。纵横ReRAM技术的互补金属氧化物半导体(CMOS)兼容性可以使得逻辑(数据处理)和存储器(存储)能够集成在单个芯片内。在其它可能的配置中,纵横ReRAM阵列可以以一个晶体管/一个电阻器(1T1R)配置和/或一个晶体管驱动n个电阻式存储器单元(1TNR)的配置形成。
多种无机和有机材料系统可以实现热和/或离子电阻转变。在多个实施例中,这样的系统可以包含:相变硫属化物(例如Ge
在所示实施例中,电阻元件302是非线性无源双端子电气组件,其可以基于当前应用的历史(例如,滞后或存储器)来改变其电阻。在至少一个示范性实施例中,电阻元件302可以响应于向第一端子(连接到字线304)和第二端子(连接到位线306)施加不同极性的电流而形成或破坏导电细丝。在两个端子之间存在或不存在导电细丝改变了端子之间的电导。虽然本操作是在电阻元件的上下文中给出的,但是相关领域的普通技术人员将容易理解,这里描述的原理可以在以可变阻抗(例如,电阻和/或电抗)为特征的任何电路中实现。可变阻抗可以由各种线性和/或非线性元件(例如,电阻器、电容器、电感器、二极管、晶体管、晶闸管等)实现。
出于说明目的,简要地概括第一配置300中的存储器阵列320的操作。在第一配置中的操作期间,可通过将电流施加到对应于存储器阵列的行和列的存储器单元来实现存储器“写入”。行解码器316可以选择性地驱动各个行端子,以便选择存储器阵列电路320的特定行。列解码器318可以选择性地感测/驱动各个列端子,以便“读取”和/或“写入”到由所选择的行和列唯一标识的对应存储器单元(如图3中通过较粗的线宽和涂黑的单元元件强调的)。如上所述,电流的施加导致在电介质固态材料内形成(或破坏)导电细丝。在这样一种情况下,低电阻状态(接通状态)用于表示逻辑“1”,而高电阻状态(断开状态)用于表示逻辑“0”。为了切换ReRAM单元,将具有特定极性、幅值和持续时间的第一电流施加到电介质固态材料。随后,可通过向电阻元件施加第二电流并基于相应阻抗感测电阻元件是处于接通状态还是断开状态来实现存储器“读取”。存储器读取可能是或可能不是破坏性的(例如,第二电流可能足以或可能不足以形成或破坏导电细丝)。
相关领域的普通技术人员将容易理解,第一配置300中的存储器阵列320的上述讨论与根据例如ReRAM存储器技术的现有存储器操作一致。相反,第二配置350使用存储器单元作为模拟纵横结构(矩阵结构)321来执行矩阵乘法运算。虽然图3的示范性实施方案对应于2x4矩阵乘法单元(MMU),但是可以用等效的成功来替换其它变体。例如,可以实现任意大尺寸(例如,3x3、4x4、8x8等)的矩阵(取决于由数模转换(DAC)308和模数(ADC)310组件实现的精度)。
在模拟纵横结构(矩阵结构)321操作中,由模拟输入信号同时驱动行端子中的每一者,且针对模拟输出(其是跨越用于每一行/列组合的对应电阻元件的电压电势的模拟总和)同时感测列端子中的每一者。值得注意的是,在第二配置350中,与矩阵乘法相关联的所有行和列端子都是活动的(如图3中通过较粗的线宽和涂黑的单元元件所强调的)。换句话说,ReRAM纵横结构(矩阵结构)321使用矩阵结构来执行“模拟计算”,所述“模拟计算”计算向量-矩阵乘积(或标量-矩阵乘积、矩阵-矩阵乘积等)。
值得注意的是,纵横结构内的并发向量-矩阵乘积计算是原子的。具体地说,向量-矩阵乘积的模拟计算可以在单个存取周期中完成。如前所述,原子操作不受数据竞争条件的影响。此外,向量-矩阵乘积计算同时对矩阵运算的所有行和所有列进行计算;换句话说,向量-矩阵乘积计算在复杂度上不根据矩阵维数进行缩放。虽然制造约束(例如ADC/DAC粒度、制造公差等)可限制单个矩阵结构可产生的精度和复杂性的量,但可将多个矩阵运算数学地组合在一起以提供高得多的精度和复杂性。
例如,在本公开的一个示范性实施例中,DAC 308将输入转换到模拟域以用于模拟计算,但是ADC 310也可以将输入转换回数字域以用于随后的数字和/或逻辑操作。换句话说,算术逻辑单元312能够对矩阵结构321的输出进行复杂的数字操作。在模拟域由于实际实施方案限制(例如制造成本等)而不能实现所需计算的情况下,可以使用这种能力。
考虑图4的说明性实例,其中可以通过2x4矩阵结构来执行简单的“FFT蝶形”计算400。虽然可以增加或减少电导,但是不能使电导为“负”。结果,可能需要在数字域内执行减法。在以下矩阵(M)和向量(a)的乘法中描述FFT蝶形运算(EQN.1):
EQN.1:
EQN.1的这个简单FFT蝶形400可以分解为表示正和负系数的两个不同矩阵(EQN.2和EQN.3)。
EQN.2:
EQN.3:
EQN.2和EQN.3可以用矩阵结构电路实现为模拟计算。一旦被计算,所得的模拟值可以通过前述ADC被转换回数字域。现有的ALU运算可用于在数字域(EQN.4)中执行减法:
EQN.4:
换句话说,如图4所示,2x2矩阵可以进一步细分为2x2正矩阵和2x2负矩阵。ALU可将2x2正矩阵和2x2负矩阵的结果相加/相减以生成单个2x2矩阵。相关领域的普通技术人员将容易理解ALU启用的繁多的种类和/或能力。例如,ALU可提供算术运算(例如,加法、减法、进位加法、借位减法、取反、递增、递减、传递等)、逐位运算(例如,AND、OR、XOR、补码)、移位运算(例如,算术移位、逻辑移位、循环、进位循环等)以实现例如多精度算术、复数运算和/或任何将MMU能力扩展到任何精度、大小和/或复杂性程度。
如本文中所使用的,在计算的上下文中的术语“数字”和/或“逻辑”指的是使用量化值(例如,“0”和“1”)来表示符号值(例如,“接通状态”、“断开状态”)的处理逻辑。相反,在计算的上下文中的术语“模拟”是指使用物理信令现象的连续可变方面来执行计算的处理逻辑,所述物理信令现象例如电、化学和/或机械量。本公开的各种实施例可将模拟输入和/或输出信号表示为连续电信号。例如,电压电势可以具有不同的可能值(例如,最小电压(0V)与最大电压(1.8V)之间的任何值等)。可以用数模转换器(DAC)、模数转换器(ADC)、算术逻辑单元(ALU)和/或可变增益放大/衰减来执行将模拟计算与数字分量组合。
再参考图3,为了将存储器单元配置成第二配置350的纵横结构(矩阵结构)321,可以用相应的矩阵系数值写入每个电阻元件。不同于第一配置300,第二配置350可以使用具有被选择来设置特定电导的极性、幅值和持续时间的电流量将不同程度的阻抗(表示系数值)写入每个ReRAM单元中。换句话说,通过形成/破坏具有不同导电性的导电细丝,可以建立多个不同的导电性状态。例如,施加第一量值可导致第一电导,施加第二幅值可产生第二电导,施加第一幅值达较长的持续时间可产生第三电导等。前述写入参数的任何置换可以用等效的成功来替换。更直接地,变化的电导可以使用多种状态(例如,三(3)、四(4)、八(8)等)来表示值的连续范围和/或值的范围(例如,[0,0.33,0.66,1],[0,0.25,0.50,0.75,1]、[0,0.125,0.250,…,1]等),而不是使用两个(2)电阻状态(接通状态、断开状态)来表示两个(2)数字状态(逻辑“1”、逻辑“0”)。
在本公开的一个实施例中,矩阵系数值被提前存储在查找表(LUT)中并且由相关联的控制逻辑315配置。在初始配置阶段,矩阵结构321通过控制逻辑315被写入来自LUT的矩阵系数值。相关领域的普通技术人员将容易理解,某些存储器技术也可实现一次写入多次使用操作。例如,即使形成(或破坏)ReRAM单元的导电细丝可能需要电流的特定持续时间、幅值、极性和/或方向;存储器单元的后续使用可以重复多次(只要导电细丝在使用期限内基本上不形成也不被破坏)。换句话说,相同矩阵结构321构造的后续使用可用于支付初始构造时间。
此外,某些存储器技术(例如ReRAM)是非易失性的。因此,一旦矩阵结构电路被编程,其可以在不使用时进入低功率状态(或者甚至断电)以节省功率。在一些情况下,可以利用矩阵结构的非易失性来进一步改善功耗。具体地,不同于可以从非易失性存储器重新加载矩阵系数值以用于后续处理的现有技术,即使在存储器装置断电时,示范性矩阵结构仍可以存储矩阵系数值。在随后的唤醒中,可以直接使用矩阵结构。
在一个示范性实施例中,可以根据矩阵运算的特性导出矩阵系数值。例如,可基于“大小”(或其它结构上定义的参数)提前导出特定矩阵运算的系数并将其存储在LUT内。仅作为两个这样的实例,快速傅立叶变换(EQN.5)以及离散余弦变换(DCT)(EQN.6)在下文再现:
EQN.5:
EQN.6:
注意EQN.6表示DCT的DCT-II版本,并且通常用于视频/图像压缩。如在数学上可从前述等式确定的,根据变换的大小确定矩阵系数值(也称为“旋转因子”)。例如,一旦DCT矩阵的大小已知,就可以先验地设置矩阵的值(使用例如EQN.6)。
在另一个示范性实施例中,可以提前存储矩阵系数值。例如,某些矩阵乘法运算的系数可以是已知的或者由例如应用程序或用户定义。例如,图像处理计算例如在2018年6月7日申请的题为“形成于存储器单元阵列中的图像处理器(AN IMAGE PROCESSOR FORMED INAN ARRAY OF MEMORY CELLS)”的共同拥有和共同未决的第16/002,644号美国专利申请案中所描述的,先前在上文并入,可以定义各种不同的矩阵系数值,以便实现例如缺陷校正、色彩插值、白平衡、色彩调整、伽马亮度、对比度调整、色彩转换、下采样和/或其它图像信号处理操作。
在另一个实例中,可以通过例如用户考虑、环境考虑、其它装置和/或其它网络实体来确定或定义某些矩阵乘法运算的系数。例如,无线装置经常经历可能干扰操作的不同多径效应。本公开的各种实施例确定多径效应并用矩阵乘法对其进行校正。在一些情况下,无线装置可基于已知信令的降级来计算独立的不同信道效应中的每一者。预期的参考信道信号与实际的参考信道信号之间的差异可以用于确定其经历的噪声影响(例如,在特定频率范围上的衰减、反射、散射和/或其它噪声影响)。在其它实施例中,可以指示无线装置使用波束成形配置的预定“码本”。波束成形系数的码本可能不太精确,但由于其它原因(例如,速度、简单性等)可能是优选的。
如前面提到的,矩阵系数值提前存储在查找表(LUT)中并由相关控制逻辑315配置。在一个示范性实施例中,可以通过专用硬件逻辑来配置矩阵结构。这种内部硬件逻辑可以不受处理器字大小的限制;因此,任何维度的矩阵系数值可以是同时可配置的(例如,4x4、8x8、16x16等)。虽然本公开是在内部控制逻辑315的上下文中呈现的,但是外部实施方案可以用等效的成功来替换。例如,在其它实施例中,逻辑包含内部存储器内嵌处理器(PIM),其可以基于一系列读取和写入中的LUT值来设置矩阵系数值。在其它实例中,例如,外部处理器可执行LUT和/或逻辑功能。
以下参考图5A至5B和6A至6B描述经配置以执行特定矩阵乘法运算的存储器阵列。
在各种实施例中,本公开的各方面可应用于视频/图像压缩或其它操作,无论是否有损。离散余弦变换(DCT)由各种图像/视频处理和压缩技术(包含JPEG)用来将图像的像素值(例如,Y、Cb或Cr值)表示为不同余弦函数的和。例如,图像可以被分解成8x8像素块,其中块中的64个像素中的每一个用亮度(Y)和色度(Cb,Cr)的值来表示。可以对每个8x8块应用DCT以获得该像素块的DCT频率系数的矩阵D。然后使用这个DCT频率系数矩阵来执行图像块的实际压缩。注意,DCT可以类似地应用于其它大小的像素块(例如16x16像素块)。
可以使用矩阵乘法运算D=TMT'来执行NxN像素块的DCT,其中T表示DCT变换矩阵(其值可以使用EQN.6)来计算,T'表示T矩阵的转置,M表示像素值(例如Y值、Cb值、R值等)的矩阵,并且D表示像素块的DCT频率系数的矩阵。这个操作可以被分解为两个单独的矩阵-矩阵乘法阶段/操作:第一操作(EQN.7)和第二次操作(EQN.8)。
EQN.7:B=TM
EQN.8:D=BT'
第一和第二矩阵-矩阵乘法运算中的矩阵的个别值在下文被明确写出。
每个矩阵-矩阵乘法运算可以使用单独的矩阵-向量乘法运算来执行,并且存在将EQN.7和EQN.8的两个矩阵-矩阵乘法运算解构成矩阵-向量运算的各种方式,如本领域普通技术人员在给出本公开时将理解的。并且如前所述,可以使用(一或多个)矩阵结构和(一或多个)MMU来执行矩阵-向量乘法运算。
在一个示范性实施例中,可以使用EQN.7A计算B矩阵的个别列。
EQN.7A:b
其中向量b
例如,可使用矩阵-向量乘法运算b
通过执行n次b
EQN.8A:d
其中向量d
例如,D矩阵的第一行(d
图5A和5B示出了矩阵结构和MMU电路500的一个示范性实施例,其可用于使用上面在EQN.7A和8A中所述的矩阵-向量运算对NxN矩阵M执行DCT。注意,为了简单起见,图5A的矩阵结构521被示为2x4单元阵列。然而,矩阵结构521表示大小为Nx2N的阵列,其中第一NxN矩阵结构部分521A可以配置有矩阵T的正值,而第二NxN矩阵结构部分521B可以配置有矩阵T的负值。
在一个实施方案中,矩阵结构521是8x16单元阵列,第一矩阵结构部分521A配置有8x8T矩阵的正值,而第二矩阵结构521B配置有8x8T矩阵的负值。8x16矩阵结构521可用于对表示8x8像素块的像素值的8x8矩阵M执行DCT运算。
在另一实施方案中,矩阵结构521是16x32单元阵列,用16x16 T矩阵的正值和负值编程,并经配置以对16x16矩阵M执行DCT运算。
在其它实施方案中,矩阵结构521的大小可以适当地按比例放大或缩小,以便对表示各种其它大小的像素块的矩阵M执行DCT运算。如前所述,可以对非常大的矩阵执行本公开的矩阵乘法运算,因为它们不面临传统方法的时间指数缩放问题。因此,根据本公开的各方面,可以在合理的时间量内对非常大的像素块(例如,64x64像素)执行基于矩阵结构的DCT运算。
在图5A的系统500中,矩阵结构521(包含第一部分521A和第二部分521B)使用控制逻辑515用DCT变换矩阵T的正值和负值编程。T矩阵的值取决于矩阵的大小,并且可以根据需要使用EQN.6来计算,或预先存储在查找表(LUT)中。在一个实施例中,将通常使用的矩阵大小(例如,8x8和16x16)的T值存储在LUT中。矩阵M的值表示像素块的个别像素的值(例如,亮度值),并且可以存储在存储器阵列522中。
为了执行DCT运算的第一阶段(EQN.7或7A),表示矩阵M的个别列的向量m
一旦计算了整个B矩阵,DCT运算的第二阶段(EQN.8或8A)可以使用相同的矩阵结构521(配置有T个矩阵值)来执行。表示矩阵B的个别列的每个向量b
如图5B所示,另一系统550可用于通过使用两个或两个以上矩阵结构521并行运行几个矩阵-向量乘法运算来执行矩阵-矩阵乘法运算。在一个实施例中,图5B的系统550包含多个矩阵结构521,所述矩阵结构521连接到其自己的行驱动器517和MMU 519。在一个变体中,多个矩阵结构521包含例如纵横矩阵阵列的垂直堆叠,每个纵横矩阵阵列被配置为矩阵结构521。在另一变体中,多个矩阵结构可以实现为设置在单个级上的矩阵阵列,或者甚至是公共半导体管芯。
还可以理解,尽管图5B的每个矩阵结构521连接到其自己的MMU 519,但是多个矩阵结构521可以连接到单个MMU 519。例如,可以使用具有足够容量的单个MMU来并行处理每个矩阵结构521的输出。此外,可以使用公共行驱动器装置517(尽管使用离散组成的行驱动器电路来独立地驱动每个矩阵结构521)。
在一个实施例中,使用存储器结构系统550,EQN.7的整个矩阵-矩阵乘法阶段可以在驱动一个矩阵结构521一次所花费的时间内执行,因为EQN.7A的所有n个矩阵-向量运算可以同时执行。在所述设备的这个实施例中,控制逻辑515经配置以获取n个单独的向量m
EQNS.7A和8A示出了一种解构DCT运算所需的两个矩阵-矩阵乘法的方式。然而,DCT矩阵-矩阵乘法运算(EQNS.7和8)可以使用不同于EQNS.7A和8A的矩阵向量乘法运算来解构,如给出本公开的普通技术人员所认识到的。
在一个示范性实施例中,可以使用下式来计算矩阵B的值
EQN.7B:b
其中向量b
图6A和6B示出了矩阵结构和MMU电路的另一个实施例,其可用于使用在EQN.7B和8A中所述的矩阵-向量运算对NxN矩阵M执行DCT。在其一种配置中,在DCT运算的第一阶段期间,EQN.7B的矩阵-向量乘法可以使用图6A所示的电路600的第一部分(左)来实现。第一矩阵结构621由控制逻辑615配置成保持M'矩阵的值(分成正M'矩阵621A和负M'矩阵621B)。M'矩阵的值对应于特定图像块的像素值,是未知的或预先计算的,并且不存储在查找表(LUT)中。相反,M'矩阵的值可以存储在装置的存储器阵列622中。控制逻辑615可以存取存储器阵列622并使用存储在存储器阵列622中的M'值来配置第一矩阵结构621。
在配置第一矩阵结构621之后,控制逻辑615向第一行驱动器617提供个别向量t
在一个变体中,b
在DCT运算的第二阶段期间,每个向量b
图6B示出了所述设备的另一个实施例,其中系统650经配置以使得EQN.7B的所有矩阵-向量乘法运算可以并行地执行,并且EQN.8A的所有矩阵-向量乘法运算可以并行执行。矩阵B的所有行可以使用多个(例如,堆叠或公共级/管芯)第一行驱动器/第一矩阵结构/第一MMU电路并行计算,如图6B所示。然后将b
图7A是根据在此描述的各种原理的处理器-存储器架构700的一个示范性实施方案的逻辑框图。如图7A所示,处理器702耦合到存储器704;存储器包含查找表(LUT)706、控制逻辑708、矩阵结构和相应的矩阵乘法单元(MMU)710以及存储器阵列712。
在一个实施例中,LUT 706存储与不同矩阵运算相关联的多个矩阵值系数、维度和/或其它参数。在一个示范性实施例中,LUT 706存储与不同DCT维度相关联的多个离散余弦变换(DCT)系数(例如,“旋转因子”)。
在另一示范性实施例中,LUT 706存储多个快速傅立叶变换(FFT)“旋转因子”,其中旋转因子的各种子集与不同FFT维度相关联。例如,存储64点FFT的旋转因子的LUT 706具有64个系数值,其包含在32点FFT中使用的所有32个系数,以及在16点FFT中使用的所有16个系数,等等。
在其它实施例中,LUT 706存储多个不同矩阵系数值以用于图像信号处理(ISP),例如缺陷校正、色彩插值、白平衡、色彩调整、伽马亮度、对比度调整、色彩转换、下采样和/或其它图像信号处理操作。在LUT 706的又一个实施例中,LUT 706可以包含各种信道矩阵码本,所述码本可以是预定义的和/或基于无线电信道测量根据经验确定的。
在一个实施例中,控制逻辑708基于从处理器702接收的指令控制矩阵结构和MMU710的操作。在一个示范性实施例中,控制逻辑708可以根据由LUT 706提供的前述矩阵维度和/或矩阵值系数,在矩阵结构的每个存储器单元内形成/破坏具有不同电导率的导电细丝。另外,控制逻辑708可以配置相应的MMU来执行矩阵结构的任何附加的算术和/或逻辑操作。此外,控制逻辑708可以选择一或多个数字向量来驱动矩阵结构,并且选择一或多个数字向量来存储MMU的逻辑输出。
在处理技术中,“指令”通常包含不同类型的“指令音节”:例如,操作码、操作数,和/或其它相关联的数据结构(例如,寄存器、标量、向量)。
如本文中所使用,术语“操作码”(操作码)是指可由处理器逻辑、存储器逻辑或其它逻辑电路解释以实现操作的指令。更直接地,操作码标识要对一或多个操作数(输入)执行以生成一或多个结果(输出)的运算。操作数和结果都可以体现为数据结构。数据结构的常见实例包含但不限于:标量、向量、数组、列表、记录、并集、对象、图、树和/或任何数量的其它形式的数据。一些数据结构可以全部或部分地包含参考数据(“指向”其它数据的数据)。参考数据结构的常见实例包含例如指针、索引和/或描述符。
在一个示范性实施例中,操作码可以标识以下中的一或多个:矩阵运算、矩阵运算的维度,和/或存储器单元的行和/或列。在一个这样的变体中,操作数是指定要运算的一或多个数字向量的编码标识符。
例如,对输入数字8x8矩阵执行涉及的DCT处理并将结果存储在输出数字矩阵中的指令可以包含操作码和操作数:DCT8 X 8($input,$output),其中:DCT8 X 8标识所述运算的大小和特性,$input标识输入数字矩阵基地址,而$output标识输出数字矩阵基地址。在另一个这样的实例中,DCT处理可以被分成几个不同的原子操作,例如(i)DCT8X8($address),其将$address处的存储器阵列转换为8x8(64点)矩阵结构,(ii)ROWS8($input,$output),其将$input处的8x8数字矩阵分解为8个单独的数字向量($output),以及(iii)MULT($address,$input,$output),其将$input处的向量-矩阵乘积和$address处的矩阵结构存储到$output。
在一个实施例中,存储器-处理器架构700可用于通过计算存储器704中的一个视频帧(例如,I帧)、至少部分地将处理器702断电(或将其分配给其它任务),然后将处理器唤醒以计算下一帧(例如,B帧)来对连续视频帧执行DCT视频处理。由于每个DCT矩阵运算是在存储器内执行的,并且视频帧数据总是驻留在存储器中,所以存储器带宽负载被大大降低。
图7A示出了在功能上独立于并不同于输入/输出(I/O)存储器接口的指令接口。在一个这样的实施例中,指令接口可以是物理上不同的(例如,具有不同的管芯和/或连接)。在其它实施例中,指令接口可以与I/O存储器接口多路复用(例如,共享相同的控制信令,以及地址和/或数据总线,但处于不同的通信模式)。在其它实施例中,指令接口可以通过I/O存储器接口虚拟可存取(例如,作为位于可通过I/O接口寻址的地址空间内的寄存器)。在给定本公开的内容的情况下,可由本领域的普通技术人员替换其它变体。
在一个实施例中,矩阵结构和MMU 710紧密耦合到存储器阵列712以读取和写入数字向量(操作数)。在一个示范性实施例中,操作数被标识用于进出矩阵结构和MMU 710的专用数据传送硬件(例如,直接存储器存取(DMA))。在一个示范性变体中,数据的数字向量可以是任何维度,并且不受处理器字大小的限制。例如,操作数可以指定N位的操作数(例如,2、4、8、16…等)。在其它实施例中,DMA逻辑708可以使用现有的存储器行/列总线接口对矩阵结构710进行读/写。在其它实施例中,DMA逻辑708可以使用内部存储器接口内的现有地址/数据和读/写控制信令来对矩阵结构710进行读/写。
图7B提供了一组示范性的矩阵运算750在图7A中描述的示范性实施例700的上下文中的逻辑流程图。如其中所示,处理器702通过接口707将指定操作码(例如,由矩阵M
控制逻辑708确定是否应该配置/重新配置矩阵结构和/或矩阵乘法单元(MMU)。例如,将存储器阵列的一部分转换成一或多个矩阵结构,并用由矩阵M
当矩阵结构和/或矩阵乘法单元(MMU)被适当地配置时,输入操作数a被数模(DAC)读取并被应用于矩阵结构M
图7C提供了一组示范性的矩阵运算760在图7A中描述的示范性实施例700的上下文中的替代逻辑流程图。与图7B的流程图相反,图7C的系统使用显式指令将存储器阵列转换为矩阵结构。在指令行为中提供进一步的原子性程度可以实现各种相关的益处,包含例如流水线设计和/或降低的指令集复杂性。
更直接地,当矩阵结构包含适当的矩阵值系数M
此外,相关领域的普通技术人员将进一步理解,一些矩阵结构可具有超出其初始构造的附加通用性和/或用途。例如,如前所述,64点FFT具有64个系数值,其包含在32点FFT中使用的所有32个系数。因此,被配置用于64点操作的矩阵结构可以被重新用于32点操作,其中在64点FFT矩阵结构的适当行上适当地应用32点输入操作数a。类似地,FFT旋转因子是离散余弦变换(DCT)旋转因子的超集;因此,也可以使用FFT矩阵结构(适当地应用输入操作数a)来计算DCT结果。
在给定本公开的内容的情况下,前述实例的其它置换和/或变体对于相关领域的普通技术人员将是显而易见的。
方法-
现在参考图8,示出了将存储器阵列转换为矩阵结构并在其中执行矩阵运算的一个示例性方法600的逻辑流程图。
在方法800的步骤802处,存储器装置接收一或多个指令。在一个实施例中,存储器装置从处理器接收指令。在一个这样的变体中,处理器是通常用于消费电子产品中的应用处理器(AP)。在其它这样的变体中,处理器是无线装置中常用的基带处理器(BB)。
简而言之,所谓的“应用处理器”是经配置以执行操作系统(OS)和一或多个应用、固件和/或软件的处理器。术语“操作系统”是指控制和管理对硬件的存取的软件。OS通常支持处理功能,例如任务调度、应用执行、输入和输出管理、存储器管理、安全性和外围设备存取。
所谓的“基带处理器”是经配置以通过通信协议栈与无线网络进行通信的处理器。术语“通信协议栈”是指控制和管理对无线网络资源的存取的软件和硬件组件。通信协议栈通常包含但不限于:物理层协议、数据链路层协议、媒体存取控制协议、网络和/或传输协议等。
其它外围设备和/或协处理器配置可以类似地用等效成功替换。例如,服务器装置通常包含共享公共存储器资源的多个处理器。类似地,许多公共装置架构将通用处理器与专用协处理器和共享存储器资源(诸如图形引擎或数字信号处理器(DSP))配对。这种处理器的常见实例包含但不限于:图形处理单元(GPU)、视频处理单元(VPU)、张量处理单元(TPU)、神经网络处理单元(NPU)、数字信号处理器(DSP)、图像信号处理器(ISP)。在其它实施例中,存储器装置从专用集成电路(ASIC)或其它形式的处理逻辑(例如现场可编程门阵列(FPGA)、可编程逻辑装置(PLD)、相机传感器、音频/视频处理器和/或媒体编解码器(例如图像、视频、音频和/或其任何组合))接收指令。
在一个示范性实施例中,存储器装置是以“纵横”行-列配置布置的电阻式随机存取存储器(ReRAM)。虽然在此描述的各种实施例假定特定的存储器技术和特定的存储器结构,但是给出本公开的内容的相关领域的普通技术人员将容易理解,在此描述的原理可以广泛地扩展到其它技术和/或结构。例如,某些可编程逻辑结构(例如,通常用于现场可编程门阵列(FPGA)和可编程逻辑装置(PLD))在能力和拓扑方面可以具有与存储器类似的特征。类似地,某些处理器和/或其它存储器技术可以改变电阻、电容和/或电感;在这种情况下,可以使用变化的阻抗特性来执行模拟计算。另外,虽然基于“纵横”的构造提供了很好地适应于二维(2D)矩阵结构的物理结构,但是其它拓扑结构也可以很好地适应于更高阶的数学运算(例如,经由三维(3D)存储器堆叠的矩阵-矩阵乘积等)。
在一个示范性实施例中,存储器装置进一步包含控制器。控制器接收一或多个指令并将每个指令解析成一或多个指令分量(通常也被称为“指令音节”)。在一个示范性实施例中,指令音节包含至少一个操作码和一或多个操作数。例如,可将指令解析成操作码、第一源操作数和目的地操作数。指令分量的其它常见实例可包含但不限于第二源操作数(用于二进制运算)、移位量、绝对/相对地址、寄存器(或对数据结构的其它参考)、立即数据结构(即,在指令本身内提供的数据结构)、从属函数和/或分支/链接值(例如,取决于指令是完成还是失败而被执行)。
在一个实施例中,每个接收的指令对应于原子存储器控制器操作。如本文中所使用的,“原子”指令是在单个存取周期内完成的指令。相反,“非原子”指令是在单个存取周期内完成或不完成的指令。即使非原子指令可能在单个周期中完成,但所述指令必须被视为非原子的以防止数据竞争条件。在由处理器指令(读或写)存取的数据可以在第一处理器指令有机会完成之前由另一处理器指令存取的情况下,发生竞争条件;竞争条件可能不可预测地导致数据读/写错误。换句话说,原子指令保证在不完整的状态下不能观察到数据。
在一个示范性实施例中,原子指令可识别将被转换为矩阵结构的存储器阵列的一部分。在一些情况下,原子指令可以识别矩阵结构的特征属性。例如,原子指令可以基于例如存储器阵列内的位置(例如,通过偏移、行、列)、大小(行数目、列数目和/或其它维度参数)、粒度(例如,精度和/或灵敏度)来识别存储器阵列的所述部分。值得注意的是,原子指令可以提供对存储器装置操作的非常精细的控制;在存储器装置操作可鉴于各种专用考虑而优化的情况下,此可能是合乎需要的。
在其它实施例中,非原子指令可指定将被转换成矩阵结构的存储器阵列的部分。例如,非原子指令可以指定矩阵结构的各种要求和/或约束。存储器控制器可以在内部分配资源以便适应要求和/或约束。在一些情况下,存储器控制器可另外基于当前存储器使用、存储器资源、控制器带宽和/或其它考虑来对指令进行优先级排序和/或取消优先级排序。在存储器装置管理是不必要的,否则将使处理器负担的情况下,此类实施方案可能尤其有用。
在一个实施例中,指令指定矩阵运算。在一个这样的变体中,矩阵运算可以是向量-矩阵乘积。在另一变体中,矩阵运算可以是矩阵-矩阵乘积。在给定本公开的内容的情况下,相关领域的普通技术人员还可以替换其它变体。这样的变体可以包含例如标量-矩阵乘积、高阶矩阵乘积和/或包含例如线性移位、旋转、反射和平移的其它变换。
如本文中所使用,术语“变换(transformation;transform)”等是指将输入从第一域转换到第二域的数学运算。变换可以是“内射”(第一域的每个元素在第二域中具有唯一元素)、“满射”(第二域的每个元素在第一域中具有唯一元素)或“双射”(元素从第一域到第二域的唯一一对一映射)。
在计算领域中经常使用的更复杂的数学定义的变换包含傅立叶变换(及其导数,例如离散余弦变换(DCT))、希尔伯特变换、拉普拉斯变换和勒让德变换。在本公开的一个示范性实施例中,可以提前计算用于数学上定义的变换的矩阵系数值,并将其存储在查找表(LUT)或其它数据结构中。例如,可以计算用于快速傅立叶变换(FFT)和/或DCT的旋转因子并将其存储在LUT内。在其它实施例中,用于数学定义的变换的矩阵系数值可以由存储器控制器在矩阵结构转换过程(或准备)期间计算。
其它变换可以不基于数学定义本身,而是可以基于例如应用、另一装置和/或网络实体来定义。这种变换通常可用于加密、解密、几何建模、数学建模、神经网络、网络管理和/或其它基于图论的应用。例如,无线网络可以使用预定天线加权矩阵的码本,以便用信号通知最常用的波束成形配置。在其它实例中,某些类型的加密可以在不同的加密矩阵之间达成一致和/或协商。在这样的实施例中,码本或矩阵系数值可以提前约定、以带外方式交换、带内交换,或者甚至任意确定或协商。
在给定本公开的内容的情况下,经验确定的变换也可以用等效的成功来替换。例如,在计算领域中经常使用的经验导出的变换包含无线电信道编码、图像信号处理和/或其它数学建模的环境影响。例如,多径无线电环境可以通过测量信道对例如参考信号的影响来表征。所得的信道矩阵可用于对信号接收进行相长干涉(例如,提高信号强度),同时对干扰进行相消干涉(例如,降低噪声)。类似地,可以评估具有偏斜色调的图像的整体色彩平衡,并进行数学校正。在一些情况下,可以基于例如用户输入有意地使图像歪斜,以便赋予图像美学“温暖”。
本发明的各种实施例可在存储器装置内实施“一元”操作。其它实施例可实施“二元”或甚至更高阶“N元”矩阵运算。如本文中所使用的,术语“一元”、“二元”和“N元”是指分别采用一个、两个或N个输入数据结构的运算。在一些实施例中,二元和/或N元运算可以被细分为一或多个一元矩阵原地运算符。如本文中所使用的,“原地”运算符是指将其结果存储或转变为其自身状态(例如,其自身的矩阵系数值)的矩阵操作。例如,二元运算可以分解为两(2)个一元运算;执行第一原地一元操作(结果被存储为“原地”)。此后,可以对矩阵结构执行第二一元运算以产生二元结果(例如,乘法累加运算)。
其它实施例可以基于各种考虑来串行化和/或并行化矩阵运算。例如,顺序相关的运算可以在“串行”流水线中执行。例如,图像处理计算例如在2018年6月7日申请的题为“形成于存储器单元阵列中的图像处理器(AN IMAGE PROCESSOR FORMED IN AN ARRAY OFMEMORY CELLS)”的共同拥有和共同未决的第16/002,644号美国专利申请案中所描述的,先前在上文并入,配置多个矩阵结构和MMU处理元件,以便流水线化例如缺陷校正、色彩插值、白平衡、色彩调整、伽马亮度、对比度调整、色彩转换、下采样等。流水线处理通常可以用最少的矩阵结构资源产生非常高的吞吐量数据。相反,可以用单独的资源“并行”执行不相关的运算。例如,对8x8矩阵执行的DCT运算的第一阶段可以用八个单独的矩阵结构来处理,如关于图5B和6B所描述的。高度并行化的操作可以大大减少等待时间;然而,整体存储器结构资源利用率可能非常高。
在一个示范性实施例中,经由专用接口从处理器接收指令。专用接口在矩阵计算结构被处理成类似于协处理器或硬件加速器的情况下特别有用。值得注意的是,专用接口不需要仲裁,并且可以以非常高的速度(在某些情况下,以本地处理器速度)操作。在其它实施例中,经由共享接口接收指令。
共享接口可在时间、资源(例如,通道、信道等)或其它方式上与其它并发活动存储器接口功能性多路复用。其它存储器接口功能性的常见实例包含但不限于:数据输入/输出、存储器配置、存储器内嵌处理器(PIM)通信、直接存储器存取和/或任何其它形式的阻塞存储器存取。在一些变体中,共享接口可以包含一或多个排队和/或流水线机制。例如,一些存储器技术可以实现流水线接口以便最大化存储器吞吐量。
在一些实施例中,可以从能够存取存储器接口的任何实体接收指令。例如,相机协处理器(图像信号处理器(ISP))能够直接与存储器装置通信以例如写入捕获的数据。在某些实施方案中,相机协处理器能够将其处理任务卸载到存储器装置的矩阵结构。例如,ISP可以加速/卸载/并行化例如色彩插值、白平衡、色彩校正、色彩转换等。在其它实例中,基带协处理器(BB)能够直接与存储器装置通信以例如通过网络接口读取/写入用于事务的数据。BB处理器能够将例如FFT/IFFT、信道估计、波束成形计算和/或任何数量的其它联网任务卸载到存储器装置的矩阵结构。类似地,视频和/或音频编解码器通常利用DCT/IDCT变换,并且将受益于矩阵结构运算。在给定本公开的内容的情况下,相关领域的普通技术人员将容易地认识到前述内容的变体。
本发明的各种实施方案可支持多个指令的队列。在一个示范性实施例中,矩阵运算可以一起排队。例如,多个向量-矩阵乘法可以一起排队,以便实现矩阵-矩阵乘法。例如,如本公开中其它地方所述,可以使用多个矩阵-向量乘法来有效地执行DCT所需的矩阵-矩阵乘法运算。类似地,如前所述,较高阶变换(例如,FFT1024)可以通过将较低阶组成变换(例如,FFT512等)的多次迭代排队来实现。在又一实例中,对图像的ISP处理可以包含迭代空间上的多次迭代(每次迭代可以预先排队)。在给定本公开的内容的情况下,相关领域的普通技术人员可容易地用同样的成功替换其它排队方案。
在一些情况下,矩阵运算可以级联在一起以实现更高阶的矩阵运算。例如,高阶FFT(例如,1024x1024)可以被分解为低阶FFT的多次迭代(例如,512x512 FFT的四(4)次迭代、256x256 FFT的十六(16)次迭代等)。在其它实例中,可以通过级联其它大小的DFT来实现任意大小的N点DFT(例如,不是2的幂)。级联和/或链接的矩阵变换的其它实例可以用等效的成功来替换,上述纯粹是说明性的。
如前所述,ReRAM的非易失性特性即使在ReRAM未通电时也能保持存储器内容。因此,处理器-存储器架构的某些变体可以使一或多个处理器能够独立地为存储器供电。在一些情况下,当处理器不活动时,处理器可对存储器供电(例如,当处理器处于低功率时保持存储器活动)。即使在处理器休眠时,存储器的独立功率管理尤其可用于例如在存储器中执行矩阵运算。例如,存储器可以接收要执行的多个指令;处理器可以转换到睡眠模式,直到完成多个指令。其它实施方案可以使用ReRAM的非易失性特性来在存储器断电时保持存储器内容;例如,某些视频和/或图像处理计算可以在不活动期间保持在ReRAM内。
在方法800的步骤804,可以基于指令将存储器阵列(或其一部分)转换成矩阵结构。如本文中所使用,术语“矩阵结构”是指具有可配置阻抗的多个存储器单元,所述存储器单元在用输入向量驱动时产生输出向量和/或矩阵。在一个实施例中,矩阵结构可以与存储器映射的一部分相关联。在一些这样的变体中,所述部分在其大小和/或位置方面是可配置的。例如,可配置的存储器寄存器可以确定库是被配置为存储器还是矩阵结构。在其它变体中,矩阵结构可以重复使用和/或甚至阻塞存储器接口操作。举例来说,存储器装置可允许存储器接口可基于GPIO(例如,在一种配置中,存储器接口的引脚可在正常操作期间选择性地作为ADDR/DATA操作,或在矩阵运算期间例如作为FFT16等操作)。
在一个实施例中,指令标识由结构上定义的系数表征的矩阵结构。在一个示范性实施例中,矩阵结构含有用于结构上定义的矩阵运算的系数。例如,用于8x8 DCT的矩阵结构是8x8矩阵结构,其已经用DCT的结构上定义的系数预先填充。在一些变体中,矩阵结构可用特定符号(正、负)或特定基数(最高有效位、最低有效位或中间位)的系数预先填充。
如本文中所使用,术语“结构上定义的系数”指的是矩阵乘法的系数由矩阵结构(例如,矩阵的大小)、而不是运算的特性(例如,乘以操作数)定义的事实。例如,可由例如行和列指定来标识结构上定义的矩阵运算(例如,8x8、16x16、32x32、64x64、128x128、256x256等)。尽管前述论述呈现在满秩矩阵运算的上下文中,亏矩阵运算符可用等效成功替换。例如,矩阵运算可具有非对称列和/或行(例如,8x16、16x8等)。事实上,多个基于向量的运算可被视为具有单个列的行或具有单个行的列(例如,8x1、1x8)。
在一些混合硬件/软件实施例中,控制逻辑(例如,存储器控制器、处理器、PIM等)可确定是否存在提供矩阵结构的资源。在一个这样的实施例中,矩阵运算可由预处理器评估以确定是应在软件内还是专用矩阵结构内处理。例如,如果现有存储器和/或矩阵结构的使用消耗了所有存储器装置资源,那么可能需要在软件内处理矩阵运算,而非通过矩阵结构处理。在这种情况下,所述指令可能变回不完整(导致通过处理器指令进行传统矩阵运算)。在另一个这种实例中,将暂时矩阵结构配置为处理简单的矩阵运算可能回报较少,使得矩阵运算应该在软件内处理。
在确定是否应该使用矩阵结构时可以使用各种考虑。例如,存储器管理可以为存储器和/或矩阵结构分配存储器阵列的各部分。在一些实施方案中,可静态地分配存储器阵列的各部分。静态分配对于减少存储器管理开销和/或简化操作开销(损耗均衡等)是优选的。在其它实施方案中,可动态地分配存储器阵列的各部分。例如,可能需要损耗均衡来确保存储器的性能均匀地降级(而不是损耗高可用性区域)。其它变体可以静态地和/或动态地分配不同的部分;例如,可以动态地和/或静态地分配存储器和/或矩阵结构部分的子集。
简而言之,可以在任何离散量的存储器(例如,存储器库、存储器块等)中执行存储器单元的损耗均衡。对矩阵结构进行损耗均衡可以使用类似的技术;例如,在一个变体中,对矩阵结构部分进行损耗均衡可能需要整个矩阵结构整体移动(纵横结构不能分段移动)。可替换地,可通过首先将矩阵结构分解为组成矩阵计算并将组成矩阵计算分散到其它位置来执行矩阵结构部分的损耗平衡。更直接地,矩阵结构磨损均衡可间接受益于在其它矩阵运算(例如,分解,级联,并行化等)中使用的“逻辑”矩阵操作。特别地,将矩阵结构分解为其组成矩阵结构可以实现更好的损耗均衡管理,仅使用略微复杂的操作(例如,通过MMU的逻辑组合的附加步骤)。
在一个示范性实施例中,转换包含重新配置行解码器以作为可变地驱动存储器阵列的多个行的矩阵结构驱动器来操作。在一个变体中,行驱动器将数字值转换成模拟信号。在一个变体中,数模转换包含根据矩阵系数值改变与存储器单元相关联的电导。另外,转换可以包含重新配置列解码器以执行模拟解码。在一个变体中,列解码器经重新配置以感测对应于一列变化电导单元的模拟信号,所述变化电导单元由变化信令的对应行驱动。列解码器将模拟信号转换成数字值。虽然前述构造是以一种特定的行-列配置呈现的,但是其它实施方案也可以用同样的成功替换。例如,列驱动器可以将数字值转换成模拟信号,而行解码器可将模拟信号转换成数字值。在另一个这样的实例中,三维(3D)行-列-深度存储器可以以任何置换(例如行驱动器/列解码器、行驱动器/深度解码器、列驱动器/深度解码器等)和/或3D矩阵置换(例如行驱动器/列解码器驱动器/深度解码器)来实现2D矩阵。
在一个示范性实施例中,矩阵系数值对应于结构上确定的值。结构上确定的值可以基于操作的特性。例如,对NxN矩阵执行的离散余弦变换(DCT)使用NxN DCT矩阵T,其中DCT矩阵的值被计算为N的函数。实际上,各种不同的变换在这方面是类似的。例如,离散傅立叶变换(DFT)和快速傅立叶变换(FFT)都使用结构上定义的系数。
在一个示范性实施例中,矩阵结构本身具有结构上确定的维度。结构上确定的维度可以基于操作的特性;例如,ISP白平衡处理可以使用3x3矩阵(对应于红(R)、绿(G)、蓝(B)、亮度(Y)、色度红(Cr)、色度蓝(Cb)等的不同值)。在另一个这样的实例中,信道矩阵估计和/或波束成形码本通常根据多输入多输出(MIMO)路径的数量来定义。例如,2x2 MIMO信道具有相应的2x2信道矩阵和相应的2x2波束成形加权。在给定本公开的内容的情况下,相关领域的普通技术人员可以替换对于矩阵运算有用的各种其它结构上定义的值和/或维度。
某些变体还可以细分矩阵系数值,以便处理原本可能不切实际的操作。在这种情况下,矩阵结构可以只包含一部分矩阵系数值(只执行一部分矩阵运算)。例如,执行带符号运算和/或更高级的基数计算可能需要极其昂贵的制造公差级别。带符号的矩阵运算可以被分成正的和负的矩阵运算(其稍后由本文中其它各处描述的矩阵乘法单元(MMU)求和)。类似地,高基数矩阵运算可被分成例如最高有效位(MSB)部分、最低有效位(LSB)部分和/或任何中间位(其可由前述MMU进行位移位和求和)。在给定本公开的内容的情况下,本领域的普通技术人员将容易地认识到其它变体。
在一个示范性实施例中,提前确定矩阵系数值并将其存储在查找表中供以后参考。例如,可以提前存储具有结构上确定的维度和结构确定的值的矩阵运算。仅作为一个这样的实例,8x8 DCT矩阵T具有结构上确定的维度(8x8)和结构上确定的值(例如,用EQN.6计算)。DCT8X8指令可以导致8x8矩阵结构的配置,所述矩阵结构预先填充有相应的DCT8X8结构上确定的值。作为另一个这样的实例,天线波束成形系数通常在码本内提前定义;无线网络可以识别码本内的相应索引以配置天线波束成形。例如,MIMO码本可以标识4x4 MIMO系统的可能配置;在操作期间,可以基于其索引从码本中检索所选择的配置。
虽然在结构上定义的维度和/或值的上下文中呈现了前述实例,但是其它实施例可以使用基于一或多个其它系统参数定义的维度和/或值。例如,低功率操作可能需要较小的粒度。类似地,如前所述,各种处理的考虑可能有利于(或反对)在矩阵结构内进行矩阵运算。另外,矩阵运算可影响其它存储器的考虑,包含但不限于:损耗均衡、存储器带宽、存储器内过程带宽、功率消耗、行和列和/或深度解码复杂度等。在给出本公开的内容的情况下,相关领域的普通技术人员可以替换各种其它考虑,上述内容仅仅是说明性的。
在方法800的步骤806处,可以基于指令配置一或多个矩阵乘法单元。如前所述,某些矩阵结构可以实现逻辑(数学恒等式)来处理矩阵运算的单个阶段;然而,多级矩阵结构可以级联在一起以实现更复杂的矩阵运算。在一个示范性实施例中,第一矩阵用于计算矩阵运算的正积,而第二矩阵用于计算矩阵运算的负积。可以在MMU内编译所得的正积和负积,以提供带符号的矩阵乘法。在一个示范性实施例中,第一矩阵用于计算矩阵运算的第一基数部分,而第二矩阵用于计算矩阵运算的第二基数部分。所得的基数部分可以在MMU内被位移位和/或求和,以提供更大的基数乘积。
简单地说,逻辑矩阵运算区别于模拟矩阵运算。示范性矩阵结构将模拟电压或电流转换成由矩阵乘法单元(MMU)读取的数字值。逻辑运算可以通过数学特性(例如,通过矩阵分解等)来操纵数字值;不能以这种方式操纵模拟电压或电流。
更一般地,可以用矩阵组来执行不同的逻辑操作。例如,矩阵可以被分解或因式分解为一或多个组成矩阵。类似地,可以将多个组成矩阵聚集或组合成单个矩阵。另外,矩阵可以以行和/或列扩展,以创建较大维度(但相同秩)的有缺陷矩阵。这种逻辑可用于实现许多高阶矩阵运算。例如,如本公开中其它各处所解释的,将两个矩阵相乘在一起可以被分解为多个向量-矩阵乘法。这些向量-矩阵乘法可进一步实施为矩阵乘法单元(MMU)内的乘法累加逻辑。换句话说,甚至非一元运算也可以作为一系列分段一元矩阵运算来处理。更一般地,相关领域的普通技术人员将容易理解,可以整体或部分地表示为一元运算的任何矩阵操作可以大大受益于本文中所描述的各种原理。
本公开的各种实施例使用矩阵乘法单元(MMU)作为多个组成矩阵结构之间的胶合逻辑。另外,可以选择性地切换MMU运算以连接到各种行和/或列。并非所有的矩阵结构都可以同时使用;因此,根据当前的处理和/或存储器使用,矩阵结构可以选择性地连接到MMU。例如,单个MMU可以动态地连接到不同的矩阵结构。
在一些实施例中,控制逻辑(例如,存储器控制器、处理器、PIM等)可以确定是否存在在例如列解码器或其它地方提供MMU操作的资源。例如,当前的MMU负载可以由预处理器评估以确定是否可以使MMU负载很高。值得注意的是,MMU主要用于逻辑操作,因此具有等效逻辑功能的任何处理实体可以帮助MMU的任务。例如,存储器内嵌处理器(PIM)可以卸载MMU操作。类似地,矩阵结构结果可以直接提供给主处理器(其可以在软件中执行逻辑操作)。
更一般地,本公开的各种实施例考虑在多个不同的矩阵结构之间共享MMU逻辑。共享可以基于例如时间共享方案。例如,MMU可以在一个时隙期间分配给第一矩阵结构,而在另一个时隙期间分配给第二矩阵结构。换句话说,不同于矩阵结构的物理结构(其被静态地分配达矩阵运算的持续时间),MMU执行可以以任何数量的方式被调度、细分、分配、保留和/或划分的逻辑运算。更一般地,矩阵结构的各种实施例基于存储器和非易失性。结果,矩阵结构可以预先配置,并在需要时读取;非易失性特性确保即使例如存储器设备断电,矩阵结构仍保持内容而不需要处理开销。
如果矩阵结构和相应的矩阵乘法单元(MMU)都被成功地转换和配置,则在方法800的步骤808处,基于所述指令驱动矩阵结构,并且在步骤810处用一或多个矩阵乘法单元计算逻辑结果。在一个实施例中,通过矩阵结构将一或多个操作数转换成用于模拟计算的电信号。模拟计算的结果是驱动电信号通过矩阵结构元件;例如,电压降是矩阵结构的系数的函数。感测模拟计算结果并将其转换回数字域信号。此后,用一或多个矩阵乘法单元(MMU)处理一或多个数字域值,以创建逻辑结果。
图8A示出了一个示范性方法850的逻辑流程图,所述方法实施图8的步骤808和810以执行DCT矩阵运算。在一个实施例中,使用图5A中描述的存储器结构来实施示范性方法850,尽管这仅仅是示范性的。
返回参考图8,在DCT的上下文中,在步骤802处,存储器装置从例如处理器接收一或多个指令。所述指令可以指定要对大小NxN矩阵M执行的DCT运算。
在方法800的步骤804处,存储器阵列的一部分被转换成经配置以执行DCT矩阵运算的矩阵结构。在一个实施例中,存储器阵列的至少一个Nx2N部分经配置为具有DCT矩阵T的值的矩阵结构(被分成正T和负T矩阵值),如图5A所述。可通过存储器装置内的控制逻辑从查找表(LUT)检索矩阵T的值。
在步骤806处,一或多个矩阵乘法单元可以被配置为例如编译来自正T矩阵结构和负T矩阵结构的矩阵-向量乘积,以便提供带符号的矩阵乘法(类似于图4中描述的)。
现在参考图8A,方法850用于对矩阵M执行DCT运算(即,如图8的步骤808和810)。
在方法850的步骤811中,从存储器阵列获得表示矩阵M的列的一或多个向量m
在步骤812中,使用一个向量m
在步骤814中,MMU获得矩阵结构的结果,并且通过从在矩阵结构的正T侧获得的矩阵-向量乘积中减去在矩阵结构的负T侧获得的矩阵-向量乘积来计算bcn向量。
在步骤816中,将所得的b
然后重复步骤811到816,直到计算整个B矩阵并在存储器阵列中累积。另外的细节可以在本公开的其它各处的图5A的讨论中找到。
一旦按照步骤811到816计算了整个B矩阵,在图8A的步骤817处,控制逻辑从存储器阵列获得表示矩阵B行的一或多个向量b
在步骤818中,使用一个向量b
在步骤820中,MMU获得矩阵结构的结果,并且通过从在矩阵结构的正T侧获得的矩阵-向量乘积中减去在矩阵结构的负T侧获得的矩阵-向量乘积来计算d
在步骤822中,将所得的drn向量的值存储在存储器阵列中。
然后重复步骤817到822,直到计算整个D矩阵并且DCT运算完成。将认识到,当给出本公开时,前述方法可以容易地被本领域的普通技术人员修改用于图5B和6B的多矩阵结构架构。
还将认识到,虽然根据方法的步骤的特定顺序描述了本公开的某些方面,但是这些描述仅是本公开的更广泛方法的说明,并且可以根据特定应用的需要进行修改。某些步骤在某些情况下可能是不必要的或可选的。另外,可以将某些步骤或功能添加到所公开的实施例中,或者排列两个或两个以上步骤的执行顺序。此外,可以组合来自两种或两种以上方法的特征。所有这些变化都被认为包含在本文公开和要求保护的公开内容内。
本文中陈述的描述结合附图描述了实例配置,并且不表示可以被实现的或在权利要求的范围内的所有实例。本文中所使用的术语“示范性”表示“充当实例、例子或说明”,而不是“优选的”或“优于其它实例”。详细描述包含提供对所描述技术的理解的特定细节。然而,可在没有这些特定细节的情况下实践这些技术。在一些例子中,以框图形式示出了众所周知的结构和装置以避免使所描述实例的概念模糊。
可以使用多种不同技术和工艺中的任一种来表示本文中所描述的信息和信号。例如,可以通过电压、电流、电磁波、磁场或磁性粒子、光场或光学粒子或其任何组合来表示可以贯穿上文描述所引用的数据、指令、命令、信息、信号、比特、符号和芯片。
虽然以上详细描述已经示出、描述和指出了应用于各种实施例的本公开的新颖特征,但是应当理解,在不脱离本公开的情况下,本领域技术人员可以对所示的装置或过程的形式和细节进行各种省略、替换和改变。此描述决不意味着是限制性的,而是应该被认为是对本公开的一般原理的说明。本公开的范围应当参考权利要求书来确定。
还应当理解,虽然这里描述的各种方法和设备的某些步骤和方面可以由人来执行,但是所公开的方面和各个方法和设备通常是计算机化/计算机实现的。由于许多原因,包含但不限于商业可行性、实用性、甚至可用性(即,人不能以任何可行的方式简单地执行某些步骤/过程),需要计算机化的设备和方法来完全实现这些方面。
可以在硬件、由处理器执行的软件、固件或其任意组合中实现本文中所描述的功能。如果在由处理器执行的软件中实现,那么功能可以作为一或多个指令或代码存储在计算机可读媒体上或通过所述计算机可读设备(例如,存储媒体)传送。计算机可读媒体包含非暂时性计算机存储媒体和通信媒体,通信媒体包含促进计算机程序从一个地方传送到另一个地方的任何媒体。非暂时存储媒体可以是能够由通用或专用计算机存取的任何可用媒体。此外,任何连接被适当地称为计算机可读媒体。例如,如果使用同轴电缆、光纤电缆、双绞线、数字用户线(DSL)或诸如红外、无线电和微波的无线技术从网站、服务器或其它远程源传送软件,则同轴电缆、光纤电缆、双绞线、数字用户线(DSL)或诸如红外、无线电和微波的无线技术被包含在媒体的定义中。如本文中所使用的盘和光盘包含CD、激光盘、光盘、数字通用盘(DVD)、软盘和蓝光盘,其中盘通常磁性地再现数据,而光盘通过激光光学地再现数据。上述内容的组合也被包含在计算机可读媒体的范围内。
- 用于在存储器阵列内执行视频处理矩阵运算的方法和设备
- 用于在存储器阵列内执行矩阵变换的方法和设备