一种海绵城市绩效评估系统
文献发布时间:2023-06-19 11:14:36
技术领域
本发明属于海绵城市绩效评估技术领域,尤其涉及一种海绵城市绩效评估系统。
背景技术
住房和城乡建设部发布《海绵城市建设技术导则——低影响开发雨水系统构建》,推荐采用模型法和容积法作为年径流总量控制率控制指标分解方法。由于年径流总量控制率目标融合了多项目标,径流污染控制目标、径流峰值削减目标、雨水资源化利用目标可通过径流总量控制实现,而容积法仅能计算实现年径流总量控制率规划设计目标所需的调蓄容积,无法表达雨水径流路径的组织,并计算实现年径流总量控制率目标所发生的复杂的水文效应以及评估其峰值削减效应、径流污染控制目标等。而采用数学模型法进行年径流总量控制率目标的分解,在实现多目标效益评估的同时,更加科学合理的分解目标,提高规划的指导性和可操作性,弥补容积法的不足。
现有海绵城市规划绩效评估技术通过一些概化的数学公式或物理方程来描述这种高度复杂的非线性的自然过程的一种工具。由于对自然过程机理认识不足,导致模型构建过程中存在极大的不确定性,从而影响模型模拟精度和预测结果。而作为建模过程中不确定性的主要来源,模型参数的不确定性是模型不确定性研究的重点内容。一般而言,水文、水动力及水质模型参数有数十到数百个,复杂的模型可能更多,各参数的不确定性使模型的模拟结果存在很大差异,要同时提高每个参数的精度非常困难。为此,需要定量评估各参数的影响,为实现高效便捷的模型优化和率定提供基础支撑。因此,参数灵敏度分析是模型构建过程中的一个关键环节。
发明内容
本发明的目的是提供一种海绵城市绩效评估系统,通过建立本地化海绵监测及模型模拟数据库,基于时间与空间维度、监测与数学模型模拟对比,实现了项目方案设计阶段、施工图设计阶段及片区级海绵城市建设绩效评估,保证评估的准确性。
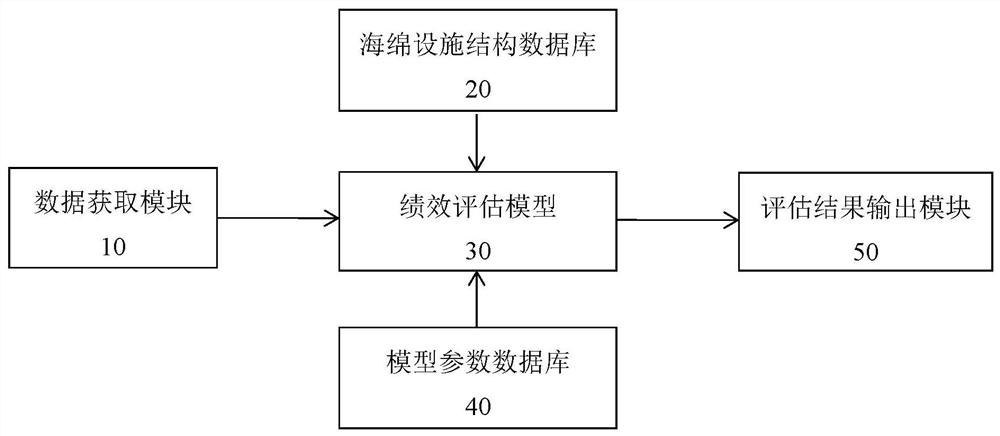
本发明提供了一种海绵城市绩效评估系统,包括数据获取模块、海绵设施结构数据库、绩效评估模型、模型参数数据库、评估结果输出模块;
所述数据获取模块用于获取CIM数据及项目数据;
所述海绵设施结构数据库用于存储海绵设施标准结构数据;所述海绵设施标准结构数据包括预设海绵设施标准结构及自定义海绵设施标准结构;
所述模型参数数据库用于存储绩效评估模型参数,所述参数包括产汇流计算、土壤特性、材料特性、种植物特性、污染物特性参数;
所述绩效评估模型用于基于从所述数据获取模块获取的CIM数据及项目数据,基于从所述海绵设施结构数据库获取的海绵设施标准结构数据,基于从所述模型参数数据库获取的绩效评估模型参数,分别对项目初步阶段、项目详细阶段、片区阶段进行评估,得出评估结果;
所述评估输出模块用于输出评估结果。
借由上述方案,通过海绵城市绩效评估系统,具有如下技术效果:
(1)内容非常全面,涵盖了海绵城市建设的全部工作。
(2)数据全面,包含了气象、水文、地形、地勘、排水分区、排水管网、水系、海绵城市建设项目及海绵设施、海绵建设目标、评估参数、结果等全部数据。
(3)展示及分析功能完备。用户可以从行政区及排水分区两个层级统计、分析、评估海绵城市建设状况,从时间维度、项目类型、项目建设状态、投资主体等全方面对比分析。
(4)绩效评估采用监测与数学模型结合的方式实现了项目级和片区级建设绩效评估。系统建立了模型评估参数数据库,用户不需要输入任何模型参数即可进行评估,便捷易用。
(5)系统根据项目编号根据数据库自动生成模型评估程序。
(6)用户可选取数据中已预留的各种评价条件和参数。
(7)模型可模拟水文、水动力学及水质指标,进一步计算出年径流总量控制率、面源污染削减率等海绵城市建设评价指标。
(8)实现项目—园区—片区三级规划、设计、评估流程化。
(9)以监测数据为验证,以模型评估为主实现海绵城市建设绩效的高效、快速、经济评估。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例详细说明如后。
附图说明
图1是本发明海绵城市绩效评估系统的结构框图;
图2是本发明一实施例中汇水分区内有滞留(流)设施时,外排洪峰流量计算示意图;
图3是本发明Richards算法示意图;
图4是本发明穿孔管出流算法示意图;
图5是本发明Horton算法示意图;
图6是本发明Langmuir吸附等温方程图;图中,a为土壤对COD等温吸附分析经验公式;b为土壤对TP的等温吸附分析经验方程图;c为土壤对TN的等温吸附分析经验方程图;d为土壤对NH
图7是本发明GreenAmpt算法示意图;
图8是本发明积分算法示意图;
图9是本发明不同衰减类型衰减效果示意图;
图10是本发明汇水区产汇流算法示意图一;
图11是本发明汇水区产汇流算法示意图二;
图12是本发明污染物累积函数趋势图;
图13是本发明污染物冲刷函数趋势图;
图14是本发明管网水动力计算框图;
图15是本发明线性结合法生成参考集原理图;
图16是本发明率定优化算法结构图;
图17是本发明优化算法计算步骤流程图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
本实施例提供了一种海绵城市绩效评估系统,包括数据获取模块10、海绵设施结构数据库20、绩效评估模型30、模型参数数据库40、评估结果输出模块50;
数据获取模块10用于获取CIM数据及项目数据;
海绵设施结构数据库20用于存储海绵设施标准结构数据;海绵设施标准结构数据包括预设海绵设施标准结构及自定义海绵设施标准结构;
模型参数数据库30用于存储绩效评估模型参数;参数包括产汇流计算、土壤特性、材料特性、种植物特性、污染物特性参数;
绩效评估模型40用于基于从数据获取模块获取的CIM数据及项目数据,基于从海绵设施结构数据库20获取的海绵设施标准结构数据,基于从模型参数数据库30获取的绩效评估模型参数,分别对项目初步阶段、项目详细阶段、片区阶段进行评估,得出评估结果;
评估输出模块50用于输出评估结果。在本实施例中,CIM数据包括地形数据、土壤及地下水数据、河道水体数据;所述项目数据包括下垫面数据、排水管/渠数据、检查井数据、排放口数据、雨水口数据、海绵设施数据。
在本实施例中,预设海绵设施标准结构包括适用于项目初级阶段的十种常见设施(绿色屋顶、蓝色屋顶、生物滞留设施、透水铺装、下沉式绿地、渗透塘、渗透井、植被草沟、雨水桶、湿地)的简易结构(常见结构和参数)和适用于项目详细阶段的十种常见设施的(绿色屋顶、蓝色屋顶、生物滞留设施、透水铺装、下沉式绿地、渗透塘、渗透井、植被草沟、雨水桶、湿地)复杂结构(常见加特殊结构和参数)。
该海绵城市绩效评估系统,提供海绵设施结构数据库:10种海绵设施标准结构,涵盖绝大部分海绵设施结构;用户可自定义设施及修改标准结构数据库。
用户根据项目所在地的地理位置和气候、资源能源秉赋、发展水平和规模、技术成熟度、区域性要求、经济技术特征等要素,为上一步确认的海绵设施选取适宜的海绵结构。
提供模型参数数据库:完备的参数库,包括产汇流计算、土壤特性、材料特性、种植物特性、污染物特性参数等25类;提供参数默认值及有效值范围;
系统根据项目位置自动配比相应的参数,例如土壤渗透率等。
系统提供数据处理程序,快速将cad图纸转化为模型输出文件。
提供海绵模拟模型:包含产汇流模型、管网模型、河道模型、海绵设施模型,可模拟片区及项目在历史降雨和设计降雨情况两种不同降雨情景。
得到模型模拟结果,系统自动与各项目及片区监测数据衔接,对模型参数自动率定。
下面对本发明作进一步详细说明。
项目初步(方案)阶段评估:
本系统提供的是项目各排水分区下垫面及海绵设施规模,通过容积法对年径流总量控制率、面源污染削减率、初期雨水径流控制、径流峰值削减率等评估指标进行计算。具体内容包括:
评估指标:年径流总量控制率计算,面源污染削减率,初期雨水径流控制,径流峰值削减率。
年径流总量控制率计算:
从系统获取项目各排水分区下垫面及海绵设施资料(系统没有录入时,手动录入)。
年径流总量控制率=每个汇水分区的年径流总量可控制量总和/每个汇水分区的年径流总量需控制量总和。
面源污染削减率:
从系统获取项目各排水分区海绵设施资料(系统没有录入时,手动录入)和低影响开发雨水系统对SS的平均去除率。
年SS总量去除率=年径流总量控制率×低影响开发雨水系统对SS的平均去除率。
低影响开发雨水系统对SS的平均去除率=(LID设施调蓄容积×径流污染控制率+(无调蓄功能LID设施面积+植草沟长度×宽1m)×年径流控制率对应设计降雨量×综合雨量径流系数×径流污染控制率)/LID设施总调蓄容积。
初期雨水径流控制:
从系统获取项目各排水分区下垫面及海绵设施资料(系统没有录入时,手动录入)。
初期雨水径流控制量=每个汇水分区的初期雨水可控制量总和。
实际初期雨水控制厚度=(每个汇水分区的初期雨水可控制量总和/每个汇水分区的初期雨水需控制量总和)*初期雨水控制厚度。
径流峰值削减率:
据根项目建设前后汇水分区内有无滞留(流)设施分别计算其外排洪峰流量Q
当汇水分区内无滞留(流)设施时,外排洪峰流量应按下式计算:
式中:
Q-外排洪峰流量(L/s)
q-设计降雨强度[L/(s·ha.)]
F-汇水面积(ha.)
当汇水分区内有滞留(流)设施时,外排洪峰流量应按图2计算:
项目详细(设计及运维)阶段评估:
根据项目编号、数据库自动生成模型评估程序,用户可选取数据中已预留的各种评价条件和参数,模型可模拟水文、水动力学及水质指标,进一步计算出年径流总量控制率、面源污染削减率等海绵城市建设评价指标。具体内容包括:
影响开发设施水文水质模型主要分为生物滞留设施和入渗设施,其中生物滞留设施主要模拟算法包括土壤层入渗算法、穿孔管出流算法、重力流恢复算法、蒸腾发算法、砾石层下渗算法以及相应的水质算法;入渗设施主要模拟算法包括表层漫流算法、表层下渗算法、蓄水层穿孔管出流算法、蓄水层下渗算法、蒸发算法以及相应的水质算法。
生物滞留设施主要模拟算法
土壤层入渗算法:
采用理查兹(Richards)入渗算法,Richards算法示意图参图3所示。
i=土层数
V
Δz=最小土层厚度
θ
达西定律同样适合于非饱和土壤的水力传输,Richards入渗方程的基本形式为:
式中:
K=随含水率而变化的渗透率;
根据水量守恒:
d(θΔz)=(V
又由非饱和达西定律:
联立上式可求得:
由上式即可求得单位时间内各层土壤的含水率变化情况。
穿孔管出流算法:
如图4所示。
根据管流出流经验公式单位时间Δt内的出流量Q为:
故
令
对原式积分可得
故由上式即可求得单位时间内的出流量以及蓄水层的水位变化情况。
重力流恢复算法:
当土壤含水量超过田间持水点时,低影响开发设施土壤种植层内的水会随着重力流下渗到蓄水层中,故需要考虑重力流恢复算法。
K(θ)=Ks*S
m=1-1/n
式中,θ=含水率;θs=饱和土壤含水率;θr=当前土壤含水率;h=水头(m);α和n为土壤特性参数。
由上式可计算出土壤含水率为θ时,土壤的渗透率K(θ);再用K(θ)乘以模拟步长,即可求得单位时间步长下土壤由于重力流作用而下渗的量。
蒸腾发算法:
Penman结合能量平衡与空气动力学来估计腾发量,Penman公式可能是应用最广的估计日PE的方法,具有如下的数学表达式:
式中:PET为水面蒸发或潜在腾发量(g/cm2/day);Δ为饱和气压曲线的斜率(mb/℃);γ为常数(0.66mb/℃);R
砾石层下渗算法:
采用霍顿入渗算法(Horton)。参图5所示。
霍顿入渗公式是计算入渗曲线的一种经验公式,其形式为:
f=fc+(fo–fc)e-kt
式中:f=入渗速率;fc=饱和入渗速率;fo=初始入渗速率;t=时间;k=与土壤特性有关的经验常数。
水质算法:
采用Langmuir等温吸附算法。
土壤对污染物的吸附等温曲线通常有Langmuir吸附等温方程式和Freundlich。吸附等温方程式两种。据有关资料显示:对于单一组分的填料,Langmuir吸附等温方程式在水处理中比较常用。
Langmuir吸附等温方程式为:
式中:
Ce-吸附平衡溶液浓度mg/L
qe-吸附平衡吸附量mg/g
qmax-吸附质的最大吸附量mg/g
K-与吸附性能有关的常数。
根据Langmuir吸附等温方程,以Ce/qe对Ce作图,可得到一条直线,根据直线可求出qmax和K值。K是与吸附性能有关的常数,能在一定程度上反应土壤对吸附质的能级,K越大,表明对溶质吸附能力越强。图6为土壤对COD、TP、TN、NH3-N的等温吸附分析经验公式:
Langmuir吸附等温方程经验公式
入渗设施主要模拟算法
表层漫流:
在大暴雨工况下,透水面层和透水垫层都饱和的情况下,透水面层的积水会沿着铺装的坡度向外产流,产流算法采用的是业内通用的非线性水库法:
式中:V为出流速度;n为曼宁糙率系数;d为汇水区当前水深;S为铺装层的坡度。
由上式,再根据水量守恒可得:
式中:V为出流速度;wide为铺装平均宽度;h为有效水深;area为铺装的总面积;dt为模拟时间步长;dh为单位时间步长内的有效水深变化量。
由上式,对两端积分可得:
式中:h1为最终水深;Manning_a为曼宁特征参数;h0为初始水深;t为单位模拟步长;wide为铺装层宽度;S为透水铺装平均坡度;area为铺装的总面积;n为曼宁糙率系数。
由上式即可计算在超水平漫流过程中透水面层上的积水的水位变化情况。
表层下渗算法:
采用格林-安普特入渗算法(Green-Ampt)
格林-安普特算法假设土壤(透水垫层)沿着湿润锋一层一层逐渐向下饱和,土壤(透水垫层)的饱和线像活塞一样向前推进(如图7所示)。
该算法的表达式为:
式中f=实际入渗率;Ks=饱和入渗率;H=饱和土壤上层的水深;S=虹吸水头;L=饱和土壤厚度。
本模型为了最大程度地减小算法给模型计算结果带来的误差,对格林安普特算法进行了积分处理:
由达西定理可知:
对上式,令
可得:
上式对x积分后令t(x0)=0即可得到:
对上式用牛顿插值迭代求解即可求出单位时间步长时间内的下渗量。
蓄水层穿孔管出流算法同生物滞留设施。
蓄水层下渗算法:
采用SCS曲线法,SCS曲线法是20世纪50年代美国水土保持局提出的一个经验模型,最初用于农业区域的净雨量,后常被用于城市化流域洪峰流量过程线的分析。实地观测发现,土壤的蓄水能力与CN值(Curve Number,CN)密切相关:
S:土壤最大蓄水量,mm;
CN:径流曲线数,其取值同植被、水文、土壤以及前期雨量密切相关。
蒸发算法:
估计PET的Hamon公式有如下简单形式:
PET=0.5ρ
式中:PET为白昼的潜在腾发量(mm/30day);ρS为月平均温度下的饱和气压(g/cm3)。
水质算法:
在LID设施中,除了土壤对污染物有吸附作用以外,雨水在通过LID设施的种植层或蓄水层时也会有相应的污染物祛除效果,一般用衰减算法来模拟:
线性衰减
式中:Cout=出水污染物浓度;Cin=进水污染物浓度;K1,K2为经验常数;HLR(hydraulic loading rate)为水力负荷率(mm/day);Q=出流速率(M3/s);A=LID设施表面积(M2)。
线性衰减中,出水的污染物浓度与LID系统的水力负荷率成线性正相关。
线性衰减参数范围表
指数衰减
指数衰减通常又称为一阶衰减,基本表达式为:
式中:Cout=出水污染物浓度;Cin=进水污染物浓度;k=衰减常数;x=与衰减常数有关的系数(如污染物的水力停留时间或者是植草沟的长度等)。
本模型中BOD的衰减算法用的是指数衰减,其中x为水力停留时间计算公式为x=V/Q(V=当前的总体积Q=当前的出流速率);K=K20(1.06)(T-20)(T为当前温度),K20=0.678d-1;
指数衰减参数范围表
对数衰减
对数衰减的基本表达式为:
K
式中:Cout=出水污染物浓度;Cin=进水污染物浓度;C*=污染物背景浓度;KAT=在特定温度下的衰减系数;KA20=在20摄氏度下的衰减系数数;θ=温度修正系数,K20=0.678d-1;
指数衰减参数范围表
(2)地块产汇流水文水质模型
地块产汇流水文水质模型模拟算法包括场地内的产汇流水文算法和水质计算算法。
产汇流水文算法
场地分为透水面和不透水面两个子汇水单元,不同的子汇水单元的产汇流独立分开计算。产汇流算法采用的是业内通用的非线性水库法:
式中:V为出流速度;n为曼宁糙率系数;d为汇水区当前水深;ds为滞蓄的深度;S为子汇水单元坡度。
由上式,再根据水量守恒可得:
式中:V为出流速度;wide为场地平均宽度;h为扣除滞蓄之后的有效水深(h=d-ds);area为子汇水单元的面积;dt为模拟时间步长;dh为单位时间步长内的有效水深变化量。
由上式,对两端积分可得:
式中:h1为最终有效水深;Manning_a为场地内曼宁特征参数;h0为初始水深;t为单位模拟步长;wide为场地平均宽度;S为子汇水单元坡度;area为子汇水单元的面积;n为曼宁糙率系数。
上式中单位均为国际单位,入渗算法在LID水文算法里单独介绍。
水质算法
场地水质算法采用的是污染物累积冲刷算法,通过线性或非线性的累积方程冲刷来模拟地表的污染物的增长和衰减过程。
累积算法:
幂函数累积(PowerFunctionBuildUp)。
幂函数累积公式污染物累积(B)与时间成一定的幂函数关系,直到累积达到最大极限:
B=Min(C1,C2tC3)
式中:C1为MAX累积量(单位面积的质量);C2为累积率常数;C3为时间指数。累积公式为线性是此公式出现的特殊情况,C3=1。
指数函数累积(ExponentialFunctionBuildUp):
指数函数累积是指污染物的累积过程与时间遵循着一定的指数函数关系,直至累积达到最大限度为止:
B=C1(1-e-C2t)
式中:C1为MAX累积量(单位面积的质量);C2为累积率常数(1/d)。
饱和函数累积(SaturationFunctionBuildUp):
饱和函数累积公式中,污染物累积与时间成饱和函数的关系,直至累积达到极限值为止:
B=C1t/(C2+t)
式中:C1为MAX累积量(单位面积的质量);C2为半饱和常数(达到MAX累积量一半时的天数)
污染物累积参数说明表
冲刷算法:
指数冲刷函数(ExponentialWashoff)
污染物的冲刷量(W)以每小时的质量为单位,与污染物累积量成正比,与径流量成指数关系。
W=C1qC2B
式中:C1是冲刷系数;C2是冲刷指数;q是单位面积的径流速率(mm/h);B为污染物的累积质量,在这里指的是累积的总质量(不是每块区域或是一定长度范围内),累积量和冲刷量的质量单位与表达污染物浓度的单位一样(mg、μg或数量)。
径流冲刷函数(RatingCurveWashoff):
径流冲刷函数表示的是污染物冲刷量与径流量成正比,并按一定幂次上升。
W=C1qC2
式中:C1是冲刷系数;C2是冲刷指数;Q为径流率(用户定义的流量单位)。
平均浓度函数(EventMeanConcentra-tion)
这是一种特殊的水量冲刷曲线,指数为1,表示每升含多少质量的污染物。
EMC=M/V
式中:M为径流全过程的某污染物总量,kg;V为相应的径流总体积,L。
污染物冲刷参数说明表
(3)模型参数设定
在采用模型法进行海绵城市建设绩效评估时,平台为用户收集了各种模型模拟需要的参数集,包括四大类:
系统及算法类参数集
系统参数包括时间、降雨、入渗、蒸发、水质和水力计算参数;算法参数包括入渗算法参数和水动力学算法参数。具体如下表所示:
系统参数表
算法参数表
(4)海绵设施结构集:
海绵设施结构集参照国内外海绵设施设计的大样图,总结出下列10种海绵设施的通用结构:
雨水花园、绿色屋顶、透水铺装、植被草沟、入渗设施、过滤设施、滞留设施、雨水湿地、雨水收集设施。
同时平台预留了3种用户自定义设施,例如环保式雨水口等。具体如下表所示(以入渗设施为例):
入渗设施结构表
水文及水力计算参数集
地表径流参数集是用于不同下垫面产汇流计算是需要的各种参数,例如曼宁系数(糙率),洼蓄量等;
土壤入渗参数包括四种土壤入渗算法:固定量法,Horton方程法,Green-Ampt法和Richards Equation法。
管道水力计算参数集包括管网及检查井计算需要的曼宁系数(糙率),水头损失等参数。
材料参数集包括各种材料(例如透水砖,透水混凝土,过滤材料等)的孔隙率及渗透系数,同时也包括各种不同土壤的含水率恢复参数,例如田间持水点,临萎点等。
具体如下表所示(以管道水力参数和材料孔隙率及渗透率为例)。
管道水力参数表
材料孔隙率及渗透率表
面源污染参数集
清扫参数包括环卫扫街的频率,清扫效果等;
污染物累计参数包括污染物最大累积量,累计过程参数。累计过程采用三种累计曲线,幂函数曲线,指数函数曲线和饱和曲线。
污染物冲刷参数包括污染物与不同地表径流厚度之间释放规律。
具体如下表所示:
街道清扫参数表
污染物累计参数表
污染物冲刷参数表
片区级模型评估:
根据项目编号、数据库自动生成模型评估程序,用户可选取数据中已预留的各种评价条件和参数,模型可模拟水文、水动力学及水质指标,进一步计算出年径流总量控制率、面源污染削减率等海绵城市建设评价指标。
片区级模型评估主要包括低影响开发设施(简称LID,下同)水文水质模型、地块产汇流水文水质模型、管网水文水质模型和一维河道水文水质模型四部分。
其中低影响开发设施(简称LID,下同)水文水质模型和地块产汇流水文水质模型主要模拟算法与项目级模拟评估程序一致。管网水文水质模型主要模拟算法包括管网水动力学算法和管网水质算法;一维河道水文水质模型主要模拟算法包括河道水动力算法和河道水质算法。
低影响开发设施(简称LID,下同)水文水质模型
与项目级模型评估程序保持一致。
地块产汇流水文水质模型
与项目级模型评估程序保持一致。
管网水文水质模型
管网水文水质模型主要模拟算法包括管网水动力学算法和管网水质算法。
管网水动力学算法
管网演进求解控制方程:
节点流量连续性方程
∑Q
式中,∑Q
节点水头方程:
式中,H
管段流量方程:
对一维圣·维南方程组进行有限差分处理,得到如下管段流量计算式:
式中,Q
计算管段的边界条件:
上游边界:管网中每一个检查井节点都是与其连接的下游管段的上游边界点。每个检查井节点对其下游管段的出流过程线就是下游管段的上游边界条件。
下游边界:计算管段下游节点的水位值,分为普通管段和末端管段两种情况。
①普通管段:
在计算初始时刻,即由t=0计算t+△t时刻时,各普通管段下游边界依据管网的原始状态确定。若管网无水,则下游节点水位边界为零;若管网存在旱季流量,可以计算得到下游节点水位值。
在计算初始时刻之后的计算中,各普通管段下游边界条件水位值是前一计算时刻中计算得到的节点水位值。使用上式计算得到。
②末端管段:
末端管段是其下游节点为管网排出口的管段。考虑到下游受纳处的影响,该
边界由用户指定(水位过程线)。注意,此处下游节点已不是普通检查井节点,不能使用上式计算。
管网演进计算步骤:
①确定上、下游边界条件(包括初始条件);
②对于某一计算时刻,计算各节点状态方程,即获得H
③计算各管段状态方程求解Q
④重复步骤②和③至计算时间结束。
管网水质算法
管网系统中,污染物模拟采用CSTR模型,即混合的一阶衰减模型来描述。
C:污染物浓度,kg/m3;
V:水流体积,m3;
Qi:入流量,m3/s;
Ci:入流污染物浓度,kg/m3;
Qe:管道出流量,m3/s;
K:一阶衰减系数,s-1;
L0:管道中污染物源汇项,kg/s
一维河道水文水质模型
一维河道水文水质模型主要模拟算法包括河道水动力算法和河道水质算法。
河道模型模拟算法
河道水动力算法:
本次模型的一维水动力学计算采用一维非稳定流微分方程,即一维圣维南(DeSaint Venant)方程组,该方程组由连续性方程(Continuity)和动量方程(Momentum)组成,即:
其中:
AT:断面过水面积;
Q:流量;
t:时间;
x:沿水流方向沿程距离;
h:断面水深;
S0:河道底坡;
z:河道水位;
ql:河道中该微分块的入流;
uq:入流在主流方向的流速;
β:动量修整系数;
Sf:摩阻比降。
河道水质算法:
采用一维水质模型来计算各控制单元沿程浓度变化及控制断面污染物浓度。模型方程如下:
CODcr水质模型方程:
式中,
式中,
CODcr降解系数
其中,
NH3-N水质模型方程:
式中,
式中,
NH3-N降解系数
为了进一步提高绩效评估的准确性,本实施例绩效评估模型还用于与各项目及片区监测数据衔接,对模型参数进行自动率定,具体内容如下:
模型参数率定算法:
1)遗传算法
遗传算法是受生物进化现象的启发,基于“适者生存”机制而设计的算法。它将问题表示为“染色体”的适应过程,通过不断的进化(复制、交叉、变异)操作,最终收敛到“最适应环境”的个体,从而求得最优解。
2)多目标粒子群算法MOPSO
生物群体内个体间的合作与竞争等行为产生的群体智能,往往可以给某些特定问题提供高效的解决方法。鸟类在搜索食物的过程中,个体之间可以进行信息交流和共享,每个成员可以得益于其他成员的发现和经历。当食物源不可预测零星分布时,这种协作带来的优势是决定性的:远大于对食物的竞争带来的劣势。对于多目标粒子群算法MOPSO,它的优点如下:算法通用性强,不依赖于问题信息;群体搜索,并具有记忆能力,保留局部和全局种群的最优信息;原理简单,容易实现;协同搜索,同时利用个体局部信息和群体信息指导搜索。
3)多目标MOSCEM-UA
多目标MOSCEM-UA是Vrugt等在SCE-UA单目标优化算法的基础上提出的一种改进多目标优化算法。首先,MOSCEM-UA算法在基于协方差的Metroplis-Annealing方法代替SCE-UA算法中的下降单纯形法生成后代样本点,从而避免进化计算向单一模式的确定性转移;其次MOSCEM-UA在进化生成子代过程中,不再将复合形进一步分解,并采用不同的样本点更新过程,从而有效避免了陷入局部后验密度区域的趋势。MOSCEM-UA算法通过继承Metroplis算法、控制随机搜索、竞争进化与复合型方法,在进化过程中能够交换并行进化序列信息。根据马尔科夫链自适应的调整转移概率,从而保证参数后验概率密度的连续更新与进化,最终达到识别非劣参数及后验分布的目的。该方法迭代次数少,可以应用于多目标参数优化问题。
4)离散搜索算法(Scatter Search)
离散搜索法像遗传算法一样也是一种基于群集的Meta-heuristic优化算法。SS是通过结合其他方法而建立起来的一种演进方法。该方法首先通过多样性生成一个初始集,然后在初始集中选择出一组参考集。再以该参考集为基础,通过一些其他的优化算法(如线性结合法)构造出新的解集,并通过改良策略形成新的参考集。
离散搜索法与禁忌算法结合解决复杂的优化问题。禁忌算法是一种高效的优化算法之一。禁忌算法首先随机生成一组集,然后选择其最佳的邻集。禁忌算法使用禁忌名单(tabu list)记录下最近选择的解集。禁忌运动法用来寻找一个新的较优解。禁忌搜索停止的标准是当寻优次数达到了设定的最大次数而当前最优解并没有得到改进或者已经确实寻求到最优解。
在离散搜索中,首先利用多样性生成初始集,接着从初始集中选择出参考集。该参考集作为生产新的参考集的基础。对参考集中各解进行区分,分为是将好的集与坏的集采用线性结合法进行交叉生成。当生成新的交叉参考集后,再利用禁忌法改进其适合度;将参考集返回作为新的参考集进行下一次搜索算法。
(1)多样性生成初始集方法:
从一个初始的种子V利用一个整数h生成可以生成两种初始集V’和V”(解最大容量为n)。
V'[1+k*h]=1-V[1+k*h]k=1,2,3,…n/h,k 且 (2)线性结合法: 用一个好的集(X1,X2,X3)和一个坏的集(Y1,Y2)进行交叉生成的过程如图15所示。 比较遗传算法与离散搜索法,离散搜索法具有快速找到最优解的高效性。 离散搜索法另一个重要的特点是其动态处理约束条件的方法。在SS中,采用动态惩罚函数来惩罚违反约束条件的方案。该惩罚函数执行时,考虑违反约束条件的程度和违反的历史等。例如,当没有条件可行方案存在时,一个条件不可行方案将受到比有一个条件可行方案存在时更重的惩罚。 参数率定的重要作用是对一个或多个目标(如模型模拟值与实测值的均方差等),搜索确定最适合该目标的最优参数组合。通常情况下,水文模型的结构比较复杂,各有侧重点,且大多是以非线性形式存在的。多目标优化问题中多个目标之间通常相互制约;如果对其中一个目标进行优化,则可能会以牺牲其他目标为代价。因此,很难正确评价多目标问题解的优劣性。目前有很多种优化算法可以用于水文模型多目标优化。其中离散搜索法具有快速找到最优解的高效性,是一种具有较强鲁棒性的全局优化算法。因此,宜采用离散搜索法进行参数率定。 率定算法结构: 通常,一个参数率定问题的解决有以下5个主要部分组成,参图16所示: 1)目标函数(Cost Function):一般的优化算法均是为了寻求最经济的解决方案,所以称之为费用计算函数。但是在参数率定问题中一般采用总体累计误差,单个监测点误差等函数来计算所需要的总花费。因此,也称为费用函数。 2)约束函数(Contraction Function):或称约束条件,一般为事物自身或外部对优化问题的限制。对率定过程中的一些参数进行约束,如时间花费,单个目标的误差,单个监测点误差等。 3)优化算法(Optimizer):用于进行优化搜索的算法,一般是一些通用算法,常用的算法遗传算法、多目标粒子群算法MOPSO、多目标MOSCEM-UA、离散搜索法等。通过上一节的分析,本次率定过程采用离散搜索法作为率定的优化算法。 4)评估方法(Evaluator):对率定过程获得的参数值解集进行重新模拟,评估参数集的模型模拟效果。 5)搜索群:指可以被优化算法用来优化的对象的集合,例如可以选择的参数集取值空间等。优化算法最终将在搜索群中确定最优的参数值解集。 目标函数 目标函数针对整个模型要求总体累计误差最小。
其中:S S n为监测点的数量。 单个监测点的总误差S
其中: Δs S X X n为监测点i拥有n个观察数据。 单个监测点的总误差为所有观察数据与模拟数据对比的差值占观察数据的比值的平均值。当观察数据值为0时,该观察数据的误差为0。 约束函数: 针对每个监测点需要确定一个误差上限(5%)。 S 因此约束函数为单个监测点的总体误差值要小于5%。如果单个监测点的总体误差值大于5%,则需要重新计算参数解集。 约束条件均采用惩罚函数处理,如果违反约束条件,每超过一个监测点违反约束条件,增加目标函数值10%。 搜索群——率定参数 参数率定过程可以看作一个获取原问题多目标条件下的Pareto最优解集。当水文模型的结构复杂,参数维数较多时,就会存在多个局部最优解可能,影响优化算法的收敛性能。因此在前面的LH-OAT敏感性分析基础上选取对模型目标敏感度高的参数进行自动率定。研究选取中高敏感度和极敏感参数做多目标参数优化,共5个参数,分别为沿程水文损失,平均径流流速,不透水率,管道曼宁系数和阻力。 率定参数又可以分为全局参数和计算单元(子汇水区、管道)参数。本次自动率定的参数中沿程水文损失,平均径流流速,不透水率,管道曼宁系数为计算单位参数,阻力为全局参数。其中计算单元参数因为每个计算单元的特征均不同,具有分布式异质性。通过实际监测数据将所有计算单元的相应局部参数(计算单元参数)均率定出来是十分困难,甚至是不切实际的。通过一定的方法来将计算单元进行分类参数率定是可取的路径之一。 沿程水文损失,平均径流流速两个参数均与汇水区的地形坡度、土地利用等属性相关。因此,根据汇水区的地形坡度、土地利用等属性进行K-mean聚类,将各汇水区分成不同的类别,同一类别的汇水区具有相同的沿程水文损失,平均径流流速参数值。同理,对于管道可以根据管道的形状,材质等属性进行聚类,区分不同类型的管道曼宁系数参数值。 不透水率参数值可以根据以下公式进行计算:
其中p 因此,只需要对几种典型的土地利用如道路、绿地、建筑等的不透水率进行率定,就可以间接地获得每个子汇水区的不透水率参数值。 评估方法: 对于取得的最优解集需要评估方法进行评估率定后参数是否满足要求。其中随机选取80%监测点的观测数据,作为优化算法的求解率定数据,使用优化算法迭代出最优参数组。然后使用该参数组进行模拟,将模拟结果与剩下的20%监测点的观测数据进行对比分析,计算每个监测点的误差S 优化算法: 通过上一节的分析,本次率定过程采用离散搜索法作为率定的优化算法。优化算法的计算步骤如下: 1)确定搜索群:搜索群即需要确定的率定参数值域。 2)耦合目标函数、约束函数、评价方法及停止条件到离散算法中。其中停止条件: M=Ms或者找到最优值。 其中:M是优化算法计算的次数;Ms是初始设定的次数,Ms=5000。 3)确定启动搜索点:首先分别将搜索群分为数量相等的4个子集,然后分别分两步建立启动点:①随机从4个子集中选出一个集;②再在选出的子集中随机选出3个点。通常选出的启动点是搜索群的开始点、结束点、中间点或者用户自定义的点。这样就确定了3个启动点:V1,V2,V3。 4)确定初始参考集:根据多样性法分别从启动点V1,V2,V3开始生成初始参考集R1,R2和R3; 5)通过计算参考集R1中各点目标函数值,将分别将3个参考集分为好的集和坏的集; 6)采用线性结合法构造新的解集R1,R2和R3,从而开始搜索; 7)以上的搜索均进行三次,搜索出三个参数值。计算该次搜索的目标函数,并判断是否违反约束条件。最后根据约束条件的结果,利用惩罚函数重新计算目标函数值; 8)利用禁忌法更新参考集:在整个优化搜索过程中,参考集会不停的被更新,更新的结果是新解会变得更优或者改善参考集中数据的多样性; 9)当搜索出一个结果时,如果参考没有被更新或该结果没有在上一个搜索结果上有所改善,将执行更新参考集算法; 10)当搜索停止条件符合时(即搜索次数达到设定次数5000,而解得到改善;或者得到最优解),搜索停止。返回给用户各个适合的解。 以上步骤如图17所示。 上所述仅是本发明的优选实施方式,并不用于限制本发明,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 一种海绵城市绩效评估系统
- 一种医院绩效质控评估系统