一种高速公路绿通车过站查验时间预测方法
文献发布时间:2023-06-19 11:14:36
技术领域
本发明属于智能公交领域;尤其涉及一种高速公路绿通车过站查验时间预测方法。
背景技术
高速公路绿色通道(简称绿通)是装运鲜活农产品的车辆专用通道。按照规定,鲜活农产品运输车辆整车或合法混装指定鲜活农产品不超过核定载重或车厢容积20%,并且超载不超过5%的车辆属于合法的“绿通车”,予以减免通行费。鲜活农产品是指新鲜蔬菜、水果、鲜活水产品、活的禽畜、新鲜的肉蛋奶,马铃薯、甘薯、鲜玉米、鲜花生。而这些物品的深加工以及花草苗木、粮食等不属于鲜活农产品范围,不能享受绿色通道运输政策。
目前收费站对绿通车都实行全部查验、逢车必查,由于缺乏有效信息指导,收费站工作人员需对每辆进站的绿通车均需无区别化仔细查验。随着信息技术发展,目前出现了采用便携式查验终端对绿通车辆进行查验登记,主要采用便携式设备与内窥镜等相结合,进行电子化登记,在提高检验效率,增加数据完整性、降低统计工作量方面有显著效果,是人工查验的一种信息化辅助手段。一般情况下,人工查验货物的耗时约5-10分钟/车,但是受到车型、货物运载数量、混装情况、封闭的不易开厢检查的车辆、恶劣天气等实际情况的影响,查验耗时具有不确定性。收费站绿色通道通行速度慢,易引起车辆排队拥堵,不利于保畅。按较快速度5分钟登记并查验一辆绿通车估算,若遇繁忙时段绿通车到达收费站时前方已有5辆车排队,则他需经过半小时后才能过站,影响鲜活农产品运输的时效性。跨省运输车辆需要多长查验,不仅耽误运输时间,由于多次对鲜活农产品进行查验,对于生鲜、绿色蔬菜等容易造成损害,从而造成产品价值降低。
发明内容
本发明的目的是提供了一种高速公路绿通车过站查验时间预测方法。
本发明是通过以下技术方案实现的:
本发明涉及一种高速公路绿通车过站查验时间预测方法,包括以下步骤:
A、对高速公路绿通车数据集进行处理,提取研究所需的数据字段;
B、对提取的数据字段进行数据预处理;
C、在数据预处理的基础上,采用车型和查验收费站两个特征建立历史均值模型,对高速公路绿通车过站查验时间进行预测;
D、在数据处理的基础上,采用车型、入口称重吨位、鲜活农产品种类、货厢类型、出口收费站、到站时段、气象因素、车辆信用等级的属性,基于K最近邻其局部改进的数据驱动模型对高速公路绿通车过站查验时间进行预测;
E、采用平均绝对误差、平均相对误差和均方误差3项评价指标对两种预测模型精度进行对比分析;通过对比结果得基于最近邻的数据驱动模型,更精确实现高速公路绿通车过站查验时间的预测,并在实际数据验证中表现出更好的适应性。
优选地,所述步骤A的具体步骤为:将收费站绿通车稽查业务数据、收费站出入口数据、预约查验平台记录数据相结合,形成绿通车大数据集,提取研究所需的数据字段。
我国高速公路收费采用全面覆盖收费过程的信息化系统,因而可以采集大量收费数据;研究所需的数据字段包括INSTATIONID(入口收费站编码)、INTIME(入口时间)、EXITSTATION(出口收费站编码)、EXITTIME(出口时间)。
绿通车稽查业务数据主要记录本次运输车辆通行的绿通车辆登记信息、货物信息、稽查班次、人员信息等;研究所需的数据字段包括:车牌号、车牌颜色、车辆类型、预约状态、货厢类型、运单类型、查验结果、查验时间、金额(元)、运输货物、入口称重(吨)、出口称重(吨)、出口车道、班长、站长、收费员、外勤、复核人、验货人。
预约查验平台记录数据主要记录绿通车预约用户的历史使用情况。研究所需字段为使用天数(天)、用户使用频次、用户信用等级。
优选地,所述步骤B所述数据预处理的具体步骤为:数据预处理的四个主要任务为:数据清洗、数据集成、数据变换和数据规约;同时结合研究目标,设计数据库表结构及其字段,以保证海量样本条件下数据查询和分析的效率。
步骤B中,数据挖掘需要的数据通常来源不全相同,数据集成是指将多个不同的数据源合并存放于同一个数据存储中的操作。数据变换指结合挖掘任务或挖掘算法的需要,将数据转换成特定的、规范化的形式。可以根据已有的属性集构造出新的属性。通常,对完整的大数据集进行数据挖掘必然耗费很长时间或者进行复杂的分析计算。数据规约是指在保障数据完整性的前提下产生更小的新的数据集。
所述数据清洗就是将原始数据集中的重复数据、噪声数据等与研究目标无关的数据进行筛选和删除。剔除异常数据,包括缺失数据、错误数据等。异常数据主要包含:缺少进入/离开收费站或进入/离开的时间信息、相同进出收费站数据、异常时间数据记录。
根据高速公路绿通车辆查验业务记录时间和收费站出口时间,构造新的字段,计算绿通车辆过站查验时间,表达式如下所示。
t
式中,t
计算查验时间样本数据的上下四分位数,以上下两个分位值为有效数据区间的上限和下限,超出该范围的数据被认为是噪声数据。数学表达式如式下所示。
t
t
式中,t
对研究字段中的类型数据,例如车牌颜色、车辆类型、预约状态、货厢类型、运单类型、查验结果等字段进行数字编码,便于后续计算。
优选地,所述步骤C的具体步骤为:
以收费站出口和车辆类型两个字段作为特征值,采用历史数据的均值计算该收费站不同车型的绿通车过站查验时间,公式如下:
式中,t
优选地,所述步骤D的具体步骤为:
采用KNN算法,通过搜索历史数据库中与预测值的特征向量最相似的K个记录来进行预测;其中,KNN算法包括:构建历史数据集、选择特征向量、标定K值、距离测量、局部加权估计五个步骤;对上述五个步骤进行算法局部改进,最终形成一个完整的改进模型作为基于KNN的高速公路绿通车过站查验时间预测算法。
步骤D的进一步说明:
(1)构建历史数据库;
以步骤A和步骤B中预处理之后的数据集构建历史数据库;
(2)选择特征向量
特征向量是数据特征的表现;在进行搜索近邻时需要通过这些特征来匹配历史数据,直接关系到预测精度;特征向量的选取尚未有统一的标准;影响查验时间的因素众多,不同因素之间可能相互关联,影响权重也不尽相同。将尽可能多的特征因素考虑到特征向量中有可能提高预测的精度,但是臃肿的特征向量导致较长的运算时间。为了避免选取特征向量的主观性,同时考虑到算法的时间复杂度,选择主成分分析法来确定特征向量。
step1:数据标准化
创建历史数据矩阵。
对数据进行标准化,以消除各个数据特征之间在量纲和数量级上的差别。
标准化矩阵为Z
其中,
Step2:确定相关系数矩阵
令r
r
Step3:确定相关系数矩阵的特征向量根据相关系数矩阵R
λ
F
F
Step4:确定主成分数量和影响因子
特征值用于表征各个主成分的影响程度。令w
计算累计贡献率,
计算各主成分贡献率与累计贡献率。通常,选取特征值大于1,累计贡献率达到90%以上的特征值λ
(3)标定K值
K作为唯一参数,其取值直接影响模型预测结果;采用恒定K值可能会造成误判,加大预测误差;采用交叉验证法确定各历史数据集中的预测效果最好的K值。具体步骤如下:
假设K的最小值与最大值分别为K
令K=K
式中,n
的真实值,P
计算不同K值得误差均值
当
(4)距离测量
距离度量的表示法有很多种,采用欧几里德距离来表征两个特征向量之间的相似程度。计算预测时刻特征向量与各历史记录特征向量之间的欧几里德距离,如下所示。
其中,F为特征向量个数,f∈[1,F]。F
(5)加权预测算法
不同近邻对预测的贡献是不一样的,当某个历史记录的特征向量与预测值的特征向量更接近时,该记录应对预测值具有更大的影响。在历史数据集中寻找K个与预测特征向量欧几里德距离最近的历史特征向量,并将所对应的K个历史值通过加权估计的方法来预测查验时间t
式中,K
优选地,所述步骤E具体分析过程为:选取平均绝对误差和平均相对误差作为预测误差衡量指标,比较每个时段测试数据集的预测误差大小,对两种预测模型精度进行对比分析;
其中,平均绝对误差EMAE和平均相对误差EMAPE计算公式如下所示:
式中,N为样本数量,t
本发明具有以下优点:
(1)本发明采用平均绝对误差(MAE),平均相对误差(MAPE)评价指标对2种预测模型精度进行对比分析。实验结果显示:基于K最近邻的高速公路绿通车过站查验时间预测模型相较于历史均值预测模型,其平均绝对误差和平均相对误差有明显降低。基于K最近邻的高速公路绿通车过站查验时间预测方法不仅预测精度高,而且能比较准确的预测不同场景下的查验时间走向及波动情况,在模型适应能力方面也呈现出一定的优势。
(2)本发明基于现有的高速公路鲜活农产品绿色通道车辆查验流程和管理平台的基础上,将收费站绿通车查验业务数据、收费站出入口数据、预约查验平台记录数据相结合,形成绿通车大数据。利用大数据的多维度、多视角、多领域进行分析、研判,从车型、入口称重吨位、鲜活农产品种类、货厢类型、出口收费站、到站时段、气象因素、车辆信用等级的属性,预测不同条件下到站绿通车查验所需要花费的时间,为绿通车司机和收费站工作人员提供数据支撑,以指导绿通车司机的出行方案规划和收费站绿色通道班次调度。
(3)本发明能够提供不同状况下高速公路收费站查验时间的精细可靠预测,充分考虑车型、运输货物、车厢类型、到站时段、天气、车辆信用等级的因素,从而实现目标场景下绿通车司机、收费站工作人员对查验时间的预判。
附图说明
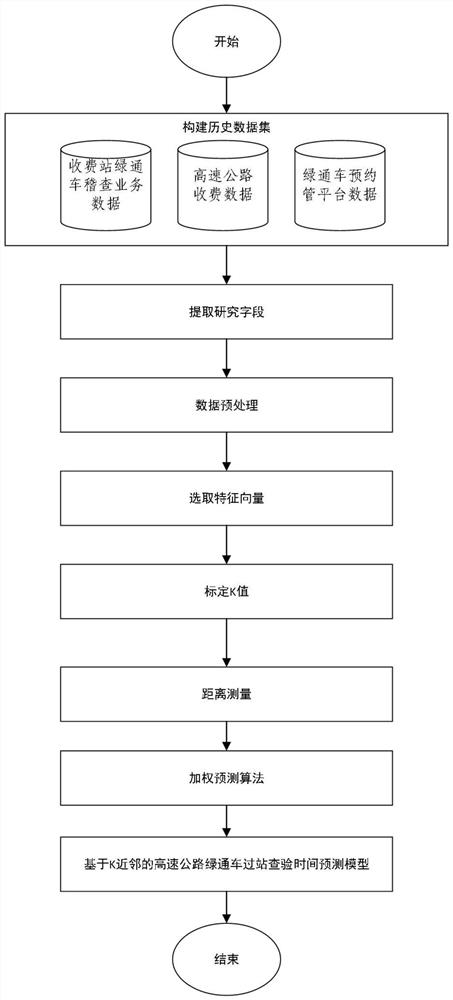
图1是本发明高速公路绿通车过站查验时间预测方法研究的流程图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。应当指出的是,以下的实施实例只是对本发明的进一步说明,但本发明的保护范围并不限于以下实施例。
实施例
本实施例涉及一种高速公路绿通车过站查验时间预测方法,流程见图1所示:包括以下步骤:
A、对高速公路绿通车数据集进行处理,提取研究所需的数据字段;
B、对提取的数据字段进行数据预处理;
C、在数据预处理的基础上,采用车型和查验收费站两个特征建立历史均值模型,对高速公路绿通车过站查验时间进行预测;
D、在数据处理的基础上,采用车型、入口称重吨位、鲜活农产品种类、货厢类型、出口收费站、到站时段、气象因素、车辆信用等级的属性,基于K最近邻其局部改进的数据驱动模型对高速公路绿通车过站查验时间进行预测;
E、采用平均绝对误差、平均相对误差和均方误差3项评价指标对两种预测模型精度进行对比分析;通过对比结果得基于最近邻的数据驱动模型,更精确实现高速公路绿通车过站查验时间的预测,并在实际数据验证中表现出更好的适应性。
所述步骤A的具体步骤为:将收费站绿通车稽查业务数据、收费站出入口数据、预约查验平台记录数据相结合,形成绿通车大数据集,提取研究所需的数据字段。
我国高速公路收费采用全面覆盖收费过程的信息化系统,因而可以采集大量收费数据;研究所需的数据字段包括INSTATIONID(入口收费站编码)、INTIME(入口时间)、EXITSTATION(出口收费站编码)、EXITTIME(出口时间)。
绿通车稽查业务数据主要记录本次运输车辆通行的绿通车辆登记信息、货物信息、稽查班次、人员信息等;研究所需的数据字段包括:车牌号、车牌颜色、车辆类型、预约状态、货厢类型、运单类型、查验结果、查验时间、金额(元)、运输货物、入口称重(吨)、出口称重(吨)、出口车道、班长、站长、收费员、外勤、复核人、验货人。
预约查验平台记录数据主要记录绿通车预约用户的历史使用情况。研究所需字段为使用天数(天)、用户使用频次、用户信用等级。
所述步骤B所述数据预处理的具体步骤为:数据预处理的四个主要任务为:数据清洗、数据集成、数据变换和数据规约;同时结合研究目标,设计数据库表结构及其字段,以保证海量样本条件下数据查询和分析的效率。
步骤B中,数据挖掘需要的数据通常来源不全相同,数据集成是指将多个不同的数据源合并存放于同一个数据存储中的操作。数据变换指结合挖掘任务或挖掘算法的需要,将数据转换成特定的、规范化的形式。可以根据已有的属性集构造出新的属性。通常,对完整的大数据集进行数据挖掘必然耗费很长时间或者进行复杂的分析计算。数据规约是指在保障数据完整性的前提下产生更小的新的数据集。
所述数据清洗就是将原始数据集中的重复数据、噪声数据等与研究目标无关的数据进行筛选和删除。剔除异常数据,包括缺失数据、错误数据等。异常数据主要包含:缺少进入/离开收费站或进入/离开的时间信息、相同进出收费站数据、异常时间数据记录。
根据高速公路绿通车辆查验业务记录时间和收费站出口时间,构造新的字段,计算绿通车辆过站查验时间,表达式如下所示。
t
式中,t
计算查验时间样本数据的上下四分位数,以上下两个分位值为有效数据区间的上限和下限,超出该范围的数据被认为是噪声数据。数学表达式如式下所示。
t
t
式中,t
对研究字段中的类型数据,例如车牌颜色、车辆类型、预约状态、货厢类型、运单类型、查验结果等字段进行数字编码,便于后续计算。
所述步骤C的具体步骤为:以收费站出口和车辆类型两个字段作为特征值,采用历史数据的均值计算该收费站不同车型的绿通车过站查验时间,公式如下:
式中,t
所述步骤D的具体步骤为:采用KNN算法,通过搜索历史数据库中与预测值的特征向量最相似的K个记录来进行预测;其中,KNN算法包括:构建历史数据集、选择特征向量、标定K值、距离测量、局部加权估计五个步骤;对上述五个步骤进行算法局部改进,最终形成一个完整的改进模型作为基于KNN的高速公路绿通车过站查验时间预测算法。
步骤D的进一步说明:
(1)构建历史数据库;
以步骤A和步骤B中预处理之后的数据集构建历史数据库;
(2)选择特征向量
特征向量是数据特征的表现;在进行搜索近邻时需要通过这些特征来匹配历史数据,直接关系到预测精度;特征向量的选取尚未有统一的标准;影响查验时间的因素众多,不同因素之间可能相互关联,影响权重也不尽相同。将尽可能多的特征因素考虑到特征向量中有可能提高预测的精度,但是臃肿的特征向量导致较长的运算时间。为了避免选取特征向量的主观性,同时考虑到算法的时间复杂度,选择主成分分析法来确定特征向量。
step1:数据标准化
创建历史数据矩阵。
对数据进行标准化,以消除各个数据特征之间在量纲和数量级上的差别。
标准化矩阵为Z
其中,
Step2:确定相关系数矩阵
令r
r
Step3:确定相关系数矩阵的特征向量根据相关系数矩阵R
λ
F
F
Step4:确定主成分数量和影响因子
特征值用于表征各个主成分的影响程度。令w
计算累计贡献率,
计算各主成分贡献率与累计贡献率。通常,选取特征值大于1,累计贡献率达到90%以上的特征值λ
(3)标定K值
K作为唯一参数,其取值直接影响模型预测结果;采用恒定K值可能会造成误判,加大预测误差;采用交叉验证法确定各历史数据集中的预测效果最好的K值。具体步骤如下:
假设K的最小值与最大值分别为K
令K=K
式中,n
的真实值,P
计算不同K值得误差均值
当
(4)距离测量
距离度量的表示法有很多种,采用欧几里德距离来表征两个特征向量之间的相似程度。计算预测时刻特征向量与各历史记录特征向量之间的欧几里德距离,如下所示。
其中,F为特征向量个数,f∈[1,F]。F
(5)加权预测算法
不同近邻对预测的贡献是不一样的,当某个历史记录的特征向量与预测值的特征向量更接近时,该记录应对预测值具有更大的影响。在历史数据集中寻找K个与预测特征向量欧几里德距离最近的历史特征向量,并将所对应的K个历史值通过加权估计的方法来预测查验时间t
式中,K
所述步骤E具体分析过程为:选取平均绝对误差和平均相对误差作为预测误差衡量指标,比较每个时段测试数据集的预测误差大小,对两种预测模型精度进行对比分析;
其中,平均绝对误差EMAE和平均相对误差EMAPE计算公式如下所示:
式中,N为样本数量,t
本发明采用基于数据驱动算法建立绿通车查验时间预测模型,能够更精确的预判绿通车所需要的查验时间;不仅能够根据预测时间合理安排人员班次,而且能够根据预判时间合理规划出行计划;是一种有助于实现查验时间的优化,有效的提高稽查效率和收费站服务水平,为收费公路管理部门和运输部门提供有力的决策支持和指导。
与现有技术相比,本发明具有以下优点:本发明采用平均绝对误差(MAE),平均相对误差(MAPE)评价指标对2种预测模型精度进行对比分析。实验结果显示:基于K最近邻的高速公路绿通车过站查验时间预测模型相较于历史均值预测模型,其平均绝对误差和平均相对误差有明显降低。基于K最近邻的高速公路绿通车过站查验时间预测方法不仅预测精度高,而且能比较准确的预测不同场景下的查验时间走向及波动情况,在模型适应能力方面也呈现出一定的优势。本发明基于现有的高速公路鲜活农产品绿色通道车辆查验流程和管理平台的基础上,将收费站绿通车查验业务数据、收费站出入口数据、预约查验平台记录数据相结合,形成绿通车大数据。利用大数据的多维度、多视角、多领域进行分析、研判,从车型、入口称重吨位、鲜活农产品种类、货厢类型、出口收费站、到站时段、气象因素、车辆信用等级的属性,预测不同条件下到站绿通车查验所需要花费的时间,为绿通车司机和收费站工作人员提供数据支撑,以指导绿通车司机的出行方案规划和收费站绿色通道班次调度。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质。
- 一种高速公路绿通车过站查验时间预测方法
- 一种基于大数据分析研判的绿通车辆查验方法