一种智能虚拟参考帧生成方法
文献发布时间:2023-06-19 11:17:41
技术领域
本发明涉及3D视频编码、深度学习领域,尤其涉及一种智能虚拟参考帧生成方法。
背景技术
多视点视频是一种典型的三维视频表示形式,能够为观众提供身临其境的立体感。为了提高多视点视频的压缩效率,国际标准组织JCT-VC推出了多视点加深度视频编码标准3D-HEVC。对于多视点视频编码,3D-HEVC不仅沿用了HEVC(高效视频编码)的编码技术来消除同一视点内的时域冗余和空域冗余,还引入了多种视点间编码技术来消除视点间冗余,有效地提升了整体的编码效率。
多视点视频的数据量远远大于2D视频,这给存储和传输带来了巨大的挑战。为此,国内外研究学者致力于对多视点视频编码的研究。Lukacs等人较早提出了视差补偿的观点,通过建立不同视点图像中相应区域的对应关系,利用已编码的独立视点预测非独立视点。Zhang等人提出一种从当前编码块的空时域相邻块来获取当前编码块视差矢量的方法。此外,一些研究学者也从生成参考帧的角度开展了研究。Yamamoto等人提出一种利用视点插值获取视点间预测参考的方法。Chen等人提出了一种基于缩放参考层偏移的视差补偿预测方法。
近年来,深度学习技术成为一个新的研究热点,国内外研究学者也开始将深度学习技术引入到视频编码领域,在帧内预测、帧间预测、环路滤波等方面都取得了较高的编码增益。Li等人设计了一个基于全连接网络的帧内预测模型,以端到端学习的方式生成预测块。Yan等人将分数像素运动补偿过程视为帧间回归问题,并提出了一个分数像素参考生成网络,有效地提高了编码效率。Zhao等人使用自适应可分离卷积,根据当前待编码帧的参考帧生成一个虚拟中间帧,并以此作为一个额外参考,提高了预测的准确度。Zhang等人提出了一个深层残差高速卷积神经网络(RHCNN),不仅提高了重建帧的峰值信噪比,而且显著降低了码率。
发明人在实现本发明的过程中,发现现有技术中至少存在以下缺点和不足:
与深度学习在2D视频编码领域的成功应用相比,目前仍缺乏基于深度学习技术的多视点视频编码方法;3D-HEVC现有的视点间预测编码工具未充分利用相邻视点间的视差关系,编码效率仍有待进一步提高。
发明内容
本发明提供了一种智能虚拟参考帧生成方法,本发明充分利用相邻视点间的视差关系,设计一种基于视点合成的智能生成模型来学习和生成视差图,并利用视差图对视点间参考帧进行时域对齐并与时域虚拟参考帧融合,最终生成一个高质量的虚拟参考帧,为当前编码帧提供高质量的参考,从而提高预测的准确度,进而提升编码效率,详见下文描述:
一种智能虚拟参考帧生成方法,所述方法包括以下步骤:
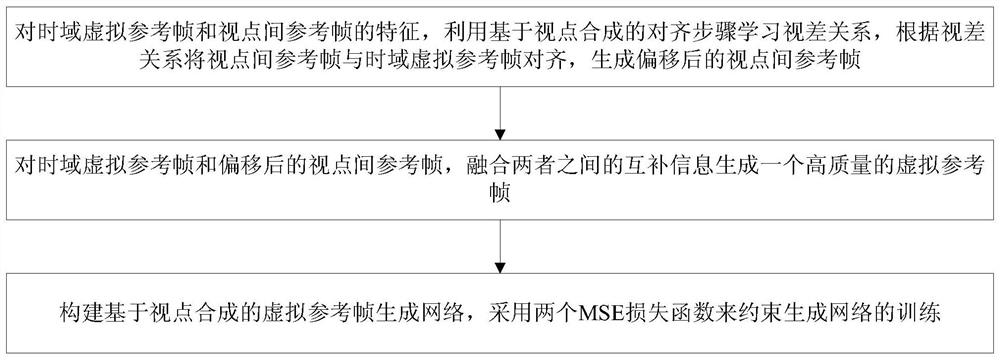
1)对时域虚拟参考帧和视点间参考帧的特征,利用基于视点合成的对齐步骤学习视差关系,根据视差关系将视点间参考帧与时域虚拟参考帧对齐,生成偏移后的视点间参考帧;
2)对时域虚拟参考帧和偏移后的视点间参考帧,融合两者之间的互补信息生成一个高质量的虚拟参考帧;
3)构建基于视点合成的虚拟参考帧生成网络,采用两个MSE损失函数来约束生成网络的训练。
其中,所述步骤1)具体为:
将时域虚拟参考帧F
根据视差图将视点间参考帧F
F′
其中,w(·)表示映射操作。
其中,所述步骤2)具体为:
使用自编码器结构,将特征图分别下采样和上采样学习不同尺度的信息表达,融合重建,将同一尺度下的浅层特征与深层特征相加。
其中,所述步骤3)具体为:
合成损失L
重建损失L
进一步地,所述合成损失L
其中,N是一幅图像中像素点总数,F
进一步地,所述重建损失L
其中,F
本发明提供的技术方案的有益效果是:
1、本发明生成了一个较高质量的参考帧,通过学习时域虚拟参考帧与视点间参考帧之间的视差关系,并将其转换成视差图,再根据视差图对视点间参考帧进行视差偏移,使其与时域虚拟参考帧对齐,进而重建出一个高质量虚拟参考帧,为预测编码过程提供参考;
2、本发明有效的提高了视点间预测编码的准确度,减少了编码比特,更加有利于多视点视频的存储和传输;
3、本发明能够有效减少视频的压缩失真,提高压缩视频的质量。
附图说明
图1为一种智能虚拟参考帧生成方法的流程图;
图2为参考帧特征提取过程的流程图;
图3为融合重建虚拟参考帧过程的流程图;
图4为基于视点合成的虚拟参考帧生成网络的流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
本发明实施例提供了一种智能虚拟参考帧生成方法,搭建了一个基于视点合成的虚拟参考帧生成网络,生成一个高质量的虚拟参考帧并为当前编码帧提供一个高质量参考,提高了预测的准确度,进而提升了编码效率。方法流程参见图1,该方法包括以下步骤:
一、特征提取
将时域虚拟参考帧F
其中,多级感受野模块是一个多分支的结构,在每一分支中,将普通的卷积核与相应扩张率的空洞卷积相结合。本发明实施例使用了四种不同尺度的卷积核,分别为1×1、3×3、5×5、7×7。所对应的空洞卷积的扩张率分别为1、3、5、7,空洞卷积的卷积核大小固定为3×3。
二、基于视点合成的对齐
对于时域虚拟参考帧F
首先,将时域虚拟参考帧F
最后,利用视点合成思想,根据视差图将视点间参考帧F
F′
其中,w(·)表示映射操作。
三、融合重建虚拟参考帧
对于时域虚拟参考帧F
此外,为了尽可能多的提取输入图像的低频和高频信息,该模块将同一尺度下的浅层特征与深层特征相加。融合重建模块中的所有卷积层均采用3×3大小的卷积核。
四、生成网络整合并嵌入编码框架
本发明实施例考虑到视频序列的时域相关性和视点域相关性,提出了一个基于视点合成的生成网络来获得高质量的虚拟参考帧,为帧间预测提供更高质量的参考。
图4给出了基于视点合成的虚拟参考帧生成网络流程图。该生成网络共有两个输入,分别为时域虚拟参考帧F
与原始帧较为相似的高质量虚拟参考帧能够提高预测编码的准确度,进而提高编码效率,为了保证虚拟参考帧的重建质量,本发明实施例将MSE(均方误差)损失作为虚拟参考帧生成网络的损失函数的主要形式,采用两个MSE损失函数来约束生成网络的训练,分别为合成损失L
其中,L
其中,N是一幅图像中像素点总数,F
其中,L
其中,F
总的损失函数可表示为:L=L
其中,β表示控制不同损失之间权重的超参数。
本发明实施例使用该损失函数训练完成的网络模型嵌入到3D-HEVC参考软件HTM16.2编码平台中。
在编码过程中,首先根据编码平台提供的时域参考帧,利用可分离卷积网络生成时域虚拟参考帧,然后将时域虚拟参考帧和视点间参考帧送入基于视点合成的虚拟参考帧生成网络,生成一个高质量的虚拟参考帧,最后将该虚拟参考帧送入编码平台作为一个额外的参考。
本发明实施例对各器件的型号除做特殊说明的以外,其他器件的型号不做限制,只要能完成上述功能的器件均可。
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种智能虚拟参考帧生成方法
- 一种基于视差引导融合的虚拟参考帧生成方法