一种用于小样本图像数据集的小麦白粉病孢子分割方法
文献发布时间:2023-06-19 11:06:50
技术领域
本发明属于计算机视觉技术领域以及孢子分割领域。其中主要涉及的知识包括一些图像预处理、数据增强、神经网络语义分割、对抗式生成网络等。
背景技术
小麦白粉病是一种常见的小麦病害,白粉病孢子常生长在植物表面。在适当的环境条件下,白粉病孢子可以尽可能长时间的传播,从而造成对植物的伤害——白粉病,它影响植物的生长发育,严重的落叶甚至死亡。小麦白粉病在中国北方和南方各省十分常见,给农作物和经济造成了巨大的损失。目前,已经有智能一体化设备和农业病虫害监测系统实现了小麦白粉病孢子显微图片的采集和分析,但是其分割算法缺少研究,存在分割精度低的问题,并且难以实现语义分割,即从图中分割出目标孢子与背景,去除其他噪音和杂物,因此,如何从图像中准确地分割小麦白粉病孢子,以便进一步对小麦白粉病孢子进行识别,及时分析和获取小麦白粉病的信息,实现小麦白粉病的自动化监测,是当前需要解决的重要问题。
在计算机数字图像处理领域内,小麦白粉病孢子目标分割问题可以被归类为图像的二分类语义分割问题,即对图像中的每一个像素进行分类,将图像划分为前景和背景,因此该问题可以被视为一个逐像素的分类问题。在传统的图像语义分割方法中,使用的方法主要是根据图像纹理、颜色等浅层表观特征,进行特征的人工筛选和设计,进而使用支持向量机(SVM)、随机森林、AdaBoost,K-Means等分类算法进行分类。而小麦白粉病孢子图像存在噪声多,孢子颜色与部分杂物相近,边缘模糊等特点,因此传统方法效果并不好。近年来,随着深度学习技术和硬件的发展,许多基于深度学习的细胞和孢子图像分割方法取得了非常不错的表现,2014年,Long等人提出了全卷积神经网络(FCN),该网络可以直接进行逐像素的端到端图像语义分割,使得深度学习在语义分割领域内产生了突破性进展。随后的几年中,SegNet,DeepLab,以及针对医疗图像设计的语义分割网络U-Net等模型相继出现,在各自的应用场景中取得了瞩目的效果。
目前,小麦白粉病图像分割存在如下问题,由于小麦白粉病孢子图片数据集具有样本少,噪声多,目标小等特点,已有小麦白粉病孢子分割算法分割正确率低,无法对目标孢子进行精确分割,分割结果存在空洞,不能精确地通过图片进行小麦白粉病病害分析。
发明内容
基于上述分析,本发明主要设计了一种语义分割方法,进行小麦白粉病孢子的图像分割。其中主体包括两个网络,一是用于数据增强的对抗式生成网络模型,一个是用于分割目标小麦白粉病孢子的分割网络模型模型。在对分割模型进行训练时,为了弥补训练数据的不足,需要对图像进行相应的预处理以及使用对抗式生成网络模型及仿射变换进行数据增强。同时为了对目标孢子进行语义分割,也需要通过图像掩码提取出小麦白粉病孢子的轮廓实体用于训练。训练与测试所用的数据来自于实验室提供的的小麦白粉病孢子图像数据。
为实现上述目的,本发明采用以下技术方案:为了更好的实现整个方法,选用Python作为方法编写语言。对数据集划分为训练集与测试集。将图像与其对应的掩码图将图像与其对应的掩码图进行数据增强以增加样本,包括:使用OpenCV实现以15°角进行变化的不同角度旋转,加以均值为20-50,均方差为50-100的高斯随机噪声,进行RGB不同通道的亮度变化以及对比度增强处理,以及使用PyTorch实现对抗式生成网络模型的训练及生成孢子图像进行数据增强,PyTorch实现小麦白粉病孢子图像分割网络模型的实现。其中,对抗式生成网络部分采用全卷积神经网络作为架构,分为生成器和判别器两部分,均使用了步长卷积替代确定性的池化操作来进行图像的生成以及判别中的上下采样操作,网络可以学习到空间下采样的过程,应用于生成器和判别器,并且出于提高收敛速度,减少过拟合的目的,取消了判别器最后的全连接层以减少参数,生成器中直接将输入噪声与卷积层特征进行连接,加入了残差模块以提高网络的学习能力,提高生成图像的质量。同时,为了防止数据样本少产生的模式崩坏导致图像缺乏多样性,对于判别器的最后一层去掉Sigmod层,使用Wasserstein距离代替JS散度作为损失函数,生成器和判别器的损失函数不取对数,在每次训练参数更新之后对网络层参数进行谱归一化使其满足Wasserstein距离的连续性要求,并使用RMSProp算法进行动量优化加快收敛速度。对已有的小麦白粉病孢子图像进行训练,进行新的小麦白粉病孢子图像生成。
图像分割网络模型的主要设计架构是经典的编码器—解码器结构。采用U-Net分割网络的设计思路,对输入图片进行四层卷积层的下采样,在获得的512维特征图层后加入了金字塔池化模块,该模块通过将输入特征图进行不同步长的池化,对特征图谱不同的子区域进行抽样,映射形成不同大小的子特征图,将不同级别的特征图进行融合,作为最终的金字塔池化全局特征图输出,用以获取不同细节区域的特征。同时,将下采样编码器中的第四层卷积层与解码器上采样中对应通道数的特征图进行连接,进行进一步的上采样解码,保证深层特征的信息传递和融合,增强网络对深层特征的学习能力。采用L2正则化来防止过拟合,在卷积层后加入批归一化层,并使用Relu作为激活函数。
一种用于小样本图像数据集的小麦白粉病孢子分割方法包括:
步骤1、收集小麦白粉病孢子图像数据集,并对数据集中的数据进行清洗,筛选能够获取包含目标小麦白粉病孢子的图片数据。
步骤2、将小麦白粉病孢子数据集进行掩码标注后,随机划分为训练集和测试集,将图片和掩码同时进行旋转,随机裁剪,添加随机高斯噪声,亮度调整和对比度增强,得到第一批增强数据。
步骤3、构建对抗式生成网络模型,以卷积神经网络作为生成器和判别器架构进行训练和生成,选用生成图片中,与小麦白粉病孢子的形状,颜色特征一致的图片,得到第二批增强数据。
步骤4、构建图像分割模型,在编码器-解码器的结构中加入金字塔池化模块和编、解码器连接结构,对步骤2,步骤3中得到的增强数据以及原训练集数据进行训练。
步骤5、对训练生成的模型对测试集进行测试,采用miou指标最高的模型作为结果。miou的计算方式如下:
其中k+1表示包含了背景在内的类别个数,p
作为优选,步骤2采取以下步骤:
步骤2.1对所有数据集图像进行掩码标注
步骤2.2随机按总数7:3比例划分为训练集和测试集
步骤2.3对训练集和测试集中的图像和掩码标注同时进行以15°角为间隔变化的角度旋转。
步骤2.4只对训练集和测试集中的图像进行如下操作:添加均值为20-50,均方差为50-100的高斯噪声,对RGB三通道中的像素矩阵进行直方图均衡以增强对比度,对像素值低于50的像素进行亮度增强,变化为原先像素值的3倍。通过以上方式得到原先样本数量的9-10倍数量大小的增强数据样本。
作为优选,步骤3具体包括以下步骤:
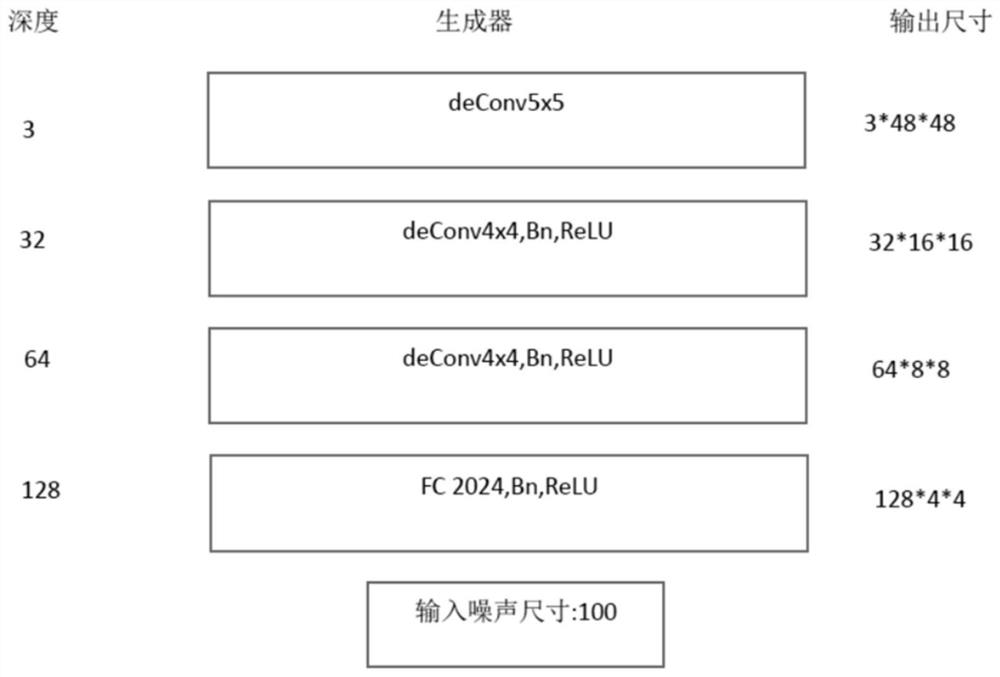
步骤3.1以全卷积神经网络为架构编写生成器由三个上采样部分组成,出于对样本数量及大小的考虑,本文设计的网络仅在第二次和第三次上采样之后加入了残差模块以提升学习能力,提升生成图片的质量,其中用反卷积进行图像的上采样操作,网络先对输入的100维噪声z进行一个上卷积,100维噪声可看成1*1*100的数据,随后通过反卷积生成128维4*4大小的特征图谱,随后通过两个卷积核大小为4*4,卷积步长为2,卷积核为1的反卷积来进行上采样,分别生成64维8*8和32维16*16的特征图谱,8*8特征图后加入带残差结构的两层卷积核大小为3*3的卷积层进行卷积,16*16的特征图谱后加入带残差结构的四层卷积核大小为3*3的卷积层进行卷积,最后通过卷积核大小为5*5,卷积步长为3的上采样后恢复为48*48*3的生成图片,网络中每个卷积层后加入BN批归一化层以及使用ReLu作为激活函数,最后一层用tanh激活函数,并使用Wasserstein距离作为损失函数,生成器Wasserstein距离定义推导见步骤3.2。
步骤3.2编写判别器,判别器分为三次下采样模块,为生成器的逆向结构,输入为48*48*3的图像,下采样卷积至128维特征图谱后,通过全连接层进行输出分类判别,在激活函数的使用上,前三层使用leaky ReLu作为激活函数,最后一层使用Wasserstein距离作为损失函数进行回归,其中Wasserstein距离定义如下:
P
可以根据Kantorovich-Rubinstein二元性理论将其写成如下形式,证明过程略过:
该公式用来计算测试集中的真实样本数据与生成器生成的样本数据之间的Wasserstein距离,此处引入了Lipschitz连续的概念,Lipschitz连续是指,对连续函数f施加限定条件,其导函数的绝对值不能超过K,K≥0,数学定义为:
|f(x
x
公式表示生成数据与真实数据的Wasserstein距离的K倍就是对真实数据和生成数据在网络参数为ω的神经网络f
由此,可以得出生成器G损失函数公式:
判别器D损失函数公式:
其中,L
步骤3.3对生成器和判别器的网络参数进行谱归一化使其满足Wasserstein距离中的Lipschitz连续条件,对于一个神经网络来说,其每一层都可以看成一个线性函数,每一层含有多个神经元,多层神经元的参数构成了神经网络参数矩阵W,而使用Wasserstein距离时,需要满足Lipschitz连续,矩阵映射是一种线性映射,其满足连续条件时,只需要在零点处使其斜率小于K,则在其矩阵所表示线性函数上斜率处处小于K,此时即可满足连续条件,对于判别器,输入x表示测试集真实数据,对于生成器,输入x表示输入的100维噪声数据,网络参数矩阵的谱范数的计算公式如下:
式中||W||
即可将W的谱范数降为1,即各个卷积层参数矩阵的谱范数也为1,此时对于任意第n层网络的映射关系W
此时则对应Lipschitz连续中|f(x
Step1.采用均值为0,方差为1的高斯函数生成随机高斯矩阵变量ν
Step2.对如下操作重复k次,实验中k为网络损失函数稳定收敛所需训练次数,网络损失函数值会随着训练进行波动下降,当其函数值改变不超过其本身值的2%时可以判定为收敛,在本方法实验中设为1000,即网络训练1000次可达到稳定收敛状态,实际可根据不同数据图片训练过程中,损失函数收敛稳定时所需训练次数来决定。μ
令μ
令ν
Step3.||W||
||μ
步骤3.4对训练集中的数据进行裁剪,用固定大小的裁剪框裁剪出每幅图中只含单个目标孢子的图片,对于小麦白粉病孢子采用框为48*48大小,保证每张图片中仅有一个目标白粉病孢子。
步骤3.5将得到的图片进行训练,采用RmsProp算法进行损失函数的优化,生成指定数量孢子图片。
步骤3.6对生成的孢子图片进行筛选,原小麦白粉病孢子为椭圆状,长宽比1.5-2的浅色孢子,挑选与原小麦白粉病孢子在颜色和形状上相似的孢子图片,覆盖至原图中裁剪部分,以得到一批新的小麦白粉病孢子图片进行数据增强。
作为优选,步骤4具体包括以下步骤:
步骤4.1搭建编码器-解码器网络架构,编码器为四层卷积下采样,输入为归一化后的256*256的图片,每一层均采用用3*3,步长为1的卷积核,第一层网络将3通道256*256的图片卷积为64*128*128的特征图,第二层卷积后生成128*64*64的特征图,第三层卷积生成256*32*32的特征图,第四层卷积生成512*16*16的512维特征图,以提取不同层次的特征信息。解码器为五层反卷积上采样,采用padding操作来进行边缘补充,以能够恢复原尺寸大小,与编码器相对应。
步骤4.2在编码器的第四层卷积层和解码器的卷积层之间加入连接结构,将第四层的编码器卷积特征矩阵与解码器第五层反卷积至第四层的特征矩阵信息进行矩阵维数的融合后,再进行一次卷积上采样。
步骤4.3在编码器第五层卷积层后加入金字塔池化模块,该模块相比于金字塔池化网络将多层特征图进行单个步长的池化后融合的算法,采用了只将第四层特征图进行不同步长池化的策略,池化卷积核大小为2*2,进行步长尺寸为2,4,6,13的池化卷积,这样可以在16*16大小的特征图中,生成多尺度的特征组合,以提取多尺度下的特征,结合第四层的连结结构,能够有效提高对小目标的特征提取和学习效果。
步骤4.4对步骤2,步骤3中得到的增强数据以及原训练集数据进行训练。
与现有技术相比,本发明具有以下优势:
本发明关注小样本,小目标的图像数据集的分割任务,所提出的方法包括采用传统的仿射变换及对抗式生成网络共同进行数据增强,以增强样本量,以达到能够在小样本的数据集使用神经网络进行训练的目的,同时,加入了金字塔池化模块以提取更多感受野尺寸下的维度特征,加入编解码器之间第四层卷积层的连接结构,增强对深层特征的提取能力,可以减少对浅层特征的过多学习,避免对类似边缘和颜色的噪声进行分割,总体来说,本发明可以实现对小麦白粉病孢子的有效准确分割。
附图说明:
图1为本发明所提出对抗式生成网络的生成器架构图;其中conv为卷积,k=n表示卷积核大小为n*n,s为卷积步长,p为使用边界填充的数量。128,64,32等为特征图谱的维度,128*4*4中,128为特征图维度,4*4为特征图大小,64*8*8中,64为特征图维度,8*8为特征图大小。同理,32*16*16中32为特征图维度,16*16为特征图大小。
图2为本发明所提出对抗式生成网络的判别器架构图;其中conv为卷积,k=n表示卷积核大小为n*n,s为卷积步长,p为使用边界填充的数量。128,64,32等框中数字为特征图谱的维度,128*4*4中,128为特征图维度,4*4为特征图大小,64*8*8中,64为特征图维度,8*8为特征图大小。同理,32*16*16中32为特征图维度,16*16为特征图大小。3*48*48为三通道48*48大小图片。
图3为本发明设计的语义分割网络结构;
图4为金字塔池化模块;
具体实施方式
以下结合具体实施例,并参照附图,对本发明进一步详细说明。
本发明提供一种小样本图像数据集的小麦白粉病分割方法,具体包括以下步骤:
本发明所用到的硬件设备有PC机1台、1050ti显卡1个;
步骤1、收集小麦白粉病孢子图像数据集,并对数据集中的数据进行清洗,筛选能够获取有效信息(包含目标孢子)的图片数据。
步骤2、将小麦白粉病孢子数据集进行掩码标注后,随机划分为训练集和测试集,将图片和掩码同时进行旋转,随机裁剪,添加随机高斯噪声,亮度调整和对比度增强,得到第一批增强数据。
步骤2.1对所有数据集图像进行掩码标注
步骤2.2随机按总数7:3比例划分为训练集和测试集
步骤2.3对训练集和测试集中的图像和掩码标注同时进行以15°角为间隔变化的角度旋转。
步骤2.4只对训练集和测试集中的图像进行如下操作:添加均值为20-50,均方差为50-100的高斯噪声,对RGB三通道中的像素矩阵进行直方图均衡以增强对比度,对像素值低于50的像素进行亮度增强,变化为原先像素值的3倍。通过以上方式得到原先样本数量的9-10倍数量大小的增强数据样本。
步骤3、构建对抗式生成网络模型,以卷积神经网络作为生成器和判别器架构进行训练和生成,选用生成图片中,孢子特征(形状,颜色等)符合要求的图片,得到第二批增强数据。
步骤3.1以全卷积神经网络为架构编写生成器由三个上采样部分组成,出于对样本数量及大小的考虑,本文设计的网络仅在第二次和第三次上采样之后加入了残差模块以提升学习能力,提升生成图片的质量,其中用反卷积进行图像的上采样操作,网络先对输入的100维噪声z进行一个上卷积,100维噪声可看成1*1*100的数据,随后通过反卷积生成128维4*4大小的特征图谱,随后通过两个卷积核大小为4*4,卷积步长为2,卷积核为1的反卷积来进行上采样,分别生成64维8*8和32维16*16的特征图谱,8*8特征图后加入带残差结构的两层卷积核大小为3*3的卷积层进行卷积,16*16的特征图谱后加入带残差结构的四层卷积核大小为3*3的卷积层进行卷积,最后通过卷积核大小为5*5,卷积步长为3的上采样后恢复为48*48*3的生成图片,网络中每个卷积层后加入BN批归一化层以及使用ReLu作为激活函数,最后一层用tanh激活函数,并使用Wasserstein距离作为损失函数,生成器Wasserstein距离定义推导见步骤3.2。
步骤3.2编写判别器,判别器分为三次下采样模块,为生成器的逆向结构,输入为48*48*3的图像,下采样卷积至128维特征图谱后,通过全连接层进行输出分类判别,在激活函数的使用上,前三层使用leaky ReLu作为激活函数,最后一层使用Wasserstein距离作为损失函数进行回归,其中Wasserstein距离定义如下:
P
可以根据Kantorovich-Rubinstein二元性理论将其写成如下形式,证明过程略过:
该公式用来计算测试集中的真实样本数据与生成器生成的样本数据之间的Wasserstein距离,此处引入了Lipschitz连续的概念,Lipschitz连续是指,对连续函数f施加限定条件,其导函数的绝对值不能超过K,K≥0,数学定义为:
|f(x
x
公式表示生成数据与真实数据的Wasserstein距离的K倍就是对真实数据和生成数据在网络参数为ω的神经网络f
由此,可以得出生成器G损失函数公式:
判别器D损失函数公式:
其中,L
步骤3.3对生成器和判别器的网络参数进行谱归一化使其满足Wasserstein距离中的Lipschitz连续条件,对于一个神经网络来说,其每一层都可以看成一个线性函数,每一层含有多个神经元,多层神经元的参数构成了神经网络参数矩阵W,而使用Wasserstein距离时,需要满足Lipschitz连续,矩阵映射是一种线性映射,其满足连续条件时,只需要在零点处使其斜率小于K,则在其矩阵所表示线性函数上斜率处处小于K,此时即可满足连续条件,对于判别器,输入x表示测试集真实数据,对于生成器,输入x表示输入的100维噪声数据,网络参数矩阵的谱范数的计算公式如下:
式中||W||
即可将W的谱范数降为1,即各个卷积层参数矩阵的谱范数也为1,此时对于任意第n层网络的映射关系W
此时则对应Lipschitz连续中|f(x
Step1.采用均值为0,方差为1的高斯函数生成随机高斯矩阵变量ν
Step2.对如下操作重复k次,实验中k为网络损失函数稳定收敛所需训练次数,网络损失函数值会随着训练进行波动下降,当其函数值改变不超过其本身值的2%时可以判定为收敛,在本方法实验中设为1000,即网络训练1000次可达到稳定收敛状态,实际可根据不同数据图片训练过程中,损失函数收敛稳定时所需训练次数来决定。μ
令μ
令ν
Step3.||W||
||μ
步骤3.4对训练集中的数据进行裁剪,用固定大小的裁剪框裁剪出每幅图中只含单个目标孢子的图片,对于小麦白粉病孢子采用框为48*48大小,保证每张图片中仅有一个目标白粉病孢子。
步骤3.5将得到的图片进行训练,采用RmsProp算法进行损失函数的优化,生成指定数量孢子图片。
步骤3.6对生成的孢子图片进行筛选,原小麦白粉病孢子为椭圆状,长宽比1.5-2的浅色孢子,挑选与原小麦白粉病孢子在颜色和形状上相似的孢子图片,覆盖至原图中裁剪部分,以得到一批新的小麦白粉病孢子图片进行数据增强。
步骤4、构建图像分割模型,在编码器-解码器的结构中加入金字塔池化模块和编、解码器连接结构,对步骤2,步骤3中得到的增强数据以及原训练集数据进行训练。
步骤4.1搭建编码器-解码器网络架构,编码器为四层卷积下采样,输入为归一化后的256*256的图片,每一层均采用用3*3,步长为1的卷积核,第一层网络将3通道256*256的图片卷积为64*128*128的特征图,第二层卷积后生成128*64*64的特征图,第三层卷积生成256*32*32的特征图,第四层卷积生成512*16*16的512维特征图,以提取不同层次的特征信息。解码器为五层反卷积上采样,采用padding操作来进行边缘补充,以能够恢复原尺寸大小,与编码器相对应。
步骤4.2在编码器的第四层卷积层和解码器的卷积层之间加入连接结构,将第四层的编码器卷积特征矩阵与解码器第五层反卷积至第四层的特征矩阵信息进行矩阵维数的融合后,再进行一次卷积上采样。
步骤4.3在编码器第五层卷积层后加入金字塔池化模块,该模块相比于金字塔池化网络将多层特征图进行单个步长的池化后融合的算法,采用了只将第四层特征图进行不同步长池化的策略,池化卷积核大小为2*2,进行步长尺寸为2,4,6,13的池化卷积,这样可以在16*16大小的特征图中,生成多尺度的特征组合,以提取多尺度下的特征,结合第四层的连结结构,能够有效提高对小目标的特征提取和学习效果。
步骤4.4对步骤2,步骤3中得到的增强数据以及原训练集数据进行训练。
步骤5对训练生成的模型对测试集进行测试,采用miou指标最高的模型作为结果。miou的计算方式如下:
其中k+1表示包含了背景在内的类别个数,p
以上实施例仅为本发明的示例性实施例,不用于限制本发明,本发明的保护范围由权利要求书限定。本领域技术人员可以在本发明的实质和保护范围内,对本发明做出各种修改或等同替换,这种修改或等同替换也应视为落在本发明的保护范围内。
- 一种用于小样本图像数据集的小麦白粉病孢子分割方法
- 一种基于小样本深度卷积神经网络用于工业磁瓦缺陷图像分类和分割的方法